
一文读懂|栈溢出攻击转载
什么是栈
简单来说,栈 是一种 LIFO(Last In Frist Out,后进先出) 形式的数据结构。栈一般是从高地址向低地址增长,并且栈支持 push(入栈) 和 pop(出栈) 两个操作。如下图所示:
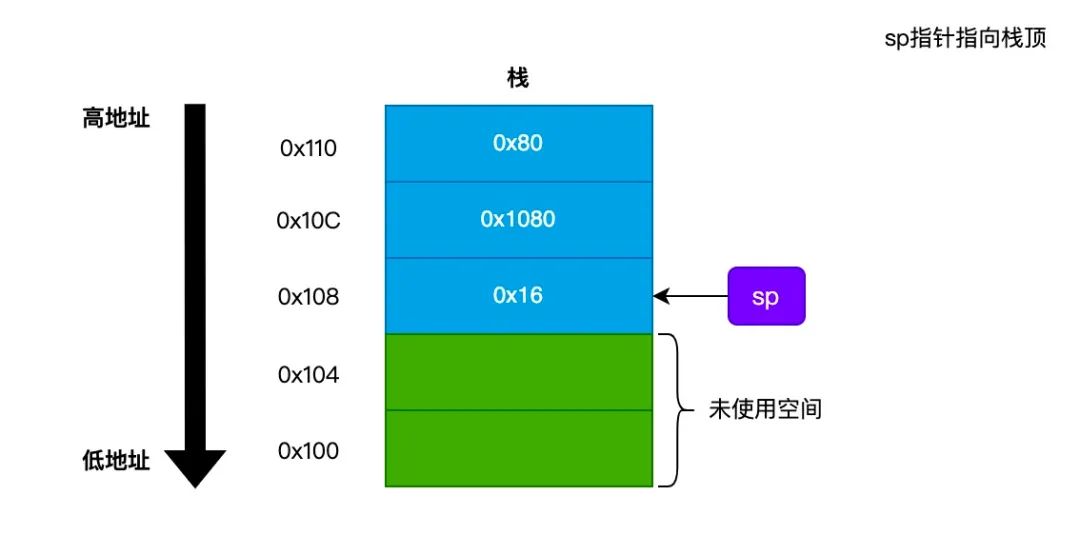
push 操作先将 栈顶(sp指针) 向下移动一个位置,然后将数据写入到新的栈顶;而 pop 操作会从 栈顶 读取数据,并且将 栈顶(sp指针) 向上移动一个位置。
例如,将 0x100 压入栈,过程如下图所示:
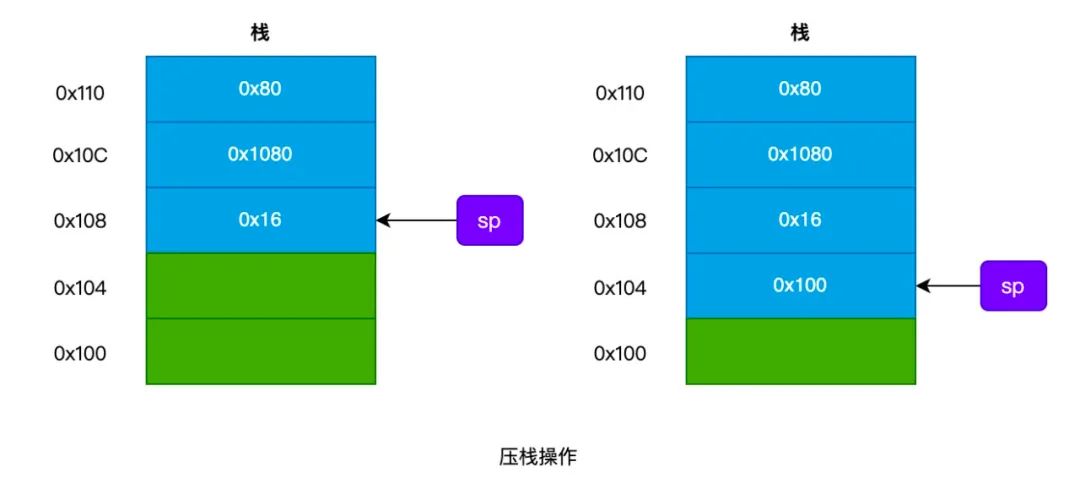
我们再来看看 出栈 操作,如下图所示:
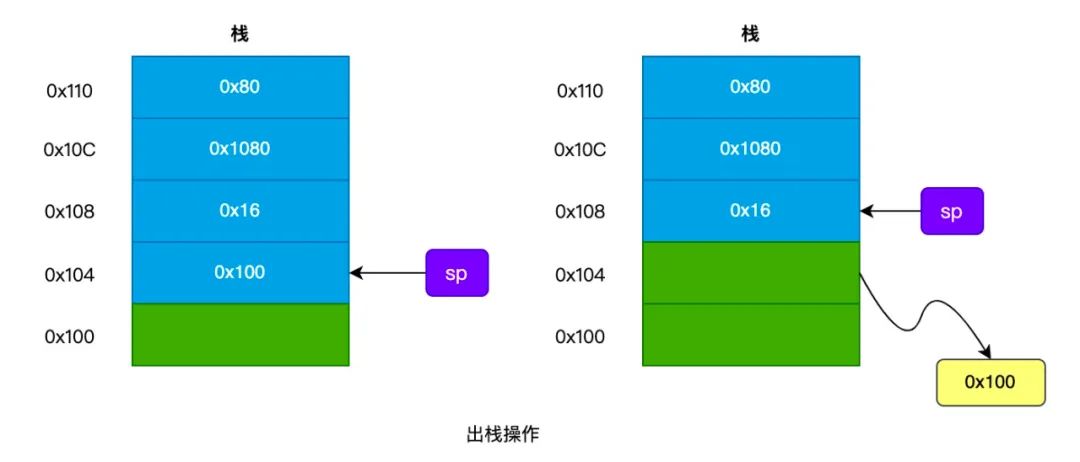
栈帧
栈帧,也就是 Sack Frame,其本质就是一种栈,只是这种栈专门用于保存函数调用过程中的各种信息(参数,返回地址,本地变量等)。
栈帧 有 栈顶 和 栈底 之分,其中栈顶的地址最低,栈底的地址最高。SP(栈指针) 就是一直指向栈顶的。在 x86 的 32 位 CPU 中,我们用 %ebp 寄存器指向栈底,也就是基址指针;用 %esp 寄存器指向栈顶,也就是栈指针。下面是一个栈帧的示意图:
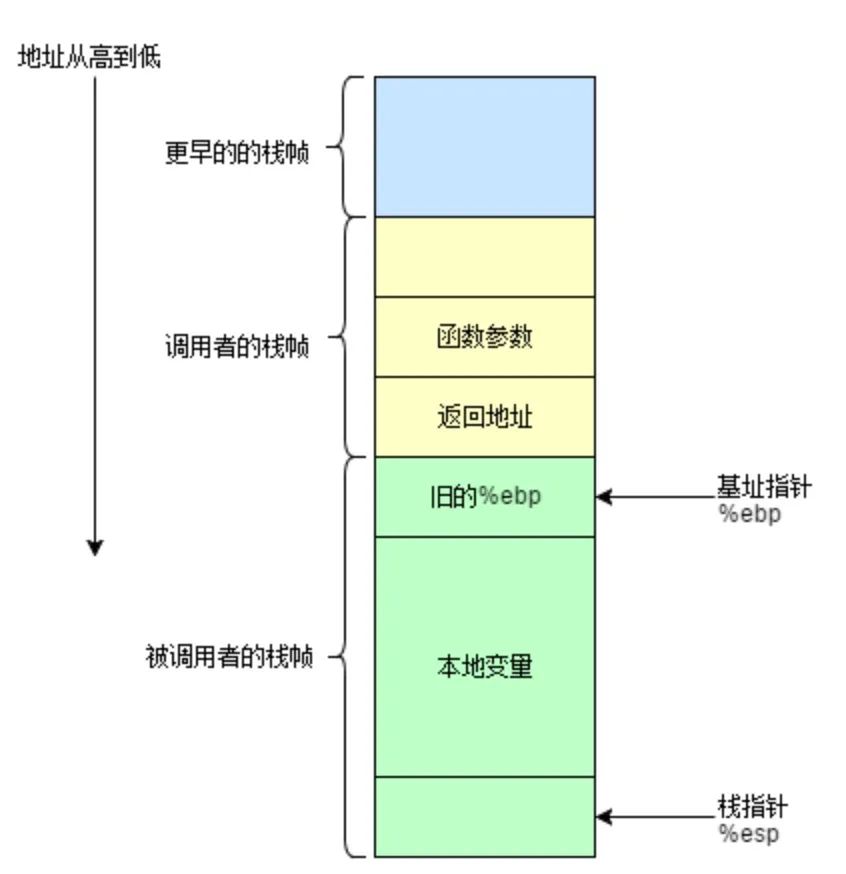
一般来说,我们将 %ebp 到 %esp 之间区域当做栈帧。并不是整个栈空间只有一个栈帧,每调用一个函数,就会生成一个新的栈帧。
在函数调用过程中,我们将调用函数的函数称为:调用者(caller),将被调用的函数称为:被调用者(callee)。在这个过程中:
-
调用者需要知道在哪里获取被调用者返回的值(一般存放到%eax寄存器)。 -
被调用者需要知道传入的参数在哪里和调用完后的返回地址在哪里。 -
我们需要保证在 被调用者返回后,%ebp和%esp寄存器的值应该和调用前一致。
函数调用
现在,我们来看看函数调用时,栈帧是如何变化的。
我们以一个函数调用的实例来解说,代码如下:
// stack.c
int add_func(int a, int b)
{
int c, d;
c = a;
d = b;
return c + d;
}
int main(int argc, char *argv[])
{
int total;
total = add_func(1, 2);
return 0;
}
我们使用命令 gcc -S -m32 stack.c 来编译上面的代码,获取的汇编代码如下所示(去掉一些无关紧要的信息):
add_func:
pushl %ebp // 保存ebp寄存器到栈
movl %esp, %ebp // 把ebp进程设置为esp的值
subl $16, %esp // 为局部变量申请空间
movl 8(%ebp), %eax // 把参数a保存到eax寄存器中
movl %eax, -8(%ebp) // 把eax寄存器的值保存到局部变量c中(c = a)
movl 12(%ebp), %eax // 把参数b保存到eax寄存器中
movl %eax, -4(%ebp) // 把eax寄存器到值保存到局部变量d中(d = b)
movl -8(%ebp), %edx // 把d的值保存到edx寄存器中
movl -4(%ebp), %eax // 把c的值保存到eax寄存器中
addl %edx, %eax // 将eax寄存器与edx寄存器的值相加,保存到eax中(返回值)
leave
ret // 函数返回
...
可能汇编代码比较难看懂,我们用下面的插图来说明这个调用过程:
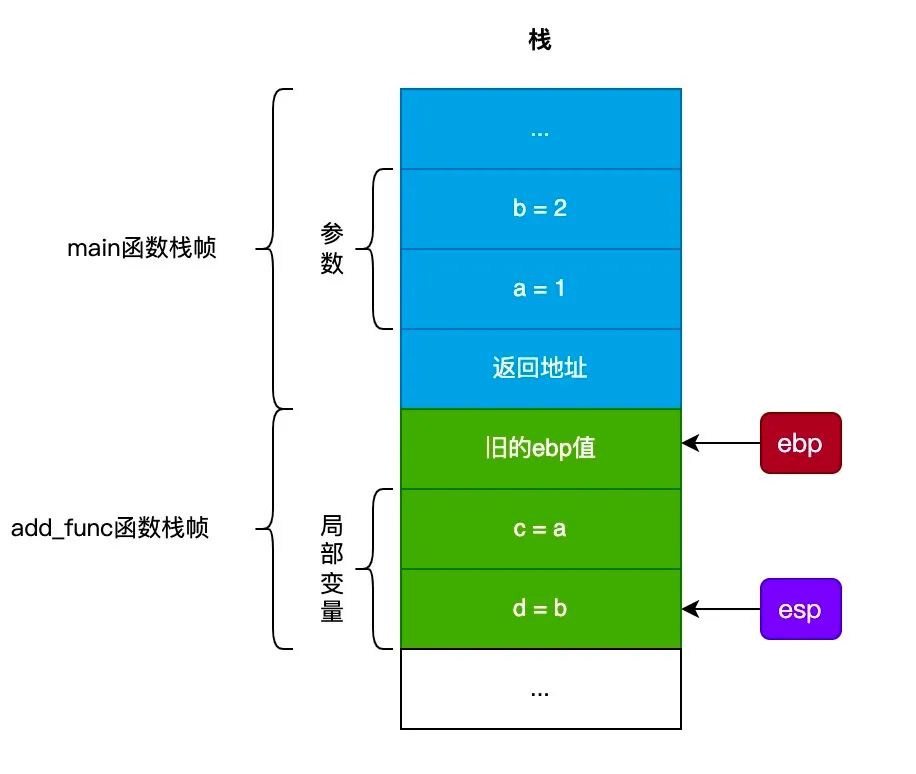
如上图所示,调用过程如下:
-
在 main()函数调用add_func()函数前,先将调用add_func()函数的参数压栈。 -
在调用 add_func()函数时,会将返回地址压栈,接着进入add_func()函数。 -
add_func()函数执行时,会将原来的ebp寄存器的值压栈,然后把ebp寄存器的设置为esp寄存器的值。 -
接着 add_func()函数会为局部变量申请空间,也就是将esp寄存器向下移动。 -
然后把局部变量 c设置为参数a的值,局部变量d设置为 参数b的值。 -
最后将局部变量 c 和 d 的值相加,放置到 eax寄存器中(C语言规定以eax寄存器传递返回值),然后调用ret指令返回到main()函数。
函数返回
上面介绍了 函数调用 的过程,现在我们来介绍一下函数调用完毕后,从被调用函数返回到原来的函数过程是如何处理的。
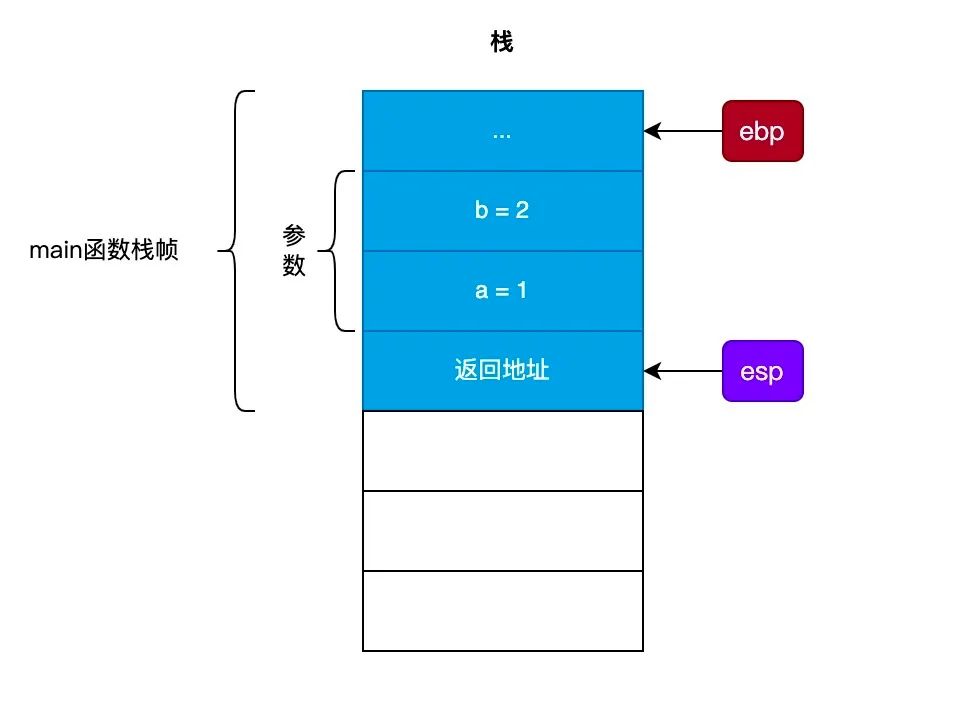
从 add_func() 函数的汇编代码可以看到,当被调用函数执行完毕返回到调用函数前,会执行 leave 指令,这条指令等价于:
movl %ebp, %esp
popl %ebp
这两条汇编指令的意思是,将 esp寄存器 和 ebp寄存器 恢复到调用函数前的值。
然后,调用 ret 指令返回到原来的函数。ret 指令会从栈顶获取 返回地址,然后跳转到(jmp指令)此地址继续执行。这时的 栈帧 的结构如下图所示:
栈溢出攻击
前面说了那么,都是为了 栈溢出攻击 这节作铺垫的。通过前面的学习,我们知道调用函数的 参数 、执行完函数后的 返回地址 和被调用函数的 局部变量 都是存放在栈中的。
如果在调用函数时,不小心将 返回地址 覆盖了,那么调用完函数后,将不会跳转到原来的函数继续执行,而是跳转到覆盖后的地址执行。如下图所示:
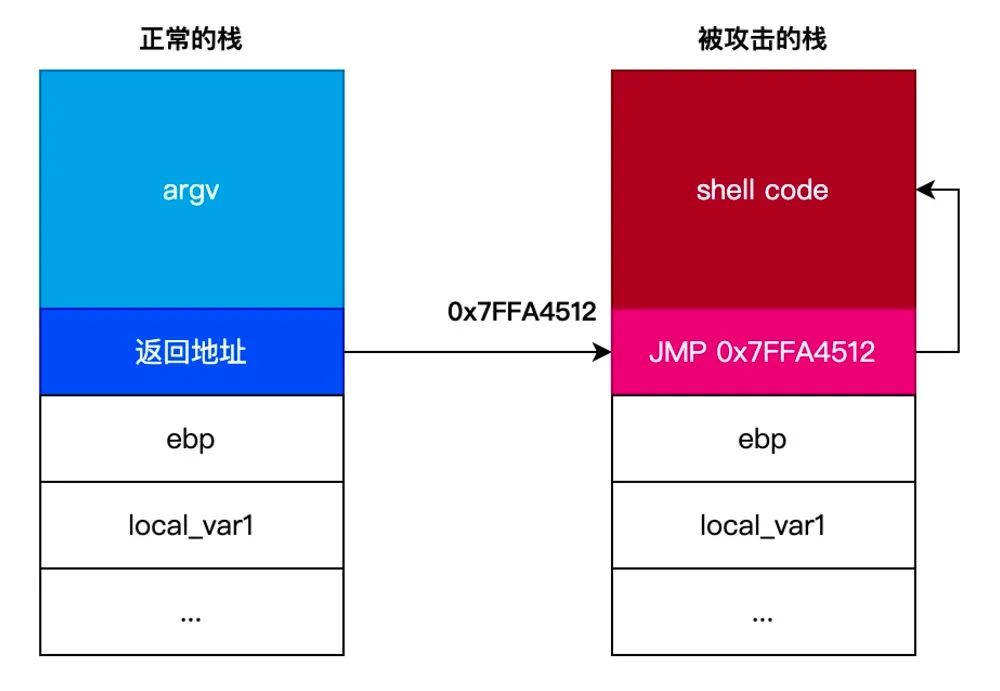
那么,怎样才能把 返回地址 覆盖呢?我们可以通过下面的例子来说明:
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdint.h>
#define PTR_SIZE 8 // 指针的大小
#define EBP_SIZE 8 // ebp寄存器的大小
void inject_callback()
{
printf("inject_callback called...\n");
exit(0);
}
void func_call(char *addr, int len)
{
char tmpBuf[16] = {0xff};
memcpy(tmpBuf + 16 + EBP_SIZE, addr, len);
printf("func_call called...\n");
}
int main(int argc, char** argv)
{
uint64_t injectPtr = (uint64_t)&inject_callback;
func_call(&injectPtr, PTR_SIZE);
printf("main exited...\n");
return 0;
}
我们使用以下命令编译上面代码,并且执行:
$ gcc stack-overflow.c -fno-stack-protector -o stack-overflow
$ ./stack-overflow
func_call called...
inject_callback called...
在编译上面程序时,一定要加上
-fno-stack-protector参数,否则将会触发栈溢出保护,导致执行失败。
在上面的代码中,我们并没有直接调用 inject_callback() 函数,而是通过把 inject_callback() 函数的地址复制到 func_call() 函数的局部变量 tmpBuf 中。
由于局部变量 tmpBuf 的类型为字符串数组,而且大小为 16 个字节。但我们复制数据是从 24(16 + 8)处开始复制,已经超出了局部变量 tmpBuf 的大小,如下图所示:
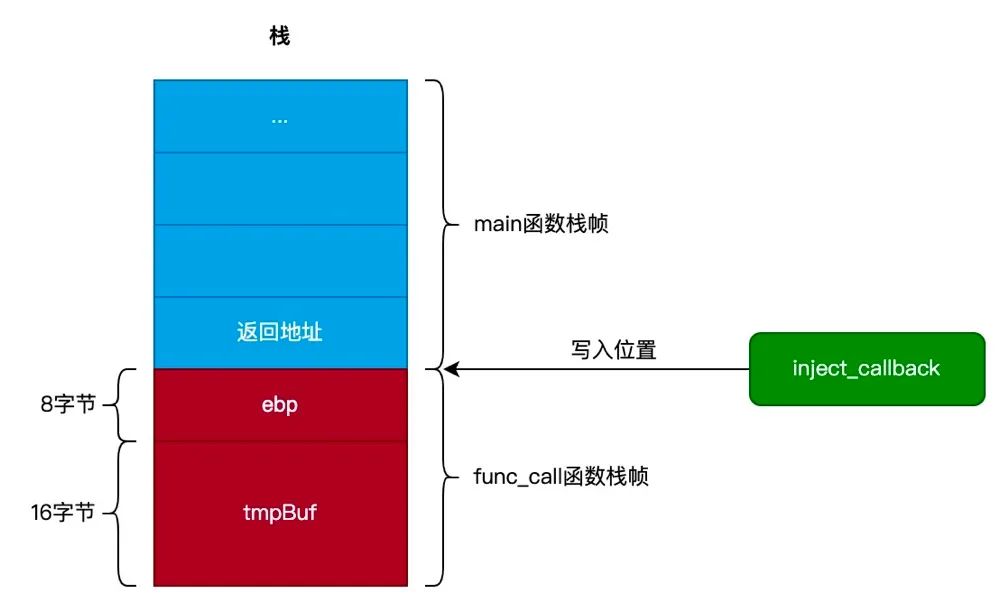
从上图可以看出,func_call() 函数在调用 memcpy() 函数复制数据时,由于不小心用 inject_callback() 函数的地址覆盖了返回地址,导致 func_call() 函数执行完毕后,跳转到 inject_callback() 函数处执行。
这就是 栈溢出攻击 的原理,而导致 栈溢出攻击 的原因就是:调用 memcpy()、strcpy() 等函数复制数据时,没有对数据的长度进行验证,从而 返回地址 被复制的数据覆盖了。
黑客可以利用 栈溢出攻击 来把函数的返回地址修改成入侵代码的地址,从而实现攻击的目的。
作者:Linux内核那些事
文章来源:微信公众号

