
为什么递归会造成栈溢出?转载
在任何编程语言中,掌握内存管理都是很重要的,一方面对于操作系统而言程序内存使用是有限制的,另外一方面内存变化也会影响我们的程序执行效率。
选择基于 C 语言来学习,也是因为我们可以借助一些工具。例如,使用 gdb 方便的调试我们的程序,从每一步的调试,来看程序的运行变化。
本节你能学到什么?
在本文开始前,先列出几个问题,读者朋友可以先思考下,也是本讲你能学到的一些知识点,如下:
-
我们的 32 位操作系统能够管理的内存是多大?对应 64 位又是如何? -
内存空间一般划分为哪几个段,每个段存储都存储哪些东西? -
为什么说栈是一块连续的内存空间? -
为什么递归会造成栈溢出? -
堆内存怎么申请?
前置知识
简单列举一些基础知识点,这些是接下来会用到的。
-
计算机最小单位是字节(byte),1byte=8bit(翻译为中文就是一个字节等于 8 个二进制位) -
计算机底层使用的二进制,如果是用来展示通常是 10 进制,编程用的时候会采用 16 进制, 内存地址编码使用的就是 16 进制。 -
1 个 16 进制数字就表示 4 位二进制数字。 -
32 bit 操作系统 1 个指针占用 4 个字节,64 bit 操作系统 1 个指针占用是 8 个字节(C 语言中指针变量内存地址占有就是 8 字节)。
问题解答:我们的 32 位操作系统能够管理的内存是多大?对应 64 位又是如何?
32 位操作系统的地址总线是 32 位,也就是寻址空间是 32 位,因为内存是按照字节寻址的,每个字节可以理解成对应一个地址编号,如下所示,可以是全 0 的,也可以是全 1 的。
00000000 00000000 00000000 00000000
........ ........ ........ ........
11111111 11111111 11111111 11111111
32 位操作系统能分配的地址编号数是 




最终,我们 32 位操作系统最多可管理的内存是 4 GB。
注:1024Byte = 1KB | 1024KB = 1MB | 1024MB = 1GB。
内存的访问是比磁盘驱动器快的多了,因此 4GB 肯定也不满足不了需求了,随之而来的是现在的 64 位操作系统,理论上它所能管理的内存空间为 2 的 64 次方,这个数字是很大的,这个内存现在是足够用的,通常我们是用不到这么大的。
内存划分
内存是交由操作系统管理,它会给我们的内存做编号、用户内存与操作系统内存隔离。
在 64 位的操作系统上,我们能够使用的是前面的 48 位,0x0000000000000000 ~ 0x00007FFFFFFFFFFF,而内核态在用户态最后一位上加 1 就是 0xFFFF800000000000 ~ 0xFFFFFFFFFFFFFFFF。
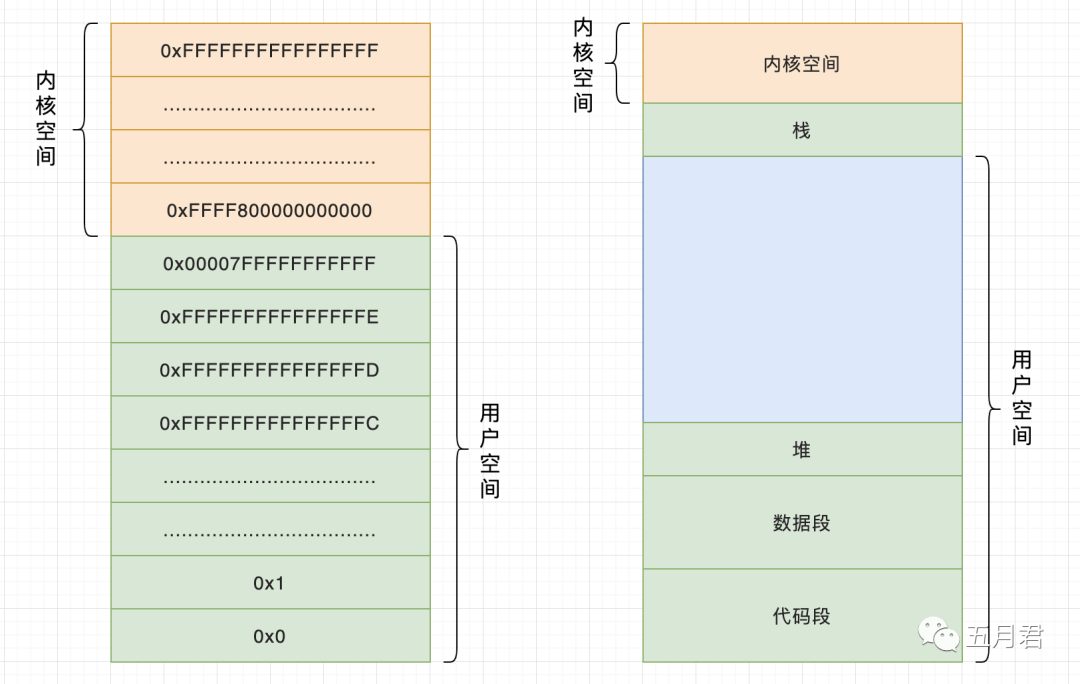
问题解答:内存空间一般划分为哪几个段,每个段存储都存储哪些东西?
通过上图可以清楚的看到,我们的内存是有划分的,一份为系统的内核空间,另外一部分为用户空间,与我们程序相关的主要看下用户空间部分,将内存划分为:栈、堆、数据段、代码段,每个里面分别存储的是什么?下面会分别介绍,答案就在里面。
代码段
代码段保存我们代码编译后的机器码,代码段的内存地址也是最小的,下例,以 0x4 开头,你可以先记住这个值,在后面介绍的其它段里,可以比较下内存大小。
(gdb) p &swap
$11 = (void (*)(int *, int *)) 0x40052d <swap>
(gdb) p &main
$12 = (int (*)()) 0x400559 <main>
数据段
数据段保存静态变量、常量和一些全局变量,以下是一段示例,两个函数分别定义了静态变量 count 和执行了全局变量 globalCount。
#include <stdio.h>
int globalCount = 0;
int add(int x, int y) {
static int count = 0;
count++;
globalCount++;
return x + y;
}
int sub(int x, int y) {
static int count = 0;
count++;
globalCount++;
return x + y;
}
int main() {
int a = 6;
int b = 3;
int s1 = add(a, b);
int s2 = sub(a, b);
printf("s1=%d s2=%d", s1, s2);
}
通过 gdb 调试看下,分别在 add 函数里打印了静态变量 count 和全局变量 globalCount 的内存地址。
静态变量 count 是声明在函数内部的,因此两次打印出来的地址也是不一样的,自然两个是不会相互影响的,全局变量可以看到内存地址是一样的,因此在任意一个函数里修改,值都会发生变化。
0x601038、0x60103c、0x601040 每次递增 4 个字节,可以看到它们的内存地址是连续递增的,数据段的内存地址以 0x6 开头是大于代码段的。
add (x=6, y=3) at main2.c:5
5 count++;
(gdb) p &count
$1 = (int *) 0x60103c <count.2181>
(gdb) p &globalCount
$2 = (int *) 0x601038 <globalCount>
sub (x=6, y=3) at main2.c:11
11 count++;
(gdb) p &count
$3 = (int *) 0x601040 <count.2186>
(gdb) p &globalCount
$4 = (int *) 0x601038 <globalCount>
数据段还有一种称为 “BSS” 段,表示未初始化或初始化为 0 的所有全局变量或静态变量,static int a 或全局变量 int a 称为 “未初始化数据段”。
关于初始化数据段与未初始化数据段,这里有篇文章讲的也很好,可以参考 https://zhuanlan.zhihu.com/p/62208277。
栈段
栈寄存器段,指向包含当前程序栈的段,这些都是临时的信息。例如:局部变量、函数参数、返回值和当前程序运行状态等都存在于栈中,随着这些临时变量对应的作用域完成之后,也会被弹出栈。
一个变量交换示例
以下为一段 C 语言代码示例,通过 swap 函数交换两个变量。
// main.c
#include <stdio.h>
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
int main() {
int a = 2;
int b = 3;
swap(&a, &b);
printf("a=%d b=%d", a, b);
}
先使用 gcc 编译我们的源代码 gcc -g main.c -o main.out,之后使用 gdb 调试。
问题解答:为什么说栈是一块连续的内存空间?
在 C 语言里一个整型的数据大小为 4 个字节(指针类型另有规定,后面会讲),整型变量 a 存储的内存地址为 0x7fffffffe35c 也即首地址,按照 4 Byte 推算应该是 0x7fffffffe35c、0x7fffffffe35d、0x7fffffffe35e、0x7fffffffe35f。整型变量 b 的内存地址为 0x7fffffffe358 同样按照 4 Byte 推算应该是 0x7fffffffe358、0x7fffffffe359、0x7fffffffe35a、0x7fffffffe35b 也就是加上 4 个字节正好相邻于变量 a,因此我们还可以在确认一个问题是:“栈是一块连续的内存区域”。
通过一个图,相对直观的感受下。
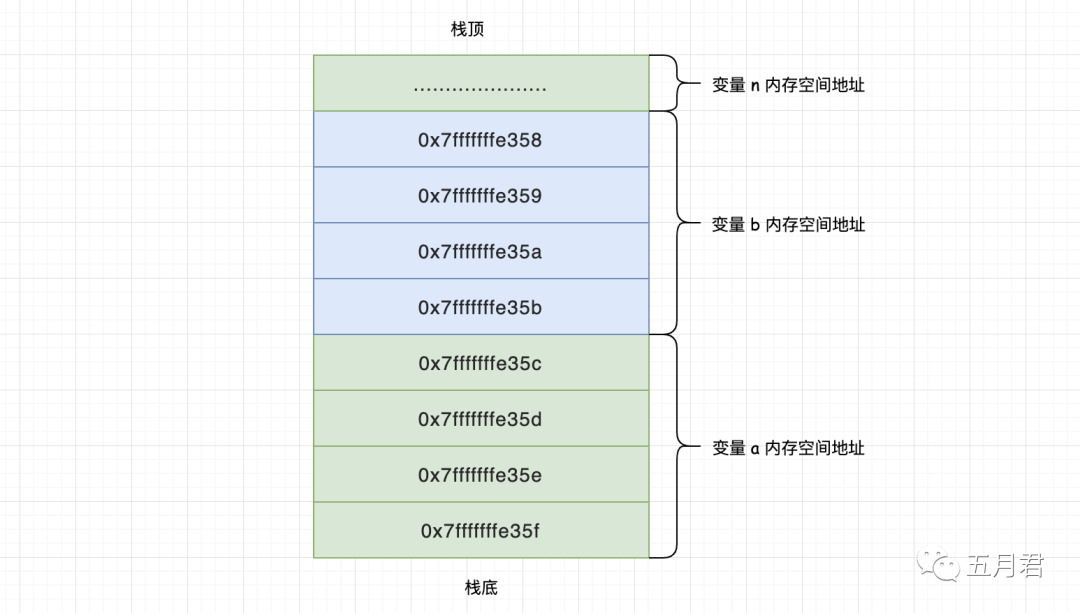
这时可能会产生一个疑问,为什么创建变量顺序是 a、b 而分配的内存地址确是递减的顺序?
这涉及到栈的存储结构,栈是先进后出的,栈顶的地址是由系统预先设置好的,由栈顶入栈随后每次内存地址呈递减的方式依次分配,当还有新元素时就继续压栈,最先入栈的最后出栈,也可理解为栈底对应高地址、栈顶对应低地址。
(gdb) p &a
$1 = (int *) 0x7fffffffe35c
(gdb) p &b
$2 = (int *) 0x7fffffffe358
使用 gdb 调试进入 swap 函数,这两个参数 a、b 我们定义为指针类型,可以看到它的值为外层整型变量 a 和 b 的内存地址。
swap 函数里的指针类型变量 a 与 b 也是有内存地址的,可以打印出来看下。同样的可以看出,这两个内存地址之间相差 8 个字节,也就号符合指针类型的定义,在 64 位系统下一个指针占用 8 个字节,当然大学课本上你可能看到过 1 个指针占用 4 个字节,那是针对的 32 位系统。
swap (a=0x7fffffffe35c, b=0x7fffffffe358) at main.c:3
3 int temp = *a;
(gdb) p &a
$1 = (int **) 0x7fffffffe328
(gdb) p &b
$2 = (int **) 0x7fffffffe320
目前处于代码的第 3 行,swap 函数里指针变量 a 存储的是外层传入的变量 a 的内存地址,如何获取该值呢?那么在 C 语言中通过运算符 * 号可以取到一个内存地址对应的值,也就是“解引用”。
(gdb) p *a
$3 = 2
接下来执行 2 两步,程序停留在第 5 行,可以看到 a 的值由 2 变为了 3,为什么 swap 函数能交换两个变量的值,也正是因为我们在这里通过指针修改了传进来的两个变量的内存地址。
(gdb) n
4 *a = *b;
(gdb) n
5 *b = temp;
(gdb) p *a
$4 = 3
查看函数堆栈
通过 bt 可以打印当前函数调用栈的所有信息,左侧有一个 #0、#1 的序号,0 就是目前的栈顶,因为我们这个程序很简单,程序入口函数 main() 就是我们的栈底,而当前执行的 swap() 函数就是我们的栈顶,也是当前程序所在的位置。
(gdb) bt
#0 swap (a=0x7fffffffe35c, b=0x7fffffffe358) at main.c:5
#1 0x0000000000400582 in main () at main.c:11
栈溢出
栈是有内存大小限制的,Linux 或 Mac 下我们可通过 ulimit -s 命令查看,结果为:8192 # stack size (kbytes) ,Linux 下用户默认的栈空间大小为 8MB。
递归造成的栈溢出
写递归时,通常要控制好边界,避免出现无限递归,递归的层级也不要太深,尽量不要在栈上定义太大的数据。一段递归调用的程序如下所示:
#include <stdio.h>
void call()
{
int a[2048];
printf("hello call! \n");
call();
}
int main(int argc, char *argv[]) {
call();
}
gdb 调试之后得到如下错误信息:
Program received signal SIGSEGV, Segmentation fault.
0x000000000040053d in call () at a.c:6
bt -n 从栈底打印 n 条信息,最下面为我们的 main 函数,除此之外可以看到 call() 总共递归调用了 1022 次,因为最上面序号是从 0 开始的。
(gdb) bt -5
#1018 0x000000000040054c in call () at a.c:7
#1019 0x000000000040054c in call () at a.c:7
#1020 0x000000000040054c in call () at a.c:7
#1021 0x000000000040054c in call () at a.c:7
#1022 0x0000000000400567 in main (argc=1, argv=0x7fffffffe458) at a.c:10
问题解答:为什么递归会造成栈溢出?
当我们递归一个函数时,这个时候每一次的递归运行都会做压栈操作,栈是一种先进后出的数据结构,系统也是有最大的空间限制的,Linux 下用户默认的栈空间大小为 8MB,当栈的存放容量超出这个限制之后,通常我们的程序会得到栈溢出得到错误。
留一个问题大家思考下🤔:通过上面我们知道了递归层级太深会导致栈溢出,这是因为系统会有栈空间大小限制的,笔者平常使用 JavaScript 相会多一些,如果是在 JavaScript 中遇到这种问题怎么解决?不知道也没关系,笔者最近在写一个系列文章 《JavaScript 异步编程指南》可以带你一起深入了解这个问题。
字符数组造成的栈溢出
模拟这个问题很简单,创建一个过大的字符数组。
#include<stdio.h>
int main()
{
char str[8192 * 1024];
int size = sizeof(str);
printf("size: %d\n", size);
}
通过 gdb 调试,会得到一个 “Segmentation fault” 通常也称为段错误,指的是访问的内存超出了系统给程序设定的内存空间,一般包括:不存在的内存地址、访问了系统保护的内存地址、访问了只读的内存地址、栈溢出等。
Program received signal SIGSEGV, Segmentation fault.
0x000000000040054e in main () at index.c:7
解决这种问题,继续往下看~
堆段
堆段由开发者手动申请分配和释放,也称动态内存分配。在 C 语言中可以使用系统提供的函数 malloc() 和 free() 申请和释放内存。
继续拿上面 “字符数组栈溢出” 这个示例,现在改成在堆中创建内存,这时仅在栈中保存指针变量 str 的地址,真正数据存放于堆中,也就不会出现栈溢出问题了。
#include <stdio.h>
#include <malloc.h>
int main()
{
char *str = (char *)malloc(8192 * 1024);
if (str == NULL) {
printf("Heap memory application failed.");
return 0;
}
printf("Heap memory application successed.");
free(str);
str = NULL;
return 0;
}
进入 gdb 调试,代码停留在第 5 行,在未分配堆内存之前,打印 str 可以看到是没有值的,而 &str 取的是该变量在栈空间的内存地址 0x7fffffffe368,这不是一回事,这是该变量的值。
再次执行,创建堆内存,代码停留在第 12 行 free(str) 打印 str 得到 0x7ffff720c010 这时候堆内存已分配成功。
现在让我们做释放操作,代码停留在 14 行,打印 str 可以看到值已被释放。
# 未分配
Temporary breakpoint 1, main () at b.c:5
5 char *str = (char *)malloc(8192 * 1024);
(gdb) p str
$1 = 0x0
(gdb) p &str
$2 = (char **) 0x7fffffffe368
(gdb) n
# 已分配
6 if (str == NULL) {
(gdb) n
10 printf("Heap memory application successed.");
(gdb) n
# 释放
12 free(str);
(gdb) p str
$3 = 0x7ffff720c010 ""
(gdb) n
13 str = NULL;
(gdb) n
14 return 0;
(gdb) p str
$4 = 0x0
(gdb) p &str
$5 = (char **) 0x7fffffffe368
总结
本文也是笔者在之前学习过程中的总结,近期又稍微整理下,发出来也是希望能与大家共同的分享、交流。
通过本文,几个常见的知识点:栈与堆的区别、为什么递归会造成栈溢出,类似于这种常见的问题,希望读者朋友能够掌握。
文章来源:微信公众号

