
一次搜索性能的排查过程和优化效果转载
一、现象描述
随着业务数据量的快速扩张,在日常监控下发现,搜索中心在高峰期容易出现告警。直至某一天,用户反馈搜索商品速度特别慢。针对此性能瓶颈,当时通过快速扩容临时予以了处置,但没有从根本上解决此问题。针对搜索低性能的问题,为彻底解决问题,解除性能束缚,展开了一次对搜索的性能排查和优化工作。
二、问题排查
搜索中心硬件配置资料:
-
ES 数据节点配置如下
-
配置:32 vCPU、128 GiB、1TB,磁盘吞吐 IO 350MB/s
通过 ES 监控排查定位发现,出现问题那段时间请求量突增,导致瞬间 ES 的磁盘 IO 到达瓶颈。而后 CPU 也出现高负荷,属于业务高峰期引发的雪崩现象。
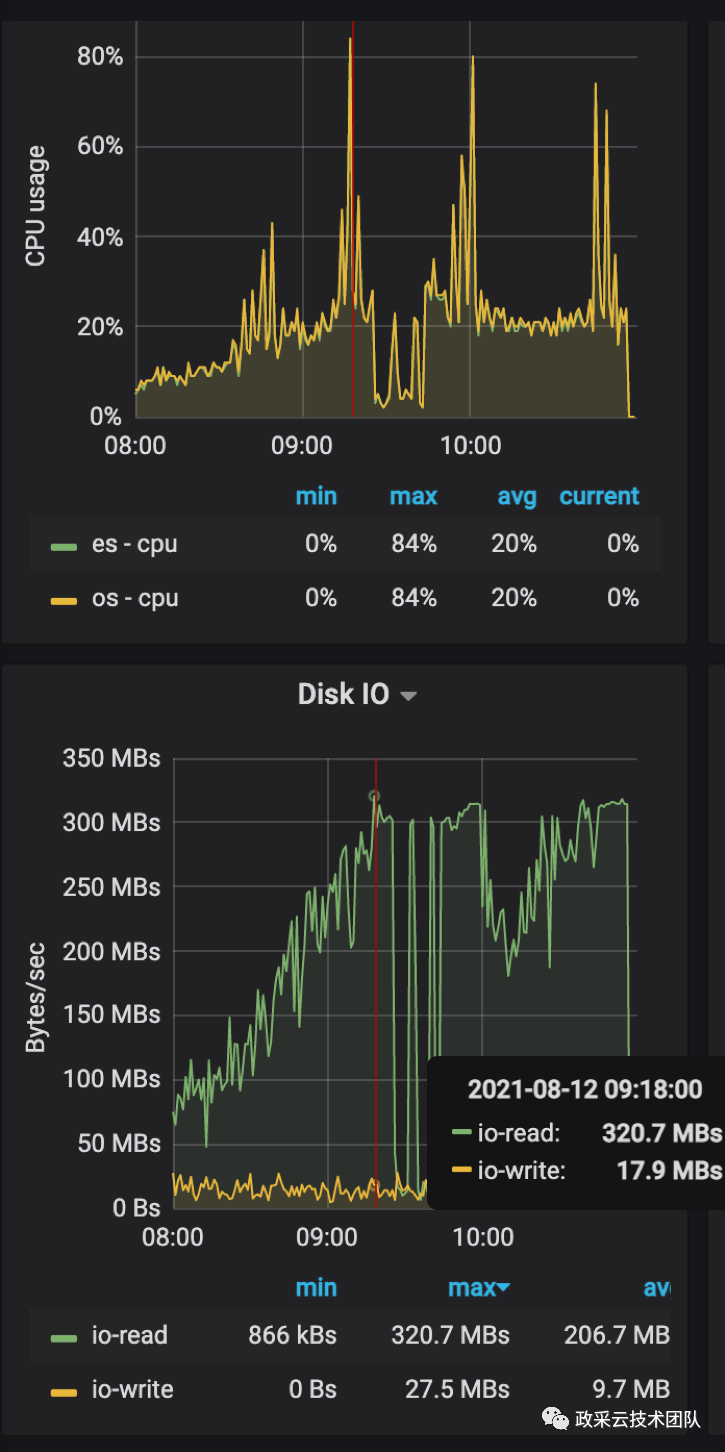
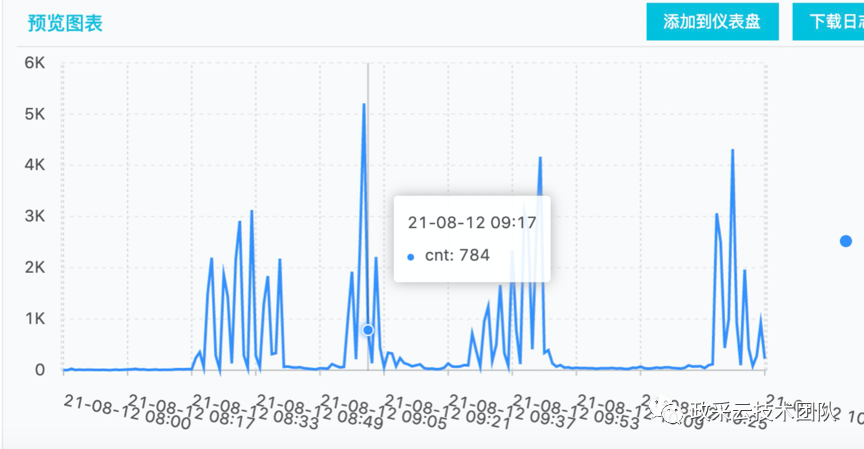
再从当时的搜索流量监控做分析,发现长尾词请求(关键词比较长的搜索请求)较以往出现很多。依据理论分析,长尾词请求也是对搜索的性能有一定程度的影响。
三、压测验证
为验证长尾词请求对性能的影响,针对此次问题,决定在线上生产环境对搜索系统进行压测,对当前搜索系统做性能评估。
对压测方案和脚本做了相应的准备,通过直接对搜索中心的 DUBBO 接口压测。压测请求,是将出现问题那段时间的线上环境,对应的请求体下载。在晚上业务低峰期,将白天在真线环境的请求,做为压测样本使用。这样也就保证了压测请求的真实有效性。
在压测过程中,采取逐渐增加并发请求数,从 10 -> 20-> 30 进行压测。且为保障系统稳定性,压测时间控制在 10 min 左右。
在实际压测过程中,发现:
-
随着并发数增大,所在的 ES 机器 CPU 并不高。
-
但 ES 所在机器磁盘 IO 越来越高,在 20 并发时,就接近了阈值。
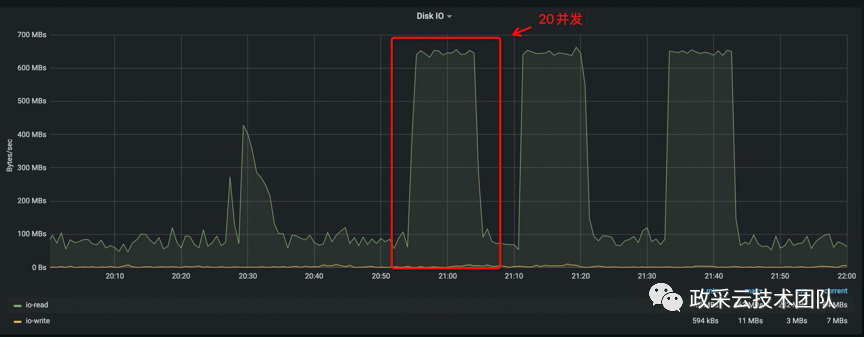
后续观察到:继续增加并发数,线程池的等待队列就会不断增加,堆积的请求会越来越多,而导致 CPU 也会越来越高。观察到现象,与线上出现的问题特征是一致的。从而,复现了问题的场景,找到了性能的瓶颈点。
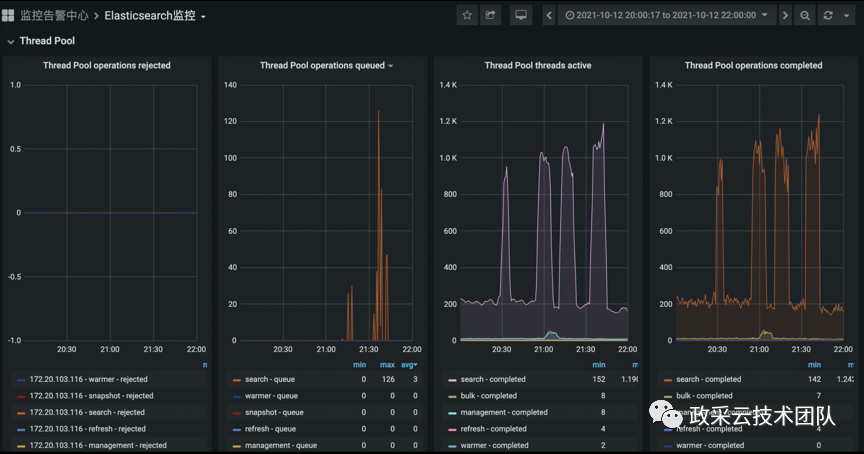
经过分析和对照,得出结论。此次压测结果与线上问题现象一致:性能瓶颈是在磁盘 IO 。
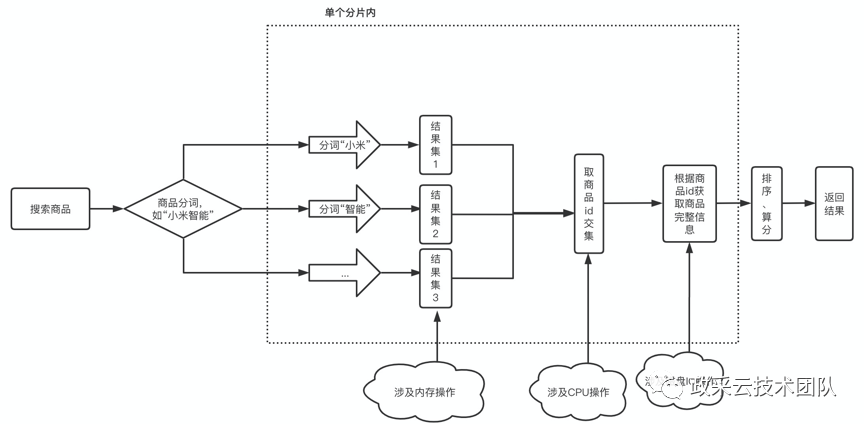
随后将搜索关键词的限制长度调小。在通过关键字搜索词汇时,搜索词会被切分成小粒度的词汇(分词)。分词越多,到 ES 文档查询次数就会越多。
比如“小米智能”,分词为“小米”“智能”,分别去 ES 文档用不同分词查询 2 次,最后取交集。随着搜索语句的长度增加,分词就会越多,不同分词拿到的结果集再去做取交集时 CPU 会有压力,这样就对搜索系统的性能构成了压力。
四、针对现状可以再做点什么
结合观察到的情况,并考虑到后续业务以及数据量发展,为提升系统性能,主要从以下 3 个可能的方向进行优化:
硬件资源优化
将当前 ES 集群的磁盘替换成本地 SSD 盘,且对配置做了变更。
-
替换后的 ES 数据节点:
-
配置:16 vCPU 、128 GiB 、2 * 1788 Gi ,磁盘吞吐 IO 1 GB/s
配置变更:
-
CPU上:32 核-> 16 核
-
磁盘上:350 MB/s -> 1 GB/s
为什么这么做呢?
1、数据表明,替换成本地 SSD 盘后对性能会有很大的提升。
从官方给出的磁盘性能数据
按目前配置做换算:
-
替换前:云盘:750 MB/s ,IOPS =51,800
-
替换后:本地 SSD:读:2GB/s ,写:1GB/s,IOPS= 300,000
(IOPS(Input/Output Operations Per Second)是一个用于计算机存储设备性能测试的量测方式,可以视为是每秒的读写次数。是衡量磁盘性能的主要指标之一。)
2、替换成本地 SSD 盘,可以减少网络消耗。因为在云盘上每次读写的网络消耗较本地盘来讲会比较高,换成本地 SSD 盘后理论也可以减少网络消耗。
另外配置上的变更:
1、CPU 配置从 32 核降为 16 核。因为从压测结果看 CPU 不是性能瓶颈,且按正常用户搜索词习惯,搜索词语并不会太长,且安全部门对搜索页面做了安全拦截,阻止了网络爬虫的威胁。CPU 上的降低成本可以加到磁盘配置扩充上。
2、磁盘吞吐配置升为 1GB/s 。因为系统瓶颈在磁盘 IO 上,给磁盘升配是必要的。且分析磁盘 IO 高的原因,从下图可以看出,搜索阶段通过商品 id 去 ES 索引获取商品完整信息时存在对磁盘 IO 操作,若索引中商品信息越大,磁盘读取大小越大,从而商品信息索引的大小影响磁盘吞吐的性能。(这个在第 2 步做了优化)
数据结构优化
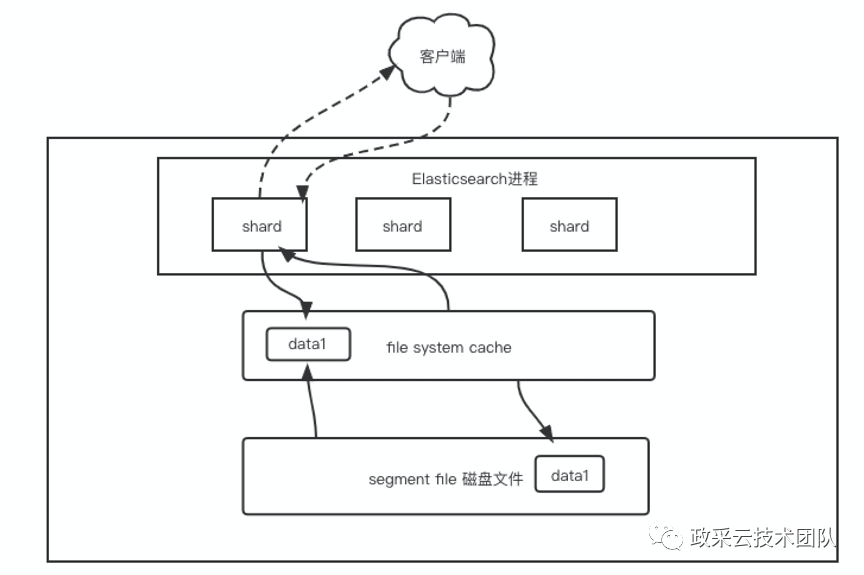
Elasticsearch 严重依赖文件系统缓存来加快搜索速度。通常,您应该确保至少有一半的可用内存进入文件系统缓存,以便 Elasticsearch可以将索引的热点区域保留在物理内存中。
针对数据方面,移除了 ES 中的多个大节点字段(原有业务节点占用特别大)。原索引大小有 900+GB,移除大节点后现索引大小到400+GB ,这部分移除的数据改用其他方式存储查询,不再占用关键的索引。
举一个例子:
如果公司ES节点有 3 台机器,每台机器内存为 64G,ES 集群的总内存就是 64 * 3 = 192G 。
每台机器给 ES 本身的JVM用 32G ,那么每台机器剩下来有 32G 可以留给 file system cache 。因此,ES 集群里给 file system cache 的就是 32 * 3=96G 的内存。
而此时,如果 ES 上索引数据有 1T ,那么每台机器的需要占用的数据量约 300G+ 。而每台机器上的 file system cache 的内存才 32G ,相当于约 10% 的数据可以放内存,其他的都在磁盘。然后执行搜索操作,大部分操作都是走了磁盘读取,磁盘 IO 会很高,因此性能会很受影响。
ES参数优化
在 ES 中每个 shard 每隔 1 秒都会 refresh 一次,每次 refresh 都会生成一个新的 Segment。每一个搜索请求都必须访问每一个Segment,这就意味着存在的 Segment 越多,搜索请求就会变的更慢。而 ES 有一个后台进程专门负责 Segment 的合并,它会把小Segment 合并成更大的 Segments。
目前系统中对 Segment 大小未验证过是否是最佳的阈值,所以期间也通过调整 Segment 大小来验证对性能的影响程度。
初步将 Segment 从 5G (默认值)-> 10G -> 15G 调整,利用相同并发数、压测样本进行压测。
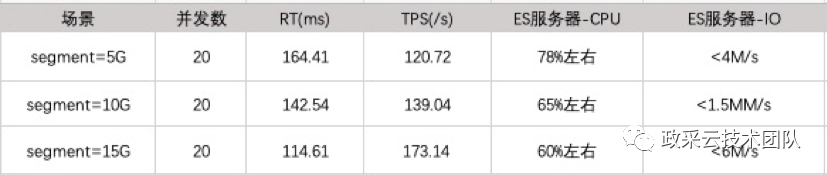
从上述的几次压测结果可以看出 Segment 越大,TPS 越高,性能会越好。
优化后再做压测
通过对搜索进行分析,并完成了下列几项优化:
-
将 ES 集群从 SSD 云盘升级成本地 SSD 磁盘,配置调优
-
数据结构优化,移除了索引中的大节点字段
-
ES 参数 Segment 大小调优
然后,再次采用与第 1 次相同的场景进行压测。然后基于升级前后性能指标、资源使用情况做比对。发现确实 ES 的磁盘 IO 明显降低,且 ES 的 CPU 比原先明显提升。
主要对比结果:
-
IO 方面:由于数据量大幅度缩减(本次缩减了约 60% ),绝大多数场景都直接走 OS-Page Cache ,磁盘 IO 使用降低了 99% ;
-
CPU 方面:CPU 使用率从 20% 提升到了 40% ;
-
内存方面:前后无基本差异,大部分都被 OS 页缓存使用;
五、总结
搜索业务的性能调优最终还是 ES 的性能调优,这涉及到了方方面面的优化。不仅包括服务器的配置,还包括了数据结构的优化,运行期基于业务需求的技术实现。对其的优化,需要依赖于对 ES 有足够深的理论了解和应用实践。实际过程中也需要根据系统的要求,进行偏向性的优化。通过对系统的深入研究,不断调优,才能保障搜索业务的稳定运行。
作者:政采云技术团队
文章来源:微信公众号

