
面试官:你给我说一下线程池里面的几把锁。原创
你好呀,我是歪歪。
最近有个读者给我说,面试聊到线程池的时候,相谈甚欢,基本都回答上来了,但是其中有一个问题直接把他干懵逼了。
面试官问他:你说一下线程池里面的锁吧。
结果他关于线程池的知识点其实都是在各个博客或者面经里面看到的,没有自己去翻阅过源码,也就根本就没有注意过线程池里面还有锁的存在。
他还给我抱怨:
他这么一说,我也觉得,好像大家聊到线程池的时候,都没有怎么聊到里面用到的锁。
确实是存在感非常低。
要不我就安排一下?

mainLock
其实线程池里面用到锁的地方还是非常的多的。
比如我之前说过,线程池里面有个叫做 workers 的变量,它存放的东西,可以理解为线程池里面的线程。
而这个对象的数据结构是 HashSet。
HashSet 不是一个线程安全的集合类,这你知道吧?
所以,你去看它上面的注释是怎么说的:

当持有 mainLock 这个玩意的时候,才能被访问。
就算我不介绍,你看名字也能感觉的到:如果没有猜测的话,那么 mainLock 应该是一把锁。
到底是不是呢,如果是的话,它又是个什么样子的锁呢?

在源码中 mainLock 这个变量,就在 workers 的正上方:

原来它的真身就是一个 ReentrantLock。
用一个 ReentrantLock 来保护一个 HashSet,完全没毛病。
那么 ReentrantLock 和 workers 到底是怎么打配合的呢?
我们还是拿最关键的 addWorker 方法来说:

用到锁了,那么必然是有什么东西需要被被独占起来的。
你再看看,你加锁独占了某个共享资源,你是想干什么?
绝大部分情况下,肯定是想要改变它,往里面塞东西,对不对?
所以你就按照这个思路分析,addWorker 中被锁包裹起来的这段代码,它到底在独占什么东西?
其实都不用分析了,这里面的共享数据一共就两个。两个都需要进行写入操作,这两共享数据,一个是workers 对象,一个是 largestPoolSize 变量。
workers 我们前面说了,它的数据结构是线程不安全的 HashSet。
largestPoolSize 是个啥玩意,它为什么要被锁起来?
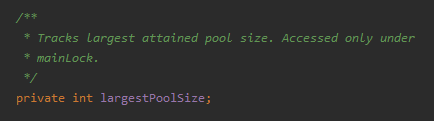
这个字段是用来记录线程池中,曾经出现过的最大线程数。
包括读取这个值的时候也是加了 mianLock 锁的:

其实我个人觉得这个地方用 volatile 修饰一下 largestPoolSize 变量,就可以省去 mainLock 的上锁操作。
同样也是线程安全的。
不知道你是不是也是这样觉得的?
如果你也是这样想的话,不好意思,你想错了。
在线程池里面其他的很多字段都用到了 volatile:

为什么 largestPoolSize 不用呢?
你再看一下前面 getLargestPoolSize 方法获取值的地方。
如果修改为 volatile,不上锁,就少了一个 mainLock.lock() 的操作。
去掉这个操作,就有可能少了一个阻塞等待的操作。
假设 addWorkers 方法还没来得及修改 largestPoolSize 的值,就有线程调用了 getLargestPoolSize 方法。
由于没阻塞,直接获取到的值,只是那一瞬间的 largestPoolSize,不是一定是 addWorker 方法执行完成后的
加上阻塞,程序是能感知到 largestPoolSize 有可能正在发生变化,所以获取到的一定是 addWorker 方法执行完成后的 largestPoolSize。
所以我理解加锁,是为了最大程度上保证这个参数的准确性。
除了前面说的几个地方外,还是有很多 mainLock 使用的地方:

我就不一一介绍了,你得自己去翻一翻,这玩意介绍起来也没啥意思,都是一眼就能瞟明白的代码。
说个有意思的。
你有没有想过这里 Doug Lea 老爷子为什么用了线程不安全的 HashSet,配合 ReentrantLock 来实现线程安全呢?
为什么不直接搞一个线程安全的 Set 集合,比如用这个玩意 Collections.synchronizedSet?
答案其实在前面已经出现过了,只是我没有特意说,大家没有注意到。
就在 mainLock 的注释上写着:

我捡关键的地方给你说一下。
首先看这句:
While we could use a concurrent set of some sort, it turns out to be generally preferable to use a lock.
这句话是个倒装句,应该没啥生词,大家都认识。
其中有个 it turns out to be,可以介绍一下,这是个短语,经常出现在美剧里面的对白。
翻译过来就是四个字“事实证明”。
所以,上面这整句话就是这样的:虽然我们可以使用某种并发安全的 set 集合,但是事实证明,一般来说,使用锁还是比较好的。
接下来老爷子就要解释为什么用锁比较好了。
我翻译上这句话的意思就是我没有乱说,都是有根据的,因为这是老爷子亲自解释的为什么他不用线程安全的 Set 集合。
第一个原因是这样说的:
Among the reasons is that this serializes interruptIdleWorkers, which avoids unnecessary interrupt storms, especially during shutdown. Otherwise exiting threads would concurrently interrupt those that have not yet interrupted.
英文是的,我翻译成中文,加上自己的理解是这样的。
首先第一句里面有个 “serializes interruptIdleWorkers”,这两个单词组合在一起还是有一定的迷惑性的。
serializes 在这里,并不是指我们 Java 中的序列化操作,而是需要翻译为“串行化”。
interruptIdleWorkers,这玩意根本就不是一个单词,这是线程池里面的一个方法:

在这个方法里面进来第一件事就是拿 mainLock 锁,然后尝试去做中断线程的操作。
由于有 mainLock.lock 的存在,所以多个线程调用这个方法,就被 serializes 串行化了起来。
串行化起来的好处是什么呢?
就是后面接着说的:避免了不必要的中断风暴(interrupt storms),尤其是调用 shutdown 方法的时候,避免退出的线程再次中断那些尚未中断的线程。
为什么这里特意提到了 shutdown 方法呢?
因为 shutdown 方法调用了 interruptIdleWorkers:
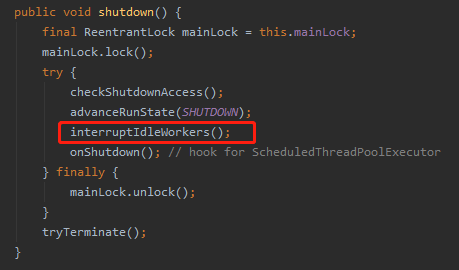
所以上面啥意思呢?
这个地方就要用一个反证法了。
假设我们使用的是并发安全的 Set 集合,不用 mainLock。
这个时候有 5 个线程都来调用 shutdown 方法,由于没有用 mainLock ,所以没有阻塞,那么每一个线程都会运行 interruptIdleWorkers。
所以,就会出现第一个线程发起了中断,导致 worker ,即线程正在中断中。第二个线程又来发起中断了,于是再次对正在中断中的中断发起中断。
额,有点像是绕口令了。
所以我打算重复一遍:对正在中断中的中断,发起中断。
因此,这里用锁是为了避免中断风暴(interrupt storms)的风险。
并发的时候,只想要有一个线程能发起中断的操作,所以锁是必须要有的。有了锁这个大前提后,反正 Set 集合也会被锁起来,索性就不需要并发安全的 Set 了。
所以我理解,在这里用 mainLock 来实现串行化,同时保证了 Set 集合不会出现并发访问的情况,因此,不需要并发安全的 Set 集合。
记住了,有可能会被考哦。
然后,老爷子说的第二个原因:
It also simplifies some of the associated statistics bookkeeping of largestPoolSize etc.
这句话就是说的关于加锁好维护 largestPoolSize 这个参数,不再贅述了。
哦,对了,这是有个 etc,表示“诸如此类”的意思。
这个 etc 指的就是这个 completedTaskCount 参数,道理是一样的:

另一把锁
除了前面说的 mainLock 外,线程池里面其实还有一把经常被大家忽略的锁。
那就是 Worker 对象。
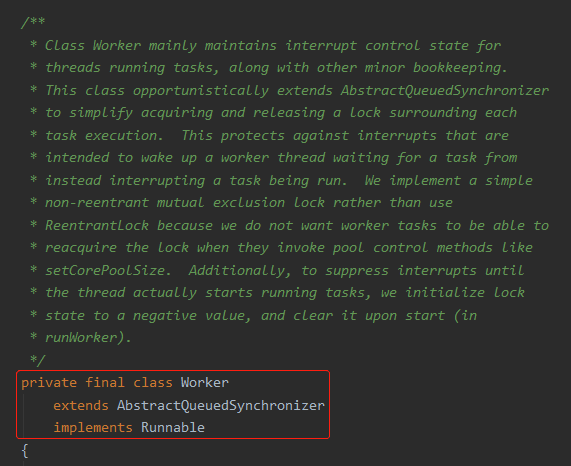
可以看到 Worker 是继承自 AQS 对象的,它的很多方法也是和锁相关的。
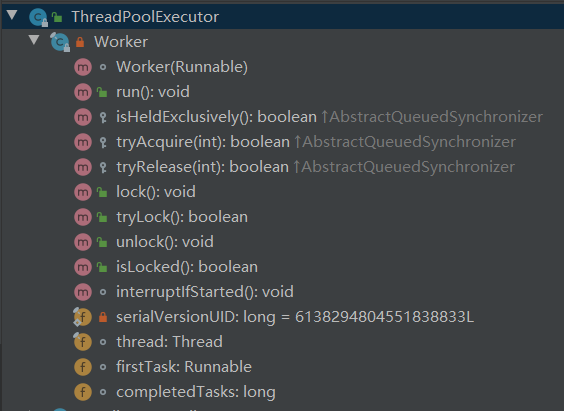
同时它也实现了 Runnable 方法,所以说到底它就是一个被封装起来的线程,用来运行提交到线程池里面的任务,当没有任务的时候就去队列里面 take 或者 poll 等着,命不好的就被回收了。
我们还是看一下它加锁的地方,就在很关键的 runWorker 方法里面:
java.util.concurrent.ThreadPoolExecutor#runWorker
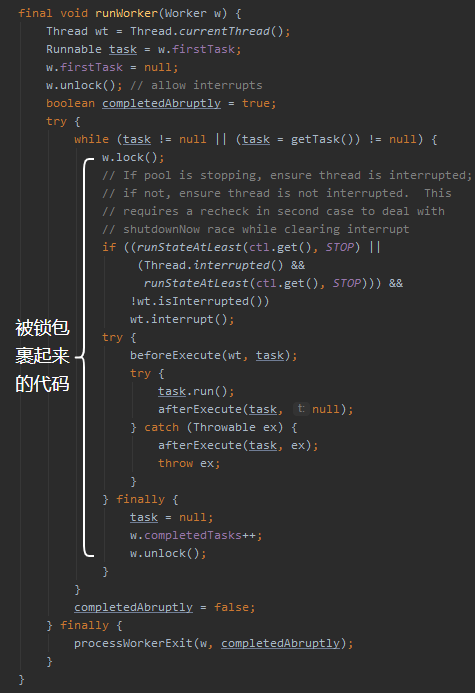
那么问题就来了:
这里是线程池里面的线程,正在执行提交的任务的逻辑的地方,为什么需要加锁呢?
这里为什么又自己搞了一个锁,而不用已有的 ReentrantLock ,即 mainLock 呢?
答案还是写在注释里面:
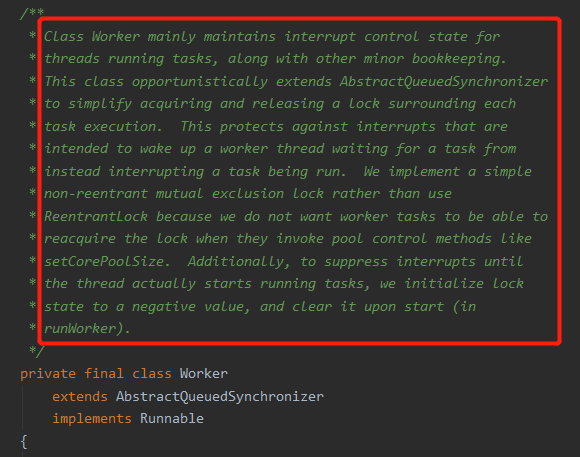
我知道你看着这么大一段英文瞬间就没有了兴趣。
但是别慌,我带你细嚼慢咽。
第一句话就开门见山的说了:
Class Worker mainly maintains interrupt control state for threads running tasks.
worker 类存在的主要意义就是为了维护线程的中断状态。
维护的线程也不是一般的线程,是 running tasks 的线程,也就是正在运行的线程。
怎么理解这个“维护线程的中断状态”呢?
你去看 Worker 类的 lock 和 tryLock 方法,都各自只有一个地方调用。
lock 方法我们前面说了,在 runWorker 方法里面调用了。
在 tryLock 方法是在这里调用的:

这个方法也是我们的老朋友了,前面刚刚才讲过,是用来中断线程的。
中断的是什么类型的线程呢?
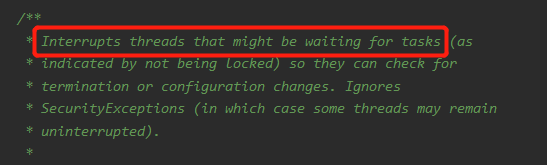
就是正在等待任务的线程,即在这里等着的线程:
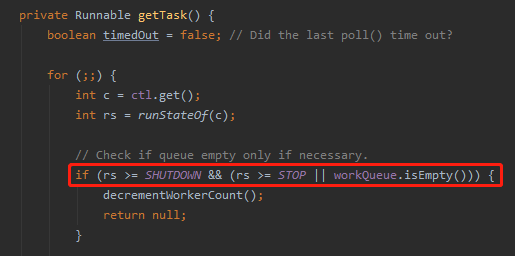
java.util.concurrent.ThreadPoolExecutor#getTask

换句话说:正在执行任务的线程是不应该被中断的。
那线程池怎么知道那哪任务是正在执行中的,不应该被中断呢?
我们看一下判断条件:

关键的条件其实就是 w.tryLock() 方法。
所以看一下 tryLock 方法里面的核心逻辑是怎么样的:
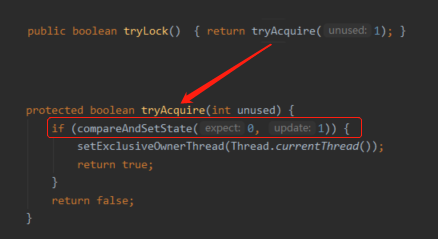
核心逻辑就是一个 CAS 操作,把某个状态从 0 更新为 1,如果成功了,就是 tryLock 成功。
“0”、“1” 分别是什么玩意呢?
注释,答案还是在注释里面:
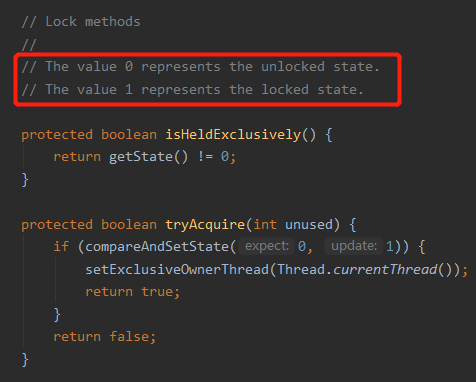
所以,tryLock 中的核心逻辑compareAndSetState(0, 1),就是一个上锁的操作。
如果 tryLock 失败了,会是什么原因呢?
肯定是此时的状态已经是 1 了。
那么状态什么时候变成 1 呢?
一个时机就是执行 lock 方法的时候,它也会调用 tryAcquire 方法。
那 lock 是在什么时候上锁的呢?
runWorker 方法里面,获取到 task,准备执行的时候。
也就是说状态为 1 的 worker 肯定就是正在执行任务的线程,不可以被中断。
另外,状态的初始值被设置为 -1。
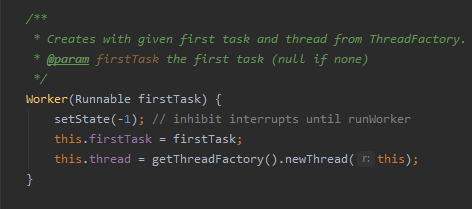
我们可以写个简单的代码,验证一下上面的三个状态:

首先我们定义一个线程池,然后调用 prestartAllCoreThreads 方法把所有线程都预热起来,让它们处于等待接收任务的状态。
你说这个时候,三个 worker 的状态分别是什么?

那必须得是 0 ,未上锁的状态。
当然了,你也有可能看到这样的局面:

-1 是从哪里来的呢?
别慌,我等下给你讲,我们先看看 1 在哪呢?
按照之前的分析,我们只需要往线程池里面提交一个任务即可:

这个时候,假如我们调用 shutdown 呢,会发什么?
当然是中断空闲的线程了。
那正在执行任务的这个线程怎么办呢?
因为是个 while 循环,等到任务执行完成后,会再次调用 getTask 方法:
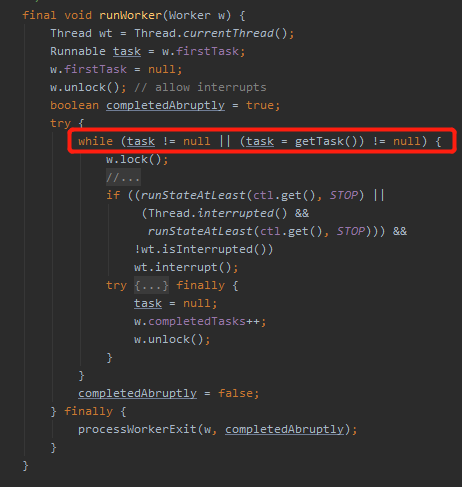
getTask 方法里面会先判断线程池状态,这个时候就能感知到线程池关闭了,返回 null,这个 worker 也就默默的退出了。
好了,前面说了这么多,你只要记住一个大前提:自定义 worker 类的大前提是为了维护中断状态,因为正在执行任务的线程是不应该被中断的。
接着往下看注释:
We implement a simple non-reentrant mutual exclusion lock rather than use ReentrantLock because we do not want worker tasks to be able to reacquire the lock when they invoke pool control methods like setCorePoolSize.
这里解释了为什么老爷子不用 ReentrantLock 而是选择了自己搞一个 worker 类。
因为他想要的是一个不能重入的互斥锁,而 ReentrantLock 是可以重入的。
从前面分析的这个方法也能看出来,是一个非重入的方法:
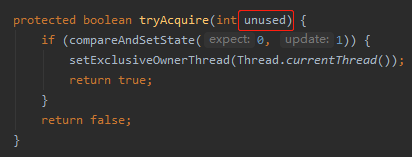
传进来的参数根本没有使用,代码里面也没有累加的逻辑。
如果你还没反应过来是怎么回事的话,我给你看一下 ReentrantLock 里面的重入逻辑:

你看到了吗,有一个累加的过程。
释放锁的时候,又有一个与之对应的递减的过程,减到 0 就是当前线程释放锁成功:
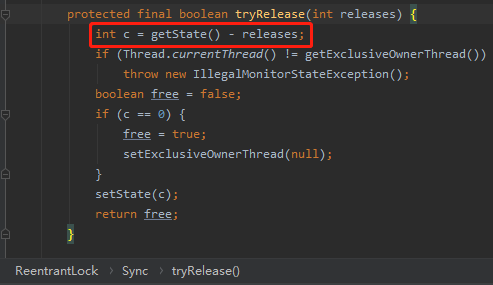
而上面的累加、递减的逻辑在 worker 类里面通通是没有的。
那么问题又来了:如果是可以重入的,会发生什么呢?
目的还是很前面一样:不想打断正在执行任务的线程。
同时注释里面提到了一个方法:setCorePoolSize。
你说巧不巧,这个方法我之前写线程池动态调整的时候重点讲过呀:
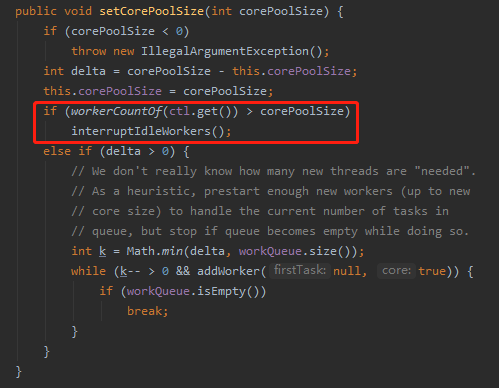
可惜当时主要讲 delta>0 里面的的逻辑去了。
现在我们看一下我框起来的地方。
workerCountOf(ctl.get()) > corePoolSize 为 true 说明什么情况?
说明当前的 worker 的数量是多余我要重新设置的 corePoolSize,需要减少一点。
怎么减少呢?
调用 interruptIdleWorkers 方法。
这个方法我们前面刚刚分析了,我再拿出来一起看一下:
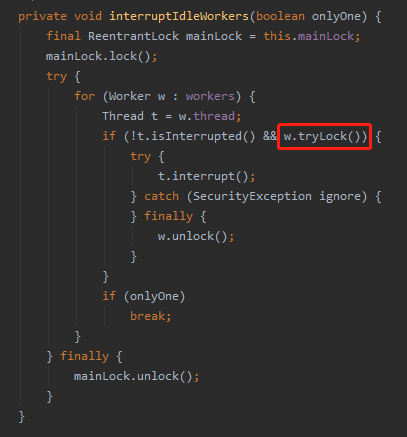
里面有个 tryLock,如果是可以重入的,会发生什么情况?
是不是有可能把正在执行的 worker 给中断了。
这合适吗?

好了,注释上的最后一句话:
Additionally, to suppress interrupts until the thread actually starts running tasks, we initialize lock state to a negative value, and clear it upon start (in runWorker).
这句话就是说为了在线程真正开始运行任务之前,抑制中断。所以把 worker 的状态初始化为负数(-1)。
大家要注意这个:and clear it upon start (in runWorker).
在启动的时候清除 it,这个 it 就是值为负数的状态。
老爷子很贴心,把方法都给你指明了:in runWorker.
所以你去看 runWorker,你就知道为什么这里上来先进行一个 unLock 操作,后面跟着一个 allow interrupts 的注释:

因为在这个地方,worker 的状态可能还是 -1 呢,所以先 unLock,把状态刷到 0 去。
同时也就解释了前面我没有解释的 -1 是哪里来的:
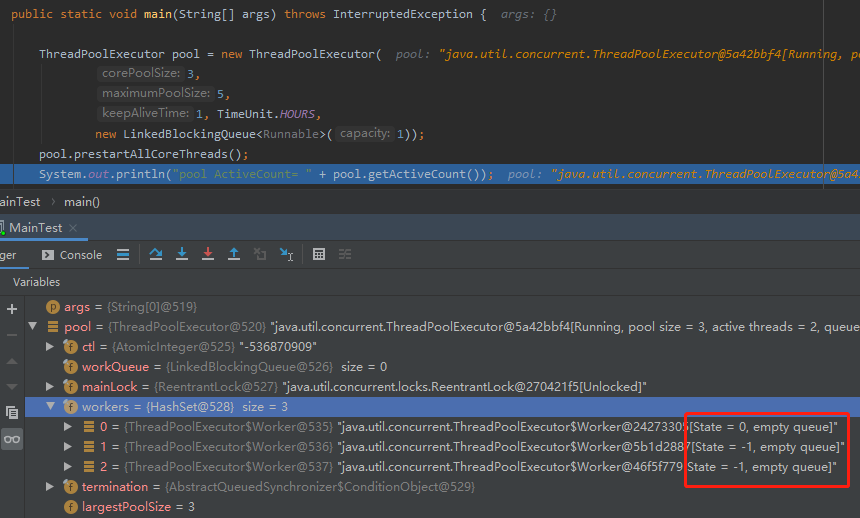
想明白了吗,-1 是哪里来的?
肯定是在启动过程中,执行了 workers.add 方法,但是还没有来得及执行 runWorker 方法的 worker 对象,它们的状态就是 -1。



