
过早提升(Premature Promotion)
提升速率(promotion rate), 用于衡量单位时间内从年轻代提升到老年代的数据量。一般使用 MB/sec 作为单位, 和分配速率类似。
JVM会将长时间存活的对象从年轻代提升到老年代。根据分代假设, 可能存在一种情况, 老年代中不仅有存活时间长的对象,也可能有存活时间短的对象。这就是过早提升:对象存活时间还不够长的时候就被提升到了老年代。
major GC 不是为频繁回收而设计的, 但 major GC 现在也要清理这些生命短暂的对象, 就会导致GC暂停时间过长。这会严重影响系统的吞吐量。
如何测量提升速率
可以指定JVM参数 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps , 通过GC日志来测量提升速率. JVM记录的GC暂停信息如下所示:
0.291: [GC (Allocation Failure)
[PSYoungGen: 33280K->5088K(38400K)]
33280K->24360K(125952K), 0.0365286 secs]
[Times: user=0.11 sys=0.02, real=0.04 secs]
0.446: [GC (Allocation Failure)
[PSYoungGen: 38368K->5120K(71680K)]
57640K->46240K(159232K), 0.0456796 secs]
[Times: user=0.15 sys=0.02, real=0.04 secs]
0.829: [GC (Allocation Failure)
[PSYoungGen: 71680K->5120K(71680K)]
112800K->81912K(159232K), 0.0861795 secs]
[Times: user=0.23 sys=0.03, real=0.09 secs]从上面的日志可以得知: GC之前和之后的 年轻代使用量以及堆内存使用量。这样就可以通过差值算出老年代的使用量。GC日志中的信息可以表述为:
| Event | Time | Young decreased | Total decreased | Promoted | Promotion rate |
|---|---|---|---|---|---|
| (事件) | (耗时) | (年轻代减少) | (整个堆内存减少) | (提升量) | (提升速率) |
| 1st GC | 291ms | 28,192K | 8,920K | 19,272K | 66.2 MB/sec |
| 2nd GC | 446ms | 33,248K | 11,400K | 21,848K | 140.95 MB/sec |
| 3rd GC | 829ms | 66,560K | 30,888K | 35,672K | 93.14 MB/sec |
| Total | 829ms | 76,792K | 92.63 MB/sec |
根据这些信息, 就可以计算出观测周期内的提升速率。平均提升速率为 92 MB/秒, 峰值为 140.95 MB/秒。
请注意, 只能根据 minor GC 计算提升速率。 Full GC 的日志不能用于计算提升速率, 因为 major GC 会清理掉老年代中的一部分对象。
提升速率的意义
和分配速率一样, 提升速率也会影响GC暂停的频率。但分配速率主要影响 minor GC, 而提升速率则影响 major GC 的频率。有大量的对象提升,自然很快将老年代填满。 老年代填充的越快, 则 major GC 事件的频率就会越高。
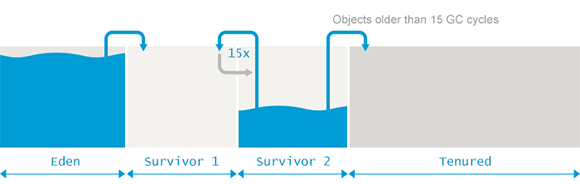
此前说过, full GC 通常需要更多的时间, 因为需要处理更多的对象, 还要执行碎片整理等额外的复杂过程。
示例
让我们看一个过早提升的示例。 这个程序创建/获取大量的对象/数据,并暂存到集合之中, 达到一定数量后进行批处理:
public class PrematurePromotion {
private static final Collection<byte[]> accumulatedChunks
= new ArrayList<>();
private static void onNewChunk(byte[] bytes) {
accumulatedChunks.add(bytes);
if(accumulatedChunks.size() > MAX_CHUNKS) {
processBatch(accumulatedChunks);
accumulatedChunks.clear();
}
}
}此 Demo 程序 受到过早提升的影响。下文将进行验证并给出解决办法。
过早提升的影响
一般来说,过早提升的症状表现为以下形式:
- 短时间内频繁地执行 full GC。
- 每次 full GC 后老年代的使用率都很低, 在10-20%或以下。
- 提升速率接近于分配速率。
要演示这种情况稍微有点麻烦, 所以我们使用特殊手段, 让对象提升到老年代的年龄比默认情况小很多。指定GC参数 -Xmx24m -XX:NewSize=16m -XX:MaxTenuringThreshold=1, 运行程序之后,可以看到下面的GC日志:
2.176: [Full GC (Ergonomics)
[PSYoungGen: 9216K->0K(10752K)]
[ParOldGen: 10020K->9042K(12288K)]
19236K->9042K(23040K), 0.0036840 secs]
2.394: [Full GC (Ergonomics)
[PSYoungGen: 9216K->0K(10752K)]
[ParOldGen: 9042K->8064K(12288K)]
18258K->8064K(23040K), 0.0032855 secs]
2.611: [Full GC (Ergonomics)
[PSYoungGen: 9216K->0K(10752K)]
[ParOldGen: 8064K->7085K(12288K)]
17280K->7085K(23040K), 0.0031675 secs]
2.817: [Full GC (Ergonomics)
[PSYoungGen: 9216K->0K(10752K)]
[ParOldGen: 7085K->6107K(12288K)]
16301K->6107K(23040K), 0.0030652 secs]乍一看似乎不是过早提升的问题。事实上,在每次GC之后老年代的使用率似乎在减少。但反过来想, 要是没有对象提升或者提升率很小, 也就不会看到这么多的 Full GC 了。
简单解释一下这里的GC行为: 有很多对象提升到老年代, 同时老年代中也有很多对象被回收了, 这就造成了老年代使用量减少的假象. 但事实是大量的对象不断地被提升到老年代, 并触发 full GC。
解决方案
简单来说, 要解决这类问题, 需要让年轻代存放得下暂存的数据。有两种简单的方法:
一是增加年轻代的大小, 设置JVM启动参数, 类似这样: -Xmx64m -XX:NewSize=32m, 程序在执行时, Full GC 的次数自然会减少很多, 只会对 minor GC的持续时间产生影响:
2.251: [GC (Allocation Failure)
[PSYoungGen: 28672K->3872K(28672K)]
37126K->12358K(61440K), 0.0008543 secs]
2.776: [GC (Allocation Failure)
[PSYoungGen: 28448K->4096K(28672K)]
36934K->16974K(61440K), 0.0033022 secs]二是减少每次批处理的数量, 也能得到类似的结果. 至于选用哪个方案, 要根据业务需求决定。在某些情况下, 业务逻辑不允许减少批处理的数量, 那就只能增加堆内存,或者重新指定年轻代的大小。
如果都不可行, 就只能优化数据结构, 减少内存消耗。但总体目标依然是一致的: 让临时数据能够在年轻代存放得下。



