
HeapDump性能社区专题系列一:了解数据库性能优化原创
数据库性能优化的目标是通过充分利用系统资源来最小化查询的响应时间。对这些资源的最佳利用包括最大限度地减少网络流量、磁盘 I/O 和 CPU 时间。这个目标只能通过理解数据的逻辑和物理结构、系统上使用的应用程序以及数据库的冲突使用如何影响性能来实现。实际上,数据库性能优化是一项系统工程,需要使用系统化分析方法,从硬件、软件和应用场景等多个相关联的维度深入分析、评估与优化,在数据库系统的架构阶段、设计阶段、开发阶段、部署阶段、运行阶段等各环节中去寻找性能问题的瓶颈和解决方案。
本文精选了HeapDump性能社区中的8篇数据库性能优化相关文章,这些文章内不仅包含了影响数据库性能的因素,数据库性能评估标准、优化方法的内容,还介绍了一些数据库设计原则和编程技巧,并且记录了一些或大或小的实战案例,帮助大家快速了解数据库性能优化,掌握一些实操技能。
1.带你重走 TiDB TPS 提升 1000 倍的性能优化之旅
作者:TiDB_Robot
作者介绍:TiDB是一个开源的NewSQL数据库,支持混合事务和分析处理(HTAP)工作负载。它与MySQL兼容,并且可以提供水平可扩展性、强一致性和高可用性。它主要由PingCAP公司开发和支持,并在Apache 2.0下授权。TiDB现已正式入驻HeapDump性能社区,未来将会分享更多数据库性能优化相关的优质文章。
文章链接:https://heapdump.cn/article/3021827
精彩导读:性能优化这个事情核心只有一句话,用户响应时间去哪儿了?性能优化很困难的原因在于,为了定位用户响应时间在各个模块的分布,需要对系统的各个部件进行测量和分析,从底层硬件,CPU、IO、网络到上层应用架构,应用代码跟数据库的交互方式都需要涉及。本文第一部分介绍了一下性能优化的通用的方法,第二部分讲了一个实际案例。
用户响应时间
性能优化的第一个概念是用户响应时间。用户响应时间是用户在使用一个业务系统的时候,发起一个请求,这个请求返回总体消耗的时间为用户响应时间。一个典型的用户响应时间的分布如下图:
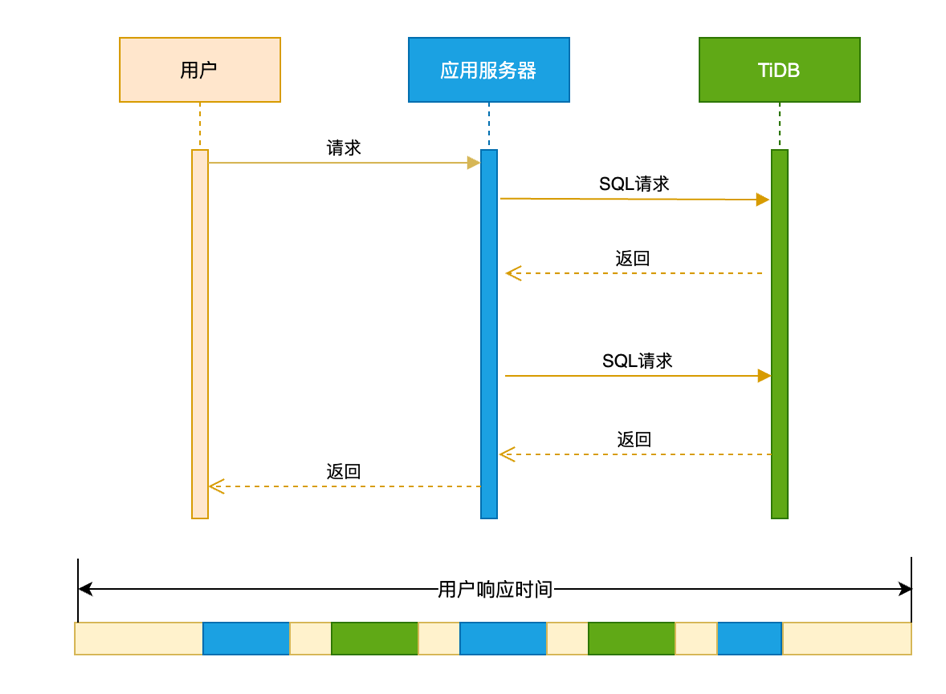
从时序图看,一个用户响应时间可能包括:
1.用户请求的到达应用服务器的网络时间
2.应用服务器本身业务逻辑处理时间
3.应用服务器跟数据库服务器之间交互消耗的网络的时间
4.数据库多次处理 SQL 的时间
5.应用服务器返回用户数据的网络时间
整个链路上来看,会涉及到网络、应用服务器和数据库这几个重要的部件。只要知道户响应时间在每个模块的分布,我们就能定位瓶颈,进行针对性的优化。
现实中性能瓶颈的定位又非常难。因为绝大部分的应用都没有去部署 APM 之类的工具,能够去跟踪一个应用请求在全链路上面的时间消耗。大部分场景的性能优化工作,都是在缺乏全局的时间分布情况下进行的。我们推荐的一种可靠的性能优化的方法:基于数据库时间进行性能优化。
数据库时间
数据库时间为单位时间内数据库提供的服务时间。对比数据库时间和应用总的用户响应时间,可以判断应用系统的瓶颈是否在数据库中。
一个应用系统,ΔT 时间内提供的总的服务时间,可以拿平均业务的 TPS 乘以平均的响应时间。ΔT 时间内的数据库时间,有多种算法:
1.平均 TPS X 平均事务延迟 X ΔT
2.平均的 QPS X 平均的延迟 X ΔT
3.平均的活跃连接数 X ΔT, 下图数据库活跃连接图的面积即为数据库时间
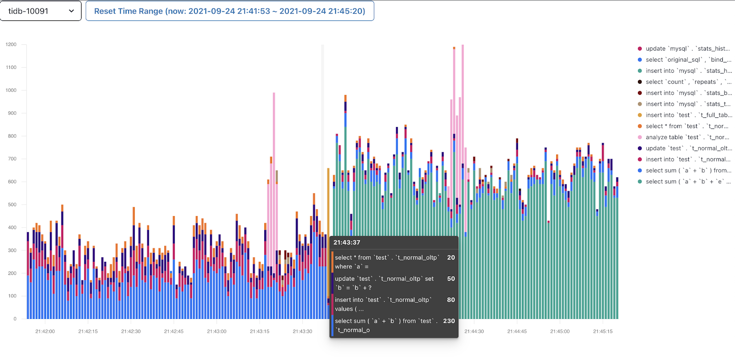
基于数据库时间和用户响应时间的对比,先从全局的角度判断瓶颈在数据库里面还是在数据库的外面,然后再进行针对性的排查和优化。把数据库时间除以总的用户响应时间:
趋近 0,数据库时间在总的服务时间里面是很小的占比,说明瓶颈并不在数据库中。
趋近 1,说明整个应用系统瓶颈是在数据库里面。工程师通过降低数据库时间来进行性能优化,比如优化 SQL 执行计划、解决数据库中存在的热点争用等。
2.5G时代,如何彻底搞定海量数据库的设计与实践
作者:孙玄|奈学教育
作者介绍:孙玄,现任奈学教育科技创始人&CEO ,毕业于浙大,前百度资深研发工程师、前 58 集团技术委员会主席/高级系统架构师到前转转公司技术委员会主席/首席架构师/大中后台技术负责人。江湖人称“玄姐”,出版过《百万年薪架构师修炼之路》书籍。
文章链接:https://heapdump.cn/article/761671
精彩导读:5G时代,业务数据越来越丰富,业务使用MySQL数据库作为后台存储,存储引擎使用InnoDB,会带来哪些挑战?如何针对公司业务特点及MySQL数据库特性,制定若干数据库使用规范供一线RD在设计业务时参考部分内容要求强制执行。本文从介绍MySQL相关关键基础架构,并结合实际案例介绍表和索引的设计技巧,并对规范中重点内容做详细解读。
小结:
1.自增主键性能不一定高,需要结合实际业务场景做分析;
2.大多数场景数据类型选择上尽量使用简单的类型;
3.索引不是越多越好,太多的索引会导致过大的索引文件;
4.如果要查询的数据可以在索引文件中找到,存储引擎就不会查找主键索引访问实际记录。
3.Mysql的sql优化方法
作者:臆想的一只猫
文章链接:https://heapdump.cn/article/2994366
精彩导读:本文总结了一些对mysql性能有利的编程技巧。
1、选择最合适的字段属性
2、尽量把字段设置为NOT NULL
3、使用连接(JOIN)来代替子查询(Sub-Queries)
4、使用联合(UNION)来代替手动创建的临时表
5、事务
6、锁定表
7、使用外键
8、使用索引
9、优化查询语句
4.一些比较好的Redis性能优化思路总结
作者:刘思宁
文章链接:https://heapdump.cn/article/2871512
精彩导读:在一些网络服务的系统中,Redis 的性能,可能是比 MySQL 等硬盘数据库的性能更重要的课题。比如微博,把热点微博,最新的用户关系,都存储在 Redis 中,大量的查询击中 Redis,而不走 MySQL。那么,针对 Redis 服务,我们能做哪些性能优化呢?或者说,应该避免哪些性能浪费呢?那么,针对 Redis 服务,我们能做哪些性能优化呢?或者说,应该避免哪些性能浪费呢?
在讨论优化之前,我们需要知道,Redis 服务本身就有一些特性,比如单线程运行。除非修改 Redis 的源代码,不然这些特性,就是我们思考性能优化的基本面。首先,Redis 使用操作系统提供的虚拟内存来存储数据。其次,Redis 支持持久化,可以把数据保存在硬盘上。第三,Redis 是用 key-value 的方式来读写的,而 value 中又可以是很多不同种类的数据;更进一步,一个数据类型的底层还有被存储为不同的结构。最后,在上面的介绍中没有提到的是,Redis 大多数时候是单线程运行的(single-threaded),即同一时间只占用一个 CPU,只能有一个指令在运行,并行读写是不存在的。
针对这些特性,概括了对Redis进行性能优化的几个切入点:优化网络延时;警惕执行时间长的操作;优化数据结构、使用正确的算法;考虑操作系统和硬件是否影响性能;考虑持久化带来的开销;使用分布式架构 —— 读写分离、数据分片。
5.千万级数据表选错索引导致的线上慢查询事故
作者:后端技术漫谈
文章链接:https://heapdump.cn/article/2166752
精彩导读:最近在线上环境遇到了一次SQL慢查询引发的数据库故障,影响线上业务。经过排查后,确定原因是「SQL在执行时,MySQL优化器选择了错误的索引(不应该说是“错误”,而是选择了实际执行耗时更长的索引)」。在排查过程中,查阅了许多资料,也学习了下MySQL优化器选择索引的基本准则,在本文中进行解决问题思路的分享。本人MySQL了解深度有限,如果错误欢迎理性讨论和指正。在这次事故中也能充分看出深入了解MySQL运行原理的重要性,这是遇到问题时能否独立解决问题的关键。
6.MySQL全面瓦解21(番外):一次深夜优化亿级数据分页的奇妙经历
作者:翁智华
文章链接:https://heapdump.cn/article/2869483
精彩导读:本次事故的情况是线上的一个查询数据的接口被疯狂的失去理智般的调用,这个操作直接导致线上的MySql集群被拖慢了。分析慢查询日志后发现,其实对于我们的MySQL查询语句来说,整体效率还是可以的,该有的联表查询优化都有,该简略的查询内容也有,关键条件字段和排序字段该有的索引也都在,问题在于他一页一页的分页去查询,查到越后面的页数,扫描到的数据越多,也就越慢。这种查询的慢,其实是因为limit后面的偏移量太大导致的。比如像上面的 limit 2000000,25 ,这个等同于数据库要扫描出 2000025条数据,然后再丢弃前面的 20000000条数据,返回剩下25条数据给用户,这种取法明显不合理。《高性能MySQL》第六章:查询性能优化,对这个问题有过说明:分页操作通常会使用limit加上偏移量的办法实现,同时再加上合适的order by子句。但这会出现一个常见问题:当偏移量非常大的时候,它会导致MySQL扫描大量不需要的行然后再抛弃掉。
7.Redis 高负载下的中断优化
作者:骁雄 春林
作者介绍:骁雄,14年加入美团点评,主要从事MySQL、Redis数据库运维,高可用和相关运维平台建设。春林,17年加入美团点评,毕业后一直深耕在运维线,从网络工程师到Oracle DBA再到MySQL DBA 多种岗位转变,现在美大主要职责Redis运维开发和优化工作。
文章链接:https://heapdump.cn/article/2842148
精彩导读:2017年年初以来,随着Redis产品的用户量越来越大,接入服 务越来越多,再加上美团点评Memcache和Redis两套缓存融合,Redis服务端的总体请求量从年初最开始日访问量百亿次级别上涨到高峰时段的万亿次级别,给运维和架构团队都带来了极大的挑战。原本稳定的环境也因为请求量的上涨带来了很多不稳定的因素,其中一直困扰我们的就是网卡丢包问题。起初线上存在部分Redis节点还在使用千兆网卡的老旧服务器,而缓存服务往往需要承载极高的查询量,并要求毫秒级的响应速度,如此一来千兆网卡很快就出现了瓶颈。经过整治,我们将千兆网卡服务器替换为了万兆网卡服务器,本以为可以高枕无忧,但是没想到,在业务高峰时段,机器也竟然出现了丢包问题,而此时网卡带宽使用还远远没有达到瓶颈。
8.记一次慢SQL优化
作者:艾小仙
作者介绍:艾小仙,前阿里P7技术专家。工作11年,做过开发、产品、运营,行业横跨互联网安全、电商、支付、金融、酒店、O2O等等,热衷于分享大厂面试经验、架构设计、中间件、算法、数据库等热门技术。微信公众号【艾小仙】粉丝数10w+,曾被各大技术社区公众号转载推荐。
文章链接:https://heapdump.cn/article/3058836
精彩导读:这是一个线上问题,从日志平台查询到的 SQL 执行情况,该 SQL 执行的时间为 11.146s,可以认定为是一个慢查询。整个情况来看,缓冲区大小、排序字段的数据长度、查询数据条数等都会影响查询性能。分析了整个排序过程,指导的优化思想就是尽量不使用using filesort,尤其是在排序的数据量比较大的时候,那么优化的方式就是尽量让查询出来的数据已经是排好序的,也就是合理使用联合索引以及覆盖索引。


