
记一次慢SQL优化原创
问题
这是一个线上问题,从日志平台查询到的 SQL 执行情况,该 SQL 执行的时间为 11.146s,可以认定为是一个慢查询,美化后的 SQL 如下:
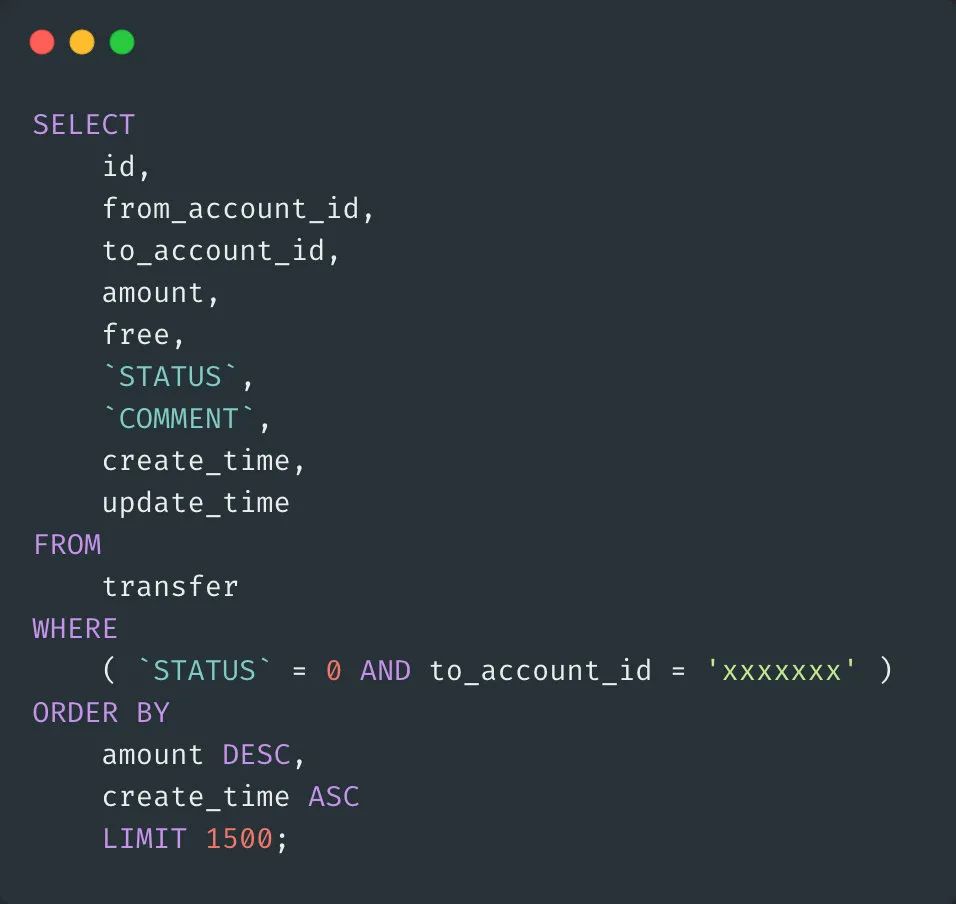
先找到这个表的定义以及索引情况如下:
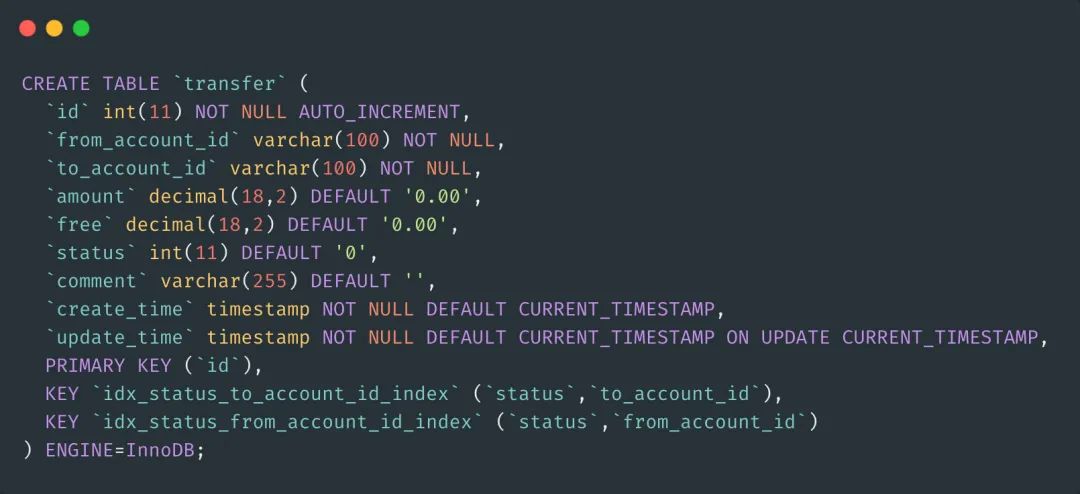
可见,主要有两个联合索引:status, to_account_id 和 status, from_account_id
问题分析
我们先用 explain 查看执行计划:

先看看explain的含义吧。
id :没什么就是ID而已,如果没有子查询的话,通常就一行。
select_type :大致分为简单查询和复杂查询两类,复杂查询又分为简单子查询,派生表(from中的子查询)和union。一般我们看见simple比较多,代表不包含子查询和union,如果有复杂查询则会标记成primary。
table :表名
type :表示关联类型,决定Mysql通过什么方式查找行数据。这个一般就是我们看查询时候的关键信息点。比如ALL就是全表扫描;index代表使用索引;range代表有限制的扫描索引,回比直接扫描全部索引好一些;ref也是索引查找,会返回匹配具体某个值的行数据,这个还有一些其他类型,比如eq_ref只返回符合的一条记录,const会进行优化转换成常量。
possible_keys :显示可以使用的索引,但不一定用。
key :实际使用到的索引。
key_len :索引使用的字节数。
ref :代表上面key一列中使用索引查找用到的列或者常量值。
rows :为了找到符合条件的数据读取的行数。
filtered :表示查询符合条件的数据占表的行数百分比,rows*filtered可以大致得到关联的行数,Mysql5.1之后新增的字段。
Extra :额外信息,比如using index表示使用覆盖索引,using where表示在存储引擎之后进行过滤,using temporary表示使用临时表,using filesort表示对结果进行外部排序。
基本上述的经验,我们看到索引和扫描行数其实都没啥问题,但是,我们发现执行计划中使用了 using filesort。
综合执行 SQL 和表定义,基本断定问题出在 ORDER BY amount desc, create_time asc,在生产线上数据记录较多,使用 order by 语句后引起 filesort,导致出现了外部排序,从而降低了 SQL 的查询性能。
再来理解一下 order by 的工作原理,帮助我们更好的做 SQL 优化。
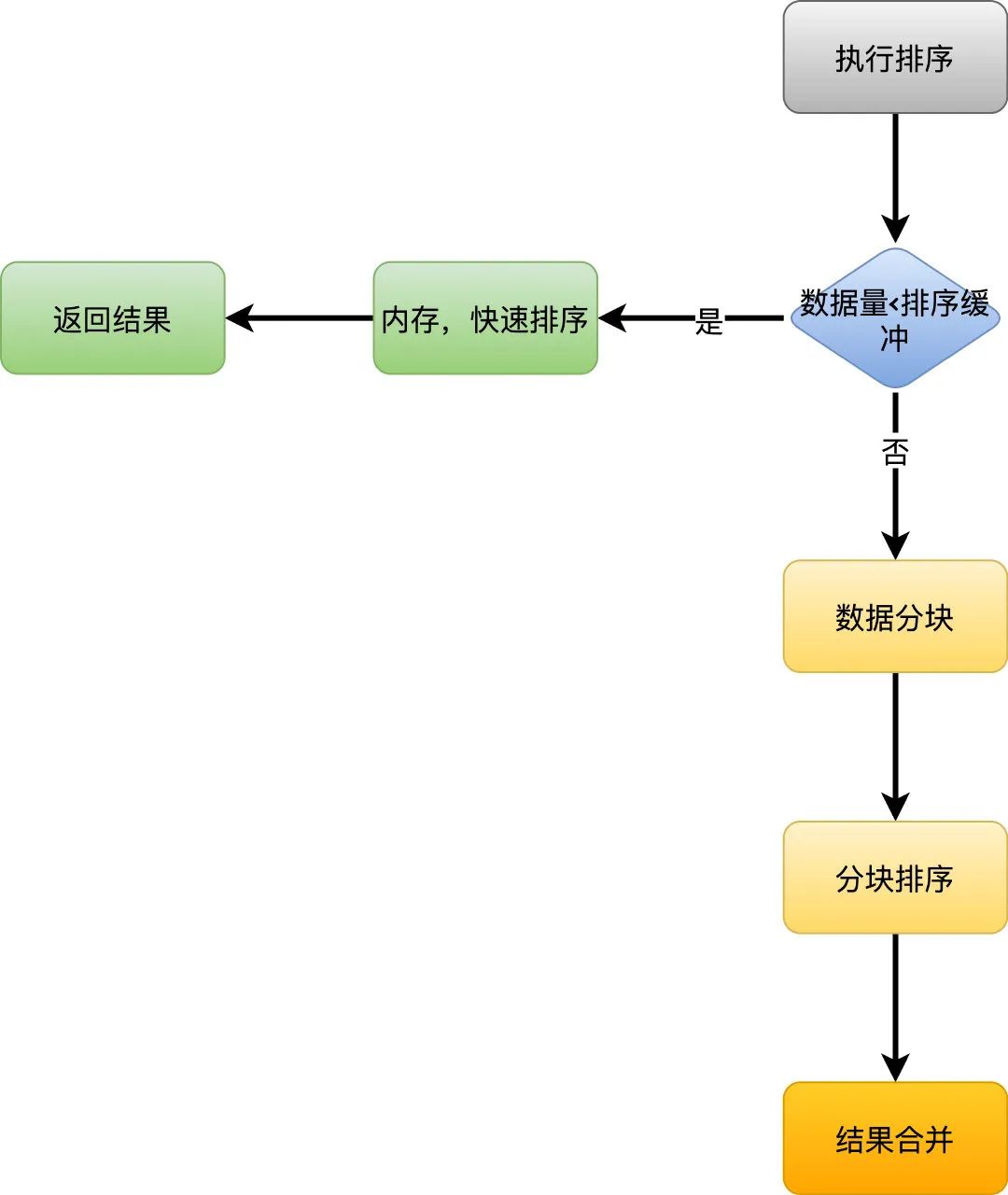
一般情况下,执行计划中如果出现using filesort 就会走如上的执行流程,对于Mysql来说,数据量小则在内存中进行排序,数据量大则需要在磁盘中排序,这个过程统一都叫做filesort。
-
首先根据索引找到对应的数据,然后把数据放入排序缓冲区中 -
如果要排序的数据实际大小没有超过缓冲区大小,就会使用内存排序,如快速排序,然后取出符合条件的数据返回 -
如果超过了缓冲区大小,就需要使用外部排序,算法一般使用多路归并排序,首先对数据分块,然后对每块数据进行排序,排序结果保存在磁盘中,最后将排序结果合并
除了知道排序的流程之外,排序使用的是字段的定义最大长度,而不是实际存储的长度,所以会花费更多的空间。
另外在5.6之前的版本,如果涉及到多表关联查询,排序字段来自不同表的话,会将关联结果保存到临时表中,这就是我们平时看到using temporary;using filesort的场景,如果这时候再使用limit,limit将会发生在排序之后,这样也可能导致排序的数据量非常大。
整个情况来看,缓冲区大小、排序字段的数据长度、查询数据条数等都会影响查询性能。
分析了整个排序过程,指导的优化思想就是尽量不使用using filesort,尤其是在排序的数据量比较大的时候,那么优化的方式就是尽量让查询出来的数据已经是排好序的,也就是合理使用联合索引以及覆盖索引。
优化方向
优化1:调整索引结构

优化2:代码结构优化

另外,我们发现一处代码,在 for 循环中做操作,然后更新 DB 表中的状态,这样会导致 1500 次的 DB 更新,可以考虑将 DB 的更新做批量处理,减少 DB 写的次数,比如 100 条记录执行一次 DB 更新,这样会大大降低写 db 的次数。
这样每次 方法调用,就会将 3000 次的写操作,降低为 30 次的写操作,当然批量的大小可以调节。
这里我们仅仅针对 SQL 调优,代码问题就暂时不考虑了。
性能结果
测试环境数据量在30万数据
-
优化前查询在 1.5s 以上 -
优化后查询在 0.4s 左右
查询性能提升 3~4 倍。
从生产的从库上查询看到数据量大概有3KW+,符合 where 条件的数据大概在300万左右
-
优化前查询在 11s ~ 14s
-
优化后查询在 0.8s 左右
性能提升10倍以上。
虽然这个优化比较简单,但是还是需要我们平时有扎实的基础才能选择最合理的方式进行优化。


