
带你重走 TiDB TPS 提升 1000 倍的性能优化之旅原创
今天我们来聊一下数据库的性能优化,第一部分简单介绍一下性能优化的通用的方法,第二部分我们讲一个实际案例。
性能优化这个事情核心只有一句话,用户响应时间去哪儿了?性能优化很困难的原因在于,为了定位用户响应时间在各个模块的分布,需要对系统的各个部件进行测量和分析,从底层硬件,CPU、IO、网络到上层应用架构,应用代码跟数据库的交互方式都需要涉及。
用户响应时间
性能优化的第一个概念是用户响应时间。用户响应时间是用户在使用一个业务系统的时候,发起一个请求,这个请求返回总体消耗的时间为用户响应时间。一个典型的用户响应时间的分布如下图:
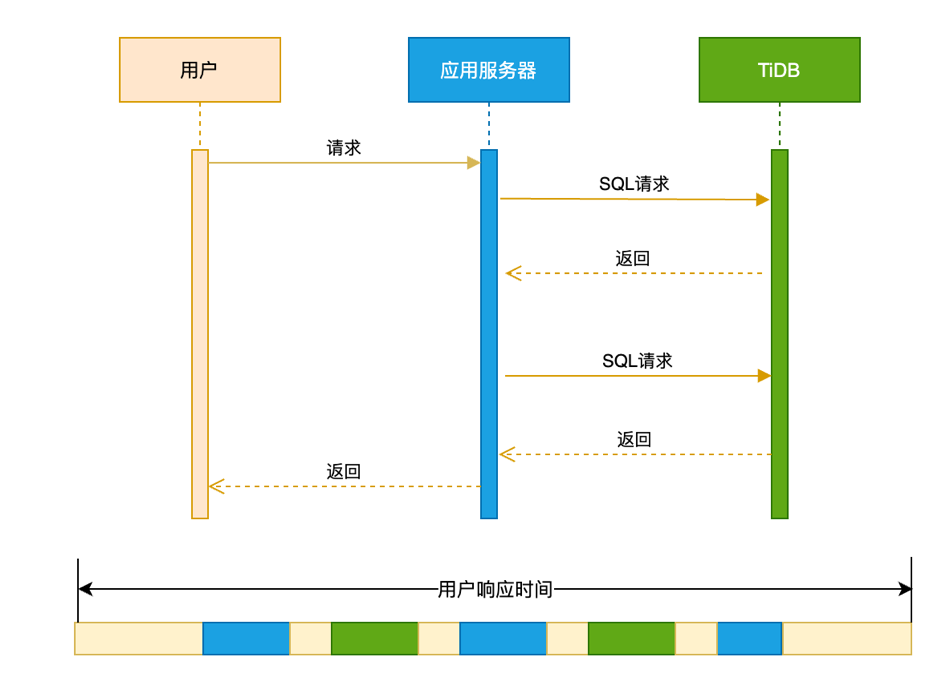
从时序图看,一个用户响应时间可能包括:
-
用户请求的到达应用服务器的网络时间
-
应用服务器本身业务逻辑处理时间
-
应用服务器跟数据库服务器之间交互消耗的网络的时间
-
数据库多次处理 SQL 的时间
-
应用服务器返回用户数据的网络时间
整个链路上来看,会涉及到网络、应用服务器和数据库这几个重要的部件。只要知道户响应时间在每个模块的分布,我们就能定位瓶颈,进行针对性的优化。
现实中性能瓶颈的定位又非常难。因为绝大部分的应用都没有去部署 APM 之类的工具,能够去跟踪一个应用请求在全链路上面的时间消耗。大部分场景的性能优化工作,都是在缺乏全局的时间分布情况下进行的。我们推荐的一种可靠的性能优化的方法:基于数据库时间进行性能优化。
数据库时间
数据库时间为单位时间内数据库提供的服务时间。对比数据库时间和应用总的用户响应时间,可以判断应用系统的瓶颈是否在数据库中。
一个应用系统,ΔT 时间内提供的总的服务时间,可以拿平均业务的 TPS 乘以平均的响应时间。ΔT 时间内的数据库时间,有多种算法:
-
平均 TPS X 平均事务延迟 X ΔT
-
平均的 QPS X 平均的延迟 X ΔT
-
平均的活跃连接数 X ΔT, 下图数据库活跃连接图的面积即为数据库时间
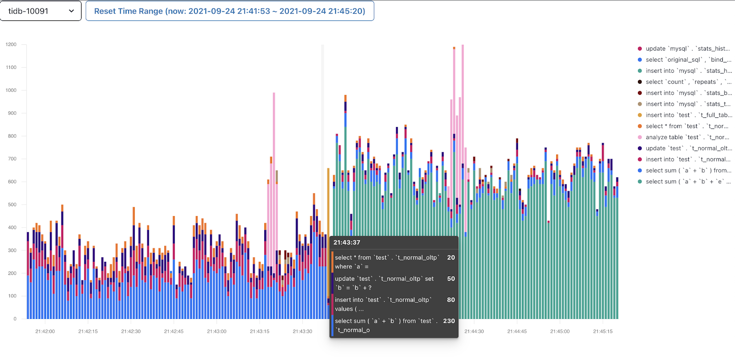
基于数据库时间和用户响应时间的对比,先从全局的角度判断瓶颈在数据库里面还是在数据库的外面,然后再进行针对性的排查和优化。把数据库时间除以总的用户响应时间:
趋近 0,数据库时间在总的服务时间里面是很小的占比,说明瓶颈并不在数据库中。
趋近 1,说明整个应用系统瓶颈是在数据库里面。工程师通过降低数据库时间来进行性能优化,比如优化 SQL 执行计划、解决数据库中存在的热点争用等。
实际案例
背景
这个例子是我们与合作伙伴一起完成的课题,银行核心应用在分布式数据库和国产 ARM 服务器上联合优化的案例。系统的硬件采用的是 ARM 服务器,每台服务器有 16 个 Numa,每台机器有一个 NVMe 盘。银行核心应用的负载属于 “Read Heavy”,查询语句占比 66%。本次应用涵盖 4 支混合交易。
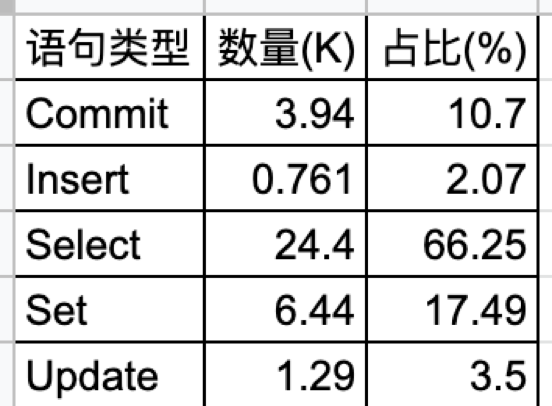
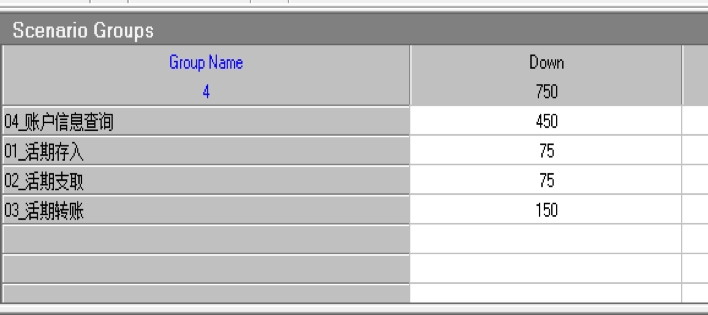
TPS 从 1 到 30
这个结果在合作伙伴的实验室跑起来之后,业务的 TPS 只有 1 左右,远低于预期。
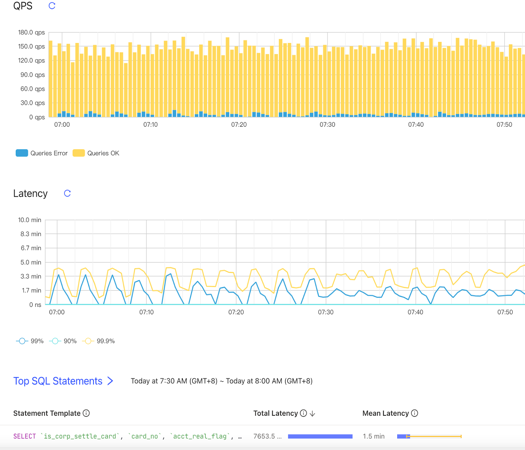
业务端会有超时的报错 (Coprocessor task terminated due to exceeding the deadline)。通常这种情况都是执行计划不优化造成的,比如说缺少索引,导致需要全表扫描。从 TiDB 的 Dashboard 上面会看到数据库的 QPS 只有 100 左右,80、90-in-txn 的延迟超过一分钟,再看 Top SQL,可以看到有 Top SQL 因为缺失索引在走全表扫描的。
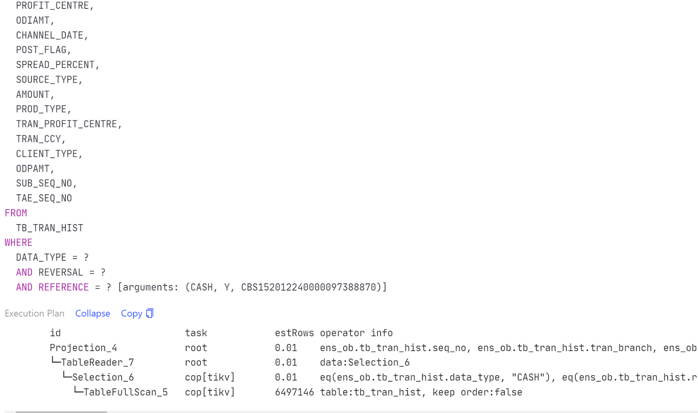
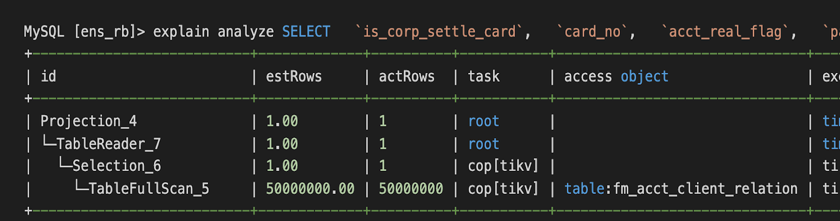
第一个 SQL 优化例子是解决索引缺失的问题,第二个 SQL 优化的例子是解决有索引却用不上的问题。因为业务系统上使用了 OR 条件,即使 OR 两端的过滤字段上都有索引,也默认走全面扫描。需要手工打开 index merge 功能 (set @@global.TiDB_enable_index_merge=on),执行计划才走索引。
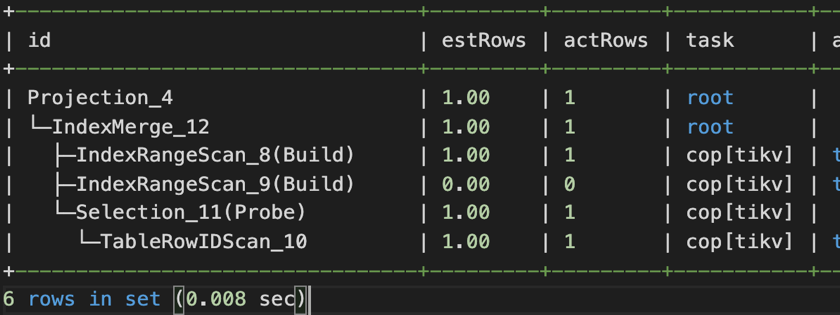
优化这两类慢 SQL 之后之后,TPS 上升到了 30 以上。
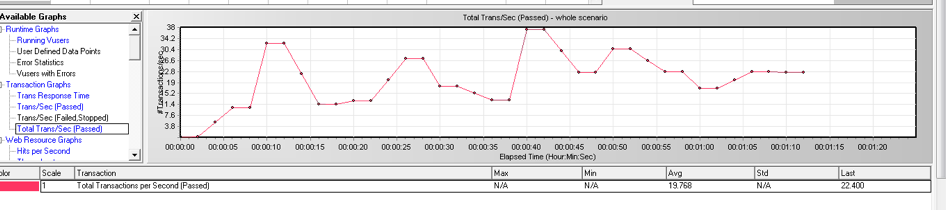
TPS 从 30 到 320
接着为了提高资源利用率,我们检查了一下集群的拓扑。测试环境是六台 ARM 服务器,每台16个 Numa,每个 Numa 是 8C 16GB。现有的拓扑部署了 3 个 TiDB + 3 个 TiKV。TiDB 是绑定到 0~4 的 Numa 上面,没有充分利用整个机器的能力。我们对这个组网的方式做了调整,部署了 36 个 TiDB + 6 个 TiKV,每个 TiDB 会绑两个 Numa ,每个 TiKV 有四个 Numa 。做了这个组网方式的修改之后,TPS 上升到了 320。
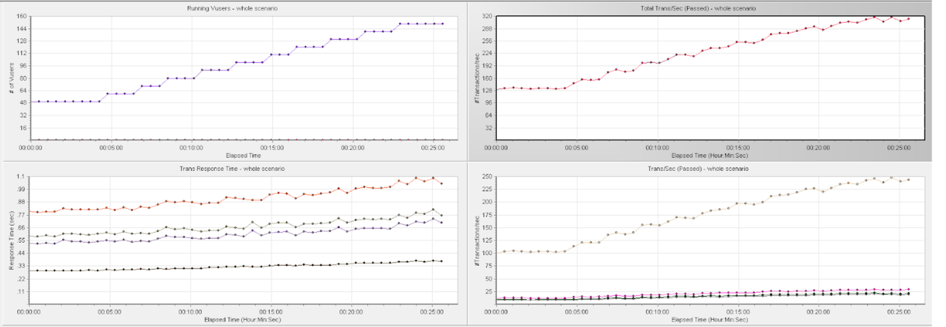
TPS 从 320 到 600
在 TPS 320 的压力下观察到一个现象是,数据库的 CPU 利用率比较低,每个 TiDB 虽然绑定了两个 Numa ,有 16 核的 CPU,但是 CPU 使用在 100% - 520%,用了 1-5个逻辑 CPU 左右。同时,应用服务器的 CPU 使用率不到 10%。query 80th 延迟是 3.84 毫秒。这是一种非常典型的情况,看起来数据库的压力不大,应用服务器的 CPU 利用率很小,但是总体的 TPS 上不去。目前硬件资源肯定是充足的,我们不确定整个系统的瓶颈在哪里。根据之前讲到的用户响应时间跟数据库时间的比例关系:
应用系统每秒响应时间:应用 TPS 300 乘以平均延迟 1 秒 = 300 秒 TiDB 每秒的数据库时间:QPS 30,000 乘以平均延迟 1.3 毫秒 = 39 秒
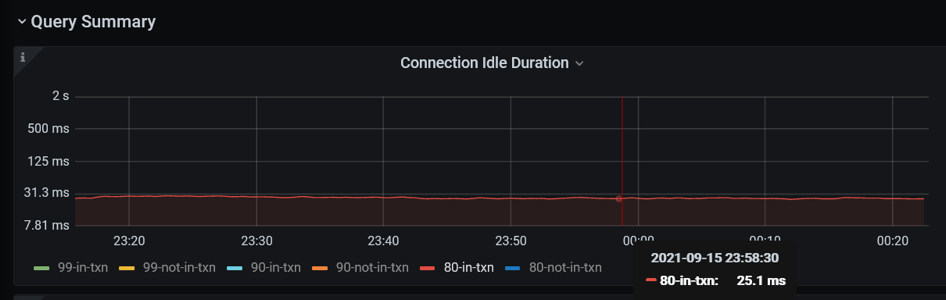
数据库时间只占用户响应时间 13%。在 TiDB 里面有更直观的方式,有一个指标叫 connection idle duration,指标记录一个应用连接提交 SQL 的间隔时间。这个例子,一个 SQL 的处理延迟 80 分位数为 3.84 毫秒,在事务里面提交 SQL 的间隔时间 80 分位数 25 毫秒。数据库花了将近 4 毫秒处理完一条 SQL 之后,他要等 25 毫秒才收到下一条 SQL。所以,很明显这个瓶颈不在数据库里面。
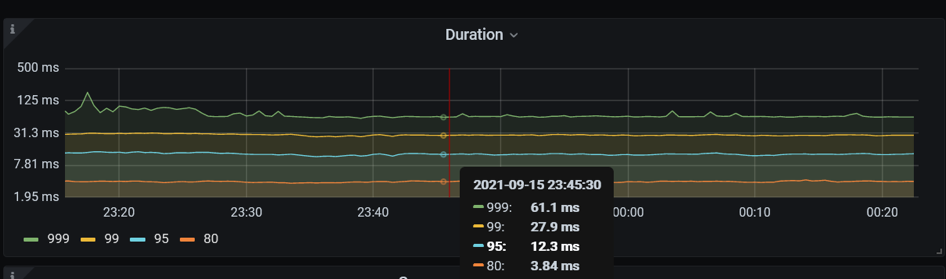
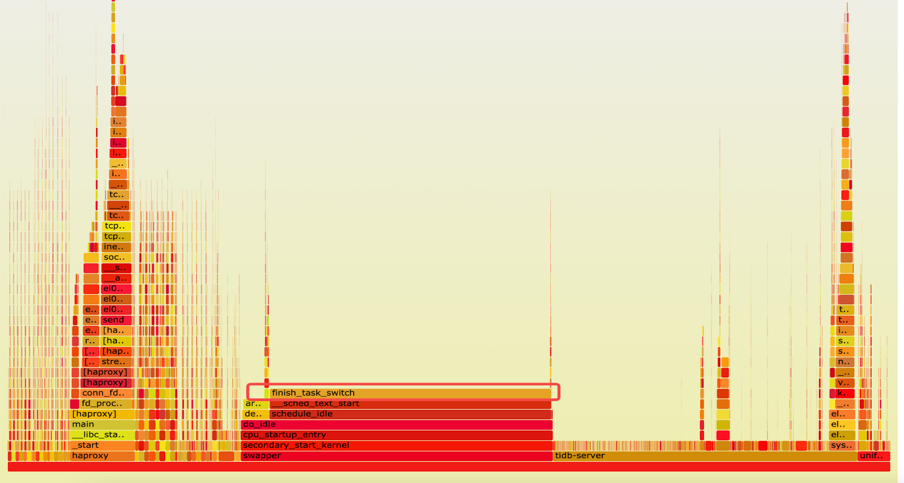
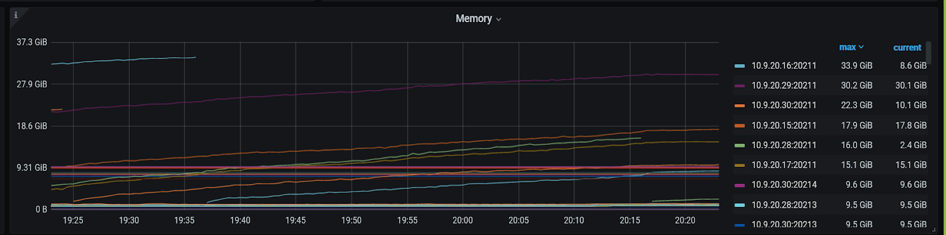
确认瓶颈不在数据库之后,我们对整体的火焰图和网络做了一些分析。由下方火焰图可见,整个系统的 CPU 20% 是消耗在一个叫 finish_task_switch 的,做进程切换,调度相关的系统调用上,说明系统在内核态存在资源争抢和串行点。因为有 16 个 Numa,每个 Numa 8 核,一共有 128 核,我们使用 mpstat -P ALL 5 命令对所有 CPU 的利用率进行确认,发现了一个比较有趣的现象 —— 所有的网卡的软中断(%soft),都打到了第一个 Numa(CPU 0-7)上。因为业务本身网络流量大,软中断处理(soft%)在 CPU 0-7 上使用率是 38% 到 94%。又因为我们在第一个 Numa 上面还跑着 TiDB、PD 和 Haproxy 等,用户 CPU (%usr)是 2% 到将近40%,第一个 Numa 的 CPU 都被打满了(%idle 接近 0)。其他的 Numa 使用率仅 55% 左右。跟 ARM 厂商机器的工程师聊过,确认 ARM 服务器默认出厂就会使用第一个 Numa 处理网卡软中断。网卡流量的处理瓶颈解释了 SQL 提交的间隔时间非常长的原因。
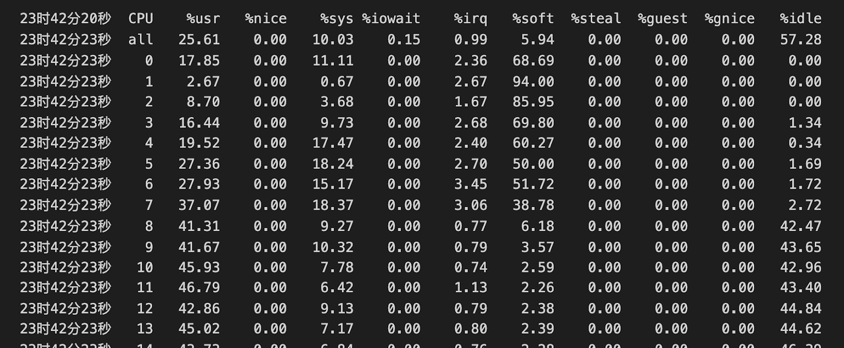
另外,对于没有绑核的程序 —— PD 和 Haproxy,我们在火焰图里面观察到关于内存的访问或者内存的加锁等系统调用占比非常高。对于开启 Numa 的系统,其实 CPU 访问内存的速度是不平等的。通常访问远端 Numa 的内存延迟是访问本地 Numa 内存的十倍。硬件厂商也推荐应用最好不要进行跨 Numa 部署,因为在 ARM 服务器进行跨 Numa 的内存访问,延迟会更高,极大的影响程序执行性能。
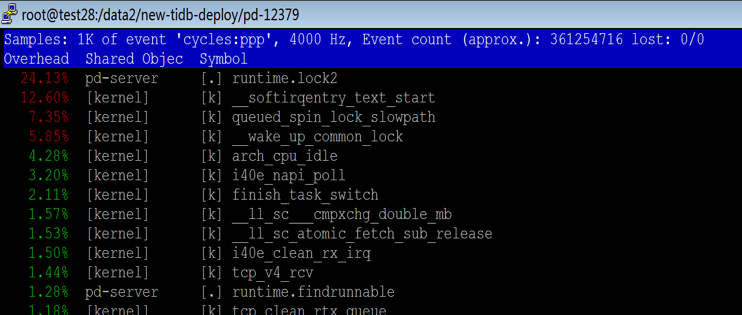
基于上面的分析,我们进行了组网方式的调整。对于六台机器,1)第一个 Numa 都空出来专门处理网络软中断,不跑任何的程序;2)所有的程序都需要绑核,每个 TiDB 只绑一个 Numa,TiDB 的数据翻倍, PD 和 Haproxy 也进行绑核。做了这个调整之后,应用的 TPS 上升到 600。Connection Idle duration 的 80-in-txn 延迟就从 26 毫秒下降到 5 毫秒。
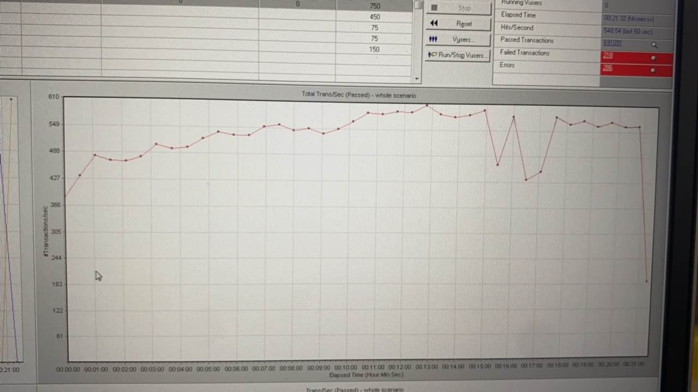
TPS 从 600 到 880
数据库最大连接数稳定在 2000,应用加大并发连接数也没有提升。使用 mysql 连接 Haproxy 地址会报错。因为 Haproxy 单个 proxy 后台 session 限制默认两千,通过把 Haproxy 从多线程模式改成了多进程的模式可以解除这个限制。变更之后连接数上升到 4400,TPS 上升到 880。
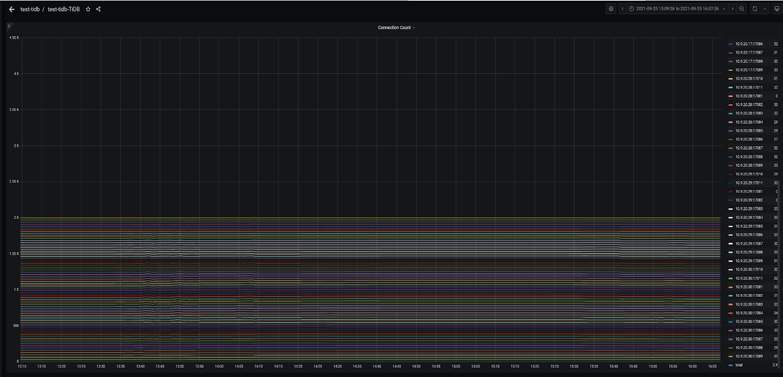
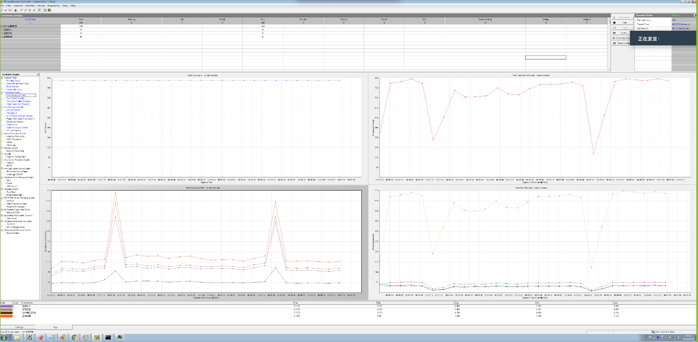
TPS 抖动解决
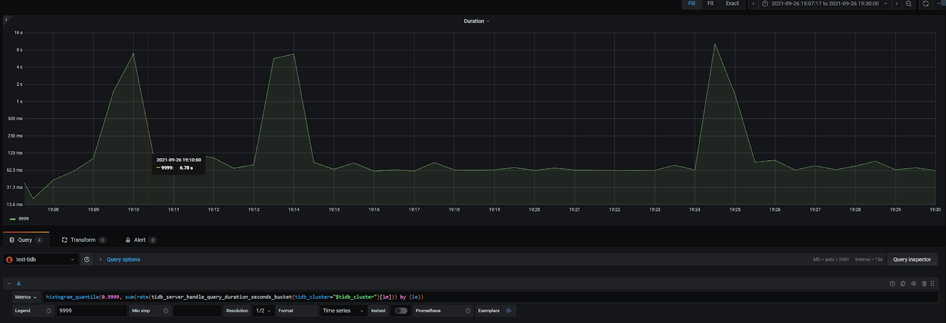
TPS 880 时应用出现明显的波动,事务处理延迟出现巨大的波动。从 Dashboard 中可以看到同样的 QPS 波动,P999 延迟在同样的时间出现小的尖刺。数据库是造成应用性能波动的原因吗?
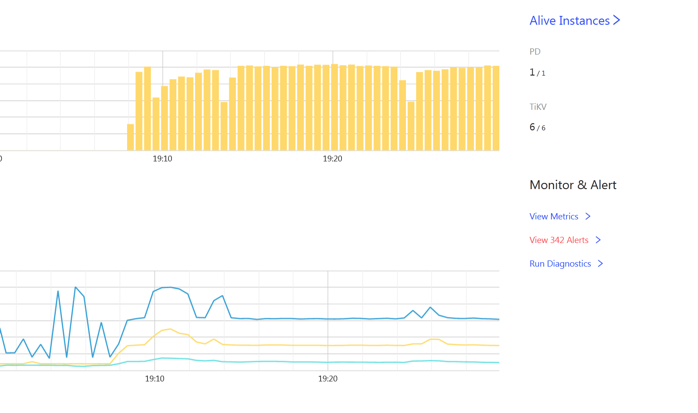
带着这个疑问,在监控上我们修改 promtheus 的表达式,查看 P9999 延迟,发现波动巨大,比 P999 明显。时间点和 load runner 的数据可以对齐。查看 TiKV-Detail 的监控发现 TiKV 实例出现重启,通过系统信息确认 TiKV 出现 oom (out of memory)。oom 的原因是之前遗留了 3 个 TiKV 实例 scale-in 之后,只是变成 TombStone 但没有清除,导致现有的 TiKV 实例 oom。

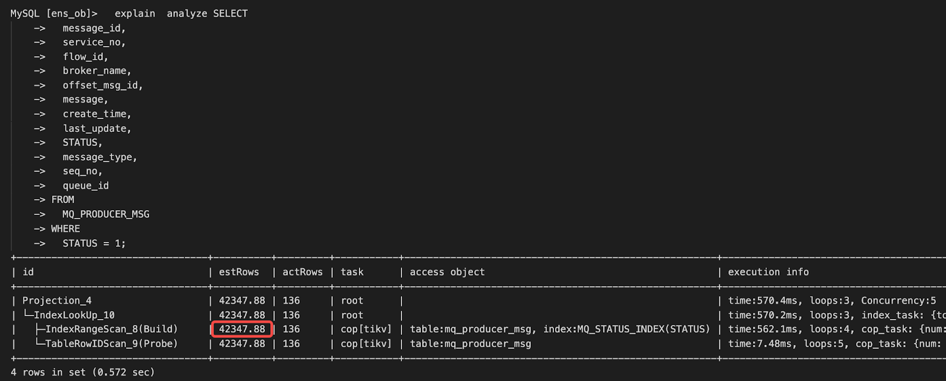
SQL 执行计划稳定性 - 永不准确的统计信息
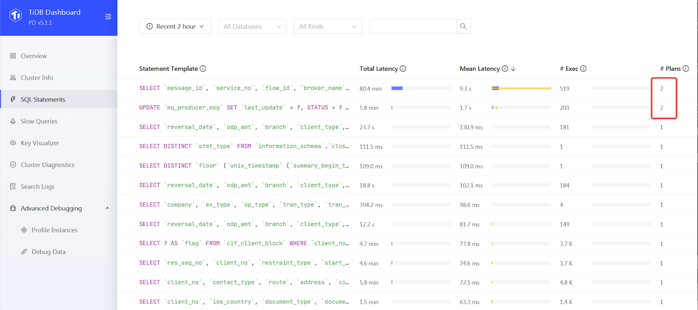
在某一次压测的过程中,应用 TPS 掉为 0,从 TiDB Dashboard 我们发现出现一条 Top SQL。这个 sql 执行计划发现了变化,出现了两个执行计划。MQ_PRODUCER_MSG 是一个消息队列表,query 包含 flow_id 和 status 两个过滤条件,flow_id 和 status 上面都有单列的索引。常的执行计划是走 flow_id 的上面的索引,平均执行时间是 62 毫秒。出问题的时候,优化器选择 status 列索引,执行时间是 38 秒。
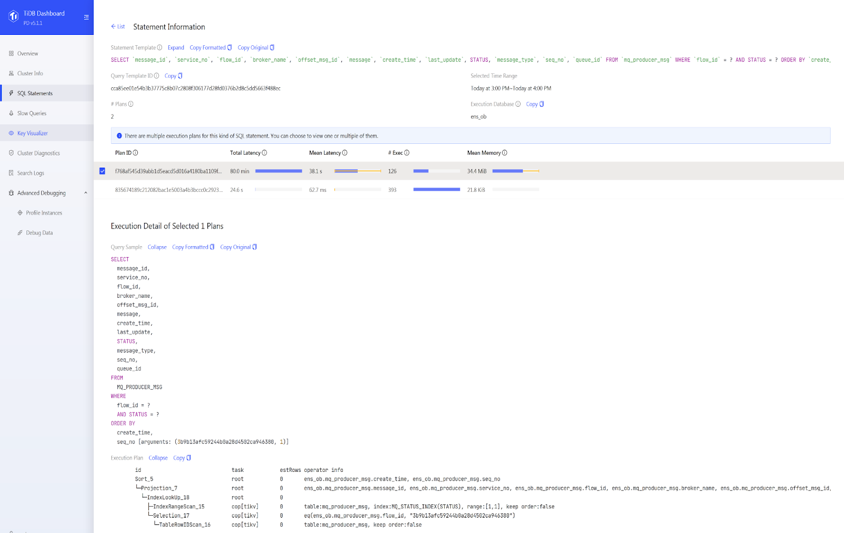
在错误的执行计划中,对于条件 status=1,优化器估算为 0 行,所以选择 了 status 列上面的索引。我们尝试重现,对 status =1 的条件做一个 explain ****yze,估算值是四万多,并没有出现估算等于 0 情况。
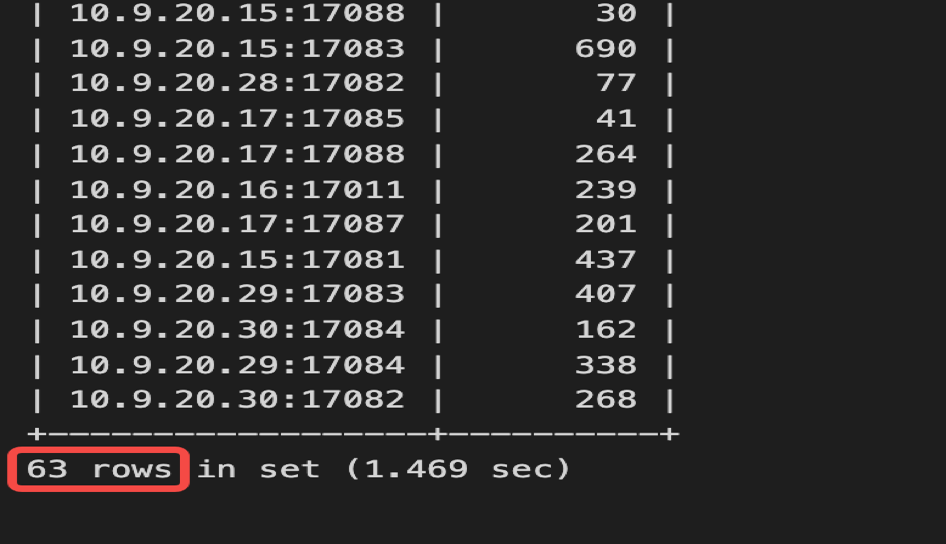
接着分析慢日志,63 个 TiDB 实例都出现这个错误的执行计划,一共有 94 个连接执行了错误的执行计划,也就是每个 TiDB 实例有一个或者两个连接执行过这个错误的执行计划。
select instance, count(*) from information_schema.cluster_slow_query where index_names like '%MQ_STATUS_INDEX%' group by instance;
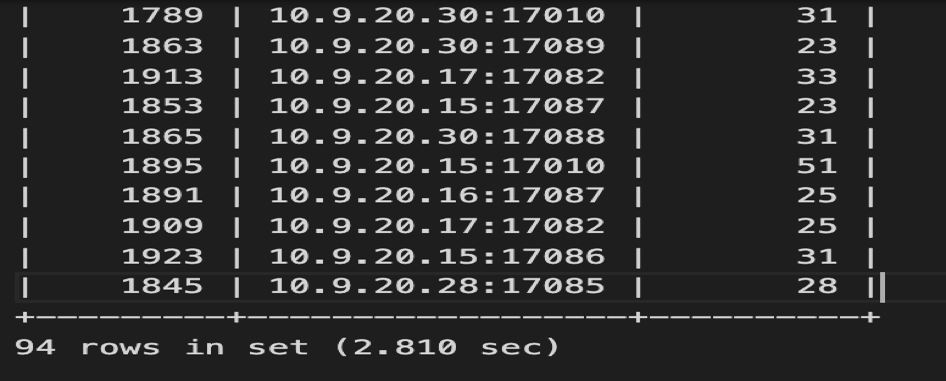
select conn_id,instance, count(*) from information_schema.cluster_slow_query where index_names like '%MQ_STATUS_INDEX%' and digest = 'cca85ee01e54b3b37775c8b07c2808f306177d28fd0376b2d8c5dd5663f488ec' group by instance,conn_id;
基于以上的分析我们怀疑错误的估算跟 TiDB 异步加载统计信息的行为相关。统计信息 Lazy Load 的 feature 是对于列上详细的统计信息,比如 (histogram/cm_sketch 等),只有等到第一次被用到之后,后台任务才会异步加载的。为了验证,我们重启一个 TiDB 实例,然后对 status=1 进行 explain ****yze,依然没有重现 status=1 估算为 0 的情况。

通过 stats_histograms.update_time 检查上一次统计信息更新时间可以确认跑负载之前表上的统计信息刚好被自动更新过 (注意:stats_meta.update_time 不代表上一次统计信息更新时间)。然而统计信息还是不准确,这是为什么呢?
通过偶然的机会我们发现,status=1 情况只存在于跑负载过程中。负载跑完以后,表里面没有status=1 的数据。所以自动收集统计信息时,因为上一轮的负载已结束,status=1 的数据已经被处理完了,表里没有 status=1 的数据,所以 status=1 的估计值为 0,status 列唯一值 (NDV, number of distinct values)只有 1。而正确的统计信息里,NDV 为 2。
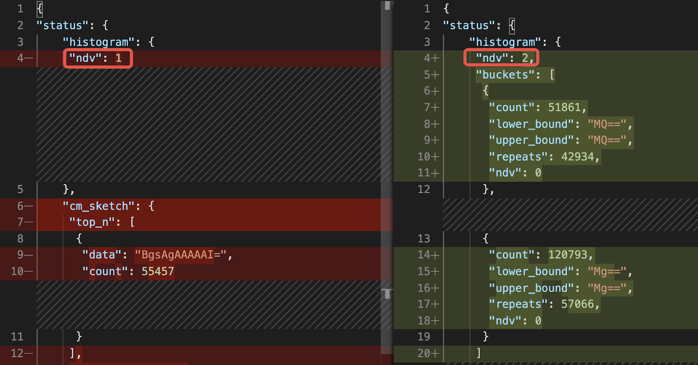
对于业务中消息中间表,数据是频繁变动的,统计信息是否具有代表性,取决于统计信息更新时,数据的状态。针对这种情况,TiDB 优化器需要支持手工锁定统计信息,避免 auto ****yze 任务在错误的时间点搜集了非典型统计信息。在现有版本,需要通过 SQL Binding 手工绑定执行计划,确保正确的执行计划被选择。
TPS 880 到 1200+
数据库优化之后,应用的 TPS 跟应用 jvm 的个数成正比。最终,使用一台 ARM 服务器,同样是 16 个 Numa,部署15个应用,每个应用 jvm 绑定一个 Numa,连接到 TiDB 集群。最优应用并发在 1200 左右,最大应用 TPS 为 1250 左右。应用服务器和数据库服务器 CPU 资源利用率在 70% 左右。
优化总结
这个案例里面我们学到了什么?
第一, ARM 服务器上万物绑 Numa,包括应用 jvm、Haproxy、TiDB 的所有的组件:PD、TiDB 和 TiKV。
第二,性能优化最核心的问题就是时间去哪儿了。难点是任何地方都可能成为瓶颈,如何进行观测和定位?在这个案例里面,我们通过用户响应时间和数据库时间的对比,判断了瓶颈在数据库里面,还是数据库外面,也可以直接通过 TiDB 的指标 connation idle duration (数据库连接提交 SQL 间隔时间),进行快速的判定。
第三,我们在这个案例里重度使用了 TiDB Dashboard 和 grafana 等内置监控,进行 sql 优化和关键指标的分析;利用了火焰图、mpstat等系统工具,对进行 CPU、网络、IO 等资源进行观测。
TiDB 性能和稳定性的挑战
对于银行核心交易应用是 read heavy 负载,一个交易包含上百条小查询,如何保持高性能和稳定性是一个巨大的挑战。
对 TiDB 实例进行 trace,同样一条 sql 的执行,针对一个单行配置表的查询,延迟范围从 1.5毫秒到 15 毫秒,虽然大多数执行分布在 2.5 毫秒左右,最大的延迟 15 毫秒。分析最高的 15 毫秒延迟信息,可以发现 sql 执行过程中 goroutine 需要频繁切换出来进行 gc mark asist 等操作,影响了 sql 的处理延迟。

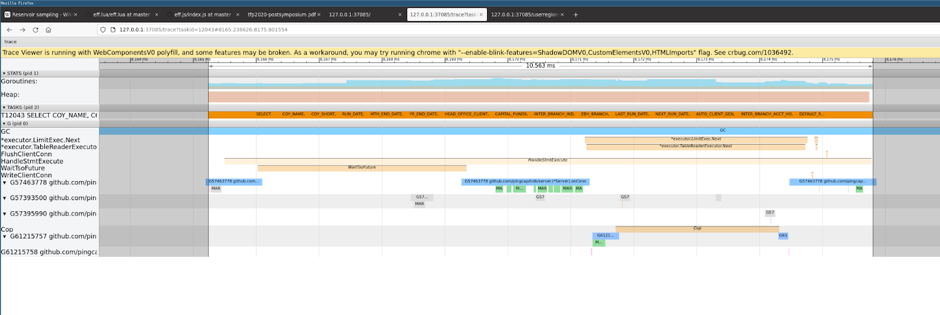
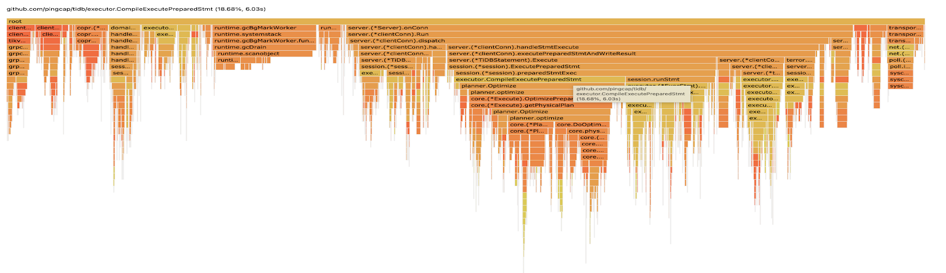
分析 TiDB 的火焰图,CompilePreparedStatements 占了 18% 的 TiDB CPU,按照 alloc_objects 排序,TiDB 内存申请操作大约36% 来源于 CompilePreparedStatements 中的planner.Oplimzer。为什么开启了执行计划缓存(prepared plan cache),优化器还需要对于 prepared statements 进行解析和执行计划生成的操作,消耗大量的内存和 CPU?
通过 grafana 监控,可以确认 prepared plan cache 命中率为 72.7%, 27.3% 的 prepared statement 没有命中 plan cache 的 sql,会重复解析生成执行计划。因为这次测试使用了v5.1.1 版本,prepared-plan-cache 还是实验特性,部分 sql 语句还不支持缓存执行计划。
-
Queries Using Plan Cache OPS = 33.3k
-
StmtExecute = 45.8k
-
prepared plan cach 命中率 = 33.3/46.8 = 72.7%

在近期新版本 v5.3.0 中,prepared plan cache 这个 feature 已经正式 GA,解决了之前部分语句的执行计划无法缓存的问题,消除了重复解析 SQL、 生成执行计划带来的 CPU 和内存的消耗。正如对于运行在 Oracle 上的 OLTP 应用,使用绑定变量和软解析可以使性能得到数量级别的提升,随着 prepared plan cache 特性的 GA,TiDB 在银行核心负载中,性能和稳定性方面将有显著的提升。另外,应用使用 prepared statement 接口,还可以有效防止 SQL 注入攻击,提高整个系统的安全性。


