
5G时代,如何彻底搞定海量数据库的设计与实践原创
5G时代,业务数据越来越丰富,业务使用MySQL数据库作为后台存储,存储引擎使用InnoDB,会带来哪些挑战?如何针对公司业务特点及MySQL数据库特性,制定若干数据库使用规范供一线RD在设计业务时参考部分内容要求强制执行。本文从介绍MySQL相关关键基础架构,并结合实际案例介绍表和索引的设计技巧,并对规范中重点内容做详细解读。
基础知识
InnoDB记录存储方式
大家都知道在InnoDB存储引擎中记录是按主键顺序存储,并且依靠这个特性为表创建了主键聚簇索引。
InnoDB是如何实现记录“顺序存储”的呢?首先要知道“顺序”分页内顺序和页间顺序,页为InnoDB内外存交换的基本单位。
页间顺序:磁盘文件中页与页之间使用双向链表连接,页间有可能是物理有序。大多数情况是逻辑上的有序;
页内顺序:页内各记录使用单项链表把记录连接起来,所以页内是逻辑有序,配合slot数据结构实现页内接近二分查找的查询效率。
图1 为InnoDB页内空间分布:
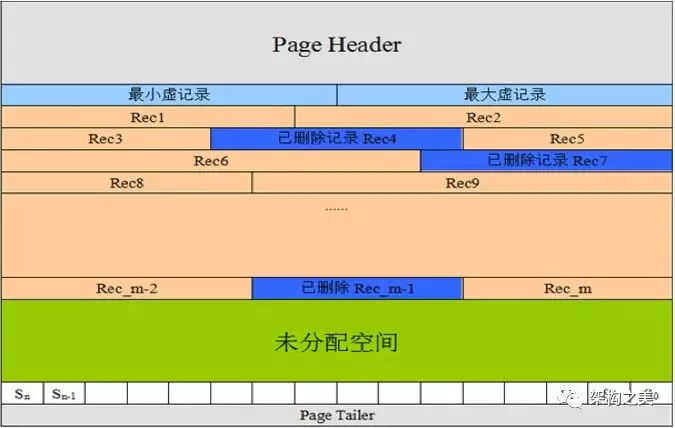
根据以上特点,我们来分析下使用不同的主键对存储会造成哪些影响:
自增主键:主键值递增,数据是顺序插入的,所以在页内数据物理连续,写满一页后在顺序分配下一页。在没有删除操作的情况下,整个表的记录在磁盘文件中都是按照写入顺序连续存储的。其中存储方式磁盘利用率非常高,且随机IO很低。插入效率相当高。
业务主键:比如用户表使用“uid”做主键,商品表使用“infoId”做主键,这种有意义的主键,我们称为业务主键。很明显,业务主键不但无法做到记录物理连续而且在插入数据时还可能造成页的分裂,从而导致页内碎片,例如如果一个页空间已满,存储主键值0~99,100条数据,如果要插入55这条记录,页内已经放不下,需要分裂成两个页才能完成插入操作,而分裂后的两个页很难被写满,会造成页内碎片,所以业务主键在写入性能和磁盘利用率上都不如自增主键。
通过上面的分析,我们是不是可以得出结论:使用自增主键一定好呢?在我们分析完InnoDB的索引以前,现在下结论还有些早。
主键索引
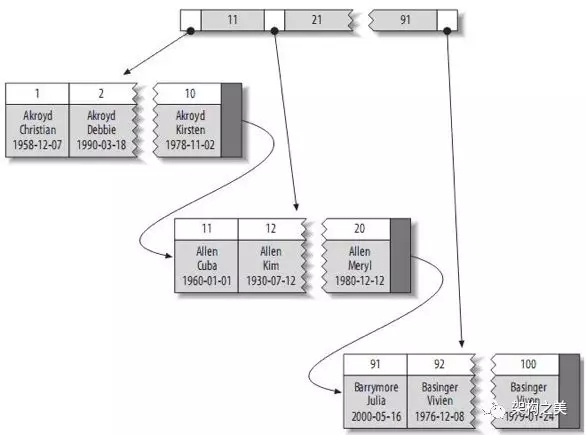
InnoDB会自动在表的主键上创建索引,数据结构使用B+ Tree。根据存储上的特点主键索引也被称为聚簇索引。聚簇索引的索引结构和实际数据是存储在一起的,B+ Tree叶子节点存储的就是实际的记录,如图2所示:
非主键索引
既然记录存储在主键索引结构中,那么在其他列创建的索引是如何找到记录的呢?我们可以很自然的想到,非主键列上的索引可以先通过自身索引结构查找到主键值,然后在用主键值在聚簇索引上找到相应的记录。InnoDB就是这么做的,所以我们也称非主键列上的索引为二级索引(因为一次查询需要查找两个索引树)。
二级索引有以下特点:
-
除了主键索引以外的索引;
-
索引结构叶子节点中的Data是主键值;
-
一次查询需要查找自身和主键两个索引;
联合索引
联合索引也叫多列索引,索引结构的key包含多个字段,排序时先第一列比较,如果相同再按第二列比较,以此类推。联合索引结构图如图3所示:
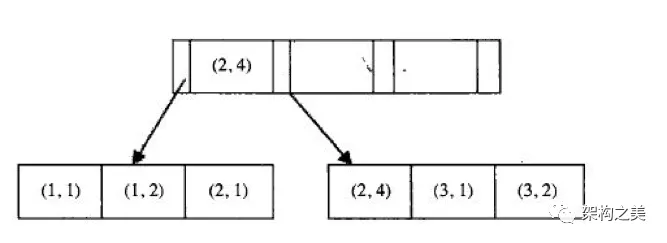
联合索引上的查询要满足以下特点:
-
key按照最左开始查找,否则无法使用索引;
-
跳过中间列,会导致后面的列不能使用索引;
-
某列使用范围查询时,后面的列不能使用索引。
根据前缀索引特性,联合索引(a,b,c),可以满足(a),(a,b),(a,b,c)三种查询。
小结
了解了InnoDB的索引后,我们再来分析自增主键和业务主键优缺点:
自增主键:写入、查询效率和磁盘利用率都高,但每次查询都需要两级索引,因为线上业务不会有直接使用主键列的查询。
业务主键:写入、查询效率和磁盘利用率都低,但可以使用一级索引,依赖覆盖索引的特性,某些情况下在非主键索引上也可以实现1次索引完成查询(后面的案例中会介绍)。
自增主键相对业务主键在IO效率上优势在SSD硬盘下几乎可以忽略,而在业务查询性能上业务主键有明显优势,所以在数据库中使用的都是业务主键。
业务表设计
针对MyQL数据库特性结合公司业务特点制定了一系列数据库使用规范,可以有效的指导一线RD在项目开发过程中数据库表和索引的设计工作。下面介绍业务中表和索引的重点设计原则以及两个实际案例。
表设计原则
主键选择:前面我们已经对比分析过业务主键和自增主键的优缺点,结论是业务主键更符合业务的查询需求,而互联网业务大多都符合读多写少的特性,所以所有线上业务都使用业务主键;
索引个数:由于过多的索引会造成索引文件过大,所以要求索引数不多于5个;
列类型选择:通常越小、越简单越好,例如:BOOL字段统一使用TINYINT,枚举字段统一使用TINYINT,交易金额统一使用LONG。因为BOOL和枚举类型使用TINYINT可以很方便的扩展,针对金额数据,虽然InnoDB提供了支持精确计算的DECIMAL类型,但DECIMAL是存储类型不是数据类型,不支持CPU原生计算,效率会低一些,所以我们简单处理将小数转为整数用LONG存储。
分表策略:首先要明确数据库出现性能问题一般在数据量到达一定程度后!所以要求我们提前做好预估,不要等需要拆分时再拆,一般把表的数据量控制在千万级别;常用分表策略有两种:按Key取模,读写均匀;按时间切分,冷热数据明确;
实际案例
案例一:用户表设计
用户表包含字段:uid,nickname,mobile,addr,image……,switch;
uid为主键,业务上有按uid和mobile两种查询需求,所以要在moblie上创建索引。
switch列比较特殊,类型为BIGINT,用来保存用户的BOOL类型的属性,每一位可以保存用户的一个属性,例如我们用第一位保存是否接收推送,第二位保存是否保存离线消息等等。
这种设计有很高的扩展性(因为BIGINT有64位,可以保存64个状态,一般情况很难用满),但是同时也带来一些问题,switch有很高的查询频率。由于InnoDB是行存储,要找查询switch需要把正行数据取出来。
这对上述场景,我们可以表设计上可以做哪些优化呢?常用的方案是把表垂直查分,这种很常见我们不做过多讨论。
还有一种方案我们可以利用InnoDB覆盖索引的特性,在uid和switch两列上创建联合索引,这样在二级索引上包含uid和switch两列的值,这样用uid查询switch时,只通过二级所以就能找到switch,不需要访问记录,甚至不需要到二级索引的叶子节点就可以找到要查询的switch值,查询效率非常高。
另外有一点需要考虑,可以想象switch的变更也是相当频繁的,switch值得改变会导致联合索引的变更吗(这里的变更指索引节点分裂或顺序调整)?
答案是不会!因为联合索引的第一列uid是唯一且不会变的,所以uid就已经决定了索引的顺序,switch列的改变只会改变索引节点上第二个key的值,不会改变索引结构。
案例二:IM子系统分表方案
IM子系统包含:用户、联系人、云消息、系统消息四个主要的业务表。数据库按业务拆分,每个业务使用单独的实例。除系统消息表外,其他表都是以uid做key按128取模分了128个表。由于系统消息的业务比较特殊,所以其分表方案与其他业务不太一样。
我们先来了解下系统消息的业务特点:系统消息表保存的是服务器发出通知类型的消息,既然是通知,就会有实效性,我们规定系统消息有效期为30天,所以针对以上特点我们采取如下分表方案:
按月对系统消息表进行分表,每个月的数据又分为128个表。
大家思考一个问题:
查询一个人的系统消息时,由于是按月分表,而大多数查询都是跨月的(因为需要查找30天内的消息),所以需要两次数据库交互。是否可以优化呢?
我们可以冗余存储,具体优化方案如下:
-
插入系统消息时写当前月和上个月两个表;
-
读从上一个月开始读;
如图4所示:
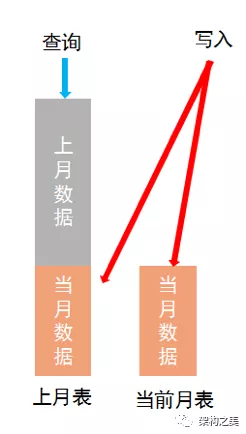
这个方案我们可以保证一次查询可以找到用户所有有效期内的系统消息,但是通过牺牲了存储空间和写入效率换取的,不一定是最优的方案,但在总数据量不大,且比较注重查询性能的业务场景下还是可以选用的。
总结
-
自增主键性能不一定高,需要结合实际业务场景做分析;
-
大多数场景数据类型选择上尽量使用简单的类型;
-
索引不是越多越好,太多的索引会导致过大的索引文件;
-
如果要查询的数据可以在索引文件中找到,存储引擎就不会查找主键索引访问实际记录。


