
记一次异步日志设置不合理导致线程阻塞问题排查原创
作为PerfMa解决方案管理部门的技术专家,我在工作遇见过很多各种问题导致的性能问题,并参与了为客户的系统进行性能诊断调优的全过程。其中有一次,碰到了一个异步日志设置不合理导致线程阻塞的情况。用文字记录下了问题的整个发现-排查-分析-优化的过程,排查过程中使用了我司商业化产品——XSea压测平台
和XLand性能分析平台,通过文章主要希望跟大家分享下分析和优化思路以及注意点,有兴趣深入了解的同学可以评论交流。
问题现象:
压测过程中发现响应时间较长(1秒多),但从XSea链路视角并未发现获取db连接慢,慢sql,访问db/redis次数特别高的情况。
分析过程:
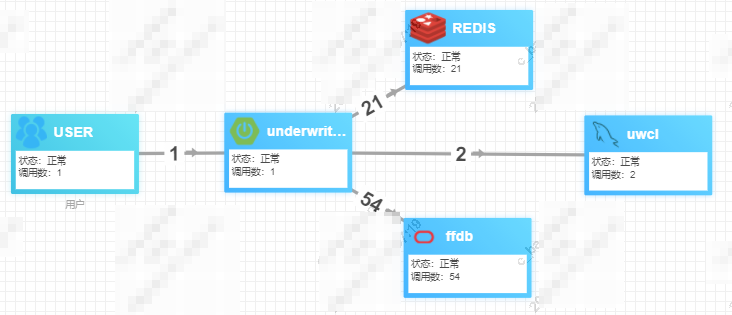
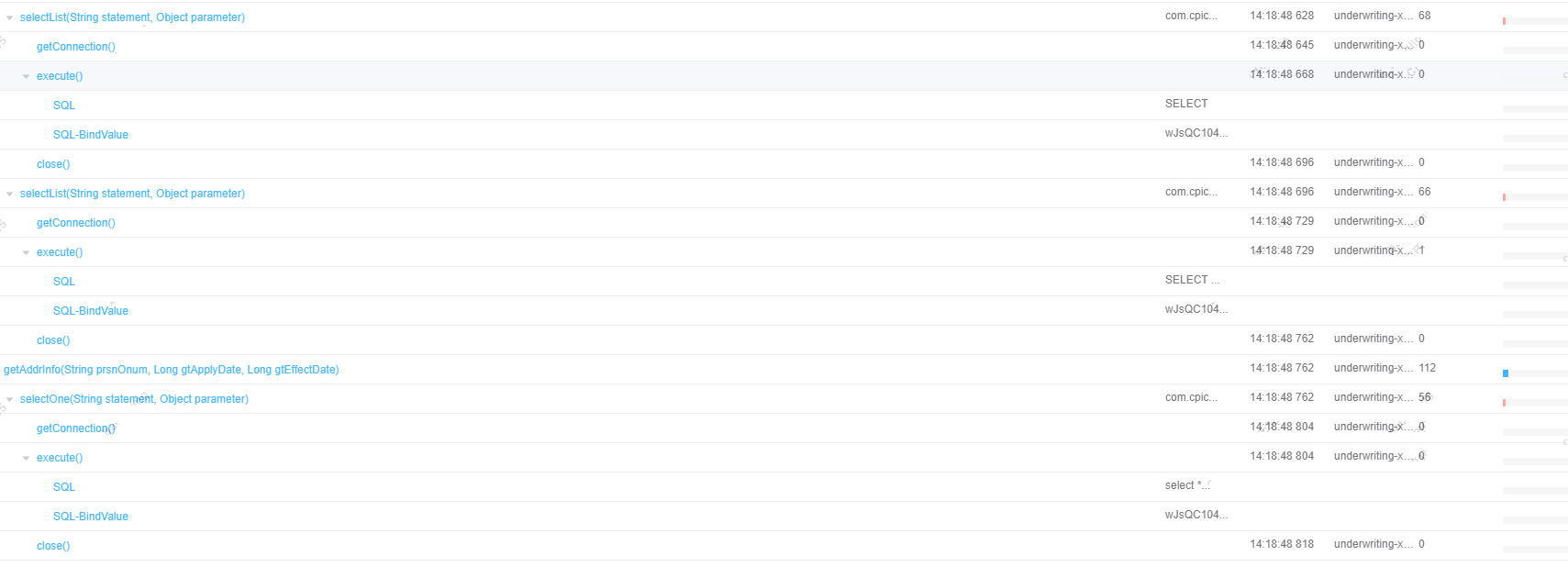
一笔请求访问21次redis,54次oracle,2次mysql,从链路树看获取连接,mybatis层的SelectOne和SelectList方法比较慢,但执行sql,redis交互都很快。
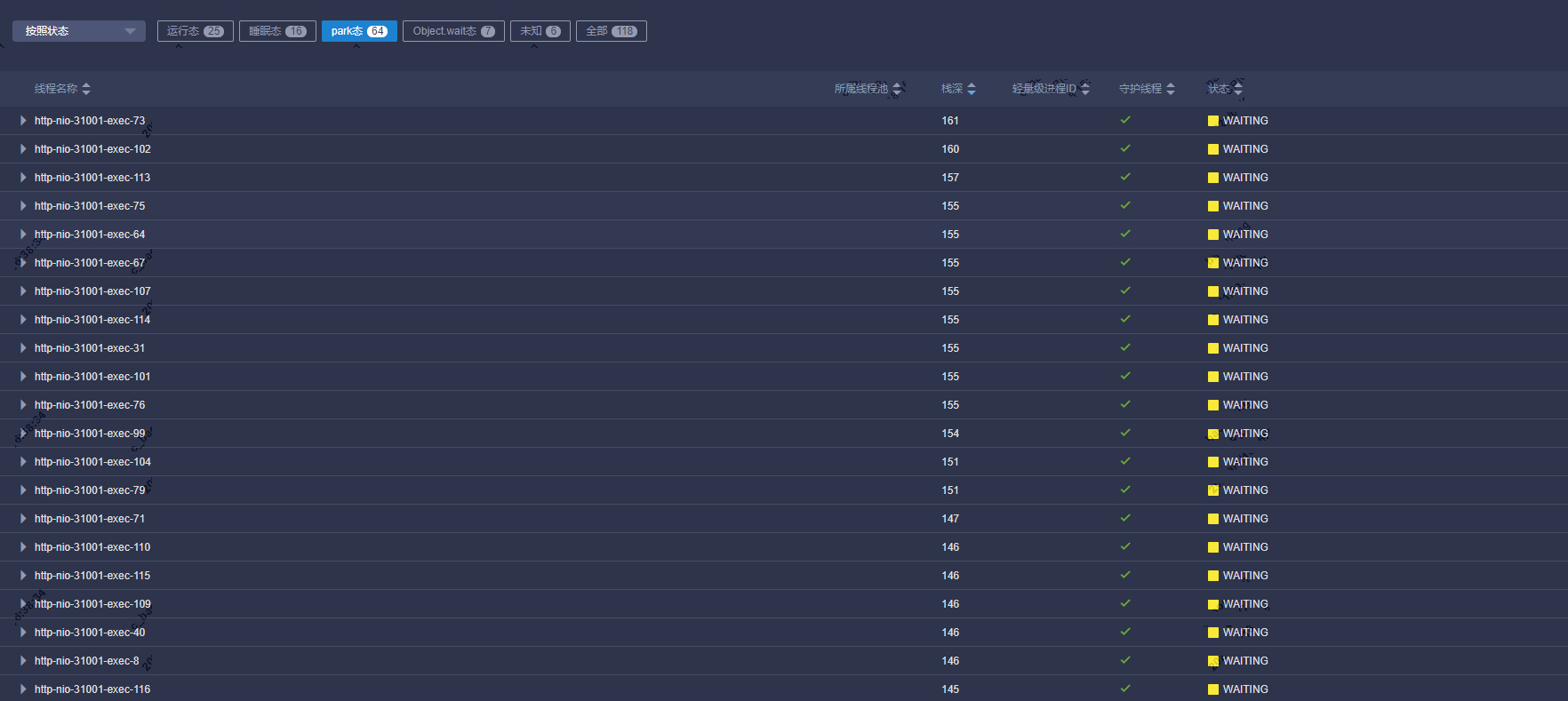
通过离线线程dump发现大量tomcat线程处于waiting状态。
继续分析线程栈发现大量业务线程阻塞在写日志相关方法上,注意栈上有个ArrayBlockingQueue.put方法,由此怀疑logback配置了异步日志,业务线程将需要打印的日志放入队列,由专门的日志线程输出到各Appender。
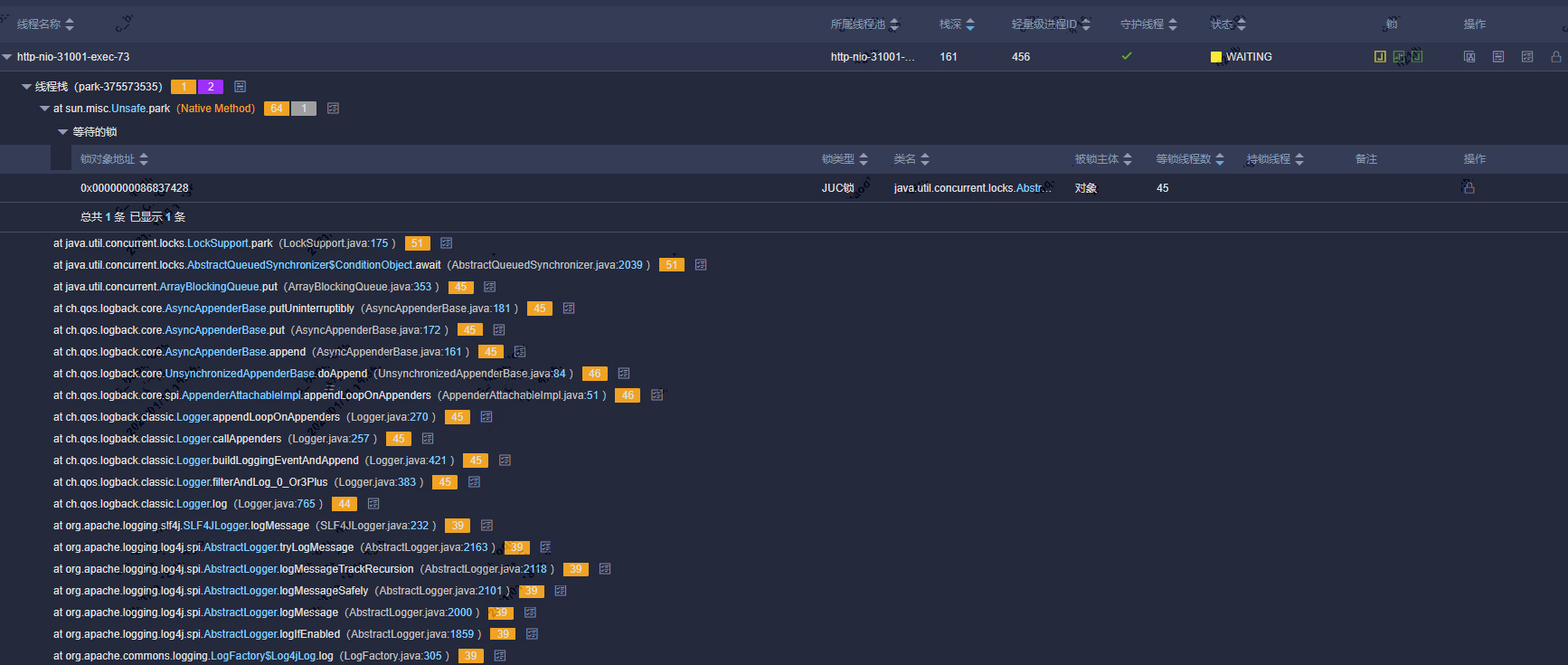
查看logback配置发现确实配置了异步日志,但一般情况下配置异步日志就是用来解决业务线程由于打印日志导致IO阻塞的问题,为什么还会阻塞呢?
继续检查logback配置,发现两个问题:
1.日志级别是debug,所以日志量比较多
2. 设置了<discardingThreshold>0</discardingThreshold>,discardingThreshold是一个阈值。
当队列的剩余容量小于这个阈值并且当前日志level TRACE, DEBUG or INFO,则丢弃这些日志,当discardingThreshold为0则不会丢弃日志level TRACE, DEBUG or INFO的日志。而此时由于日志级别为debug,日志量很大,且磁盘IO性能不高,异步日志线程已经来不及输出,队列也满了,业务线程又不能丢弃日志,就会导致阻塞。
优化建议:
1.discardingThreshold设置大于0的值,当队列满时允许丢弃TRACE, DEBUG,INFO级别的日志
2.设置neverBlock为true,则写日志队列时候会调用ArrayBlockingQueue对的offer方法而不是put,而offer是非阻塞的。可知如果队列满则直接返回,而不是被挂起当前线程。


