
代码优化日记 ——火焰图找问题代码原创
5年前
12308416
一、问题背景
- 排序服务,用于推荐item分数预测,详细项目背景及排序请求执行逻辑可参考之前的一篇文章 :《性能优化:线程资源回收》
- 本次并非事故排查,而是做系统性能优化,提升请求响应速度。
二、优化成果
本次统计结果为cat监控系统统计数据,环比优化前后同时间段的数据。
-
优化前:服务整体平均耗时:30+ms,95分位 110ms 左右
-
优化后:服务整体平均耗时:20-ms,95分位 70ms 左右


三、使用工具
- 使用工具:Arthas,arthas的详细使用方法可参考官方文档,官方文档算是比较详细的。
四、优化流程
- 借用Arthas的trace命令对接口进行耗时采样采集方法为重载方法时,可用ognl表达式进行条件筛选哦)。
- 注意:线上使用该命令时,切记带上 -n 参数指定采样次数。多次采集,每次采集时间不要太长。trace命令在一定程度上对接口的耗时影响还是比较明显的(Trace命令的实现原理)。对于高响应需求的接口或者重要业务接口慎用。尽量少食多餐,然后根据监控系统的统计,筛选出耗时较为接近监控系统的请求进行分析。防止网络抖动或者机器指标突发异常等原因采到坏样本。
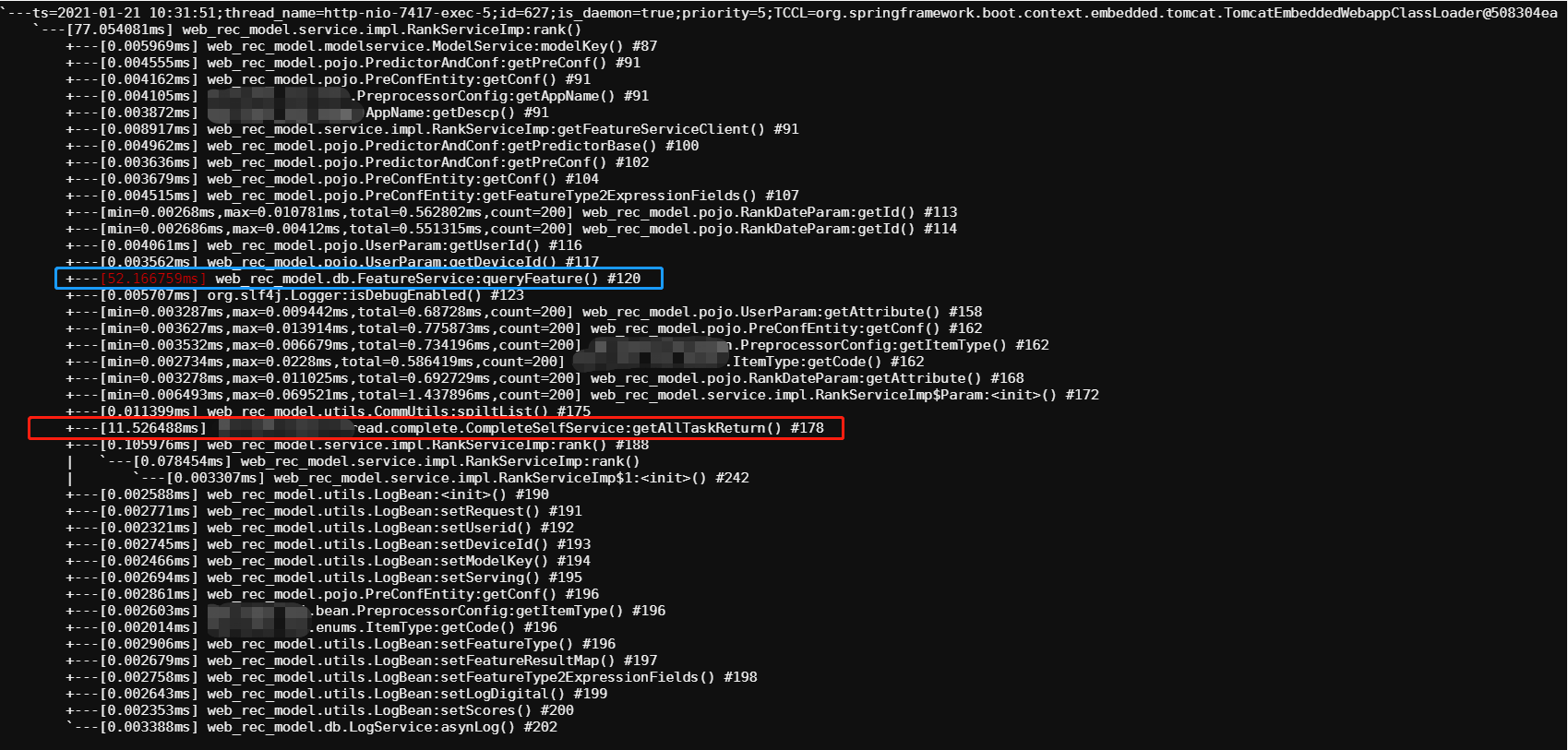
- 通过接口耗时采集,发现特征获取及预测阶段耗时较多。如下图,蓝色阶段为特征获取,红色阶段为模型预测。
- 模型预测阶段分为:特征预处理(CPU密集型计算)及分数预测两个阶段。理论上这两个动作是非常快的,合理时间在2-3ms。于是怀疑存在消耗CPU的计算动作。
- 借用Arthas的profiler生成火焰图(CPU维度的火焰图),对火焰图不熟悉的小伙伴,可以简单理解为:横向坐标为CPU使用占比,纵坐标为方法调用链层级。
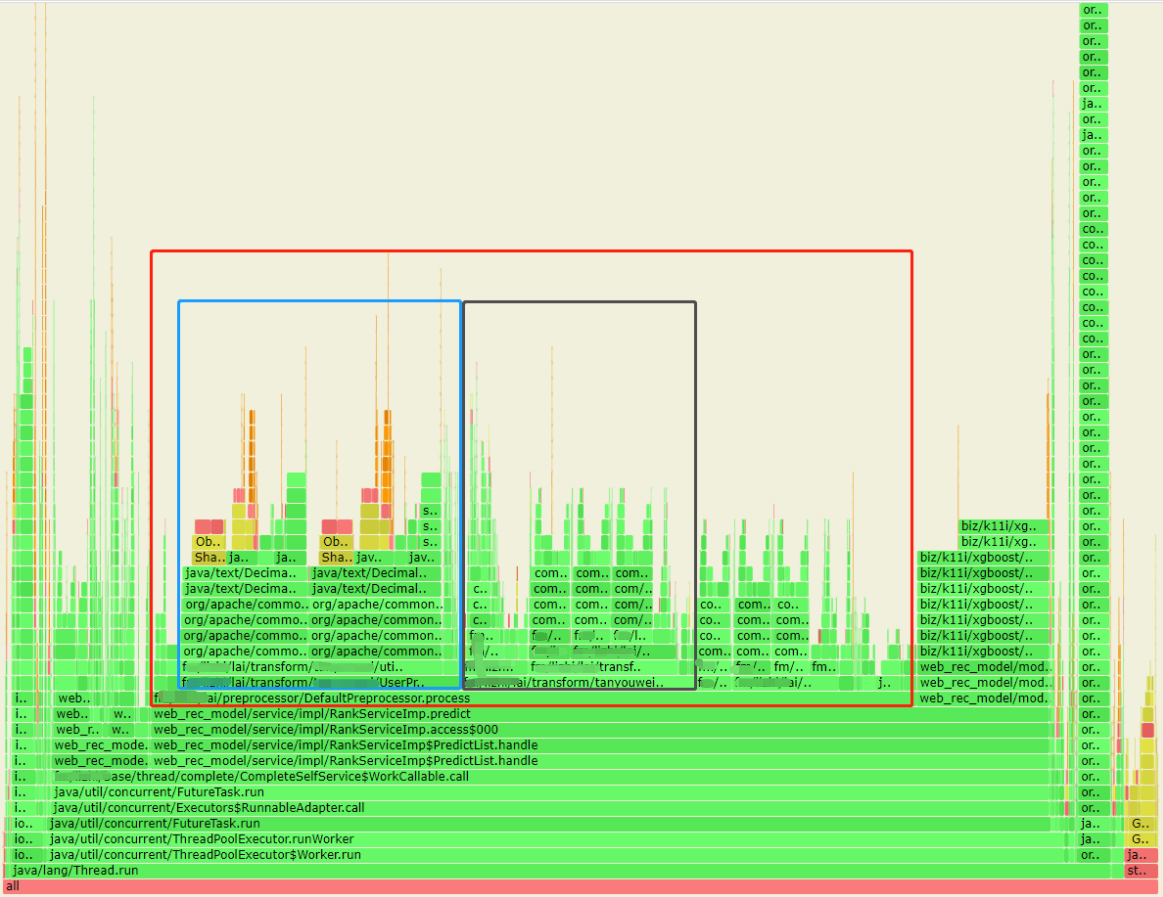
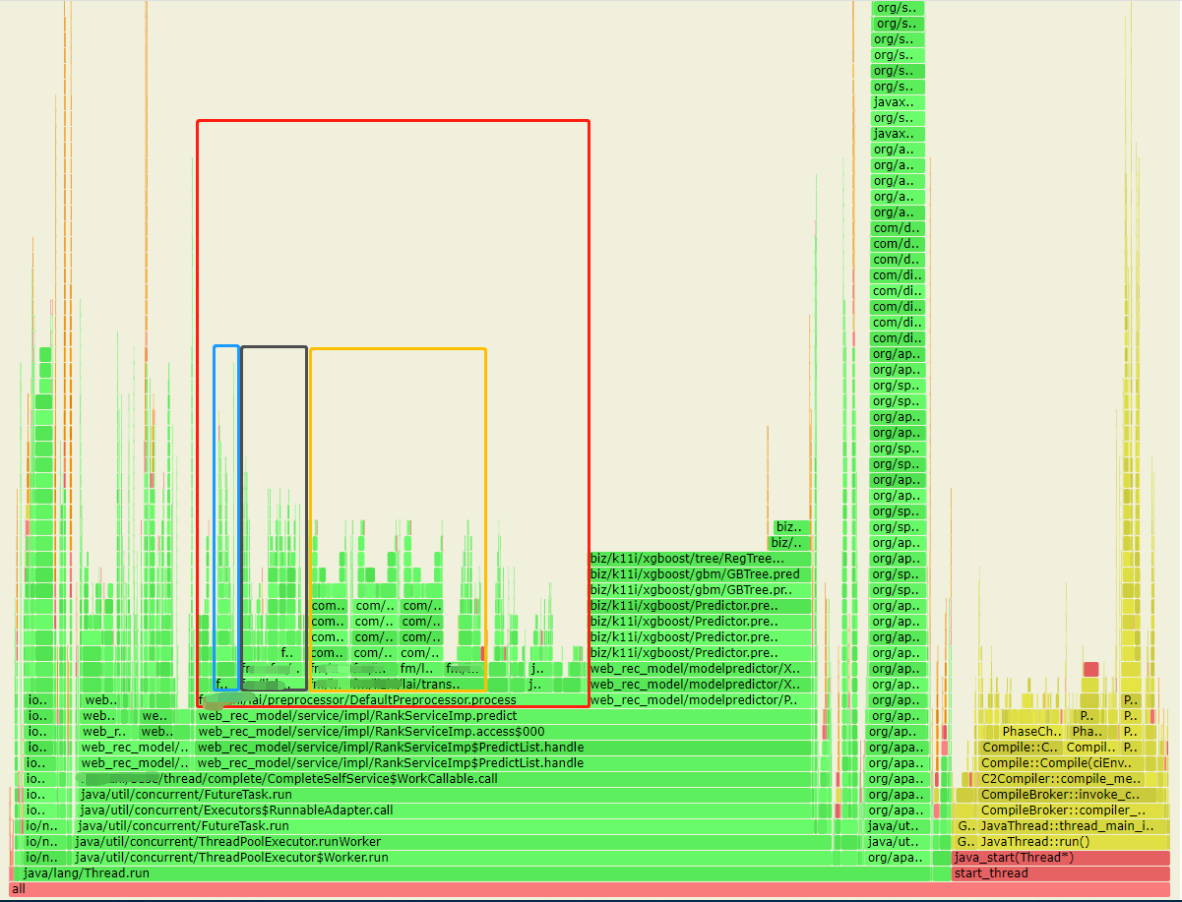
- 由火焰图可以看到,特征预处理阶段,有两个transformer大量占用CPU的资源(svg格式的火焰图在浏览器中是支持交互的)。以下先确定篮色方框问题。
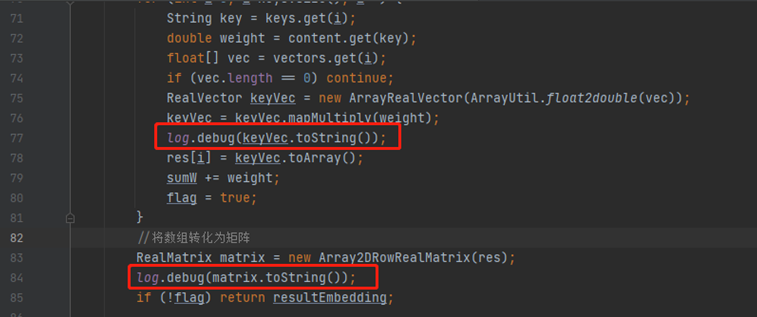
- 通过代码排查发现,小伙伴在提交代码时,忘记将debug日志去掉。注意,debug日志方法是会执行的,点进去源码中可以发现,debug方法中做了日志级别标识的判断,再决定是否写日志文件。图中77、84行代码中,是先调用toString后再讲结果传入debug方法中,所以不管日志级别是INFO还是DEBUG,toString始终会执行
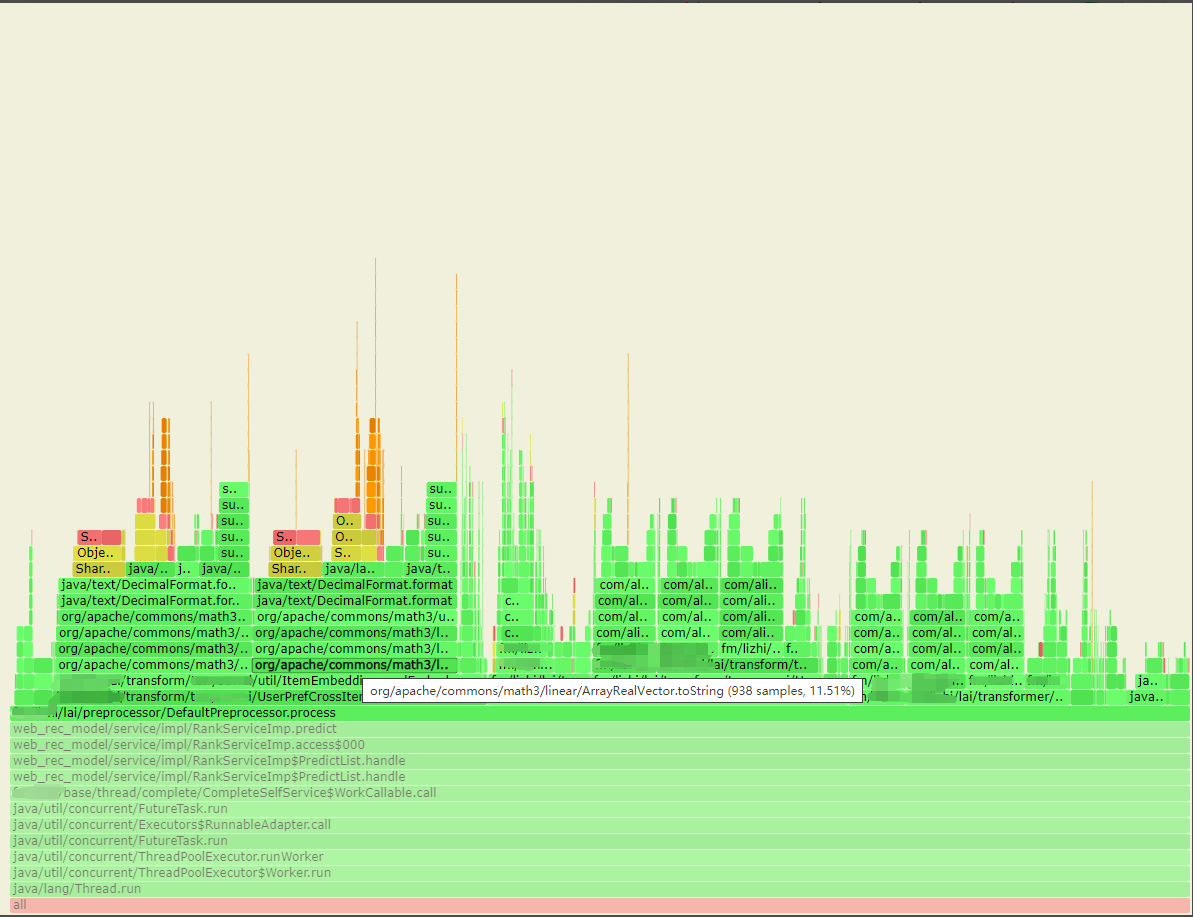
- 接着查看黑色方框的火焰图,如下图圈出,发现该特征处理的transformer中大量使用到fastjson的反序列化方法(parseObject或者parseArray)。并且通过锁定方法发现,该transformer为用户侧处理的,计算过程中并没有与item特征进行交叉计算。由于先前的特征预处理阶段设计问题。该transformer原则上仅需要在一次请求中只计算一次,而当前被多次计算(计算次数为预测的item个数)。
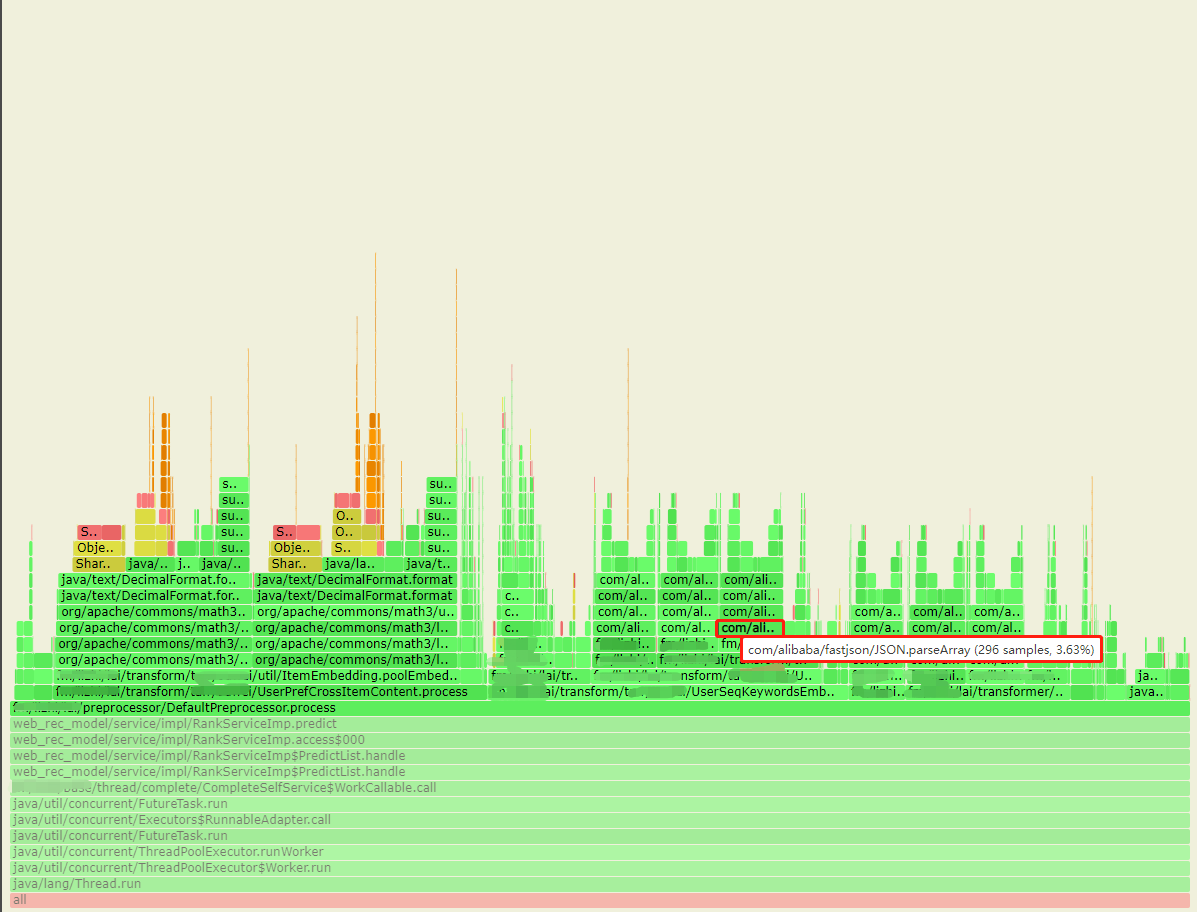
- 通过这两步优化,原本在火焰图中,这两个步骤的CPU资源消耗占比由 44% 减少到 7% 的占用。如下图,蓝色方框与黑色方框为优化后的占比情况。
-
经过筛查,橙色方框的代码也布满fastjson的方序列化动作。通过代码判断,该部分的transformer是用户特征与item特征的交叉计算,原则上无法节省计算次数。并且小伙伴们可能还记得trace采样中还有一处50+ms的耗时。该动作为特征获取,后续我们将以 特征本地化方案 进行特征获取,以及 特征规范化存储 来优化,争取将排序服务的耗时下调到10ms左右。由于该方案任在开发中,后续方案落地后再进行分享。
-
优化前的火焰图和优化后的火焰图,优化了 37% 的CPU占用。
点赞收藏
分类:

