
G1垃圾回收源码分析(一)原创
G1 垃圾回收(一)
垃圾回收算法
标记清除,标记复制,标记-清除-压缩,
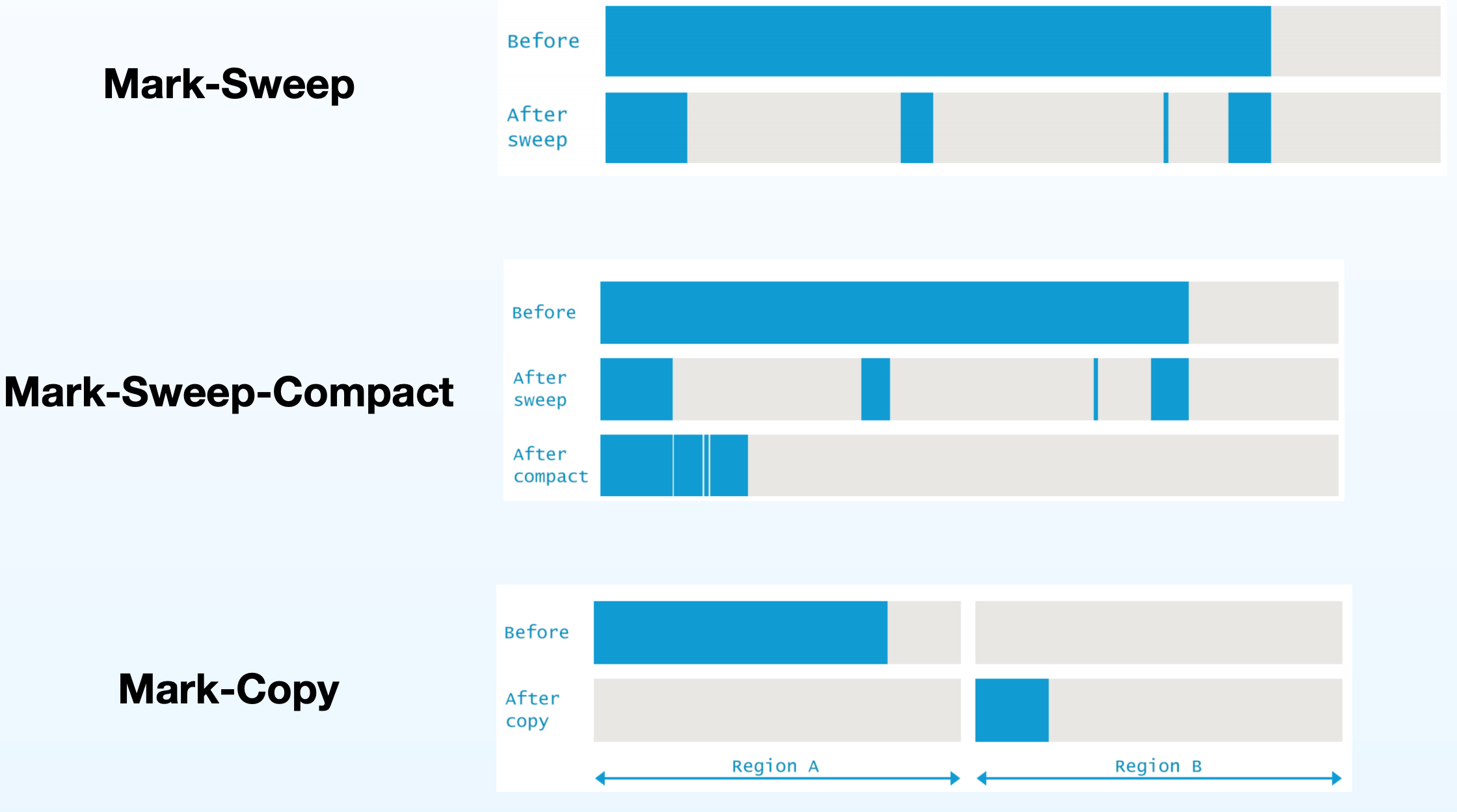
- 标记清除
标记清除呢就是比较直观的理解了,内存中当引用不可达之后这一块内存就要被释放出来,,当然我们知道java中的对象在内存中的分布不是连续的,每一次将标记的对象清除之后,就会释放出来当前的空间,这些空间大小不均,如果很小的话不足以再次分配的话,这就造成了大量的内存碎片,CMS就是基于该算法
- 标记复制
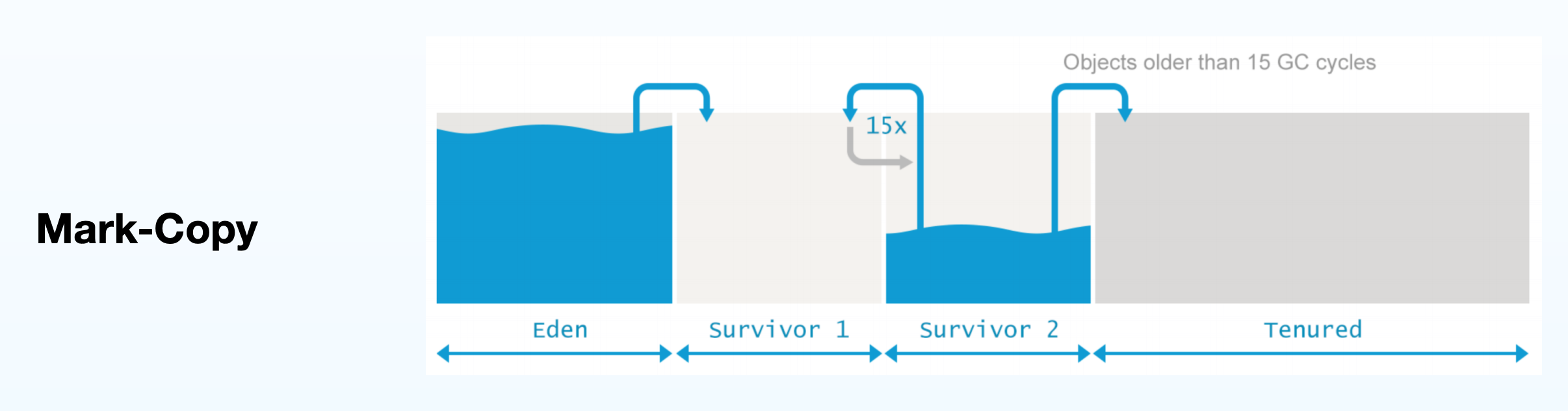
将内存中分成俩块区域,俩块区域来回复制,一般是from区域和to区域,在垃圾回收发生器的时候,from区域所有存活的对象移动到to区,然后以此类推,to区再移回from区域,这样内存区域的利用率比较低,适用于朝生夕灭的对象。
压缩呢,则是增加一次压实操作,将碎片内存利用起来
在分代回收的Hotspot虚拟机中,新生代的垃圾收集采取标记复制算法,老年代采取标记清除算法。
-
CMS垃圾回收器
低延时,并发收集,只用于老年代垃圾回收,新生代配合ParNew使用。无法进行压缩,压缩依赖于Full GC。
下图是CMS垃圾呼死后的工作流程,一共触发2次STW,分别在初始标记和重标记阶段
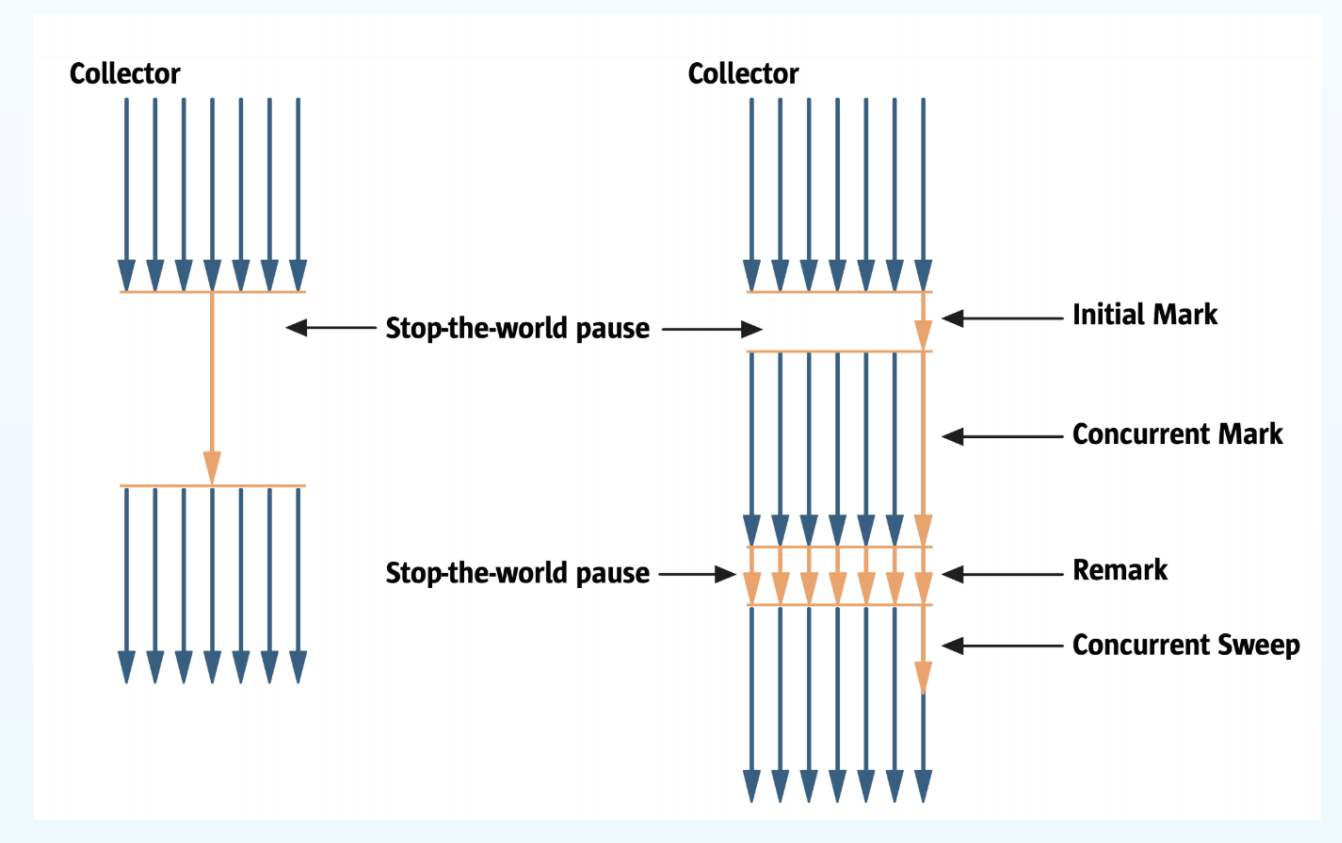
-
G1垃圾回收器
同样是低延时,提供增量压缩,适用于较大的Heap(>4G),可以设定GC预期。相较于CMS来说,G1不单单只用于新生代或者老年代。而是横跨整个堆。而且分代不再是来连续的内存空间,而是分布在不同的Region(后文会说),G1垃圾回收器把整个JVM 堆划分为N个(1M~32M)的等大的分区。默认是2048个分区。
- 针对新生代
STW ,并行,复制
- 针对老年代
STW ,并行标记清除,增量压缩
G1垃圾回收的工作流程,同样是先在Eden去进行垃圾并发回收,然后回收内存。不同的是G1会在新生代GC的时候记录,用于老年代GC,GC停顿预测。当整个堆占用达到默认45%(-XX:InitiatingHeapOccupancyPercent=N),回进行老年代GC,同样,老年代也是并发GC,但是区别于CMS的是,G1的老年代GC一定会再进行一次新生代GC,类似于使用CMS垃圾回收器时候增加参数(-XX:+CMSScavengeBeforeRemark),老年代的GC使用<red>三色标记算法<red>来进行老年代初始标记,然后在重标记阶段使用SATB来解决并发标记时候可能是活跃对象的内存处理,然后回收全空的分区。还有G1的老年代GC不是立即发生的,而且这个发生的区域也不是整个堆,而是部分老年代分区进行GC,默认是1/8的老年代(-XX:G1MixedGCCountTarget=N),依据暂停的预期,G1会选择最多的区域进行优先回收。(-XX:G1MixedGCLiveThresholdPercent=N (default 85),(-XX:G1HeapWastePercent=N),下图是G1的回收工作流程。
>
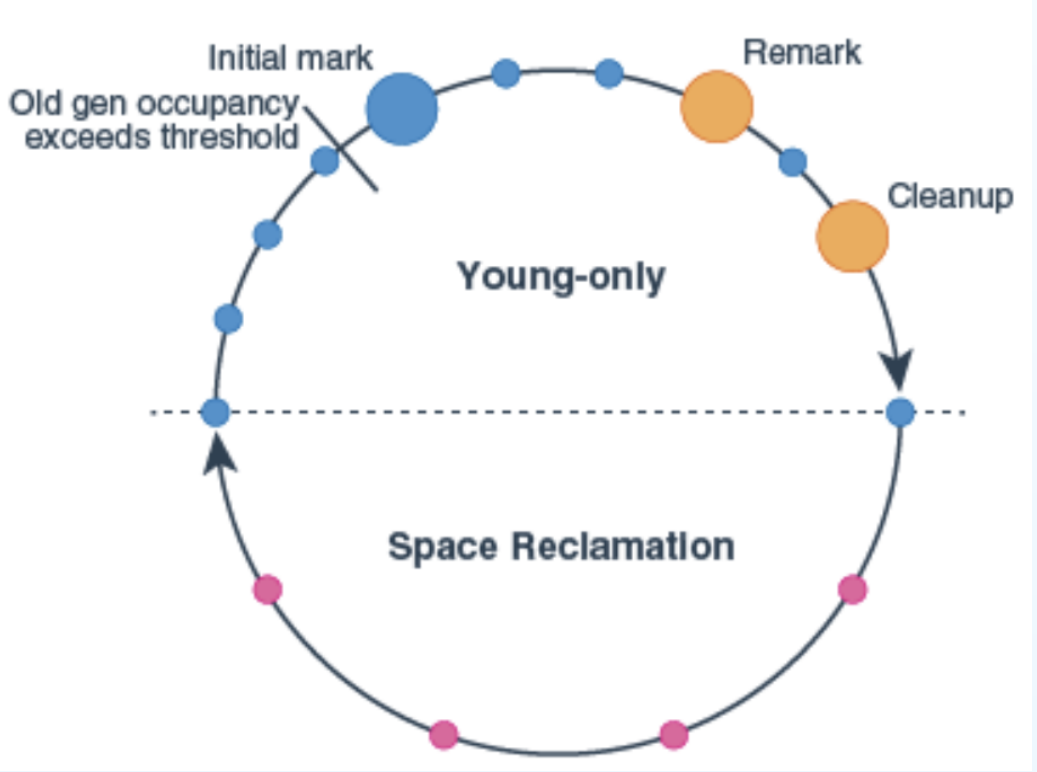
分区(Heap Region)
上面简单讲述了几种垃圾回收器的信息,这里呢就G1的分区展开讲述。分区呢是G1特有的内存结构。参见源代码分区类型可以知道G1主要分为以下几种分区类型
-
自由分区 (FHR)
-
新生代分区(YHR)
-
老年代分区(OHR)
-
大对象分区(Humongous Heap Region)
-
大对象头分区
-
大对象连续分区
-
上面说G1垃圾回收器把整个JVM 堆划分为N个(1M~32M)的等大的分区。默认是2048个分区。这是在我们不指定分区大小(G1HeapRegionSize,默认为0.使用自推断。)的情况下,G1自动推断出来的,推断的逻辑参照源代码分区类 的setup_heap_region_size方法.
void HeapRegion::setup_heap_region_size(size_t initial_heap_size, size_t max_heap_size) {
uintx region_size = G1HeapRegionSize;
if (FLAG_IS_DEFAULT(G1HeapRegionSize)) {
size_t average_heap_size = (initial_heap_size + max_heap_size) / 2;
region_size = MAX2(average_heap_size / HeapRegionBounds::target_number(),
(uintx) HeapRegionBounds::min_size());
}
int region_size_log = log2_long((jlong) region_size);
// Recalculate the region size to make sure it's a power of
// 2. This means that region_size is the largest power of 2 that's
// <= what we've calculated so far.
region_size = ((uintx)1 << region_size_log);
// Now make sure that we don't go over or under our limits.
if (region_size < HeapRegionBounds::min_size()) {
region_size = HeapRegionBounds::min_size();
} else if (region_size > HeapRegionBounds::max_size()) {
region_size = HeapRegionBounds::max_size();
}
// And recalculate the log.
region_size_log = log2_long((jlong) region_size);
// Now, set up the globals.
guarantee(LogOfHRGrainBytes == 0, "we should only set it once");
LogOfHRGrainBytes = region_size_log;
guarantee(LogOfHRGrainWords == 0, "we should only set it once");
LogOfHRGrainWords = LogOfHRGrainBytes - LogHeapWordSize;
guarantee(GrainBytes == 0, "we should only set it once");
// The cast to int is safe, given that we've bounded region_size by
// MIN_REGION_SIZE and MAX_REGION_SIZE.
GrainBytes = (size_t)region_size;
guarantee(GrainWords == 0, "we should only set it once");
GrainWords = GrainBytes >> LogHeapWordSize;
guarantee((size_t) 1 << LogOfHRGrainWords == GrainWords, "sanity");
guarantee(CardsPerRegion == 0, "we should only set it once");
CardsPerRegion = GrainBytes >> CardTableModRefBS::card_shift;
}具体视线逻辑如下:
-
首先判断JVM参数(G1HeapRegionSize)是否设定,如果没有设定,那么就是采取自推断模式来计算,计算依赖于堆的初始大小和最大值。用这俩个值的平均数整除默认的分区个数。得到分区的大小。
-
左移让分区的大小对其$2^N $幂
-
处理溢出,保证在1M-32M范围之内
-
设置一些全局变量的值,如卡表的大小,PreRegion的大小(用于设定Remember Set,内部PerRegionTable的位图
_bm大小,用于存放卡表的索引)
停顿预测模型(基于滑动标准差)
上面我曾提到G1是低延时,可以设定GC停顿预期的回收器,具体是如何实现呢,设置的参数呢为(MaxGCPauseMillis),在当前的版本是JDK8U中源代码G1收集策略中是200MS。具体的默认值在不同的jdk版本中有不同的设定。具体是情况而定。
首先来说下衰减平均也叫滑动平均,主要用于去取一列数据的平均值$davg_n$,公式如下

其中$\alpha$为历史数据的权重,$V_n$代表平均值,$1-\alpha$为最近一次的数据权重,$\alpha$越小,对数据的影响越大。根据滑动平均的公式可得到滑动方差$davr_n$

参考源代码G1收集策略中get_new_predition,该方法为G1的获取预测值的方法
double get_new_prediction(TruncatedSeq* seq) {
return MAX2(seq->davg() + sigma() * seq->dsd(),
seq->davg() * confidence_factor(seq->num()));
}-
davg方法表示滑动均值
-
sigma代表对预测值的信赖度。默认50.也即是半信任(G1ConfidencePercent)
-
dad代表滑动方差
-
confidence_factor 一共了部分初始样本数据,当数据不足5个的时候,返回一个大于1小于2的数,供以样本计算。
-
seq->num(),代表每次YoungGC记录的GC时间,存放在
TruncateSeq中,参考源代码numberSeq中
AbsSeq::add. 该方法计算滑动均值和方差-
void AbsSeq::add(double val) { if (_num == 0) { _davg = val; _dvariance = 0.0; } else { _davg = (1.0 - _alpha) * val + _alpha * _davg; double diff = val - _davg; _dvariance = (1.0 - _alpha) * diff * diff + _alpha * _dvariance; } }
可以看到这个滑动平均的代码实现,_alpha默认是0.7,
-
举个例子来叙述G1为什么使用滑动平均来计算软实时停顿预测。看到上面的预测公式
起始令$V_0=0,\alpha=0.7$,依次对变量v进行赋值,不使用滑动平均和使用滑动平均结果数据如下。
| 不应用滑动平均赋值(随机数) | 滑动平均赋值 | time |
|---|---|---|
| 0 | / | 0 |
| 10 | 3 | 1 |
| 20 | 8.1 | 2 |
| 10 | 8.67 | 3 |
| 0 | 6.009 | 4 |
| 40 | 16.2483 | 5 |
| 0 | 11.37381 | 6 |
| 10 | 10.961667 | 7 |
| 15 | 12.1731669 | 8 |
通过数据得到:滑动平均得到的值更加平缓光滑,抖动性更小,不会因为某次的异常取值而使得滑动平均值波动很大
相关阅读



