
协助美团kafka团队定位到的一个JVM Crash问题原创
概述
有挺长一段时间没写技术文章了,正好这两天美团kafka团队有位小伙伴加了我微信,然后咨询了一个JVM crash的问题,大家对crash的问题都比较无奈,因为没有现场,信息量不多,碰到这类问题我们应该怎么去分析,我想趁这次机会和大家分享一下我针对这种问题的分析过程。
不过我觉得这个分析过程可能会有点绕,因为crash文件太大,不能让大家看到crash文件的全貌而对让大家理解起来没那么有体感,因此您可以先跳到文章最后看一下结论,再回过头来看整个分析过程或许会更有帮助。
问题初探
首先我要了crash文件,第一眼当然是看开头
从这个提示初步来看我们基本猜到是物理内存不够导致的crash,在请求196608bytes内存的时候crash了,于是马上跑到crash文件的最后
发现其实物理内存是足够的,还有1G多,怎么会分配192KB的内存都分配不了呢?因此不太可能是物理内存不够导致的。
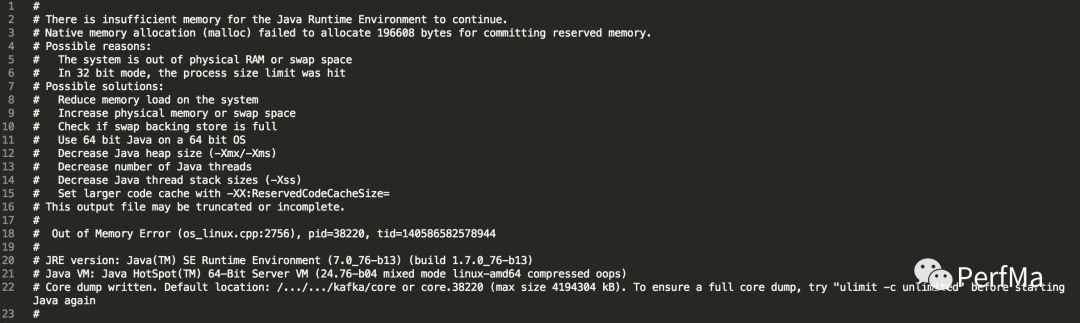

另外我们注意下这是发生在JDK7上的,JDK8上的提示会有一些不一样,JDK8上只会在32位的机器上才会有和上面完全一样的提示内容。
找出问题现场
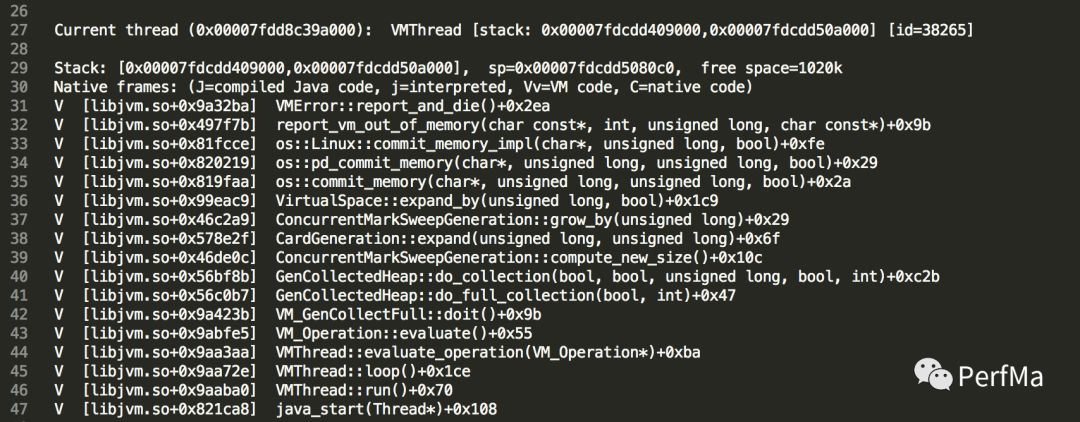
那接下来我们要找一下发生问题的地方究竟在哪里?我的第一感觉是看是什么线程上发生的crash,然后再看其栈到底是什么?于是在crash日志里找到了如下内容:
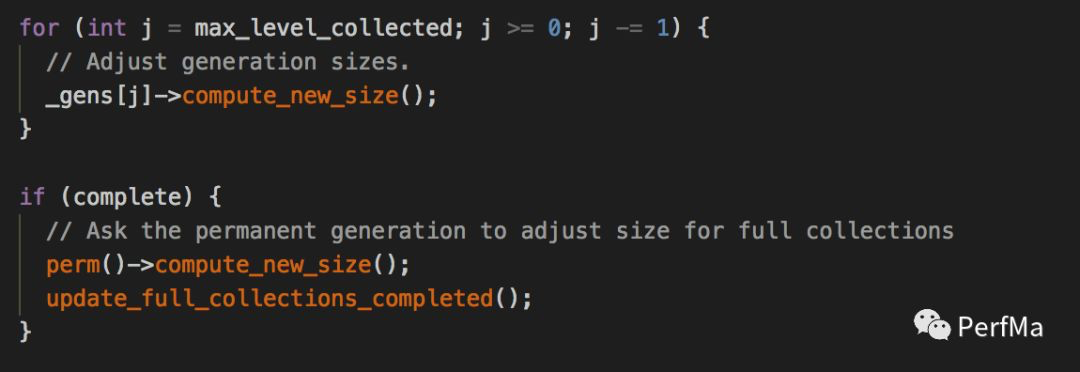
从上面我们看到crash的线程是VMThread(JVM里唯一的一个线程,主要用来处理JVM的一些事件,比如GC),它正在做Full GC,从栈上我们可以看到正在做扩容,不过ConcurrentMarkSweepGeneration的数据结构在CMS GC下Perm和Old都是用的它,那究竟是哪个呢,我们先看下栈上提到的GenCollectedHeap::do_collection这个方法,找到其调用compute_new_size方法的地方
我们暂时无法确认到底调用的是上面那个compute_new_size,还是下面那个,如果是下面那个,那就可以确认是Perm扩容所致,如果是上面那个,那就是old扩容所致。
为了进一步确认,我们此时应该看下JVM参数
从上面的JVM参数可以看到我们设置了Xmx和Xms相等,并且还设置了Xmn,那Old的Size是固定的,这样一来基本可以排除是Old扩容所致,并且我们发现没有设置PermSize和MaxPermSize,这样肯定是存在扩容操作的,因为它们默认不相等,因此可以断定是Perm扩容的时候发生了crash
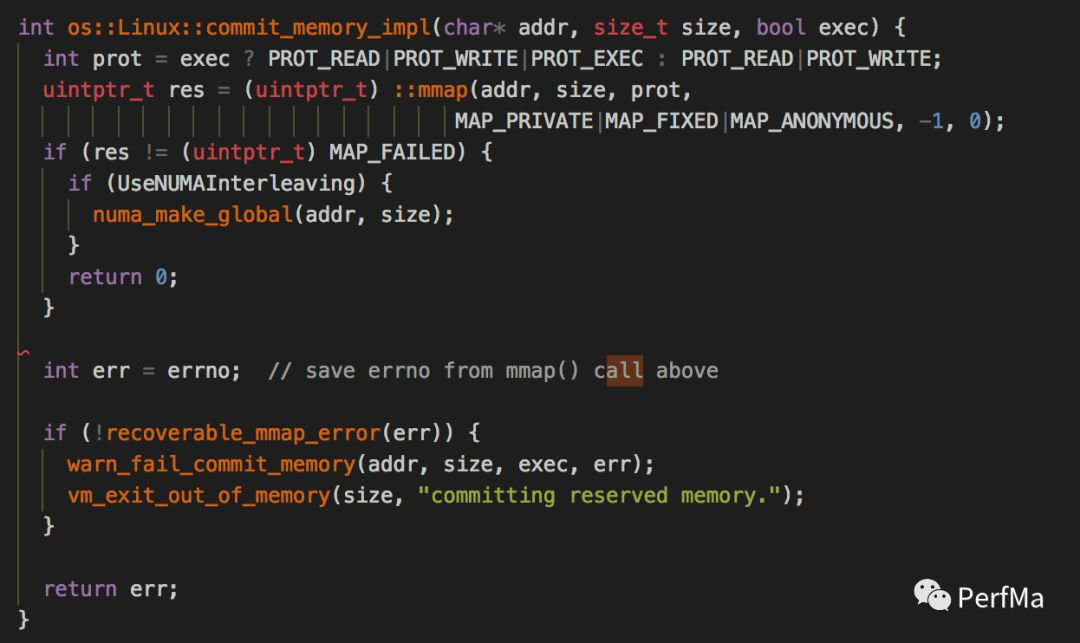
至此我们可以确定当时的场景是:发生了一次Full GC,在Full GC完之后根据当时的实际情况会对各个内存分代重新设置分代大小进行扩容,在对Perm扩容的时候发生了crash,Perm扩容其实就是做了一次mmap的操作:
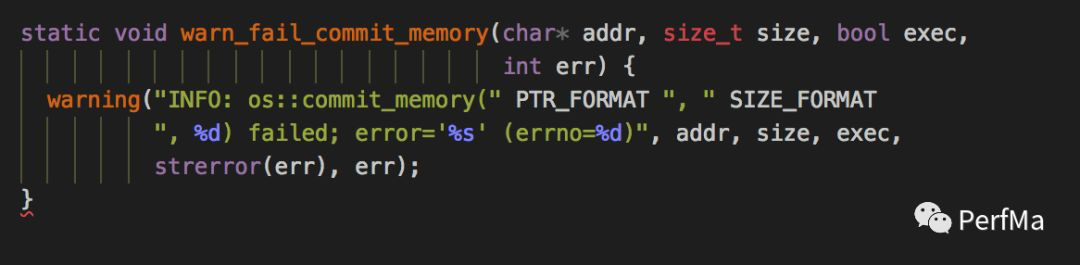
从上面的代码,我们进入到warn_fail_commit_memory这个方法
理论上我们其实是会在标准输出里打印上面的内容,不过从业务方那得知,他们将标准输出重定向到了/dev/null,因此上面那行日志就看不到了,如果能看到上面的日志,那至少我们知道mmap发生的具体errno是什么,从而断定mmap到底是为什么失败了。于是叫业务方将标准输出重定向到一个固定的文件里看具体的异常。

到现在好像基本上断了思路,只能等待参数修改之后看看其效果。
结合GC日志再探问题
我忙完一些事情后又想起这个案例,于是继续看这个crash日志,看到了crash的那个点,是发生了Full GC,而这个Full GC是GenCollectFull,这个就比较特殊了,因为它发生的场景主要是三种:
- JVMTI的强制GC
- System GC
- GC Locker
第一个基本可以排除,因为一般情况下都不会有这种agent来做这个,那下面两种情况怎么确定呢?如果有GC日志就好了,于是找业务方要了GC日志,比较可惜的是这个系统跑在JDK7上,GCCause并没有默认开启,因此我们从GC日志上看不到GC的原因,如果是JDK8,那在GC日志里是能看到System.gc的关键字来表明是System.gc触发的,GC Locker也同样可以看到相关的关键字。不过因为JDK参数里没有显示开启GCCause(-XX:+PrintGCCause),于是最后那条GC日志我们只能看到如下内容:
这条GC日志还没有打完,因为此时发生了crash,从这个GC日志看,老生代使用率其实很低的(5891510K/20971520K=28%),是不是超过了CMS的阈值?于是我们看上面的JVM参数里果然看到了CMSInitiatingOccupancyFraction设置为30,那就是老生代使用率达到30%会触发一次background CMS GC,不过目前还没达到CMS GC发生的条件,而且从整个GC日志来看,CMS GC的次数并不多,因此基本可以排除内存碎片的问题,因为这次要申请的内存其实还是很小的,那这么一说是不是可能是GC Locker导致的呢,看起来也不应该,这个要结合上一条GC日志来看,上一条GC日志是
和下一条Full GC相差了蛮久(2069977.519-2069794.281=183.238s),这期间新生代和老生代使用率都不高,可以结合crash日志里的下面内容断定
在Full GC之前,eden使用率也只有55%,因此不太可能在这个期间存在跨GC的情况,因此GC Locker基本没可能。



那最有可能的就是System GC了,那什么情况会导致System GC的发生呢?
稍微总结下以前主要碰到的几种会触发System GC的情况:
- 代码里显示调用
- RMI里定时调用
- 堆外内存不够导致的调用
这几种可能基本都可以排除
- 系统是kafka,是scala写的,我特地下载了scala的源码下来,基本没有这种显示调用System GC的逻辑;
- RMI也不可能,因为我们从线程列表里看不到GC Deamon线程,因此不存在这种check的调用;
- 堆外内存(主要是说DirectByteBuffer这种)也不太可能,因为我们从JVM参数来看,第一没有显示设置最大值MaxDirectMemorySize,第二Xmx设置有24G,那默认的堆外内存最大值基本也有差不多这么大(Xmx除去一个survivor的大小),后面再结合看了下top命令看到的数据的值,物理内存总共都才使用了7G左右,所以堆外内存满了而导致的System GC也基本可以排除。
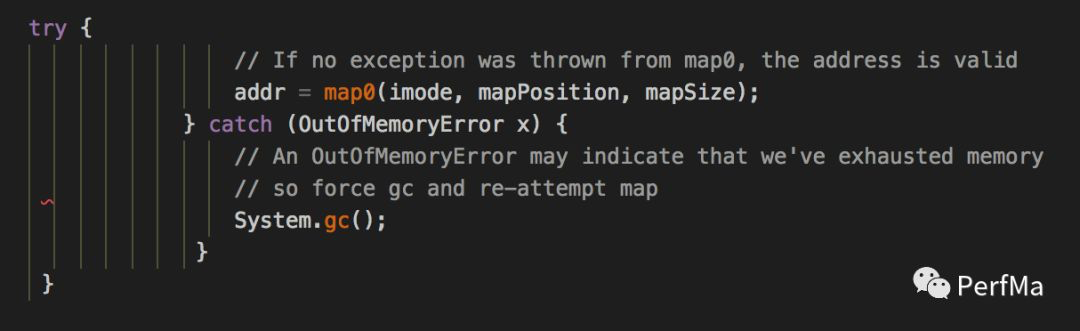
所以我再次翻了下JDK的代码,寻找可能抛出System GC的情况,结果发现了sun.nio.ch.FileChannelImpl的map方法里有类似的逻辑
会不会是这里发生的呢?
确定问题现场
为了确定是否有类似的逻辑调用,于是我在kafka的源码里搜索了map的逻辑调用,果然看到大量的地方调用
似乎柳暗花明了,找业务方确认,还真得知有大量的索引文件映射,并且都是大于1G的,于是我们是否可以设想这么一个场景:kafka映射一个大文件,结果失败了,然后抛出了一个OOM的异常,在catch到这个OOM的异常之后,主动触发了一次System.gc,从而这就是当时crash发生的整个现场。

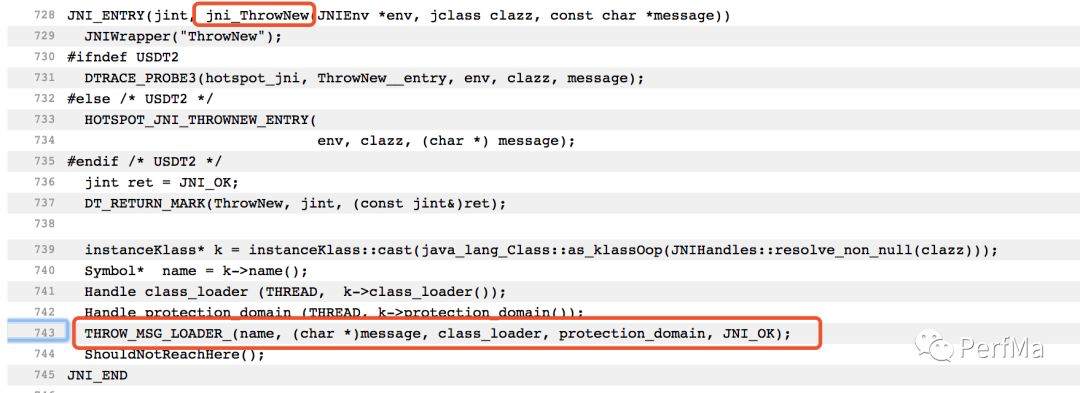
我们从crash日志里找到了类似的日志

这个时间点和Full GC的时间点基本一致,差不多可以认为是上面这个事件发生的时候接着做了一次Full GC,那基本可以笃定jni.cpp:743应该是一个OOM的异常处理,于是我找到这个JDK版本的这行代码的位置,验证确实如此
因此基本也确定业务系统是直到这个地方发生了crash,要验证这个只能是有那个时候的线程,比如有crash时候的heapdump或者coredump,然后找到引发Full GC的那个线程,看它的调用栈是不是正好在做这块的操作。
确定根本原因
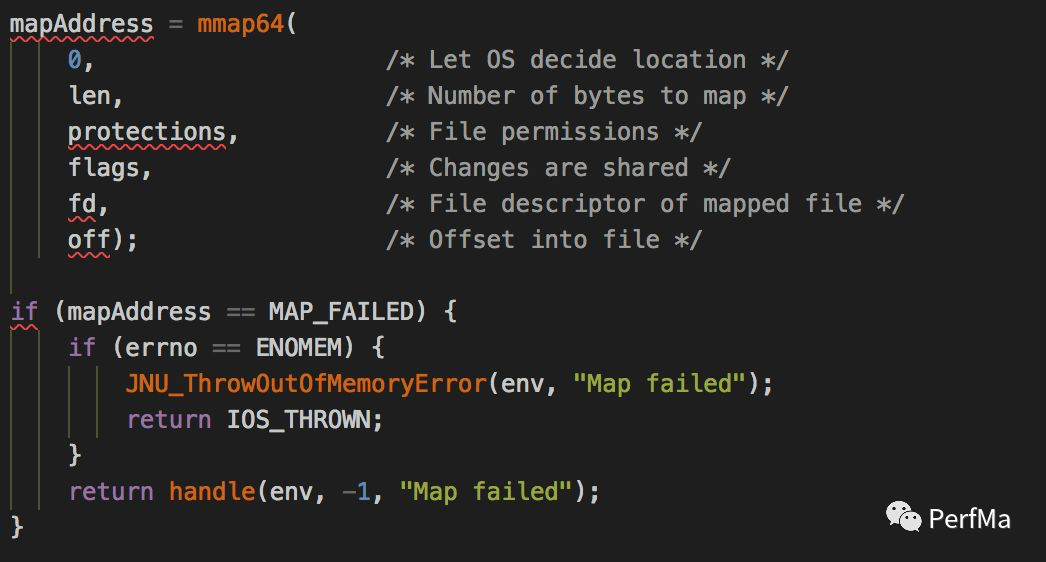
问题发生的点确认了,那接下来我们要寻找根本原因,我们看下sun.nio.ch.FileChannelImpl.map0的native方法实现Java_sun_nio_ch_FileChannelImpl_map0,因为这是触发crash的地方,然后看到下面的逻辑
因为确实是抛出了一个OOM的异常,因此我们这里完全可以确定mmap返回的errno是ENOMEM,所以我们在前面提出的,想把标准输出打印出来以确认具体的mmap异常,从这个地方也基本可以确认mmap就是因为返回了ENOMEM这个错误码,我们先看下mmap的手册里关于ENOMEM的介绍
因为我们确认了物理内存是足够的,因此我们只能怀疑是否达到了mappings的最大个数,我们再结合下kernel里的mmap的实现(mmap.c:do_mmap)
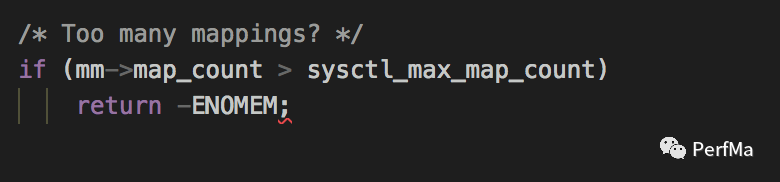
当mmap的vma个数达到了最大值的时候确实也会返回ENOMEM,于是我们要业务方确认下/proc/sys/vm/max_map_count的值,结果发现是65530,也就是说我们mmap的vma最多只能是65530个,我们再结合下crash日志里虚拟地址映射的个数,正好达到了这个上限了,具体可以看看Dynamic libraries下面的条数有多少基本就是mmap的vma的个数。
至此我们完全确认了整个问题。

问题解决
从上面分析解决问题的方法有两个
- 增大系统限制/proc/sys/vm/max_map_count
- kafka的索引文件是否不需要一直有?是否可以限制一下
问题总结
上面的过程是我思考的一个过程,可能过程有些绕,不过我这里可以来个简单的概述,描述下整个问题发生的过程:
kafka做了很多索引文件的内存映射,每个索引文件占用的内存还很大,这些索引文件并且一直占着没有释放,于是随着索引文件数的增多,而慢慢达到了物理内存的一个上限,比如映射到某个索引文件的时候,物理内存还剩1G,但是我们要映射一个超过1G的文件,因此会映射失败,映射失败接着就做了一次System GC,而在System GC过程中因为PermSize和MaxPermSize不一样,从而导致了在Full GC完之后Perm进行扩容,在扩容的时候因为又调用了一次mmap,而在mmap的时候check是否达到了vma的最大上限,也就是/proc/sys/vm/max_map_count里的65530,如果超过了,就直接crash了。
这只是我从此次crash文件里能想像到的一个现场,当然其实可能会有更多的场景,只要是能触发mmap动作的地方都有可能是导致crash的案发现场,比如后面又给了我一个crash文件,是在创建线程栈的时候因为mmap而导致的crash,完全和OOM没有关系,所以根本原因还是因为kafka做了太多的索引文件映射,导致mmap的vma非常多,超过了系统的限制,从而导致了crash。



