
【云原生•监控】基于Prometheus的云原生集群监控(理论+实践)-02原创
【云原生•监控】基于Prometheus的云原生集群监控(理论+实践)-02
k8s资源对象指标
kube-state-metrics
cAdvisor主要是底层容器运行时的性能指标,并没有kubernetes集群资源对象的状态指标,比如我们想了解服务运行状态、Pod有没有重启、伸缩有没有成功、Pod的状态是怎么样的等,kubernetes提供了一个kube-state-metrics组件可以用来暴露这些指标。
kube-state-metrics 只是一个简单的服务,该服务通过监听API Server订阅各类资源对象的变更生成有关资源对象的最新状态指标,比如Deployment、Daemonset、StatefulSet、Node、Pod、Container、Service等。它不关注 Kubernetes 节点组件的运行状况,而是关注集群内部各种资源对象的运行状况,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,所以我们可以使用prometheus来抓取这些数据然后存储。
cAdvisor 已经被 Kubernetes 默认集成,而kube-state-metrics并没有被默认集成,所以我们要想监控集群完整数据,就需要在 kubernetes 中单独部署kube-state-metrics组件,这样才能够将集群中的服务资源指标数据暴露出来,以便于对不同资源进行监控。
kube-state-metrics组件部署比较简单,不过需要注意版本兼容的问题:
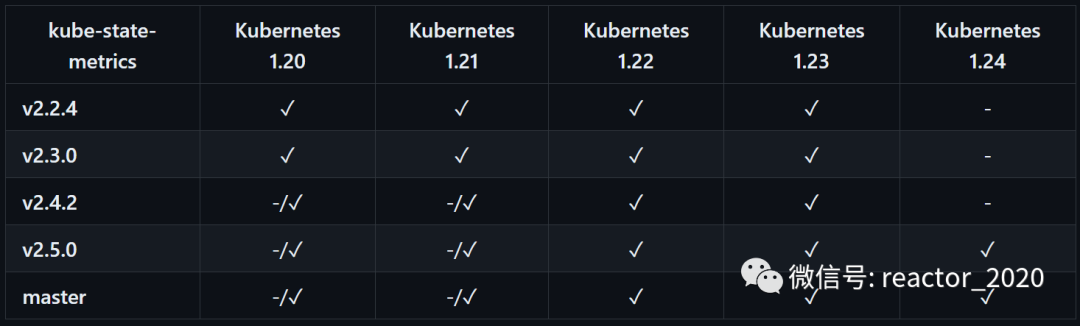
我的kubernetes版本是v1.21.0,所以这里选择kube-state-metrics版本v2.3.0。
部署
1、在master节点上创建目录kube-state-metrics,并将kube-state-metrics-2.3.0.tar.gz解压包中examples/standard目录下文件拷贝到kube-state-metrics目录中:
[root@k8s-01 kube-state-metrics]# ls -alh
总用量 20K
drwxr-xr-x 2 root root 135 6月 19 16:02 .
drwxr-xr-x 4 root root 54 6月 19 15:57 ..
-rw-r--r-- 1 root root 418 6月 19 16:02 cluster-role-binding.yaml
-rw-r--r-- 1 root root 1.7K 6月 19 16:02 cluster-role.yaml
-rw-r--r-- 1 root root 1.2K 6月 19 16:02 deployment.yaml
-rw-r--r-- 1 root root 234 6月 19 16:02 service-account.yaml
-rw-r--r-- 1 root root 447 6月 19 16:02 service.yaml
❝由于
❞kube-state-metrics组件需要通过与kube-apiserver连接,并调用相应的接口去获取kubernetes集群数据,这个过程需要kube-state-metrics组件拥有一定的权限才能成功执行这些操作。在kubernetes中默认使用RBAC方式管理权限,所以,我们需要创建相应的 RBAC 资源来提供该组件使用。
2、修改镜像:
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
labels:
k8s-app: kube-state-metrics
spec:
replicas: 1
selector:
matchLabels:
k8s-app: kube-state-metrics
template:
metadata:
labels:
k8s-app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: bitnami/kube-state-metrics:2.0.0
securityContext:
runAsUser: 65534
ports:
- name: http-metrics ##用于公开kubernetes的指标数据的端口
containerPort: 8080
- name: telemetry ##用于公开自身kube-state-metrics的指标数据的端口
containerPort: 8081
❝❞
k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0这个镜像是特别注意的,因为前缀是k8s.gcr.io,所以是pull不了的需要,改为registry.cn-beijing.aliyuncs.com/zhaohongye/kube-state-metrics:v2.3.0。
3、创建部署:
[root@master kube-state-metrics]# kubectl apply -f ./
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
serviceaccount/kube-state-metrics created
service/kube-state-metrics created
4、查看是否允许成功:
[root@k8s-01 ~]# kubectl get pod -n kube-system -l app.kubernetes.io/name=kube-state-metrics -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-state-metrics-5dc49b696-rssx8 1/1 Running 0 11m 192.165.179.4 k8s-02 <none> <none>
[root@master kube-state-metrics]# kubectl get svc -n kube-system |grep kube-state-metrics
kube-state-metrics ClusterIP None <none> 8080/TCP,8081/TCP 50m
5、验证/metrics端点是否可以采集指标:
[root@master kube-state-metrics]# curl 192.165.179.4:8080/metrics
❝访问
❞kube-state-metrics组件的pod ip+8080端口。
prometheus接入
/metrics端点可以采集到指标数据,说明kube-state-metrics组件部署正常,下面就可以使用prometheus接入。
1、该组件创建了svc名称kube-state-metrics,所以可以采用service的endpoints服务发现协议,配置如下:
- job_name: 'kube-state-metrics'
metrics_path: metrics
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: kube-state-metrics
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: http-metrics
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
❝参见
❞prometheus部署一节,prometheus的配置放到prometheus-config这个ConfigMap中。并将configmap-reload容器以sidecar模式部署到prometheus容器部署到一起,我们只需要修改prometheus-config这个ConfigMap,configmap-reload容器会自动监听变更,然后拉取最新的配置并热更新到prometheus。
2、查看prometheus的web页面下target信息,接入正常:

3、grafana中导入14518 dashboard,kube-state-metrics性能监控指标就展示到模板上。
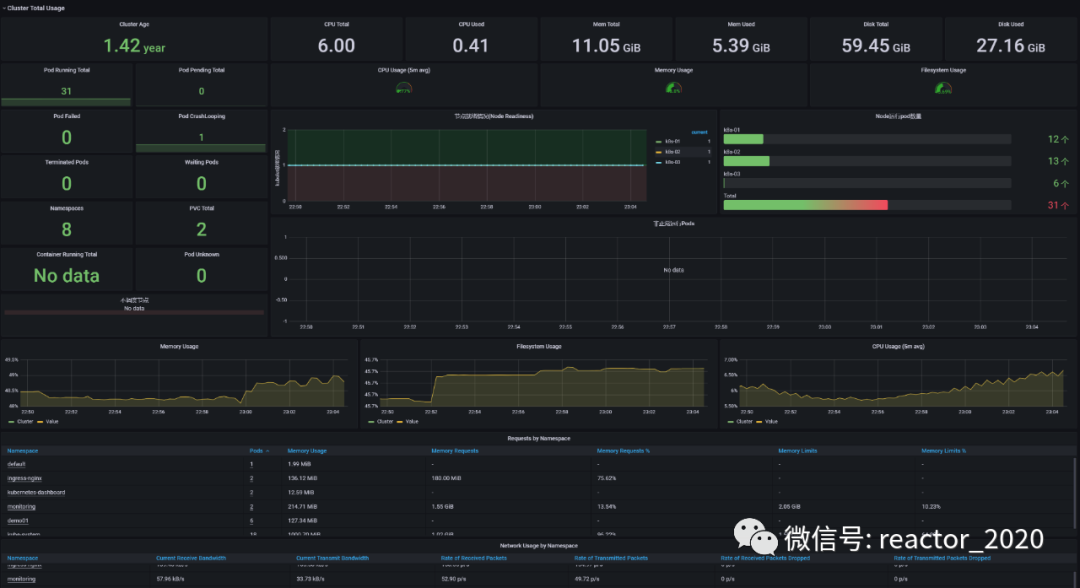
a、如集群Node节点性能指标,如CPU、内存、网络IO、磁盘IO、磁盘等监控信息:

b、如集群中各种资源对象统计,比如各种状态Pod数量统计、namespace数量、pvc数量、node节点上运行pod统计,namespace资源申请统计等等。
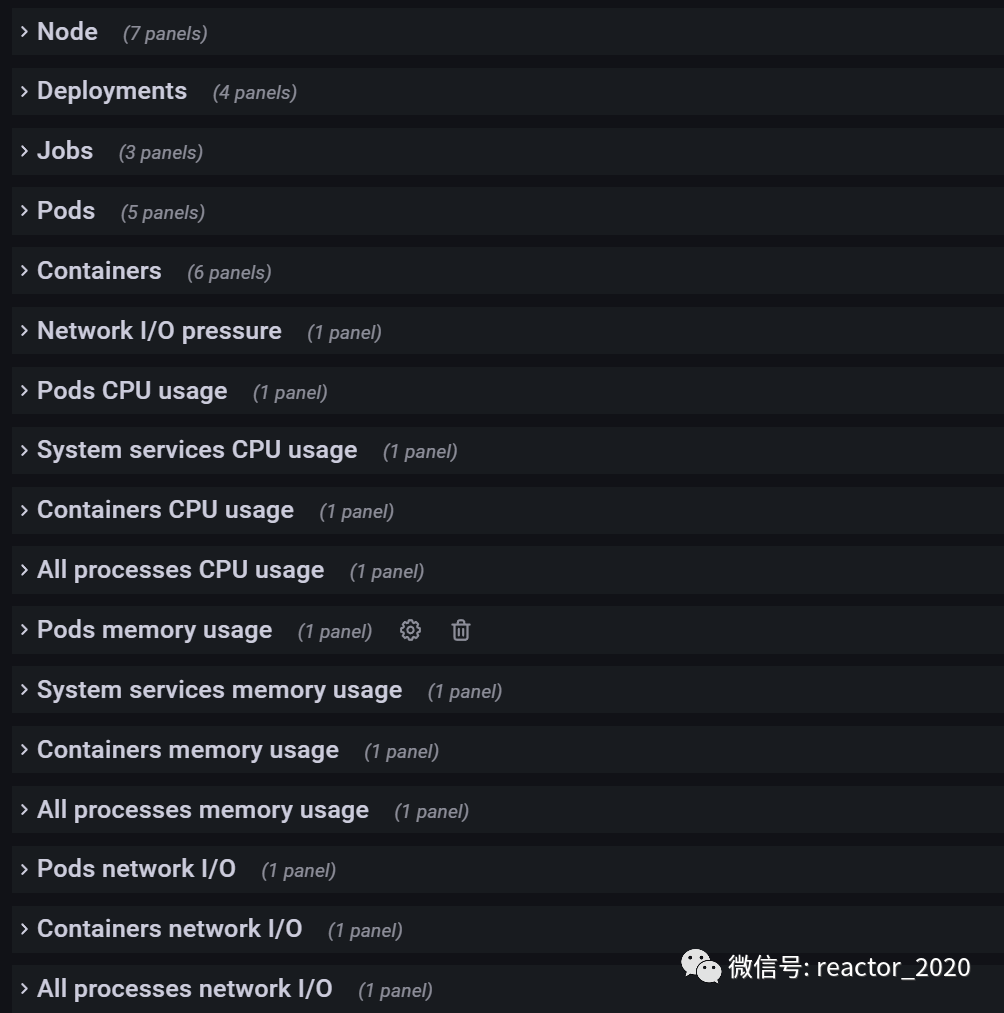
c、更多资源监控如下:
metrics-server
和kube-state-metrics组件经常容易混淆的还有一个组件metrics-server,下面来看下该组件的作用。
从kubernetes 1.8开始,资源使用指标,如容器的CPU和内存,是通过Metrics API在kubernetes中获取,这些数据可以由用户直接访问,例如通过使用kubectl top命令查看节点、Pod或容器的CPU和内存使用信息, 或者由集群中的控制器,例如VPA、HPA等使用来进行决策,metrics-server组件替代了heapster实现了这套接口,heapster从1.11开始逐渐被废弃。
❝❞
VPA、HPA读书用于扩缩容技术,扩缩容判断的标准是否出现性能问题,metrics-server就是为性能问题提供数据依据。
metrics-server是集群核心监控数据的聚合器,通俗地说,它存储了集群中各节点的监控数据,并且提供了API以供分析和使用。核心原理就是从每个节点上的 kubelet组件Summary API采集指标信息,如下指令就可以获取到k8s-02节点上kubelet组件的summart数据:
# 获取节点 kubelet summary 数据
[root@k8s-01 metrics-server]# kubectl get --raw=/api/v1/nodes/k8s-02/proxy/stats/summary
这里数据就是节点的CPU、内存、网络、文件系统的使用情况,以及更细化的该节点上每个容器的CPU、内存、网络、volume等使用情况,metrics-server组件通过kubelet组件将集群中所有节点的信息都收集汇集到一起,这样在控制台输入kubectl top pods 命令就可以查看到这些信息。
比如查看每个节点的CPU和内存使用情况:
[root@k8s-01 metrics-server]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-01 164m 8% 2172Mi 59%
k8s-02 93m 4% 1631Mi 44%
k8s-03 101m 5% 1489Mi 40%
或者查看Pod的CPU和内存使用情况:
[root@k8s-01 metrics-server]# kubectl top pod --all-namespaces
NAMESPACE NAME CPU(cores) MEMORY(bytes)
default my-nginx-6b74b79f57-gxzx6 0m 4Mi
demo01 nginx 0m 3Mi
demo01 nginx-demo1-7678bcdf48-cwtxk 0m 2Mi
demo01 nginx-demo1-7678bcdf48-f8bhh 0m 2Mi
demo01 nginx-deployment-746fbb99df-lxn7b 0m 1Mi
demo01 probe-deployment-59dd8bb78d-d5ljg 0m 0Mi
demo01 tomcat-deployment-7db86c59b7-bn8zl 2m 129Mi
monitoring grafana-7cfd74ccf5-crcnz 1m 34Mi
monitoring prometheus-7fd7fdb677-4q7d2 4m 160Mi
还可以更细化查看pod里容器的负载:
[root@k8s-01 metrics-server]# kubectl top pod prometheus-7fd7fdb677-4q7d2 --containers -n monitoring
POD NAME CPU(cores) MEMORY(bytes)
prometheus-7fd7fdb677-4q7d2 prometheus 8m 156Mi
prometheus-7fd7fdb677-4q7d2 prometheus-reload 0m 4Mi
这个功能的背后就是metric-server这个组件提供的支持,如果没有部署这个组件,执行kubectl top指令会报错。
「metrics-server关注的是底层容器CPU、内存等性能数据,其来源于kubelet组件,其实来源于kubelet内部集成的cAdvisor组件提供的容器性能指标,即cAdvisor提供的性能指标已经包含metrics-server组件的性能指标,prometheus采集是只需要采集cAdvisor组件,metrics-server不在需要接入prometheus监控。」
部署
1、metrics-server 是扩展的依赖于kube-aggregator,因为我们需要在 APIServer 中添加启动参数--enable-aggregator-routing=true:
# vi /etc/kubernetes/manifests/kube-apiserver.yaml
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=192.168.31.160
- --allow-privileged=true
- --authorization-mode=Node,RBAC
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --enable-admission-plugins=NodeRestriction
- --enable-bootstrap-token-auth=true
- --enable-aggregator-routing=true
- --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt
- --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt
- --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key
- --etcd-servers=https://127.0.0.1:2379
❝如果您未在
master节点上运行kube-proxy,则必须确保kube-apiserver启动参数中包含--enable-aggregator-routing=true。然后,重启
❞kubelet组件:systemctl restart kubelet。
2、下载metrics-server介质:https://github.com/kubernetes-sigs/metrics-server/releases
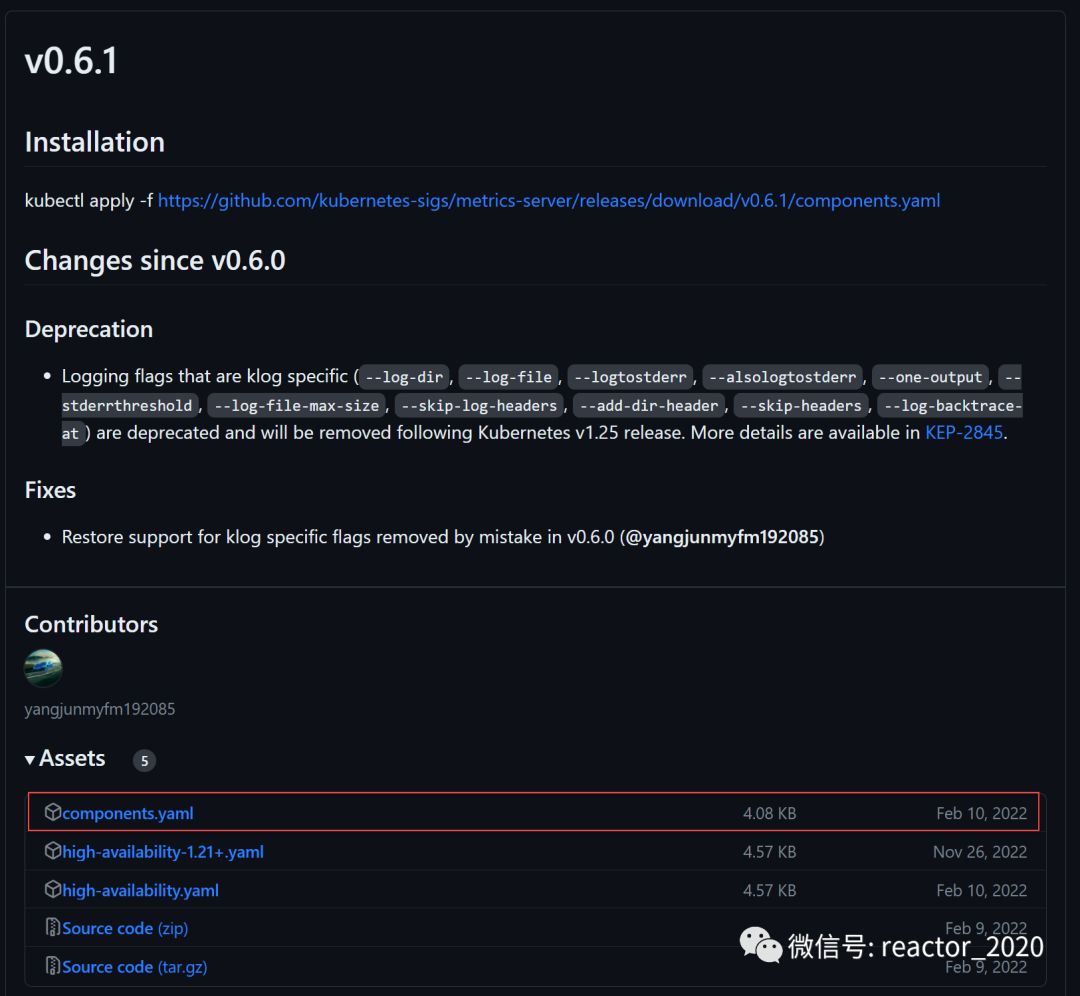
❝我这里下载
❞v0.6.1版本。
3、修改配置:
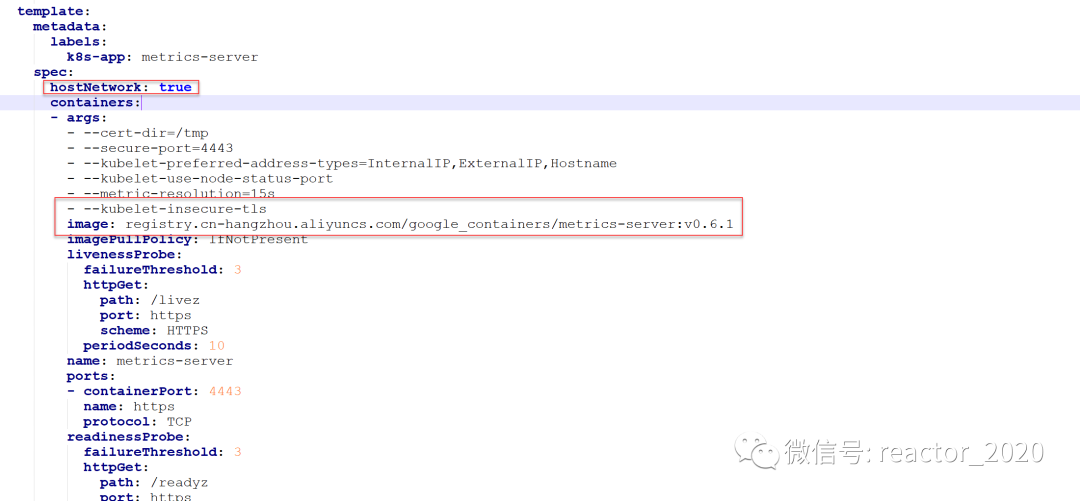
❝注意事项:
1、如果需要忽略 Kubelet certificate ,name只需要在 deployment 的containers.args 中加上 –kubelet-insecure-tls 即可 2、如果在国内,需要将镜像仓库更改为国内的源,例如阿里云的,例如将 k8s.gcr.io/metrics-server/metrics-server 更改为 registry.aliyuncs.com/google_containers/metrics-server。
3、添加配置
❞hostNetwork: true
4、创建部署:
[root@k8s-01 metrics-server]# kubectl apply -f components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
5、查看是否运行成功:
[root@k8s-01 metrics-server]# kubectl get pod -n kube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-5bb7df9c68-x4ttq 1/1 Running 0 3m44s
❝隔个一两分钟就可以看到metrics-server-5bb7df9c68-x4ttq运行成功。
❞
6、执行kubectl top指令验证是否正常:
[root@k8s-01 metrics-server]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-01 164m 8% 2172Mi 59%
k8s-02 93m 4% 1631Mi 44%
k8s-03 101m 5% 1489Mi 40%
「所以,总结下:kube-state-metrics和metrics-server之间还是有很大不同的,kube-state-metrics主要关注的是业务相关的一些元数据,比如Deployment、Pod、副本状态等;metrics-service主要关注的是资源度量API的实现,比如CPU、内存、网络等指标,为kubectl top指令查看性能信息,或为VPA、HPA等组件提供决策指标支持。」

[更多云原生监控运维,请关注微信公众号:云原生生态实验室]

