记一次微服务耗时毛刺排查原创
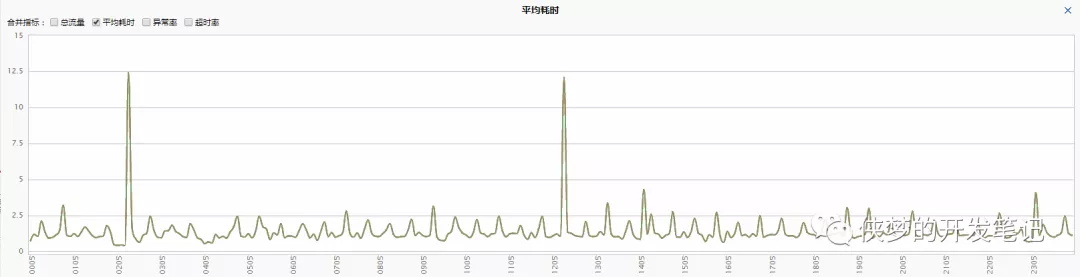
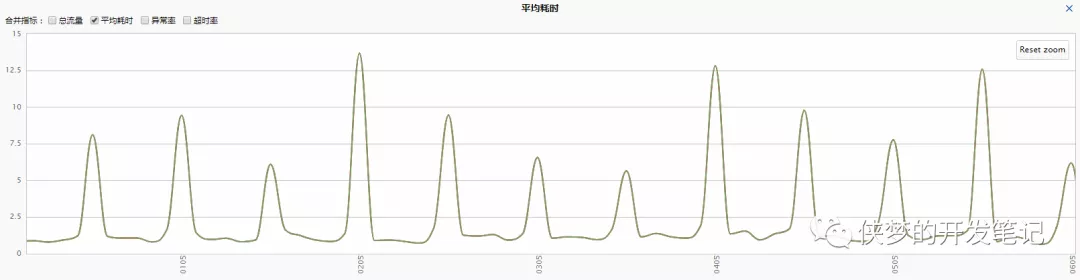
前段时间的某天,注意到一个服务的平均耗时出现了如下图的毛刺现象。

注意到毛刺出现极其规律,每30分钟出现一个毛刺。考虑到这种规律性,并结合服务的流量较小(20 QPS)推测,可能是某个定时请求的接口进行了耗时操作,由于流量较小放大了平均耗时,继而出现了毛刺。但排查主调调用的接口,并没有发现定时的调用,从而否定了这种可能性。
排除服务外部的原因导致的毛刺,那么只剩下服务内部的原因了。该服务为JAVA应用,考虑到服务GC会导致应用暂停,使外部请求耗时异常增长;但是,并不能解释如此规律的毛刺。抱着“死马当活马医”的想法,使用如下命令
jstat -gc pid 3000
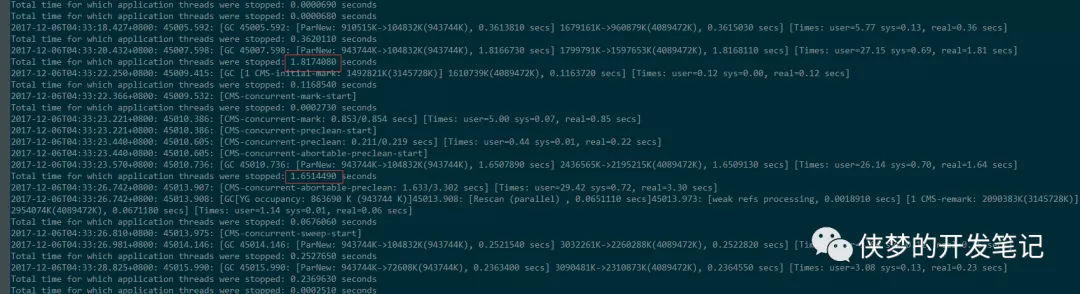
查看了服务的GC情况,结果有了意外发现:产生毛刺时发生了多次GC,GC情况如下图:
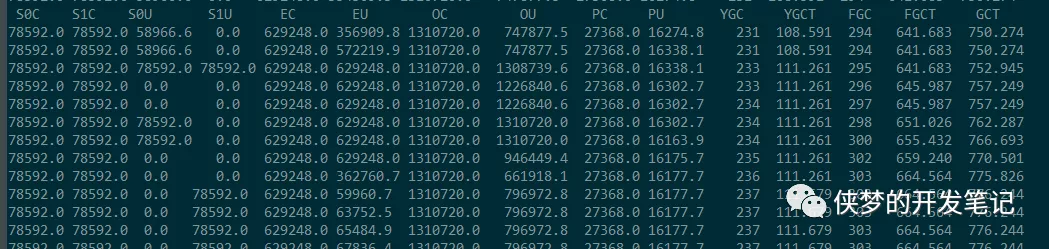
分析数据,得知产生一个毛刺时Young GC进行了237-231=6次,Full GC进行了303-294=9次,Full GC的时间664-641=23秒,可知,正是由于GC停顿了20多秒,从而使得平均耗时显著提高。得益于良好的运维,服务启动时加入了如下参数:
-XX:+UseConcMarkSweepGC -Xloggc:jvm.log -verbosegc -XX:+PrintGCDetails
-XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCTimeStamps
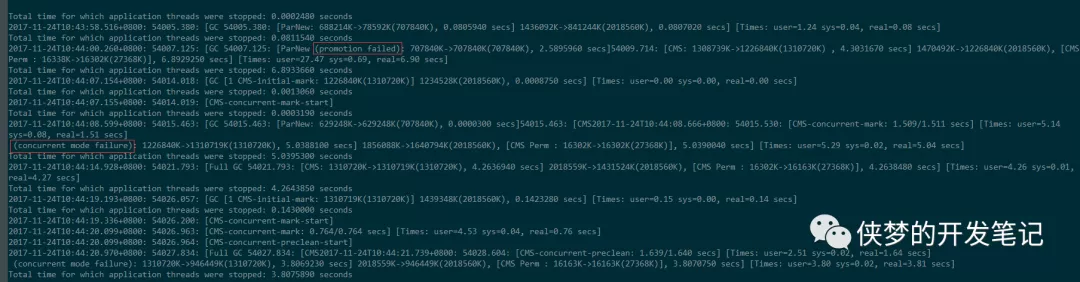
注意到GC时发生了两次失败:Promotion Failed和Concurrent mode Failuer,分别是进程停顿6.8s和5s。截图中省去了部分日志,实际之后还发生了两次Concurrent mode Failuer从而使进程暂停20多秒。
那为什么连GC都如此有规律的每30分钟进行呢?再次排查代码,发现了如下类似的代码:
public static void refresh() {
ConcurrentHashMap<String, Integer> newCache = DBUtil.getCache();
cache = newCache;
log.info("refresh cache, size:" + newCache.size());
}
该服务是一个缓存服务,将数据库中的数据读取到内存,然后提供接口查询。由于数据库中的数据会更新,所以需要固定时间(每30分钟)从数据库重新读取数据,刷新缓存。查询数据库中的数据,发现已经有接近500万行的数据。当加载这部分数据到内存时,内存需求暴涨,JVM进行了多次耗时的GC,导致进程暂停,从而使得请求耗时出现毛刺。
找到了问题出现的原因,开始着手进行优化。由于主要是GC问题,故尝试不修改业务代码,直接修改JVM参数的方式进行优化。在优化之前,需要弄明白Promotion Failed和Concurrent mode Failuer的原因。
晋升失败Promotion Failed的原因主要有:
Survivor区空间不足,Survivor中的对象还不足以晋升到老年代,从年轻代晋升到Survivor的对象大于了Survivor剩余的空间。
从年轻代直接晋升到老年代的对象大于老年代剩余的空间。
由于本例中的对象是突然暴涨的,所以可确定原因为后者,所以需要增大老年代的空间。
并发模式失败Concurrent mode Failuer的原因是:CMS GC回收对象的速度赶不上用户申请对象的速度。当发生并发模式失败后,CMS GC会退回到Serial Old GC使用串行回收,从而使得CMS GC不能发挥作用。解决该问题的方法有:
尽早进行CMS GC即调低-XX:CMSInitiatingOccupancyFraction参数,默认为68
增大老年代空间
由此,将JVM参数由之前的:
-Xmx2048m -Xms2048m -XX:NewSize=768m -XX:MaxNewSize=768m
调整为:
-Xmx3072m -Xms3072m -XX:NewSize=1536m -XX:MaxNewSize=1536m
增大新生代的初衷是为了直接容纳下服务刷新时的临时对象,不需要晋升到老年代。观察原来的老年代大约需要700M所以没有进行大的扩容。修改后的效果如下:
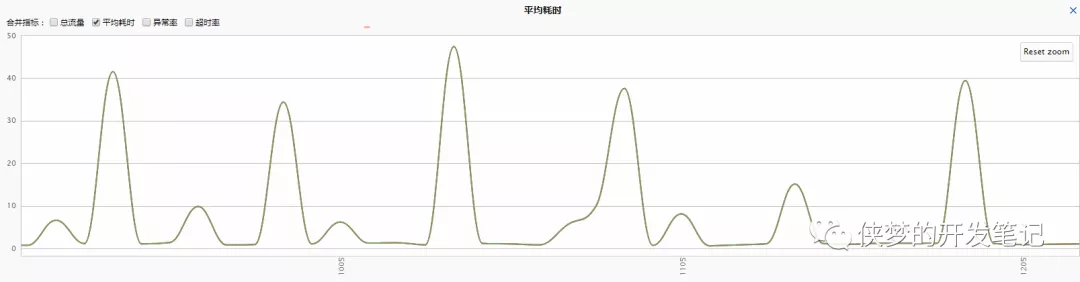
高峰耗时减少一半,但依然存在毛刺。查看GC日志,依然存在一次concurrent mode failure。
继续调整参数,增大老年代:
-Xmx4096m -Xms4096m -XX:NewSize=1024m -XX:MaxNewSize=1024m
整个堆内存从2G扩容到4G,老年代从1.25G扩容到3G,内存已经较为充足。调整后,耗时大幅降低,也没有出现concurrent mode failure,但依然没有消除毛刺现象,效果图如下:
再次查看GC日志,发现耗时主要集中在年轻代回收:
尝试使用UseParallelOldGC加快年轻代回收,但是年老代耗时过长。不能同时使用Parallel Scavenge回收年轻代,CMS回收年老代真是大坑。最后更换为G1 GC大大减少了Full GC,毛刺抖动得到大大缓解,效果如下: