
从X86指令深扒JVM的位移操作原创
概述
之所以会写这个,主要是因为最近做的一个项目碰到了一个移位的问题,因为位移操作溢出导致结果不准确,本来可以点到为止,问题也能很快解决,但是不痛不痒的感觉着实让人不爽,于是深扒了下个中细节,直到看到Intel的指令规约才算释然,希望这篇文章能引起大家共鸣。
本文或许看起来会比较枯燥,不过其实认真看挺有意思的,如果实在看不下去,告诉你一个极简路径,先看下下面的Demo,然后直接跳到后面的小结,如果懂了,别忘记顺便点个赞,请叫我雷锋,哈哈。
Demo
还是从一个简单的例子说起
大家可以尝试做几个改变,看看结果怎样
-
4 << shift改成4L << shift -
将35改成291,PS:提示一下
291=25+256*1
如果上面的各种结果你都能解释,那说明你对位移操作还是有一定了解的,不过本文主要从JVM到Intel X86_64指令角度来分析这个问题,或许也值得一看
JVM里4和4L的区别
要知道区别,我们看doShiftL方法通过javac编译出来的指令有什么不一样
4 << shift的字节码
0: iconst_4
1: iload_0
2: ishl
4L << shift的字节码
0: ldc2_w #34 // long 4l
3: iload_0
4: lshl
针对4和4L的区别,我们看到了两条不同的指令,分别是iconst_4和ldc2_w,其实如果我们将4改成其他的值,可能会有不一样的指令出现
-
-1<= x <=5: iconst_x -
-128<= x <-1 || 5< x <=127:bipush -
-32768 <= x < -128 || 127 < x <= 32767:sipush -
-32768 > x || x > 32767:ldc
不过这些都不是我们今天的重点,不想细说了,就以iconst_4为例来简单介绍下
iconst_4
先看iconst_4的大概汇编指令如下
重点看0x00007fcb529b0b30这条就是将0x4移到EAX寄存器里,这是一个32位的寄存器,需要注意的是这里并没有直接将4 push到操作数栈上,而是在下一条指令(也就是iload_0)执行的时候才预先push到栈上,后面看iload_0的汇编代码可知
ldc2_w
ldc2_w是将long或者double的常量值从常量池推到操作数栈顶,其大概汇编指令如下
重点看0x00007fcb529b1990这条开始,主要就是从常量池里取出相关的值,然后push到操作数栈上(看0x00007fcb529b19c2这行开始的接下来三行)
因此做一个小结:
-
iconst_4:将4存入到EAX寄存器,但是此时还并没有将4 push到操作数栈顶 -
ldc2_w:将后面跟着的值(其实也就会4),存到RAX寄存器,并且将其push到操作数栈顶
着重注意下上面两条指令使用的两个寄存器是不一样的,一个是EAX,一个是RAX,其中RAX是64位寄存器,而EAX是RAX寄存器的低32位,是一个32位寄存器
不过还没结束,对于iconst_4这种情况,什么时候将4 push到栈上呢,那接下来我们看看iload_0这条指令,因为不管是iconst_4还是ldc2_w,后面都跟了iload_0,所以还是一起来看看这条指令
iload_0
iload_0的汇编实现大致如下:

这条指令简单来说就是将方法的0号local槽里的数据存到EAX寄存器里,不过针对上一条指令是iconst_4,此时会先做一个push的动作,将RAX寄存器里的值push到操作数栈上,但是如果是ldc2_w指令的话,就不会做push了,因为这两条指令规定的执行完后的top of stack不一样,iconst_4要求栈顶是一个int,而ldc2_w没要求,尽管在实现里确实将值push到了栈顶
因此在执行完iload_0之后,都已经将4 push到操作数栈顶了,并且将第一个local槽,其实就是doShiftL函数的shift参数存到了EAX寄存器里,具体看上面的0x00007fcb529b1f0f位置的指令
JVM里的位移操作
从上面的字节码里我们看到,当我们位移的基数是4或者4L的时候,分别看到了两条不同的位移指令,分别是ishl和lshl,这两条指令一个是将int型的值左移一定位数,一个是将long型的值左移一定位数,那这两条指令分别有什么区别呢?
JVM里ishl指令实现
先看定义

对于ishl指令主要实现在iop2方法里,并且传递一个参数shl
因此主要实现其实就是
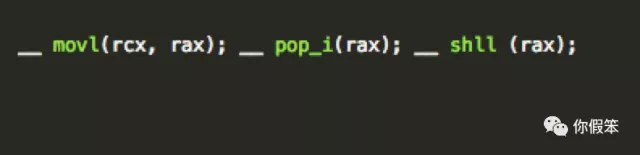
主要是将RAX寄存器里的值(其实就是doShiftL函数的shift参数)存入到RCX寄存器里(注意这里用的movl,其实是用的32位寄存器),然后将操作数栈顶的值(就是上述的4)存到RAX里,并做shll操作!
那问题就来了,这里的0xD3,0xE0到底是什么鬼,不过我们能猜到是做的位移操作,那我们看看ishl完整的汇编代码
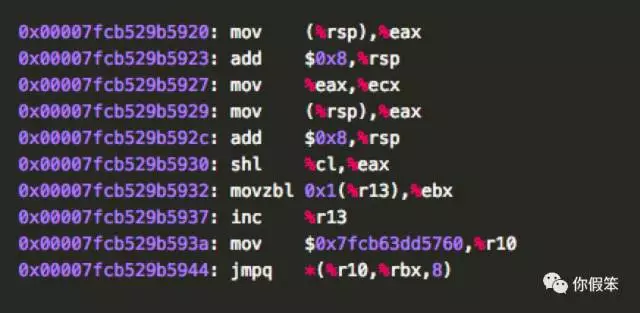
上述的0x00007fcb529b5930其实就应该是上面的Assembler::shll的输出了,里面有CL寄存器(RCX寄存器的低32位是ECX,而ECX的低8位是CL,这个关系清楚了吧)和EAX寄存器,看到这指令其实可以解释了,CL寄存器因为是ECX寄存器的低8位,而我们从上面得知RCX里存的其实是要位移的位数,也就是上面Demo里的doShiftL函数的shift参数值,而EAX寄存器里的值是操作数栈顶的值,也就是4
那现在的问题是明明我们就传了一个RAX的寄存器给Assembler::shll,那怎么操作起CL寄存器来了,这其实就是我想写本文的根本原因,我想解释这个现象,还想知道0xD3,0xE0到底是什么鬼,于是找了intel指令手册,看到SHL指令这样的描述
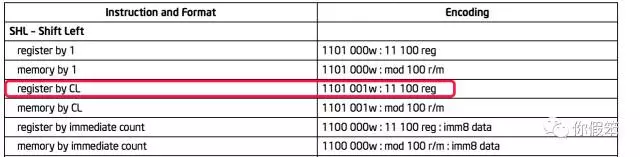
0xD3的二进制表示是1101 0011,和上面的1101 001w是匹配的,这个w应该是如果是寄存器寻址,那就是1吧
0xE0的二进制表示是1110 0000,和上面的11 100 reg是匹配的,也就是reg占3位,那问题是寄存器个数并不只有8个,因此超过8个的情况怎么表示呢,那来看看encode的过程
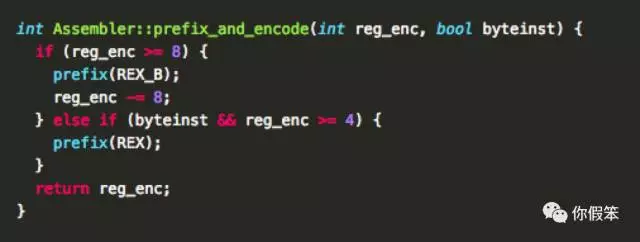
这里的关键其实就是prefix的值了,通过设置prefix来看是否使用了普通寄存器之外的寄存器,这个大家网上可以找找相关资料看看,是X86的扩展64位技术
另外从上面的规范里我们看到了CL寄存器,也就是shl命令本身就是和CL寄存器紧密结合实现的(其中一种寻址方式而已),另外将shel之后的结果存到EAX寄存器里,再次提醒下是32位的寄存器,而和下面说的lshl的最大区别就是其使用的其实是64位的RAX寄存器,因此两者表示的最大值显然不一样啦
JVM里lshl指令实现
先看定义

lshl指令主要实现在lshl方法里
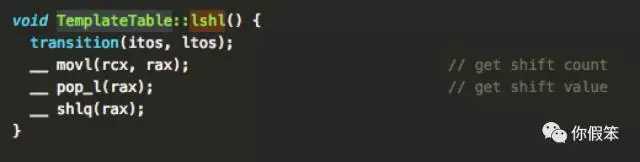
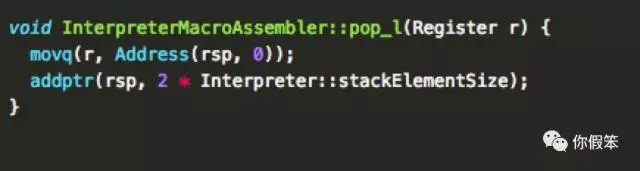
而pop_l的实现如下,使用了movq,也就是移动栈上的双字(8byte=64位,用RAX寄存器存)到寄存器里,注意上面的ishl使用的是movl,是移动长字到寄存器里(即4byte=32位,正好用EAX寄存器存),
lshl的汇编实现:
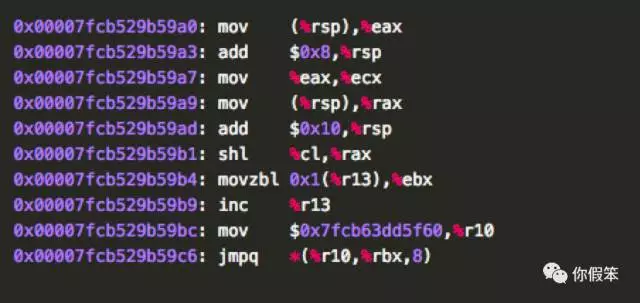
从这里也印证了确实用了RAX寄存器(请看0x00007fcb529b59b1)
总结
这篇文章因为涉及到太多的汇编指令,可能不少人看起来不是很明白,不过我觉得你可以多看几遍啦,看多了也许就看懂了,不过实现看不下去没关系,就看看小结吧
-
当我们要位移的基数的类型是long的时候,其实是用64位的RAX寄存器来操作的,因此存的最大值(2^64-1)会更大,而如果基础是int的话,会用32位的EAX寄存器,因此能存的最大值(2^32-1)会小点,超过了阈值就会溢出
-
使用了8位的CL寄存器来存要位移的位数,因此最大其实就是2^8-1=255啦,所以上述demo,如果我们将shift的参数从35改成291发现结果是一样的



