
前言
最近看到了这样的一篇文章, 一个对象的引用占多少个字节呢?4个?8个?算出来都不对 , 呵呵 这是一个之前想要弄明白, 但是这块的代码似乎是看着有点复杂, 所以 一直没有花时间来整理一下, 呵呵最近看到了一篇文章, 看了一下 R大的分析
然后 自己结合自己的 实际情况, 整理了一下 些东西
以下代码, 截图 基于 jdk9
首先是测试用例
package com.hx.test04;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* TypeSizeOf
*
* @author Jerry.X.He <970655147@qq.com>
* @version 1.0
* @date 2020-03-07 16:04
*/
public class Test05TypeSizeOf {
// fields
private long id = 1;
private Test05TypeSizeOf test2 = null;
private List<Test05TypeSizeOf> list = new ArrayList<>();
private Date date = new Date();
private byte status = 2;
private byte count = 3;
// refer : https://hllvm-group.iteye.com/group/topic/38670
// -ea -javaagent:/Users/jerry/Tmp/agent/HelloWorld-1.0-SNAPSHOT_agent.jar
// vm 调试相关参数为 -da -dsa -Xint -Xmx100M -XX:+UseSerialGC -javaagent:/Users/jerry/Tmp/agent/HelloWorld-1.0-SNAPSHOT_agent.jar com.hx.test04.Test05TypeSizeOf
public static void main(String[] args) {
long sizeOfTest05TypeOfSizeOf = Test01PremainAgentClazz.inst.getObjectSize(new Test05TypeSizeOf());
System.out.println(sizeOfTest05TypeOfSizeOf);
}
}
测试结果如下

第一个输出是 javaagent 里面的输出, 第二个输出是 这里 main 方法里面的输出
那么, 这里输出的结果是 40, 好了 我们现在知道了 Test05TypeSizeOf 会占用 40个 字节, 那么 他又是如何计算的呢, 在内存中是如何排列的呢 ?
布局的计算方式?
classFileParser.layout_fields 相关代码片段如下
int nonstatic_oop_space_count = 0;
int nonstatic_word_space_count = 0;
int nonstatic_short_space_count = 0;
int nonstatic_byte_space_count = 0;
int nonstatic_oop_space_offset = 0;
int nonstatic_word_space_offset = 0;
int nonstatic_short_space_offset = 0;
int nonstatic_byte_space_offset = 0;
// Try to squeeze some of the fields into the gaps due to
// long/double alignment.
if (nonstatic_double_count > 0) {
int offset = next_nonstatic_double_offset;
next_nonstatic_double_offset = align_size_up(offset, BytesPerLong);
if (compact_fields && offset != next_nonstatic_double_offset) {
// Allocate available fields into the gap before double field.
int length = next_nonstatic_double_offset - offset;
assert(length == BytesPerInt, "");
nonstatic_word_space_offset = offset;
if (nonstatic_word_count > 0) {
nonstatic_word_count -= 1;
nonstatic_word_space_count = 1; // Only one will fit
length -= BytesPerInt;
offset += BytesPerInt;
}
nonstatic_short_space_offset = offset;
while (length >= BytesPerShort && nonstatic_short_count > 0) {
nonstatic_short_count -= 1;
nonstatic_short_space_count += 1;
length -= BytesPerShort;
offset += BytesPerShort;
}
nonstatic_byte_space_offset = offset;
while (length > 0 && nonstatic_byte_count > 0) {
nonstatic_byte_count -= 1;
nonstatic_byte_space_count += 1;
length -= 1;
}
// Allocate oop field in the gap if there are no other fields for that.
nonstatic_oop_space_offset = offset;
if (length >= heapOopSize && nonstatic_oop_count > 0 &&
allocation_style != 0) { // when oop fields not first
nonstatic_oop_count -= 1;
nonstatic_oop_space_count = 1; // Only one will fit
length -= heapOopSize;
offset += heapOopSize;
}
}
}
int next_nonstatic_word_offset = next_nonstatic_double_offset +
(nonstatic_double_count * BytesPerLong);
int next_nonstatic_short_offset = next_nonstatic_word_offset +
(nonstatic_word_count * BytesPerInt);
int next_nonstatic_byte_offset = next_nonstatic_short_offset +
(nonstatic_short_count * BytesPerShort);
int next_nonstatic_padded_offset = next_nonstatic_byte_offset +
nonstatic_byte_count;
// let oops jump before padding with this allocation style
if( allocation_style == 1 ) {
next_nonstatic_oop_offset = next_nonstatic_padded_offset;
if( nonstatic_oop_count > 0 ) {
next_nonstatic_oop_offset = align_size_up(next_nonstatic_oop_offset, heapOopSize);
}
next_nonstatic_padded_offset = next_nonstatic_oop_offset + (nonstatic_oop_count * heapOopSize);
}
classFileParser.layout_fields 这里是布局的处理, 默认情况下 allocation_style = 1
并且 我们这里存在 一个 long/double 字段, "id"
将数据分为了两批, 一个批次是 *_space_count[Word, Short, Byte, Oop], 是存放在 align_size_up(markOop + klass, BytesPerLong) 的空隙
另外的一部分 : longs/doubles, ints, shorts/chars, bytes, oops, padded fields, 排列
对于我们这里的场景, 如下
对应于我们这里的 Test05TypeSizeOf 的实际情况, 布局大致如下
markOop[8] + klass[4]
byte status[1]
byte count[1]
padding[2]
long [8]
test2 [4]
list [4]
date [4]
padding [4]
合计 40 bytes, 5 word运行时的数据?
那么我们理论上得到了数据的排列如下, 那么我们看一下 实际的运行时的一些情况呢 ?
HSDB attach 到目标进程, inspect Test05TypeSizeOf 的实例
inspect 0x0000000795969ab8
Oop for com/hx/test04/Test05TypeSizeOf @ 0x0000000795969ab8
_mark: 1
_metadata._compressed_klass: InstanceKlass for com/hx/test04/Test05TypeSizeOf
id: 1
test2: null
list: Oop for java/util/ArrayList @ 0x0000000795969ae0
date: Oop for java/util/Date @ 0x00000007959831f8
status: 2
count: 3
查看一下 的内存数据呢 ?
mem 0x0000000795969ab8 5
0x0000000795969ab8: 0x0000000000000001
0x0000000795969ac0: 0x00000302f800c354
0x0000000795969ac8: 0x0000000000000001
0x0000000795969ad0: 0xf2b2d35c00000000
0x0000000795969ad8: 0x00000000f2b3063f
# 数据拆解如下
0x0000000795969ab8 : 0x0000000000000001 为 markOop
0x0000000795969ac0 : 0xf800c354 为 compressedKlass
0x0000000795969ac4 : 0x02 为 status
0x0000000795969ac5 : 0x03 为 count
0x0000000795969ac6 : 0x0000 为 padding
0x0000000795969ac8 : 0x0000000000000001 为 id
0x0000000795969ad0 : 0x0000000 为 test2
0x0000000795969ad4 : 0xf2b2d35c 为 list
0x0000000795969ad8 : 0xf2b3063f 为 date
0x0000000795969ae0 : 0x0000000 为 padding但是 发现一个问题, 为什么记录的 数据的地址 和 给定的对象的 oop 的地址不一样呢 ?
compressedOops 相关
从上面可以看到, 实际存储的 oop 的地址数据 和 给定的 oop 的真实地址是不一样的, 那么这是怎么回事呢?, 两个数据又有什么关联呢 ?
实际存储的 list 地址为 0xf2b2d35c, list 的真实地址为 0x0000000795969ae0
这是因为一个 UseCompressedOops 特性, 那么我们来看下 压缩之后的地址 和 原来的地址的关系吧
oop.decode_heap_oop_not_null 相关实现如下
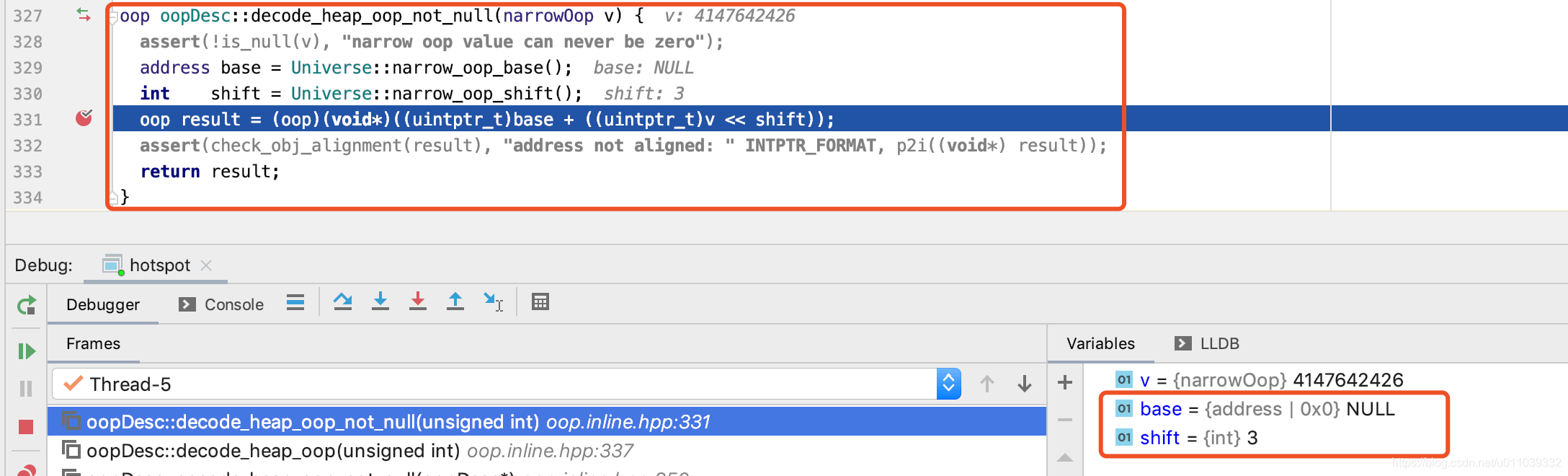
我们这里, base 为 0, shift 为 3 (<< 3 等价于 * 8[字长])
base, shift 初始化的地方在这里
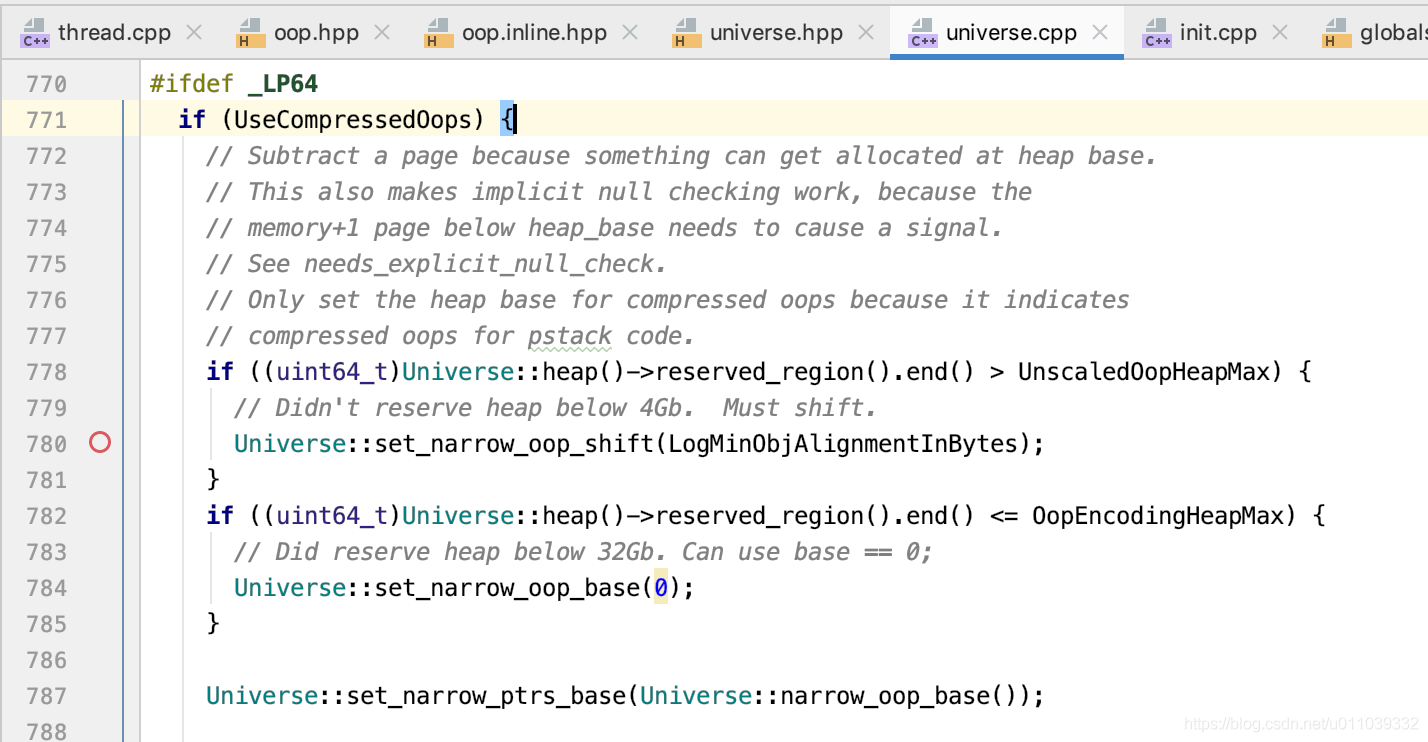
至于 base 为什么是 0, shift 是 3, 我们可以暂时不深究
好了, 两者之间的关系大概就是这样, 那么 apply 到这里的实际情况呢 ?
实际存储的 list 地址为 0xf2b2d35c, list 的真实地址为 0x0000000795969ae0
0xf2b2d35c * 8 = 0x795969ae0
那么同理 另外一个 date 的地址记录的是 0xf2b3063f, date 的真实地址为 0x00000007959831f8
0xf2b3063f * 8 = 0x7959831f8
好了, 这里的相关东西 大概就这些了
======================= add at 2020.05.31 =======================
一下内容引用自R大的文章 Oracle JDK从6 update 23开始在64位系统上会默认开启压缩指针
HotSpot VM现在只使用3种模式的压缩指针:
1、当整个GC堆所预留的虚拟地址范围的最高的地址在4GB以下的时候,使用"zero based Compressed Oops, 32-bits Oops"模式,也就是基地址为0、shift也为0;
2、当GC堆的最高地址超过了4GB,但在32GB以下的时候,使用"zero based Compressed Oops"模式,也就是基地址为0、shift为 LogMinObjAlignmentInBytes (默认为3)的模式;
3、当GC堆的最高地址超过了32GB,但整个GC堆的大小仍然在32GB以下的时候,使用非零基地址、shift为 LogMinObjAlignmentInBytes (默认为3)的模式。
如果上面三种情况都无法满足,那压缩指针就无法使用了。
上述三种模式的名字在Universe类里有声明:
hotspot/src/share/vm/memory/universe.hppC++代码
- // Narrow Oop encoding mode:
- // 0 - Use 32-bits oops without encoding when
- // NarrowOopHeapBaseMin + heap_size < 4Gb
- // 1 - Use zero based compressed oops with encoding when
- // NarrowOopHeapBaseMin + heap_size < 32Gb
- // 2 - Use compressed oops with heap base + encoding.
- enum NARROW_OOP_MODE {
- UnscaledNarrowOop = 0,
- ZeroBasedNarrowOop = 1,
- HeapBasedNarrowOop = 2
- };
哎, 可惜我这里 场景1 和 场景3 构造不出来
参考
一个对象的引用占多少个字节呢?4个?8个?算出来都不对



