
来这公司一年碰到的问题比我过去10年都多原创
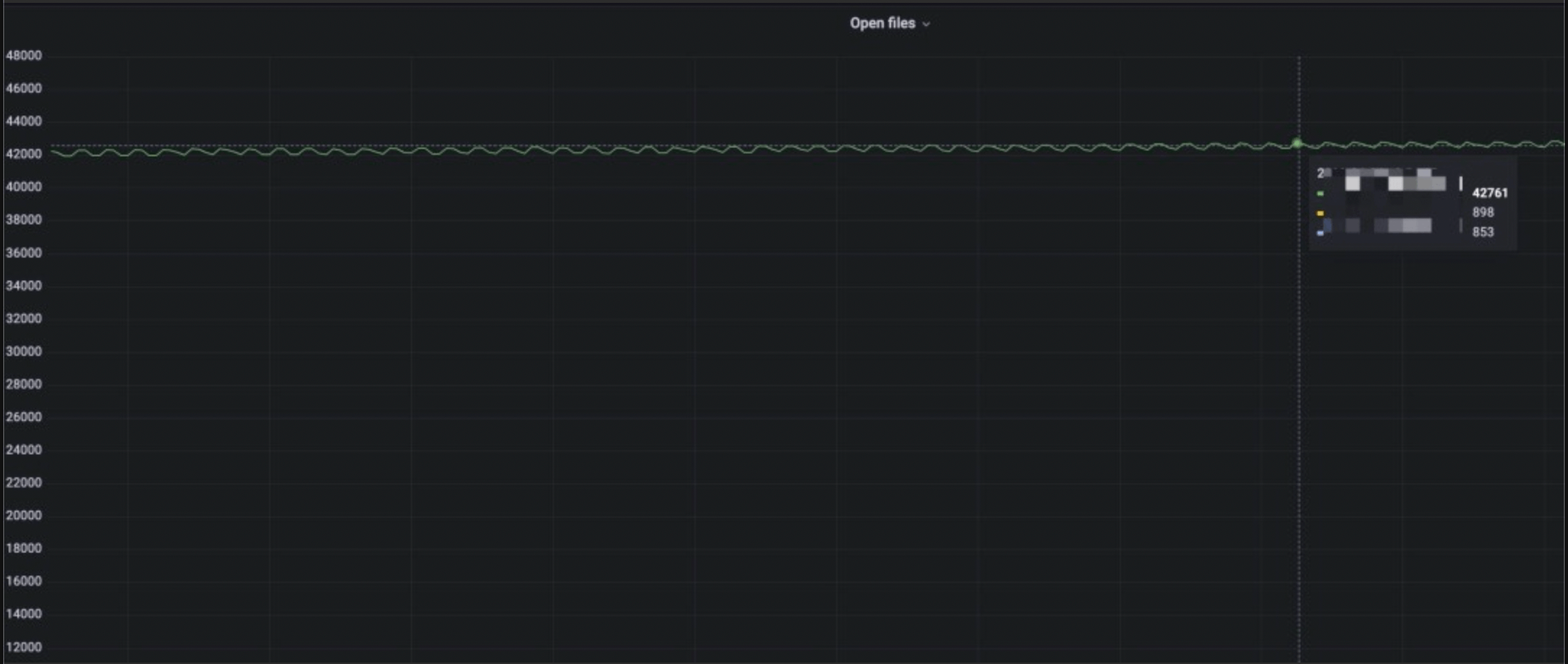
无意间发现我们 Kafka 管理平台的服务的 open files 和 CPU 监控异常,如下图,有一台机器 CPU 和 opfen files 指标持续在高位,尤其是 open files 达到了4w+。

原因分析
第一反应是这个服务请求很高?但是这个服务是一个管理服务不应该有很高的请求量才对,打开监控一看,QPS少的可怜。

既然机器还在就找 devops 同学帮忙使用 Arthas 简单看下是什么线程导致的,竟然是 GC 线程,瞬时 CPU 几乎打满了。

查看了 GC 监控,每分钟 5~6 次相比其他的正常节点要多很多,并且耗时很长。
问题节点GC Count

正常节点GC Count

应该是代码出问题了,继续求助 devops 将线上有问题的机器拉了一份 dump,使用 MAT 工具分析了下,打开 dump 就提示了两个风险点,两个都像是指标相关的对象。

查看详情发现两个可疑对象,一个是 60+M 的 byte[], 一个是 60+M 的 map,都是指标相关的对象,问题应该出在指标上。

初步去排查了下代码,看是否有自定义指标之类的,发现一个 job 会对指标进行操作,就把 job 停了一段时间,GC 少了很多,但是 open files 只减少了一点点, 很明显不是根本原因。


继续深入,将 byte[] 保存成字符串查看(确实文本也有60+M),发现全是 JMX 的指标数据,我们的系统使用了两种指标一种是Micrometer,一种是 prometheus-jmx-exporter,这个 byte[] 数组就是第二种指标的数据。

并且这些指标中发现有非常多的 kafka_producer 开头的指标。

为了验证是否属于 JMX 的指标数据,再次求助 devops 拉取线上有问题机器的 JMX 指标接口, 看返回的是否是 60M+ 的指标数据,发现根本拉不下来。

到此基本确认问题出在 JMX 指标上, 那这些指标谁注册的呢?
通过指标名称在源代码里搜索,发现是来自org.apache.kafka.common.network.Selector.SelectorMetrics,是 kafka-client注册的指标。
具体的创建顺序如下,每创建一个KafkaProducer,就会以 client id 为唯一标识创建一个SelectorMetrics, 而创建 KafkaProducer 会创建一个守护线程,并开启一个长连接定时去 Broker 拉取/更新 Metadata 信息,这个就是open files飙高的根本原因。
KafkaProducer -> Sender -> Selector -> SelectorMetrics

难道创建了很多 KafkaProducer???查看构造方法调用的地方,找到了真凶。。。

这段代码是为了支持延迟消息,业务服务每发一个延迟消息,就会执行一次这段逻辑, 就会创建一个 KafkaProducer,并且会随着收到的消息越来越多导致创建的 KafkaProducer 越来越多,直至系统无法承受。。。
庆幸的是我们延迟消息并不是太多,没有直接把系统给打挂掉
那为什么只有一个节点会有问题,其他节点没有问题呢?这个比较简单直接说结果了,就是这段消费逻辑消费的 topic 只有一个分区....
解决方案
由于 Kafka 管理平台会连接多个 Broker,所以此处将创建的 KafkaProducer 根据 Cluster 缓存起来进行复用。
问题总结
-
1. KafkaProducer 本身是一个很重的对象,并且线程安全,创建的时候注意考虑场景
-
2. 此次问题完全是凭运气提前发现了,证明监控系统也存在不够完善的地方, 我们使用 Prometheus 的标准差函数 (stddev() by()) 配置了资源严重倾斜的监控告警,防止出现类似的问题。


