
【云原生 • Prometheus】图解Prometheus数据抓取原理原创
- scrape加载流程
- 组件关系
图解Prometheus数据抓取原理
discovery模块利用各种服务发现协议发现目标采集点,并通过channel管道将最新发现的目标采集点信息实时同步给scrape模块,scrape模块负责使用http协议从目标采集点上抓取监控指标数据。
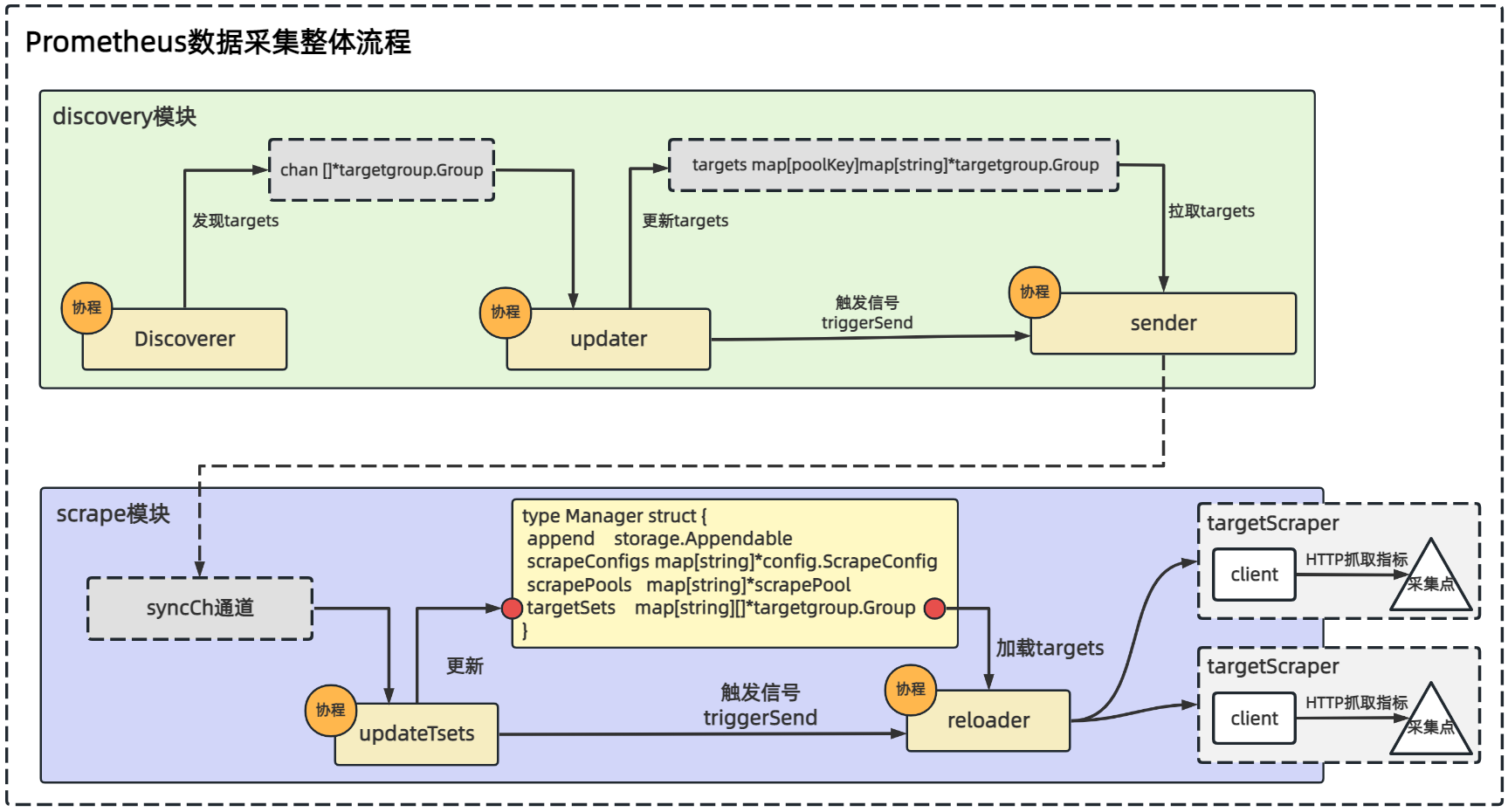
如上图,discovery服务发现模块经过Discoverer组件 --> updater组件 --> sender组件,将服务发现采集点实时动态发送到syncCh通道上,而该通道的另一端就是scrape模块,这样discovery模块和scrape模块就构建起了关联。
scrape模块updateTsets组件通过协程方式运行实时监听syncCh通道,并将更新写入到scrapeManager结构体中targetSets字段对应的map中,同时触发triggerSend信号给reloader组件,告诉该组件采集点有更新,reloader组件就从scrapeManager中targetSets中拉取最新采集点进行加载。
reloader组件基于这些采集点信息生成一个个targetScraper组件,targetScraper组件组件主要负责按照job中配置的interval时间间隔不停轮训调用采集点的HTTP接口,这样就实现了采集点的指标数据采集。
scrape加载流程
下面来看下scrape模块reloader加载采集点具体流程,如下图:
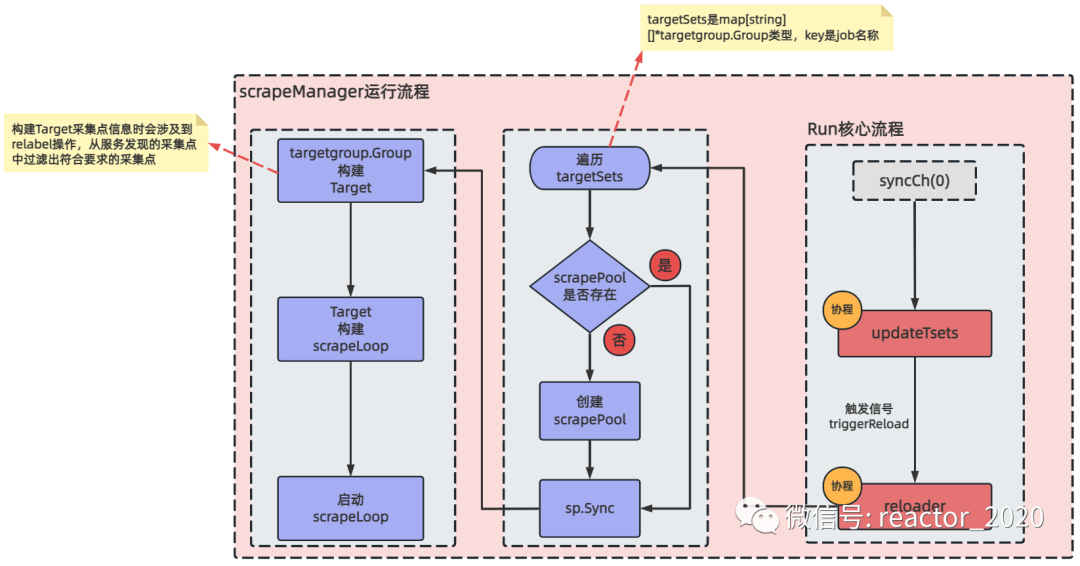
「reloader采集点加载主要分为如下几个主要步骤:」
「1、scrapePool生成并初始化基础数据:」
scrapeManager结构体中targetSets字段对应的map中存放了当前服务发现的最新采集点信息,key是job名称,遍历该targetSets中存放的采集点信息,为每个job对应生成一个scrapePool结构体的实例,即scrapePool是封装单个抓取job的工作单元:
ScrapePools 是单个的Job的抓取目标的工作单位:
type scrapePool struct {
//存储指标
appendable storage.Appendable
//一个scrapePool对应一个job,config即为该job配置
config *config.ScrapeConfig
// 基于job配置生成http请求客户端工具,比如封装认证信息等
client *http.Client
//每个target都会生成一个loop
loops map[uint64]loop
//target_limit检查
targetLimitHit bool
//relabe后有效的采集点
activeTargets map[uint64]*Target
//relabel后无效采集点
droppedTargets []*Target
//生成scrapeLoop工厂函数
newLoop func(scrapeLoopOptions) loop
}
每个抓取job生成的scrapePool存放在scrapeManager结构体中scrapePools这个map中:
scrapePools map[string]*scrapePool
「2、targetgroup.Group构建Target:」
上面生成的scrapePool中主要初始化config、client等信息,并没有涉及到抓取采集点数据,然后对生成的scrapePool执行Sync方法,入参就是该抓取job当前所有采集点信息,这个方法就是对job的采集点信息进行处理:
func (sp *scrapePool) Sync(tgs []*targetgroup.Group)
遍历采集点,通过targetsFromGroup(tg, sp.config)解析采集点返回[]*Target,
var all []*Target
sp.droppedTargets = []*Target{}
for _, tg := range tgs {
//基于targetgroup.Group构建target集合
targets, err := targetsFromGroup(tg, sp.config)
if err != nil {
level.Error(sp.logger).Log("msg", "creating targets failed", "err", err)
continue
}
for _, t := range targets {
if t.Labels().Len() > 0 {//relabel后符合要求的采集点
all = append(all, t)
} else if t.DiscoveredLabels().Len() > 0 {//relabel后不符合要求的采集点:废弃
sp.droppedTargets = append(sp.droppedTargets, t)
}
}
}
Target结构体主要字段如下,即将服务发现的采集点信息解析成scrape模块的Target信息,解析过程中会涉及relabel操作,从服务发现的目标采集点中过滤出符合要求的真实采集点,一个Target即代表一个将要真实触发Http请求对象:
type Target struct {
//服务发现标签,即未经过relabel处理的标签
discoveredLabels labels.Labels
//经过relabel处理之后标签
labels labels.Labels
//http请求参数
params url.Values
//采集点状态:up、down、unknown
health TargetHealth
}
「3、有效Target生成scrapeLoop:」
「Target只是包含采集点信息,scrapeLoop实现loop接口,封装了发送http请求采集数据指标逻辑的Target执行单元:」
type loop interface {
run(interval, timeout time.Duration, errc chan<- error)
setForcedError(err error)
stop()
getCache() *scrapeCache
disableEndOfRunStalenessMarkers()
}
其中run方法就是启动http数据抓取,入参interval指定循环抓取指标间隔;stop方法则是停止http数据采集。
我们来看下Target如何生成scrapeLoop:
if _, ok := sp.activeTargets[hash]; !ok {
//生成targetScraper,其中封装了Target和client
//Target封装了采集点请求IP、端口、请求参数等信息,通过这些信息构建HTTP请求Request
//client是封装了认证信息的http请求客户端工具,用于将http请求request发送出去
s := &targetScraper{Target: t, client: sp.client, timeout: timeout}
l := sp.newLoop(scrapeLoopOptions{
target: t,
scraper: s,
limit: limit,
honorLabels: honorLabels,
honorTimestamps: honorTimestamps,
mrc: mrc,
})
...
}
if _, ok := sp.activeTargets[hash]; !ok {
//sp.activeTargets不存在则表示新发现的采集点,则创建scrapeLoop
//生成targetScraper,其中封装了Target和client
//Target封装了采集点请求IP、端口、请求参数等信息,通过这些信息构建HTTP请求Request
//client是封装了认证信息的http请求客户端工具,用于将http请求request发送出去
s := &targetScraper{Target: t, client: sp.client, timeout: timeout}
l := sp.newLoop(scrapeLoopOptions{
target: t,
scraper: s,
limit: limit,
honorLabels: honorLabels,
honorTimestamps: honorTimestamps,
mrc: mrc,
})
sp.activeTargets[hash] = t
sp.loops[hash] = l
uniqueLoops[hash] = l
} else {
//sp.activeTargets存在则可能:
//1、重复的采集点:直接忽略即可
//2、之前发现并启动的采集点:设置uniqueLoops[hash] = nil,则后续启动loop时不用启动
//target在sp.activeTargets已存在,但是uniqueLoops不存在,说明该采集点之前就被发现过并被启动,当前发现的和之前一致未变
//uniqueLoops[hash] = nil表示当前还是存在,但是不需要启动,后面对于sp.activeTargets存在但是uniqueLoops中不存在的采集点,则为采集点消失,需要停止loop并移除掉
if _, ok := uniqueLoops[hash]; !ok {
uniqueLoops[hash] = nil
}
sp.activeTargets[hash].SetDiscoveredLabels(t.DiscoveredLabels())
}
uniqueLoops存储当前抓取job所有有效采集点,不在该集合中的采集点需要停止并移除,如之前存在的采集点,但是当前又消失不见的采集点:
for hash := range sp.activeTargets {
//uniqueLoops存储当前抓取job所有有效采集点,不在该集合中的采集点需要停止并移除,如之前存在的采集点,但是当前又消失不见的采集点
//uniqueLoops中value=nil的是不需要启动,之前服务发现过并被启动的;value不是nil则表示需要启动
if _, ok := uniqueLoops[hash]; !ok {
//移除
wg.Add(1)
go func(l loop) {
l.stop()
wg.Done()
}(sp.loops[hash])
delete(sp.loops, hash)
delete(sp.activeTargets, hash)
}
}
scrapeLoop中还有个关键的类型targetScraper,它才是真正执行http请求组件,其实现scraper接口(如下),其中scrape就是一次http请求逻辑封装:
type scraper interface {
scrape(ctx context.Context, w io.Writer) (string, error)
Report(start time.Time, dur time.Duration, err error)
offset(interval time.Duration, jitterSeed uint64) time.Duration
}
「4、启动scrapeLoop:」
最后,执行scrapeLoop的run方法,启动scrapeLoop组件:
for _, l := range uniqueLoops {
if l != nil {
go l.run(interval, timeout, nil)
}
}
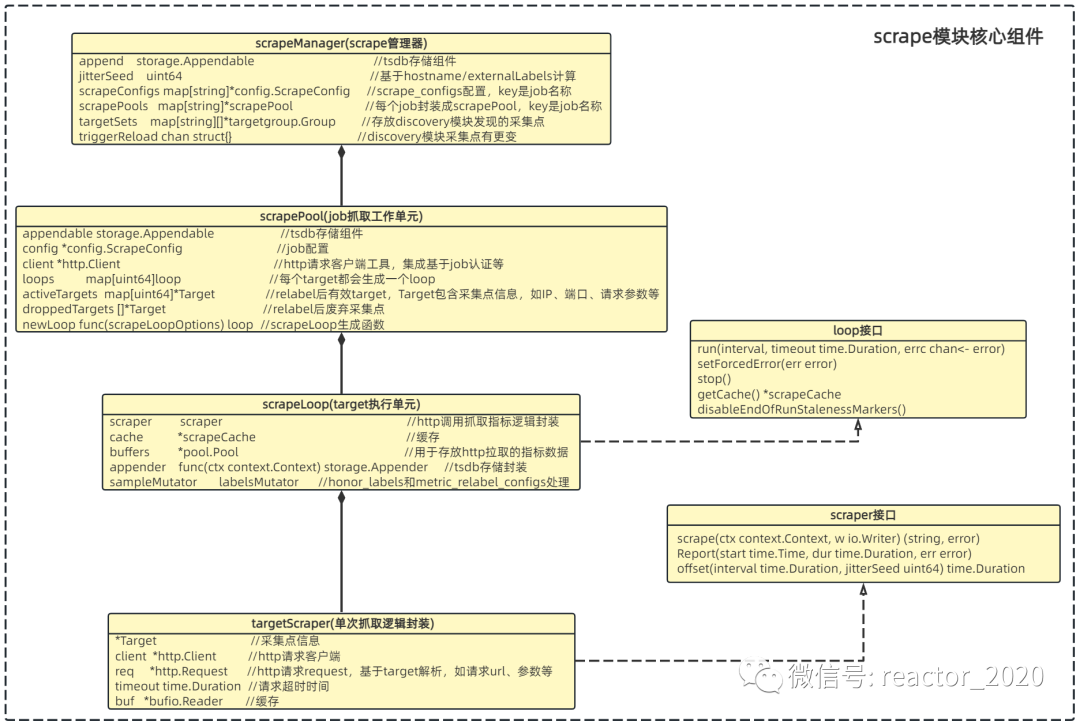
组件关系
「scrape模块加载流程关键是几个核心组件创建、初始化及启动运行的过程:」

[更多云原生监控运维,请关注微信公众号:Reactor2020]


