JVM coredump分析系列(1):OOM导致的crash分析原创
0. 前言
笔者近期遇到多个内存 OOM 导致的crash,因为内存问题发生的原因不仅牵涉 JVM 还涉及到操作系统底层,在此整理一下相关的原理和分析思路,以便今后发生类似的问题可以有一个参考。通常内存 OOM 是由于 OS 内存不足或者配置参数限制导致的,因此本文将从这两个方面入手分别阐述问题发生时的现象以及排查方法。
1. 系统内存紧张导致的 OOM
从 hs_error 文件的头部内容可以看到 OOM 的报错信息:

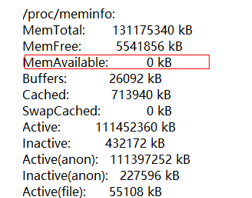
然后在 hs_error_log 的内存信息这一块的可以看到相关的内存使用情况,可以发现 available 已经为 0,那么大概率就是系统分配不出内存导致 OOM。
OOM (Out of Memory) 指 Linux 在无可用内存时的一个最后策略。当系统中可用内存过少时,OOM killer 会选择 kill 某些进程,来释放这些进程所占用的内存。接下来介绍一下 Linux 环境下内存不足导致 OOM 的触发条件和相关配置。
1.1 何时触发OOM killer
现代内核通常在分配内存时,允许申请的内存量超过实际可分配的 free 内存,这种技术称为 Overcommit,可以认为是一种内存超卖的策略。开启了 Overcommit,其实是基于一个普遍的规律——大部分应用并不会将其申请的内存全部用满——来尽量提升内存的利用率,可以允许系统分配出的内存总和超过系统能提供之和(物理内存 + Swap空间),但是这种做法也导致 OOM 的风险。
Overcommit 的策略可以通过内核参数 vm.overcommit_memory 来进行控制,表示内核在分配内存时候做检查的方式。这个变量可以取到 0,1,2 三个值。对取不同值时的处理方式都定义在内核源码 mm/mmap.c 的 __vm_enough_memory 函数中。
-
0 表示由内核控制 Overcommit,它将检查是否有足够的可用内存供进程使用。内核会根据当前系统可用虚拟内存来判断是否允许内存申请,如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
-
1 永远允许 Overcommit,此时宏为 OVERCOMMIT_ALWAYS,函数直接 return 0,分配成功。这种策略适合那些不能承受内存分配失败的应用,比如某些科学计算应用。
-
2 永远禁止 Overcommit,此时宏为 OVERCOMMIT_NEVER,在这个情况下,系统所能分配的内存不会超过
swap+RAM*系数,其中系数由 /proc/sys/vm/overcmmit_ratio 控制,默认50%,可以调整。如果这么多资源已经用光,那么后面任何尝试申请内存的行为都会返回错误,这通常意味着此时没法运行任何新程序。注意: overcommit_memory=2 就意味着关闭了OOM killer!生产环境下并不推荐:如果遇到内存完全无法分配的情况而又无法通过 OOM 来释放进程占用的内存,可能会触发不可预期的行为,比如内核 panic、服务器 hang 死等。
内存 Overcommit 量可以通过 vm.overcommit_ratio 和 vm.overcommit_kbytes 进行配置。vm.overcommit_ratio 是指定了一个比例,而vm.overcommit_kbytes 是指定一个绝对大小值。通过 /proc/meminfo 中的 Commit 值可以看到当前生效的比例和值。例如:
CommitLimit: 101037524 kB //内存分配上限,CommitLimit = 物理内存 * overcommit_ratio(默认50,即50%) + swap大小
Committed_AS: 152507000 kB //是已经分配的内存大小
overcommit_memory 的系统默认值是0,overcommit_ratio 的默认值是50。所以实际中会遇到相同配置的机器,相同的程序一个可以申请到内存,一个不可以申请到。这时候可以看看 overcommit_memory 的值是否被修改了。
1.2 Kill 哪个进程
OOM killer 的目标是选出最佳进程(一个或者多个)去 kill,最佳进程的选择需要考量一次 kill 释放出最多的内存,同时这些进程对系统的重要性也要最小。为实现这个目标,内核对每个进程维护了一个评分 oom_score,可以通过 /proc/<PID>/oom_score 看到,分数越高则被 kill 的可能性越大。
1.3 诊断OOM
OOM killer 会将 kill 的信息记录到系统日志 /var/log/messages,检索相关信息就能匹配到是否发生了 OOM。可以通过以下命令查看系统日志中记录的 OOM信息:
grep 'Out of memory' /var/log/messages
例如 EulerOS 的 message 文件中可以找到以下的信息:

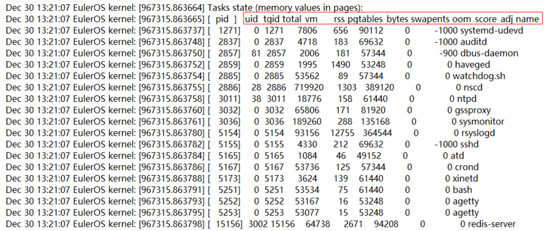
再往下可以看到 OOM 时各个进程的内存使用情况(pid 和 rss):
接下来还可以看到 OOM killer 杀死的进程情况:

1.4 其它影响系统可用内存的参数
vm.min_free_kbytes 是用于 linux 内核的可调参数。系统可能需要预留一定内存以确保系统本身的正常运行。如果内核允许分配所有内存,则在需要额外内存进行常规操作以保持操作系统平稳运行时,它可能会遇到困难。这就是内核提供可调 vm.min_free_kbytes 的原因。该可调参数将强制内核的内存管理器保留至少一定数量的空闲内存。此参数会影响操作系统的 available Memory 的大小,因此如果设置过大的话会造成明明系统还有大量的未使用内存,但是却发生 OOM 的现象。
2.非系统内存不足导致的OOM
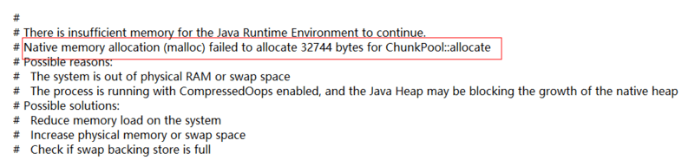
以上是系统内存不足的情况下可以查看到的日志和记录,如果发现当时系统内存还很充足,并且在 OS 日志中并未发现 OOM 的告警信息,那么很有可能是别的系统参数做了限制,例如下图的 hs_error_log 所示:
在 meminfo 块中可以看到其实内存还有很大的余量:
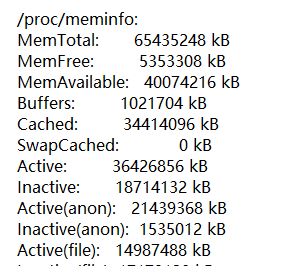
分析 JVM 的 chunckpool 代码发现,它会通过 malloc 向系统申请内存,当 malloc 返回 null 即申请不到足够内存时由 JVM 主动抛出 OOM 错误并终止进程。而 malloc 或者 mmap 申请不到内存的原因很有可能就是触碰到了操作系统的某些参数对于用户进程做的限制,因为此时并非发生了系统错误,所以在系统日志中无法找到 OOM 的错误信息,此时问题就会比较复杂和难以定位,需要一一排查对应的参数,分析最大的可能性。
有些系统日志中可能会打印 exceed limit 之类的提示信息,容易被忽略,也可以开启尝试 strace 跟踪系统调用,strace 日志中有可能会提示出错的原因,如下图所示:

下面介绍几个比较常见的可能造成 JVM 发生 OOM 错误的系统参数。
2.1 /proc/sys/vm/max_map_count
max_map_count 文件包含限制一个进程可以拥有的 VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。此参数会影响 malloc 和 mmap 等系统调用,它的默认值为 65536,可以使用下面的命令查看当前系统设置的值:
cat /proc/sys/vm/max_map_count

也可以使用以下命令查看某个进程的 map 数量:
cd /proc/pid;cat maps | wc -l
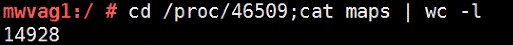
通过持续观察当前进程 map 数量以及和进程 map 总数限制作比较推测是否由这个参数导致的问题。
参数修改方式:
sysctl -w vm.max_map_count=xxxxx
然后同步修改配置文件 /etc/sysctl.conf 里面的 vm.max_map_count。
2.2 /etc/security/limits.conf 中的一些配置
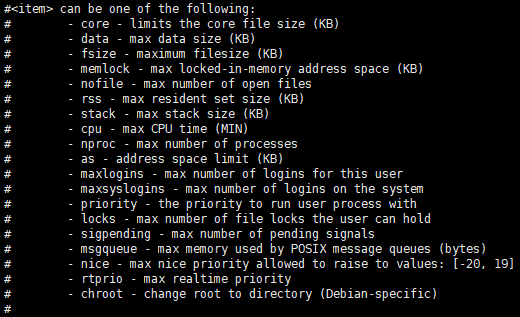
在此文件中与内存限制相关的可以重点关注以下几项:
-
max data size 配置 data segment 空间,默认为 ulimited,单位KB。此选项可以限制进程在 heap 空间可以申请的内存大小。 -
max resident set size(Ignored in Linux 2.4.30 and higher) 配置进程最大物理内存大小。 -
address space limit 限制进程虚拟内存大小。
由于进程启动后这些 limit 可能会被更改,所以查看进程受到的 limit 需要在 /proc/{pid}/limits 中查看,例如:
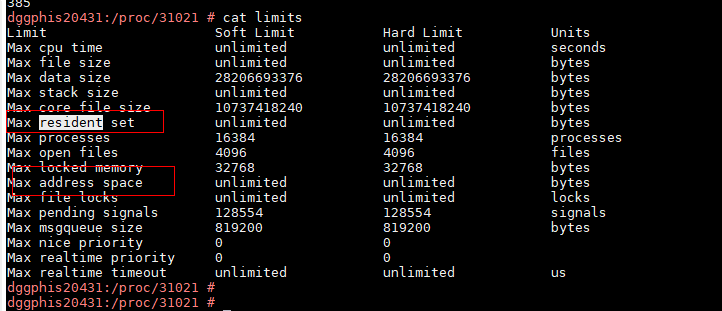
通过将进程实际使用的内存大小和进程受到的内存限制进行对比来确认是否是由 limits 导致的 OOM。一般可以使用 atop -m 命令查看进程占用的各块内存段的大小:
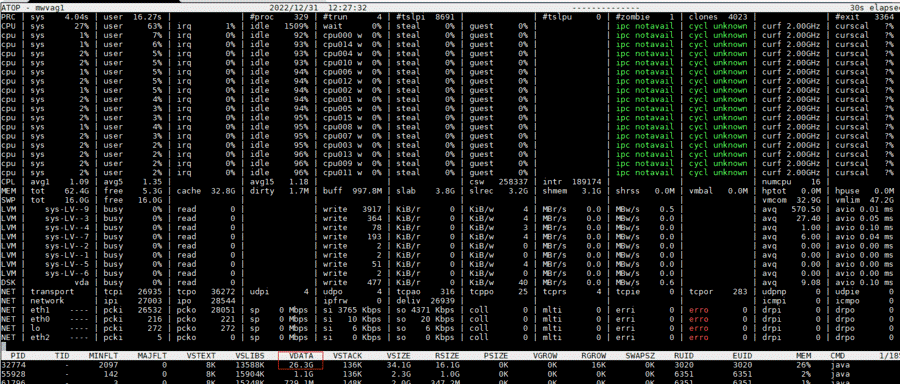
如上图 VDATA 已经达到 26.3G,而进程的 max data size limit 是 28206693376 byte=26.26G,因此基本可以确定进程是由于达到了 max data size limit 而发生 OOM。
2.3 其他可能造成影响的系统参数
有时候 JVM 发生 OOM 的 core dump 并非一定是内存受限导致的,例如 hotspot 在创建内部工作线程失败的时候也会直接报出 OOM ERROR,下面就是两条当这种情况发生时可能会在 hs_error 日志中找到的报错信息:
-
Cannot create GC thread. Out of system resources -
java.lang.OutOfMemoryError: unable to create new native thread
线程创建失败有可能是内存不足也有可能是受到了系统参数的限制,以下就是几个常见的可以限制线程创建的参数:
-
/proc/sys/kernel/threads-max:每个进程中最多创建的线程数目 -
/proc/sys/kernel/pid_max:系统中最多分配的 pid 数量 -
/etc/security/limits.conf 中的 nproc:限制了用户可创建的进程数量(在 linux 中更准确的说是线程数量)
另外,systemd 也提供了一个基于 cgroup 的限制资源使用的机制:
-
TasksMax
在 systemd 的 service 文件中可以设置 TasksMax 值来限制最大任务数,在 cgroup 中即 pids.max 值。 -
DefaultTasksMax
TasksMax 的默认值由 DefaultTasksMax 指定,在文件 /etc/systemd/system.conf 或者 /etc/systemd/user.conf 都可以设置,分别掌管系统级服务与用户级服务的默认值。 -
UserTasksMax
除了以上两个值以外,还有 UserTasksMax 值,该值限定了从一个 login-shell 中可以运行的任务数,可以在 /etc/systemd/logind.conf 中设置。
参考
-
https://blog.csdn.net/weixin_48101150/article/details/117220082 -
https://www.cnblogs.com/yinguojin/p/16418072.html -
https://cloud.tencent.com/developer/article/2129695 -
https://www.freedesktop.org/software/systemd/man/systemd.resource-control.html#TasksMax=N

Compiler SIG 专注于编译器领域技术交流探讨和分享,包括 GCC/LLVM/OpenJDK 以及其他的程序优化技术,聚集编译技术领域的学者、专家、学术等同行,共同推进编译相关技术的发展。
扫码添加 SIG 小助手微信,邀请你进 Compiler SIG 微信交流群。