
【全网首发】抛砖系列之k8s HorizontalPodAutoscaler(HPA)原创

“大伙得眼里有活,看见同事忙的时候要互相帮助,这样我们团队才能快速成长,出成绩,多干点活没坏处的,领导都看在眼里记在心里,不会亏待大伙。”
看到这也许你还有点懵,不是要讲k8s的HorizontalPodAutoscaler?怎么以一段经典pua开头,哈哈,别着急,接着往下看。
“高可用、高并发、大流量”这些曾经似乎只会出现在互联网业务中的高大上词汇,现在已然是随处可见,不管真实业务场景会不会出现,对外宣称时都会标榜这类特性,要支持这类特性有一个极其基础的能力是必须具备的,那就是扩容,而扩容一般又分为垂直扩容和水平扩容,最为广泛的属水平扩容。
水平扩容俗称加机器,对比现实工作中就是加人,加人从触发方式上来说分为主动和被动,主动就是一些热心肠(眼里有活)的同事看你太忙了过来帮你,这种概率较小,一般来说大概率是领导觉得你忙不过来了把你的活分一部分出去给其他人,这种就是被动触发加人。
回到互联网的世界中,当单机饱和了以后,就需要加机器,我经历过的公司都是运维人工操作,决策依据为一些可以体现繁忙度的监控指标,如qps、cpu利用率、内存占用等,对于一些爆炸性事件,这种人工操作就有些捉襟见肘,如大家屡见不鲜的明星头条新闻导致服务宕机的情况,假如能利用机器来自动化的感知压力进而扩容,就能更好的提高服务质量。
偶尔间发现了k8s的HorizontalPodAutoscaler可以实现自动水平扩容,就花时间简单实践了一下,在这里抛砖一波,希望能给大家带来些许帮助。
概念介绍
本节摘自k8s官网
在 Kubernetes 中,HorizontalPodAutoscaler 自动更新工作负载资源 (例如 Deployment 或者 StatefulSet), 目的是自动扩缩工作负载以满足需求。
水平扩缩意味着对增加的负载的响应是部署更多的 Pod。这与 “垂直(Vertical)” 扩缩不同,对于 Kubernetes, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。
如果负载减少,并且 Pod 的数量高于配置的最小值, HorizontalPodAutoscaler 会指示工作负载资源(Deployment、StatefulSet 或其他类似资源)缩减。
水平 Pod 自动扩缩不适用于无法扩缩的对象(例如:DaemonSet。)
HorizontalPodAutoscaler 被实现为 Kubernetes API 资源和控制器。
资源决定了控制器的行为。在 Kubernetes 控制平面内运行的水平 Pod 自动扩缩控制器会定期调整其目标(例如:Deployment)的所需规模,以匹配观察到的指标, 例如,平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标。
HorizontalPodAutoscaler 是如何工作的?
本节摘自k8s官网

Kubernetes 将水平 Pod 自动扩缩实现为一个间歇运行的控制回路(它不是一个连续的过程)。间隔由 kube-controller-manager 的 --horizontal-pod-autoscaler-sync-period 参数设置(默认间隔为 15 秒)。
在每个时间段内,控制器管理器都会根据每个 HorizontalPodAutoscaler 定义中指定的指标查询资源利用率。控制器管理器找到由 scaleTargetRef 定义的目标资源,然后根据目标资源的 .spec.selector 标签选择 Pod, 并从资源指标 API(针对每个 Pod 的资源指标)或自定义指标获取指标 API(适用于所有其他指标)。
-
对于按 Pod 统计的资源指标(如 CPU),控制器从资源指标 API 中获取每一个 HorizontalPodAutoscaler 指定的 Pod 的度量值,如果设置了目标使用率,控制器获取每个 Pod 中的容器资源使用情况, 并计算资源使用率。如果设置了 target 值,将直接使用原始数据(不再计算百分比)。接下来,控制器根据平均的资源使用率或原始值计算出扩缩的比例,进而计算出目标副本数。
需要注意的是,如果 Pod 某些容器不支持资源采集,那么控制器将不会使用该 Pod 的 CPU 使用率。下面的算法细节章节将会介绍详细的算法。
-
如果 Pod 使用自定义指示,控制器机制与资源指标类似,区别在于自定义指标只使用原始值,而不是使用率。
-
如果 Pod 使用对象指标和外部指标(每个指标描述一个对象信息)。这个指标将直接根据目标设定值相比较,并生成一个上面提到的扩缩比例。在 autoscaling/v2 版本 API 中,这个指标也可以根据 Pod 数量平分后再计算。
HorizontalPodAutoscaler 的常见用途是将其配置为从聚合 API (metrics.k8s.io、custom.metrics.k8s.io 或 external.metrics.k8s.io)获取指标。metrics.k8s.io API 通常由名为 Metrics Server 的插件提供,需要单独启动。有关资源指标的更多信息, 请参阅 Metrics Server。
对 Metrics API 的支持解释了这些不同 API 的稳定性保证和支持状态。
HorizontalPodAutoscaler 控制器访问支持扩缩的相应工作负载资源(例如:Deployment 和 StatefulSet)。这些资源每个都有一个名为 scale 的子资源,该接口允许你动态设置副本的数量并检查它们的每个当前状态。有关 Kubernetes API 子资源的一般信息, 请参阅 Kubernetes API 概念。
演练
准备测试镜像
代码逻辑很简单,创建SpringBoot工程stress-test,包含一个Controller,暴露一个接口cpu-test,占着cpu执行一分钟。
package com.example.stresstest.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import java.util.concurrent.TimeUnit;
@Controller
public class GreetingController {
@GetMapping("/cpu-test")
public String greeting() {
Long i = System.currentTimeMillis();
while(true){
if (System.currentTimeMillis() - i > TimeUnit.MINUTES.toMillis(1)){
break;
}
}
return "finish";
}
}将stress-test打包成镜像push到镜像仓库(我这里用的是公司内的,读者可以自行选择)。
部署Stress-test
通过resources.limit.cpu: "1"限制最大能占用的cpu为1核
kubectl create -f stress-test-deployment.ymal
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: stress-test
name: stress-test
namespace: jc-test
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 1
selector:
matchLabels:
app: stress-test
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
annotations:
labels:
app: stress-test
spec:
containers:
image: xxx/stress-test.1.0
imagePullPolicy: IfNotPresent
name: stress-test
resources:
limits:
cpu: "1"
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: docker-registry
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30创建 HorizontalPodAutoscaler
针对stress-test创建了一个HPA,监控的指标为cpu平均利用率,当cpu平均利用率到达80%以后开始自动扩容,最大副本数maxReplicas为3,当cpu平均利用率平缓以后会缩容到minReplicas。
kubectl create -f stress-test-hpa.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-stress-test
namespace: jc-test
spec:
maxReplicas: 3
metrics:
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: stress-test测试
看下测试之前的副本个数,只有一个
kubectl get deployment stress-test -n jc-test
NAME READY UP-TO-DATE AVAILABLE AGE
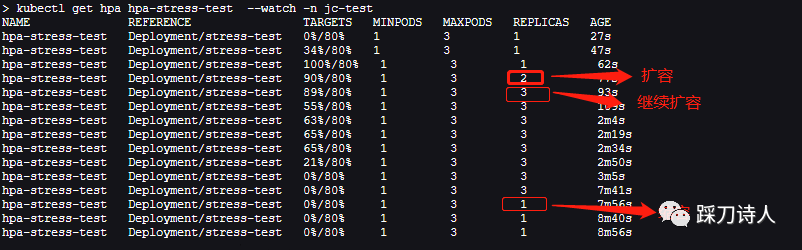
stress-test 1/1 1 1 13dcurl http://127.0.0.1:8080/cpu-test 访问测试接口,该接口会占着cpu执行一分钟,意味着cpu利用率会达到100%,大约15s以后查看副本数的变化,已经变成两个副本,多开几个窗口访问/cpu-test,最终副本数会到达3 。
kubectl get deployment stress-test -n jc-test
NAME READY UP-TO-DATE AVAILABLE AGE
stress-test 2/2 2 2 13d看下HPA的效果
kubectl get hpa hpa-stress-test--watch
一点浅见
看案例确实比较简单,但是具体要如何落地呢,这里谈谈自己的一点看法。
1.容量预估,结合业务预期通过压测等手段知道当前要部署的资源数量,比如笔者之前团队业务预期是一天1000万笔订单,而订单会分摊到早中晚的各一个小时完成,所以预估下qps=1000万/3/3600=926,通过压测单台服务能承受是qps是120,所以部署8台就足够了,但是为了防止一些突**况,会多预留20%左右的资源,最终部署10台;
2.远取指标,以第一步压测得出的qps为例,如果服务的qps到达120,说明目前已处于饱和状态,可以拿平均qps=120来作为是否扩容的标准;
3.设置HPA参数,比如min=5,max=10,qps=120,意味着最小数量是5台,最大数量是10,也许你会问10台如果还不够用呢,这的确是一个好问题,那我再调大点?似乎合情合理,但是有没有想过你的上游能不能承受,你依赖的基础资源能不能承受,微服务一般无状态可以随意扩容,但数据库、redis可就没那么轻松了,所以说max不能只考虑自己,要全局思考,再者说如果接入层做了限流,max已经被圈定在一个可控的范围内,设置太大反而是浪费资源,综合来说max也就是第一步容量预估得出的10,再多了上游不一定能扛得住,如果确实业务增长的比较快,那就得重新做容量预估,投入更多的资源来支持。
单独的说max似乎有点鸡肋,得结合min来说,max是为扩容,min是为缩容,什么场景下才需要缩容呢?为了节省资源,服务器白天可以用来跑在线业务,到了晚上用户都休息了在线业务是不是就空闲了,这时就可以把在线业务少部署几台以备不时之需,其余的资源留给一些离线业务去用,比如T+1的报表、定时任务等,这正是min的使用场景,同样的min也不能设置太小,因为服务的启动也需要一点时间,在启动的这个过程中是不能提供服务的。
HPA的本质就是计算机世界中的pua,眼里有活-通过HPA自动加机器,节省资源-通过HPA自动减机器。
总结
HPA体现了一种降本增效的思想,这种思想和现实世界高度吻合,“公司不养闲人,大家得眼里有活,自动补位。”
本文只作为抛砖,啰嗦一点自己的看法,提到的知识实属皮毛,还请去k8s官网取其精华。
推荐阅读
https://mp.weixin.qq.com/s/F3JndqsH9VxNSn4mAKoMjQ
美团弹性伸缩系统的技术演进与落地实践
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
Pod 水平自动扩缩
https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
HorizontalPodAutoscaler 演练



