
【全网首发】一次疑似 JVM Native 内存泄露的问题分析原创
最近开发同学反馈,某定时任务服务疑似有内存泄露,整个进程的内存占用比 Xmx 内存大不少,而且看起来是缓慢上升的,做了下面这次分析,包括下面的内容:
-
分析 JVM native 内存的一些常见思路 -
内存增长了,怎么甄别是不是内存泄露 -
一个完全不熟悉的项目如何找到可能导致 native 内存分配的代码 -
经典的 Linux 64M 内存问题 -
到底是内存碎片还是内存泄露
现象
这个定时任务的应用设置 Xmx 为 925M,但是 native 内存缓存持续增长,但是增长到一定阶段也会保持稳定,不再继续增长。
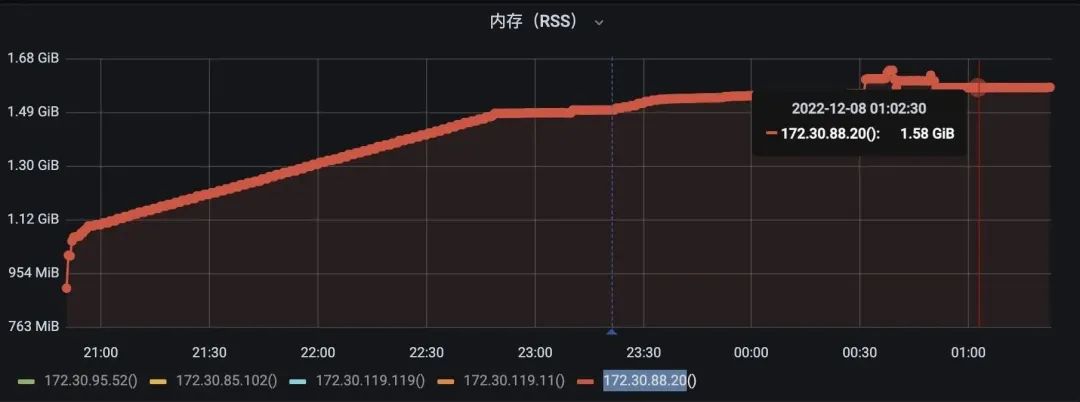
是内存泄露吗?
不管是不是内存泄露,首先要搞清楚的是这段增长的内存是什么,土方法就是用 pmap -x 持续观察内存地址空间的变化。
经过几个小时的 pmap 后台运行,很快发现堆内存几乎无变化,增长的区域都在 64M 内存空间,这就是经典的 glibc 内存分配 64M 问题。
关于 Linux 64M 内存问题,我之前写过几篇相关的文章,大家感兴趣可以去看。
一次大量 JVM Native 内存泄露的排查分析(64M 问题)
一次想不到的 Bootstrap 类加载器带来的 Native 内存泄露分析
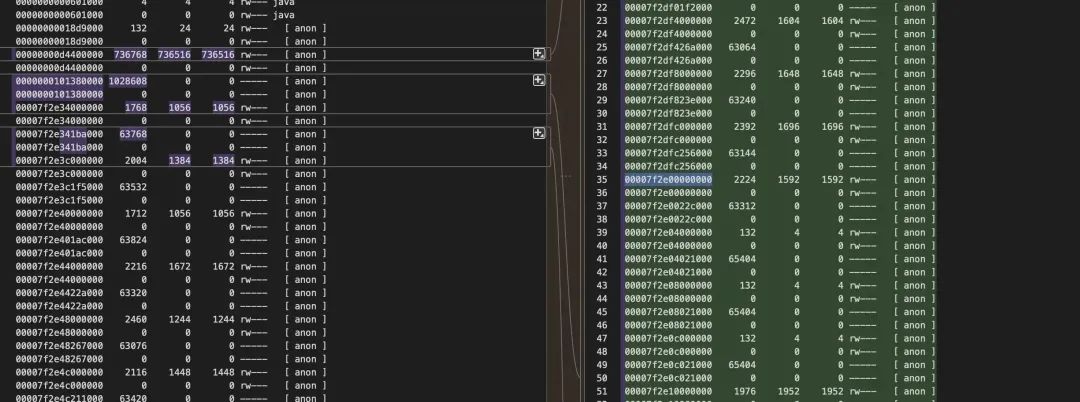
从这里基本可以确定是 native 带来的问题,接下来就是 dump 出来看里面到底存了什么。这里有几个方法
-
使用 gdb -
写一个脚本通过读取 /proc/<pid>/mem -
我自己用 Go 写的一个小工具(可能过段时间释放出来)
脚本的内容如下:
cat /proc/$1/maps | grep -Fv ".so" | grep " 0 " | awk '{print $1}' | grep $2 | ( IFS="-"
while read a b; do
dd if=/proc/$1/mem bs=$( getconf PAGESIZE ) iflag=skip_bytes,count_bytes \
skip=$(( 0x$a )) count=$(( 0x$b - 0x$a )) of="$1_mem_$a.bin"
done )
执行这个脚本,传入进程号和起始地址就可以把对应内存 dump 到文件中。接下来可以通过 strings 初步查看文件里面有没有认识的字符串。通过 strings 发现很多 jar 包文件里的内容,部分内容如下:
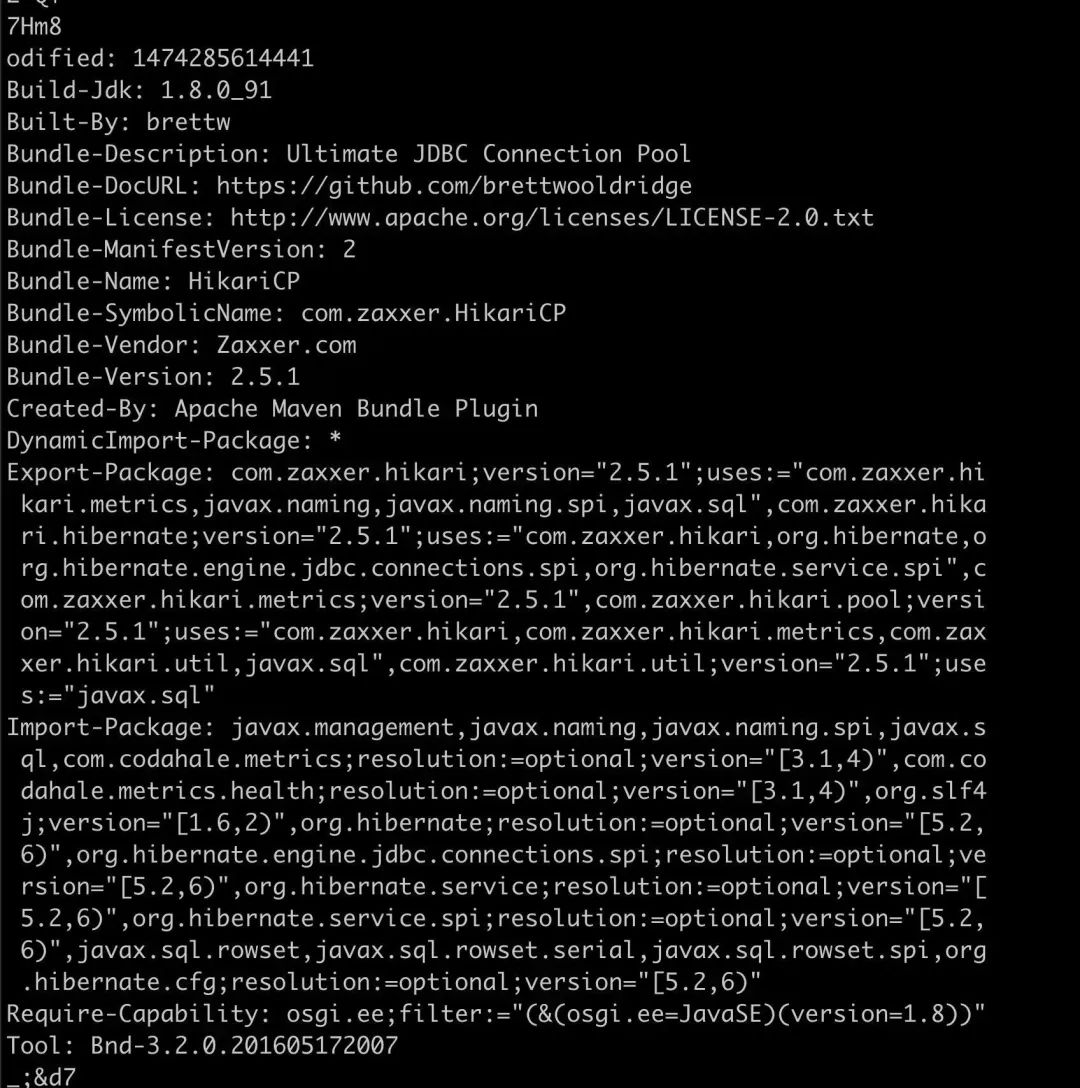
这个内容是项目依赖 jar 包 HikariCP-2.5.1.jar 的 MANIFEST.MF 文件的内容
.
├── MANIFEST.MF
└── maven
└── com.zaxxer
└── HikariCP
├── pom.properties
└── pom.xml
看来就是程序就是读了 HikariCP-2.5.1.jar 的内容,通过 16 进制分析可以进一步确认。众所周知 jar 包就是一个 zip,如果读取了 zip,那理论内存中会有 zip 的魔数,问一下 ChatGPT zip 的魔数是多少。

用 010 Editor 拿着 50 4B 03 04 去内存里搜,可以看到这个 1M 多的内存文件里有 15 个 zip 魔数。
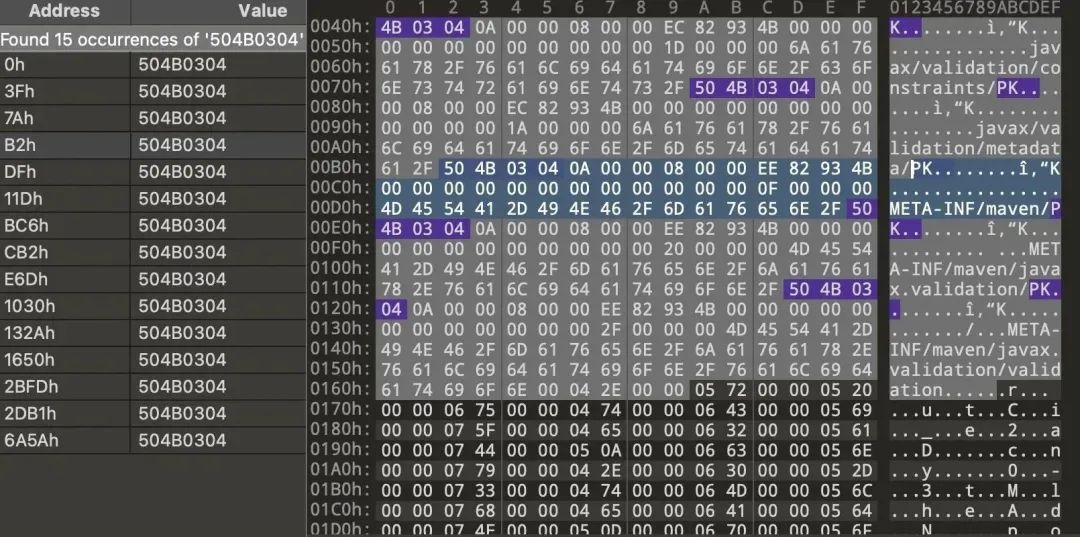
可以进一步把这个文件当做 zip 文件来解析,可以看到 zip 文件对应的 zip entry 有哪些。
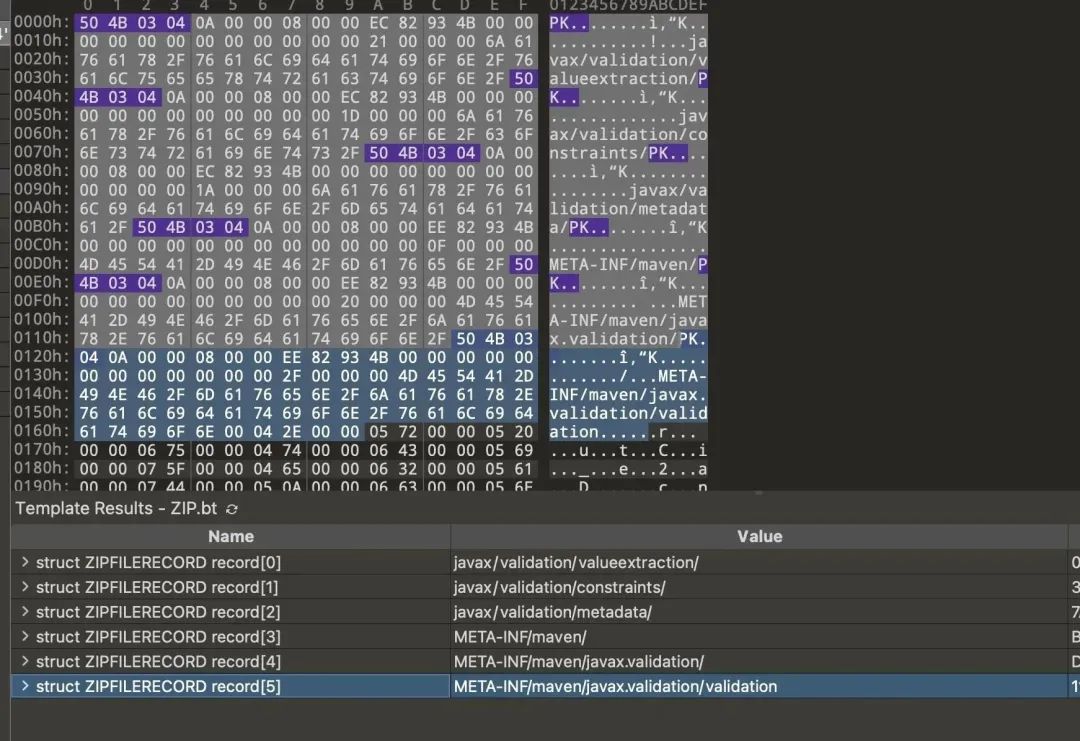
接下来就是去找是谁在读这些 jar 包,读文件会有系统调用,于是这里 strace 就可以看看到底是怎么读的。(也可以通过 jstack 看 java 层的堆栈找到同样的原因,这里不展开)
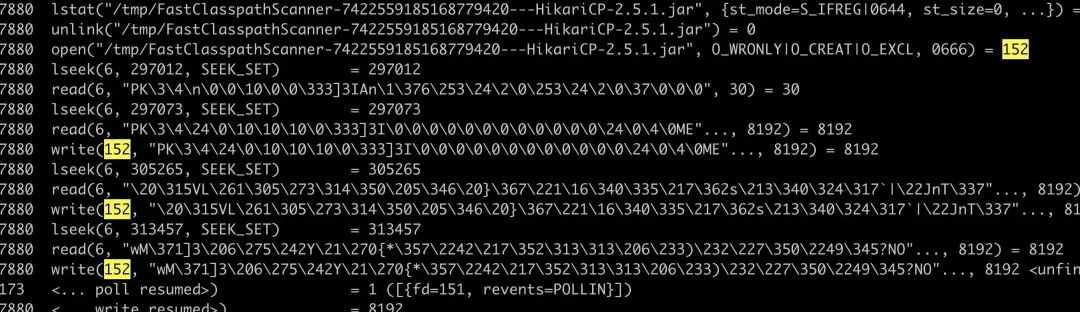
这里出现了一个不认识的临时文件,还有一个前缀 FastClasspathScanner,去代码里搜,原理是项目用了 FastClasspathScanner 来扫描 class 文件
FastClasspathScanner 项目地址在 https://github.com/classgraph/classgraph ,FastClasspathScanner 提供了一种简单快速的方法来扫描 Java 类路径。它可以轻松找到类路径上的所有类、资源、包和模块,并获取有关它们的信息。这个项目用它来做什么呢?
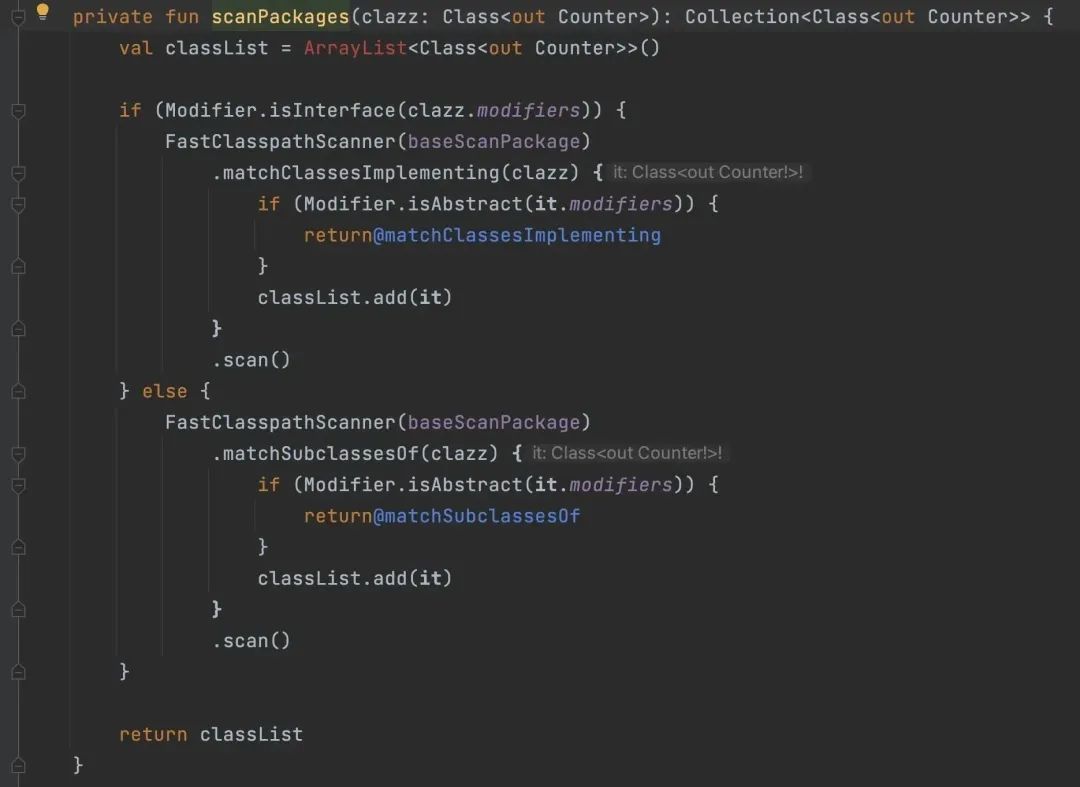
经过看代码,它大概是用来去 jar 包里搜哪些类实现了 com.seewo.school.statistics.counter.Counter 接口,然后去 classpath 中的找到实现了这个接口的类,也就是遍历所有的 jar 包去找实现类。
FastClasspathScanner 的做法是先把这些依赖的 jar 包先拷贝到临时目录(注意这里的 tempFile.deleteOnExit(),虽然跟此次问题不相关,但也是一个内存隐患,等下介绍)
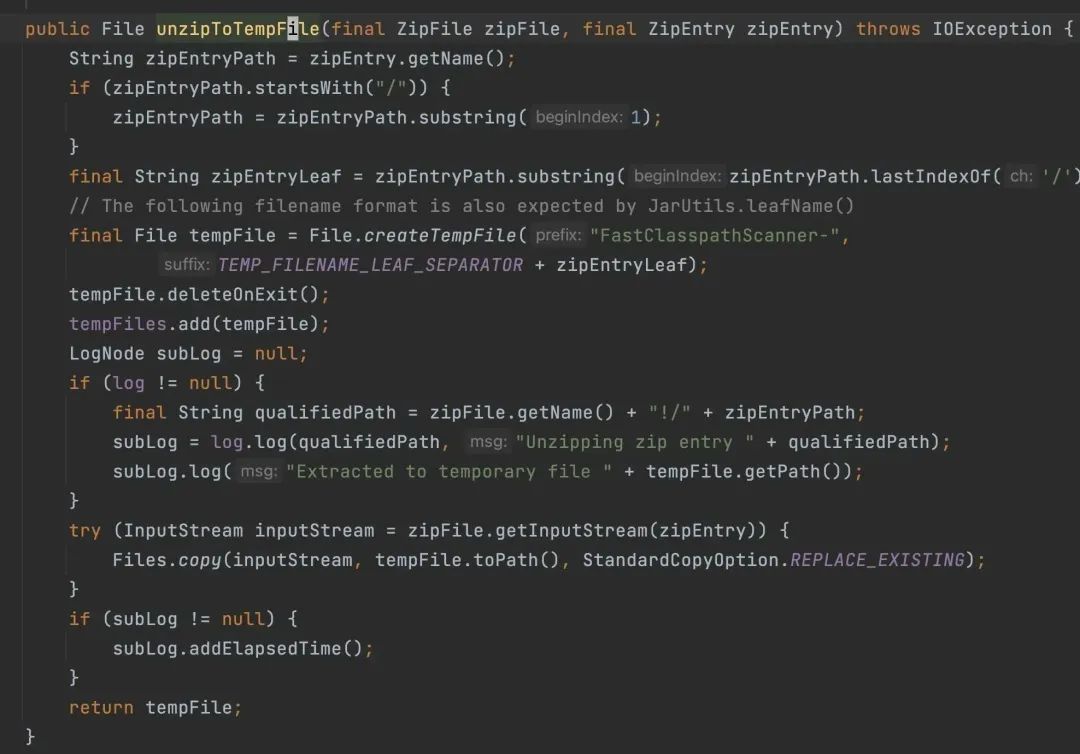
然后读取这些临时 jar 包,
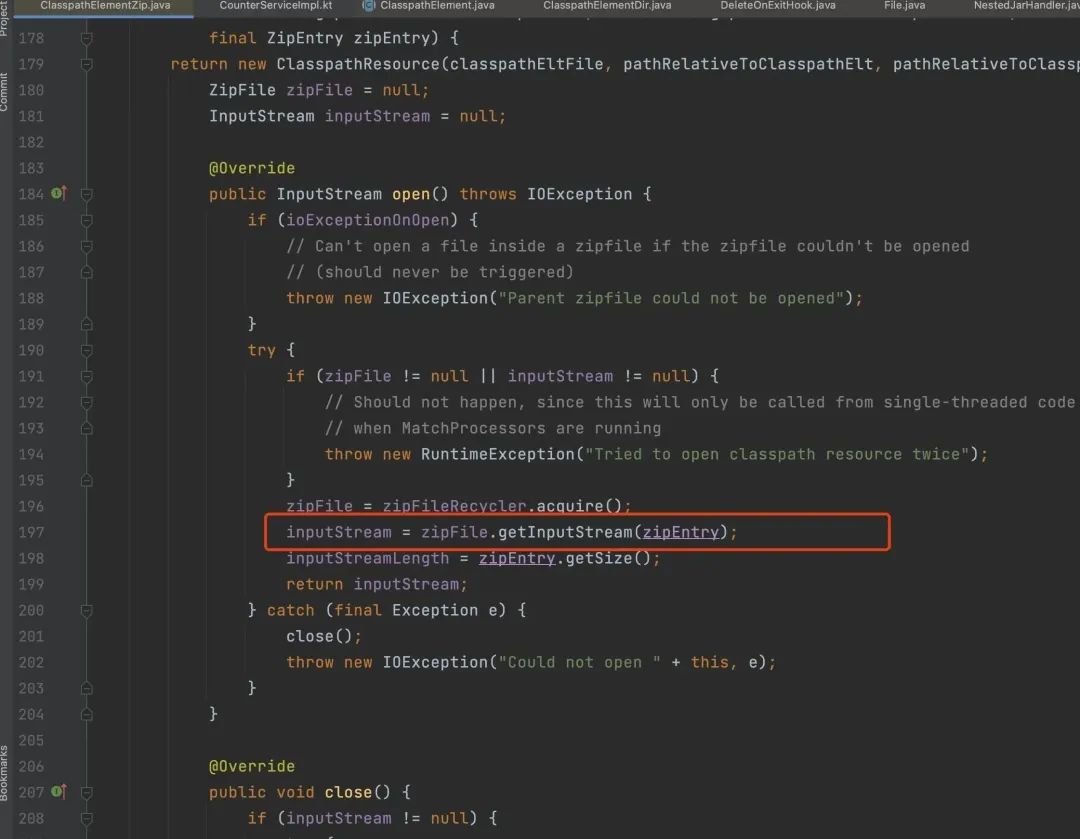
大量申请释放内存的地方在 java.util.zip.Inflater 类,调用它的 end 方法会释放 native 的内存。如果 end 方法没有调用,就会导致内存泄露,java.util.zip.InflaterInputStream 类的 close 方法在一些场景下是不会调用 Inflater.end 方法,如下所示。
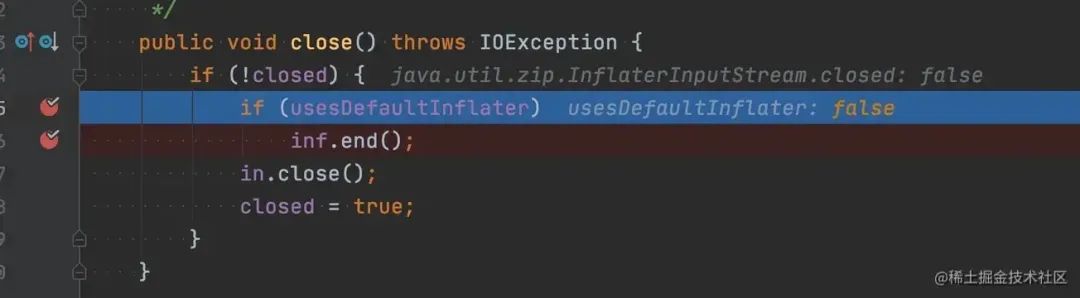
但是 Inflater 类有实现 finalize 方法,在 Inflater 对象不可达以后,JVM 会帮忙调用 Inflater 类的 finalize 方法
public class Inflater {
public void end() {
synchronized (zsRef) {
long addr = zsRef.address();
zsRef.clear();
if (addr != 0) {
end(addr);
buf = null;
}
}
}
protected void finalize() {
end();
}
private native static void initIDs();
// ...
private native static void end(long addr);
}
有几种可能性
-
Inflater 因为被其它对象引用,没能释放,导致 finalize 方法不能被调用,内存自然没法释放 -
Inflater 因为还没被 FinalizerThread 执行 fianlize 方法,导致没有释放 -
Inflater 的 finalize 方法被调用,但是被 libc 的 ptmalloc 缓存,没能真正释放回操作系统
更多关于 finalize 机制,大家可以移步笨神的文章:「JVM源码分析之警惕存在内存泄漏风险的FinalReference(增强版) 」 https://heapdump.cn/article/265970
于是 dump 堆内存去分析是不是有大量的 Inflater 类没有被回收,经过内存分析看,发现 java.util.zip.Inflater 类有 6k 多没有被回收。
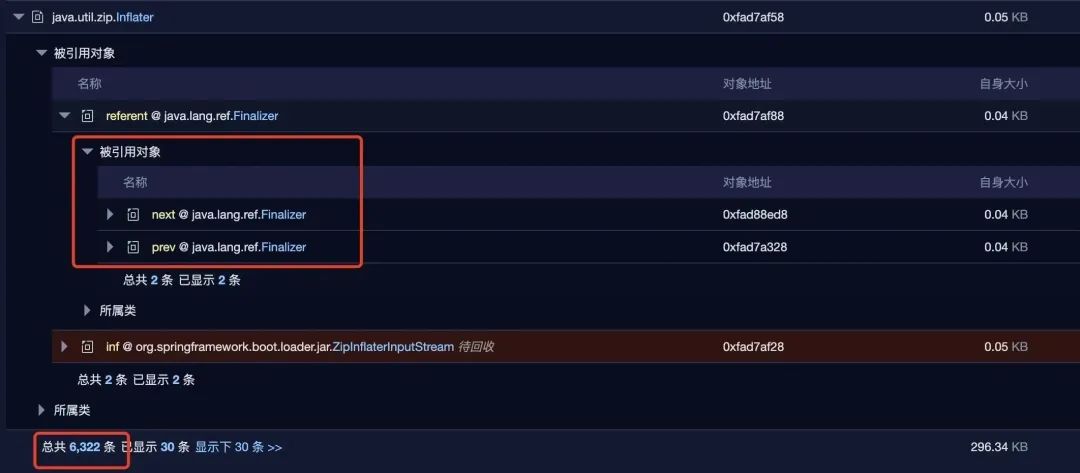
没有被回收的原因是它们被 Finalizer 引用,需要两次 GC 才有可能被回收。
而且 FinalizerThread 的优先级比较低,如果 CPU 比较紧张的情况下,会导致需要很久才会把队列中 f 对象的 finalize 方法执行完。又因为这个时间比较长,可能导致 f 对象多次 GC 以后进到老年代,如果老年代 gc 频率不高,那 f 对象存活的时间就更久了。
这样的 native 内存短时间不释放,又由于定时任务长期执行,就可能会导致内存碎片、glibc 内存不归还的出现(等下验证),就算释放 libc 也有可能不会还给操作系统。
通过手动多次触发 GC,确认可以将所有的 java.util.zip.Inflater 回收掉,但是 natvie 内存并没有太大的变化。于是怀疑是 glibc 的内存碎片和内存没有归还给操作系统。
如何修改
有几个可能的修改方式
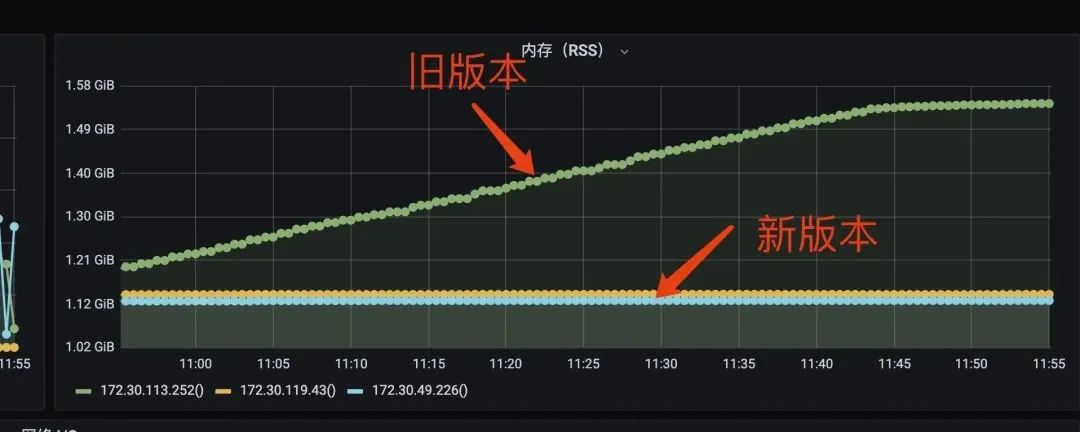
方案 1:其实这里明显是程序上设计不合理,没必要每次定时任务都去扫描包,这些包又不会变,扫描一次就可以了,与让开发的同学去修改代码,把第一次扫描的结果缓存起来。然后打了一个包去开发环境运行,效果非常明显,新版本跑了一整天都内存几乎没有什么波动,旧版本则缓慢的上涨了 400M 左右。
方案 2:修改 FastClasspathScanner 代码,在流关闭的时候,顺带关闭 Inflater, SpringBoot 里面是这么实现的。(不想改了)
SpringBoot 里面的改动如下:https://github.com/spring-projects/spring-boot/issues/13935

方案 3:前面怀疑是因为 glibc 的内存碎片,尝试替换碎片整理更友好的 tcmalloc 或者 jemalloc,看看效果。
LD_PRELOAD=/usr/local/lib/libtcmalloc.so java -jar xxx
下面是换了 tcmalloc 以后的效果,tcmalloc 贼稳。
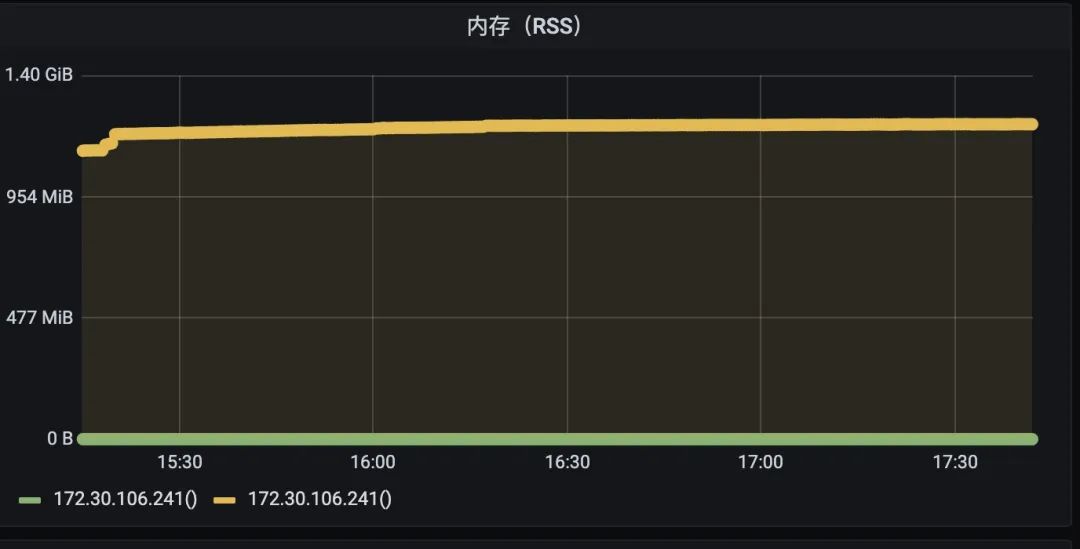
可以看到换到了对内存碎片更友好的内存分配器以后,内存的增长得到了非常好的控制。
番外篇
上面提到 tempFile.deleteOnExit() 会有巨大的坑,通过内存 dump 的分析,可以看到 java.io.DeleteOnExitHook 占了将近 40M。
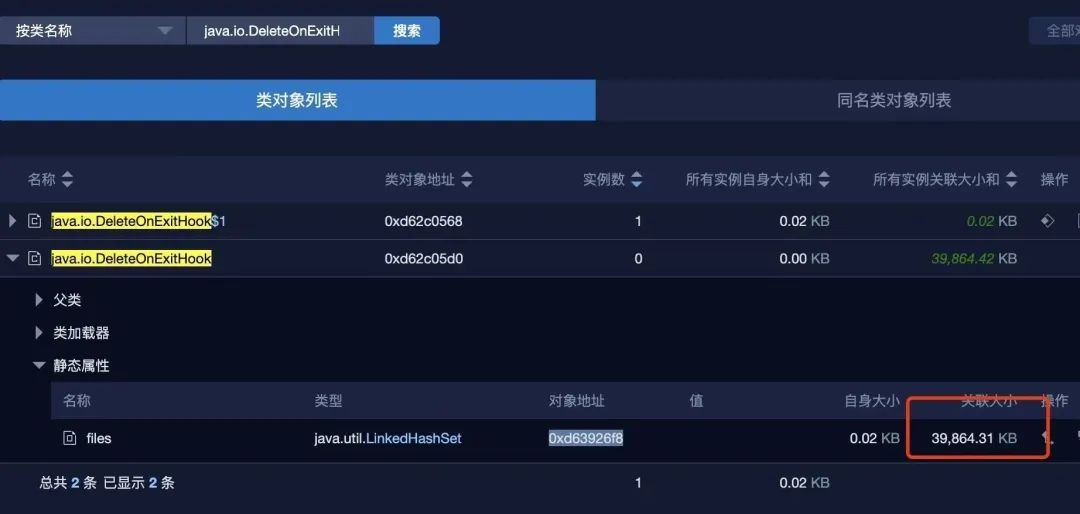
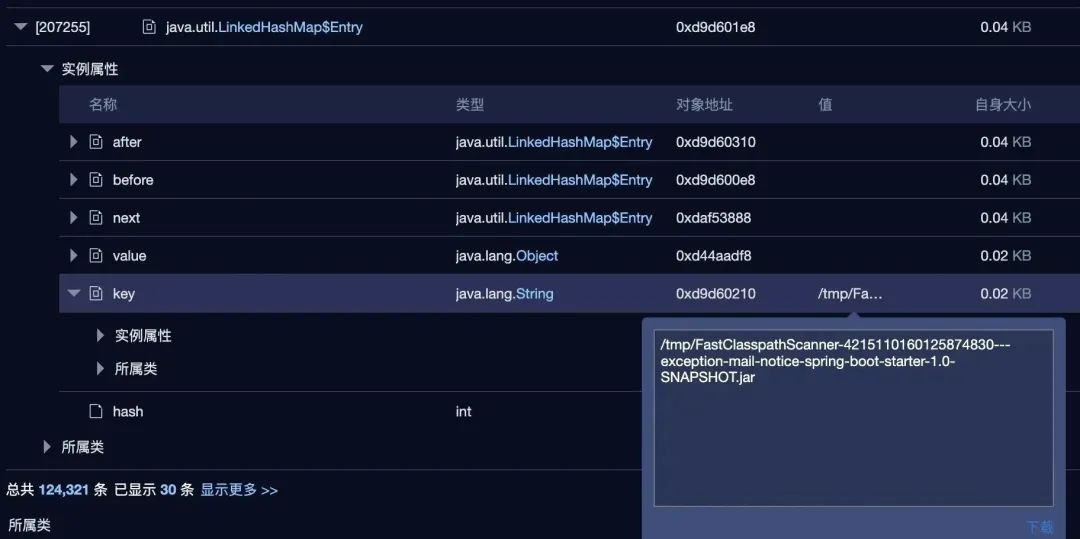
里面有一个静态的 hashset,里面存了 10 几万个字符串,就是 FastClasspathScanner 产生的临时文件路径。
是因为这里调用了 File.deleteOnExit,这个可太坑了。
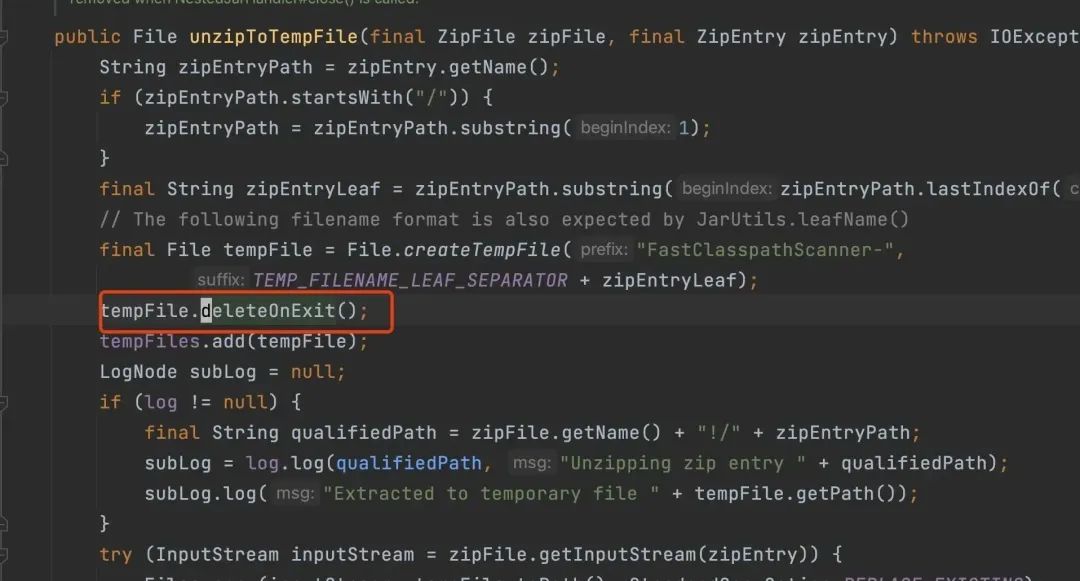
它把文件的路径加到了一个 jvm 全局 DeleteOnExitHook 类的静态变量 files 中。
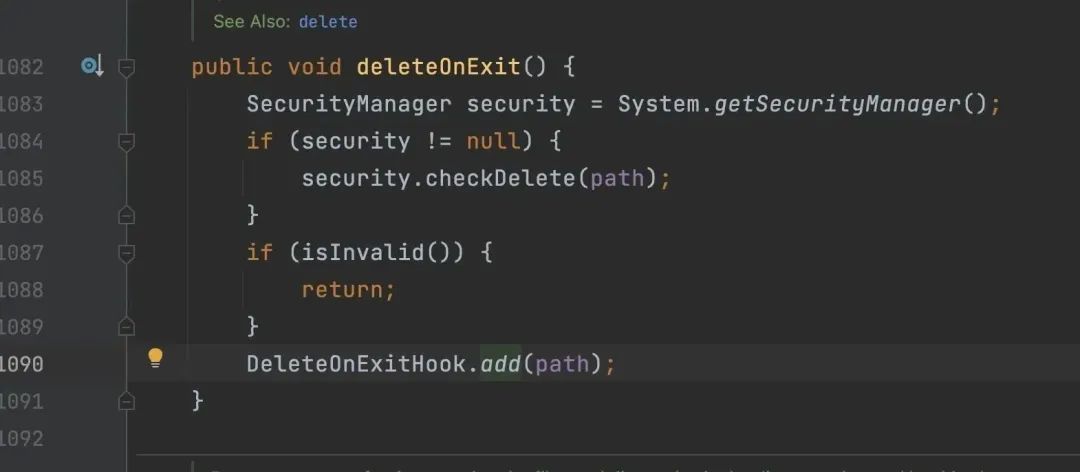
又因为临时文件每次的路径都是不一样的,导致这个 hashset 随着定时任务的执行逐渐变大,永远无法回收。
DeleteOnExitHook 本意是用来在 Java 虚拟机退出的时候删除文件。
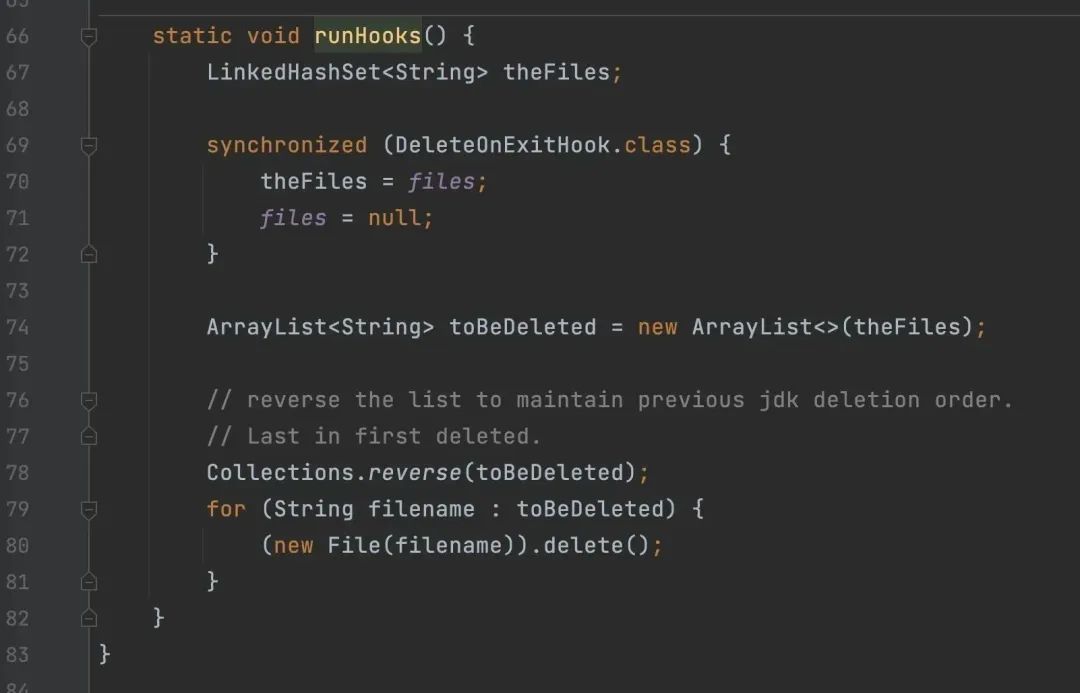
对于 server 端这种长时间运行的程序,用 deleteOnExit 就太坑了,只有等容器退出那会才会执行删除。再加上这里的文件路径每次都变,导致内存白白浪费。
小结
因为程序设计的问题导致频繁读取 jar 包(实际是 zip 文件),需要调用 native 的代码去处理 zip 文件,会有非常多 native 内存分配的产生。又因为用了 zip 默认的 InflaterInputStream,导致没有办法在流关闭时调用 java.util.zip.Inflater 类的 end 方法释放 native 内存,只能等到 Finalizer 机制在多次 GC 以后调用,导致了 native 内存可能在短时间内无法释放。
又因为内存碎片和 libc 内存分配器的实现策略,导致了它没有将内存真正释放给操作系统,导致了缓慢的内存增长。
简单来说,有一个猪队友在不停的申请内存(无法立刻释放),又由于 libc 碎片化和内存二道贩子不一定会把 native 内存还给 os,导致了内存的缓慢增长。
一点想法:
-
Java 的 zip 机制是真的设计有点坑, -
Finalize 机制完全帮倒忙,弊远大于利,新版本 Java 确实也做了修改。



