
【全网首发】一次 Netty 不健壮导致的无限重连分析原创
这是上一篇文章的姊妹篇,也是由于 OOM 导致不健壮的 Netty 一系列诡异的行为,这次的问题分析会比上次那个更有意思一点。(备注:本文 Netty 版本是上古时代的 3.7.0.Final)
上篇文章见:一次 Netty 代码不健壮导致的大量 CLOSE_WAIT 连接原因分析
现象描述
开发的同学反馈 dubbo 客户端无法调用远程的服务,抓包来看,客户端一直在建连,每次建连成功 3 秒以后就主动断开连接。

这个现象就很奇怪了,默认情况下dubbo消费端对属于同一个provider的不同service只会共享一条tcp连接进行通信,此处就是为了跟 provider 端建立这个连接。
为什么这里三次握手成功以后会断开连接呢?这个现象其实挺诡异的,于是想到用 strace 看一下背后到底发生了什么。
strace -f -T -p 238289 -o strace-new.238289.out
在 strace 中找 connect 相关的调用,根据线程号过滤对应的日志,可以看到发生了哪些系统调用:
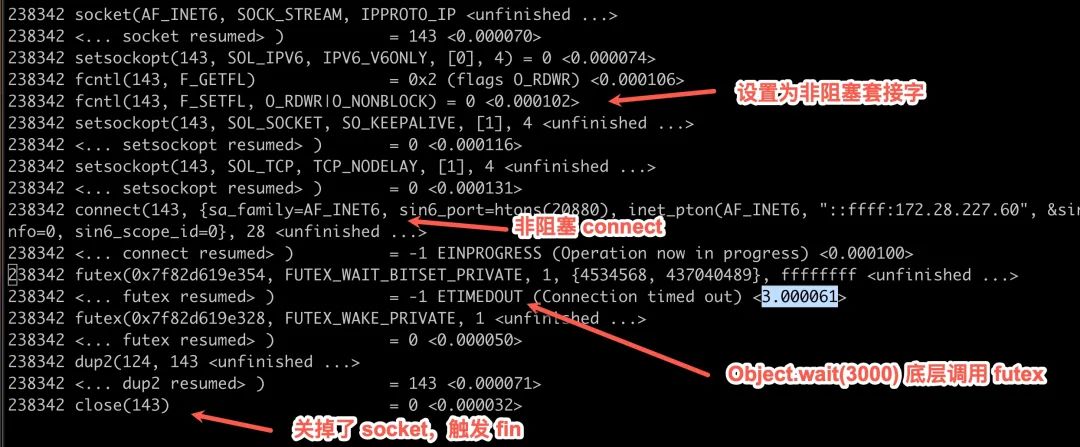
一开始就创建一个 socket,将该套接字设置为非阻塞,随后调用 connect 发起建立,因为是非阻塞套接字,connect 这里不阻塞直接返回 -1,随后开始等待 3s,如果 3s 内没有能建立成功,futex 超时退出。
但是这个跟抓包的行为就不一致了,从包上看,duboo 服务端有回复 SYN+ACK,但是 java 应用认为我没有收到,3s 超时。
同时,这里整个 strace 日志中没有看到对应 fd 相关 epoll_ctl 调用,也就是没有人把这个 fd 加入到 epoll 的事件监听中。
正常来说,我们的一个非阻塞的 connect 编程是这样的。(以下代码来自 ChatGPT,错了别赖我)
// 设置 socket 为非阻塞模式
int set_nonblocking(int fd) {
// 省略
}
// 连接服务器
int connect_to_server(const char *hostname, int port) {
int sockfd;
struct sockaddr_in serv_addr;
struct hostent *server;
// 创建 socket
sockfd = socket(AF_INET, SOCK_STREAM, 0);
// 设置 socket 为非阻塞模式
set_nonblocking(sockfd)
// 尝试连接服务器
if (connect(sockfd, (struct sockaddr *) &serv_addr, sizeof(serv_addr)) < 0) {
if (errno != EINPROGRESS) { // 非阻塞下会返回这个错误码
return -1;
}
}
return sockfd;
}
// 使用 epoll 监听 socket 连接的状态
int wait_for_connection(int sockfd) {
int epfd, nfds;
struct epoll_event ev, events[1];
// 创建 epoll 实例
epfd = epoll_create(1);
// 将 socket 添加到 epoll 的事件监听集合中
memset(&ev, 0, sizeof(ev));
ev.events = EPOLLOUT | EPOLLET;
ev.data.fd = sockfd;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, &ev) < 0) {
return -1;
}
// 监听事件
for (;;) {
nfds = epoll_wait(epfd, events, 1, -1);
if (nfds == -1) {
return -1;
}
// 检查连接是否成功
if (events[0].events & EPOLLOUT) {
return sockfd;
}
}
return -1;
}
int main(int argc, char *argv[]) {
const char *hostname = "localhost";
int port = 8080;
// 创建并连接到服务器
int sockfd = connect_to_server(hostname, port);
if (sockfd < 0) {
return 1;
}
// 使用 epoll 监听 socket 连接的状态
sockfd = wait_for_connection(sockfd);
if (sockfd < 0) {
return 1;
}
// 连接成功,在这里执行你想要的操作
printf("Connection established!\n");
// 关闭 socket
close(sockfd);
return 0;
}
目前的思路大概就清楚了:没有人调用epoll相关的函数去注册事件,导致内核收到SYN+ACK包以后,没有程序感兴趣去处理。
为什么没有向 epoll 注册事件
上面是建连是 Dubbo 的重连线程来实现的,重连线程的主要作用是检测和管理网络连接的状态,如果发现连接断开或异常,就会尝试重新建立连接。先来看一下重连线程做了什么,重连线程的创建位于 com.alibaba.dubbo.remoting.transport.AbstractClient类中。
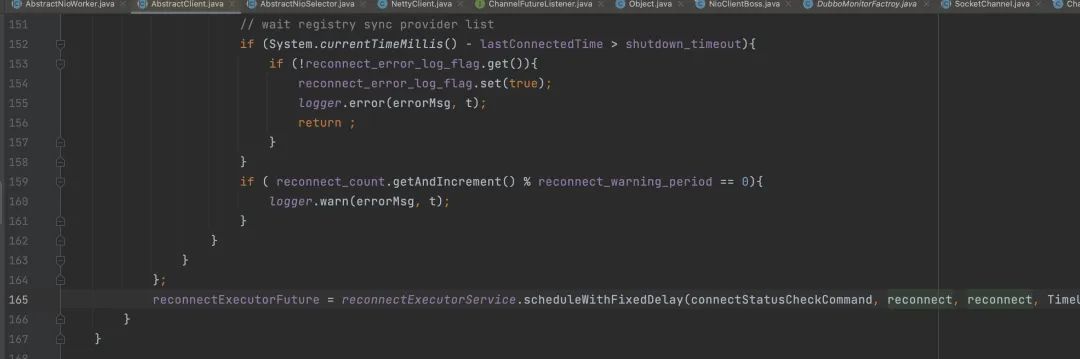
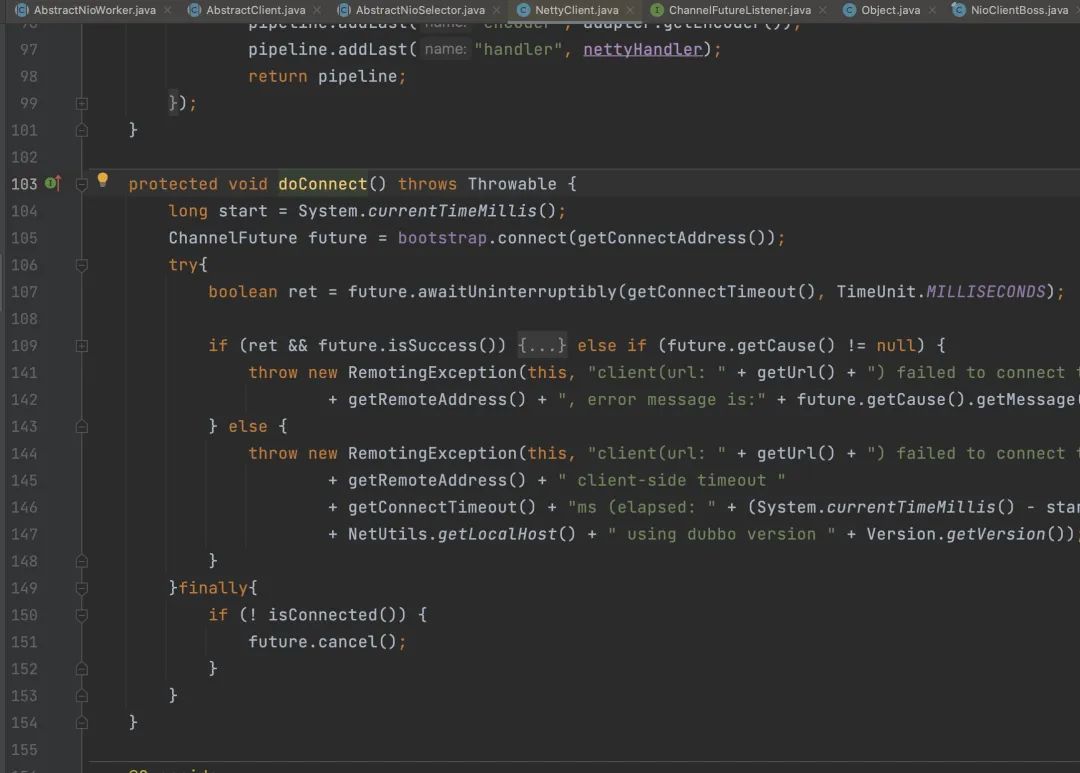
Dubbo 内部用 ScheduledThreadPoolExecutor 线程池运行 reconnect 线程。这个重连线程会调用 com.alibaba.dubbo.remoting.transport.netty.NettyClient.doConnect 发起建连。
ClientBootstrap.connect 不会直接为 channel 注册事件,而是生成了一个 RegisterTask 放入了 NioClientBoss 的 taskQueue 中,等待被处理。
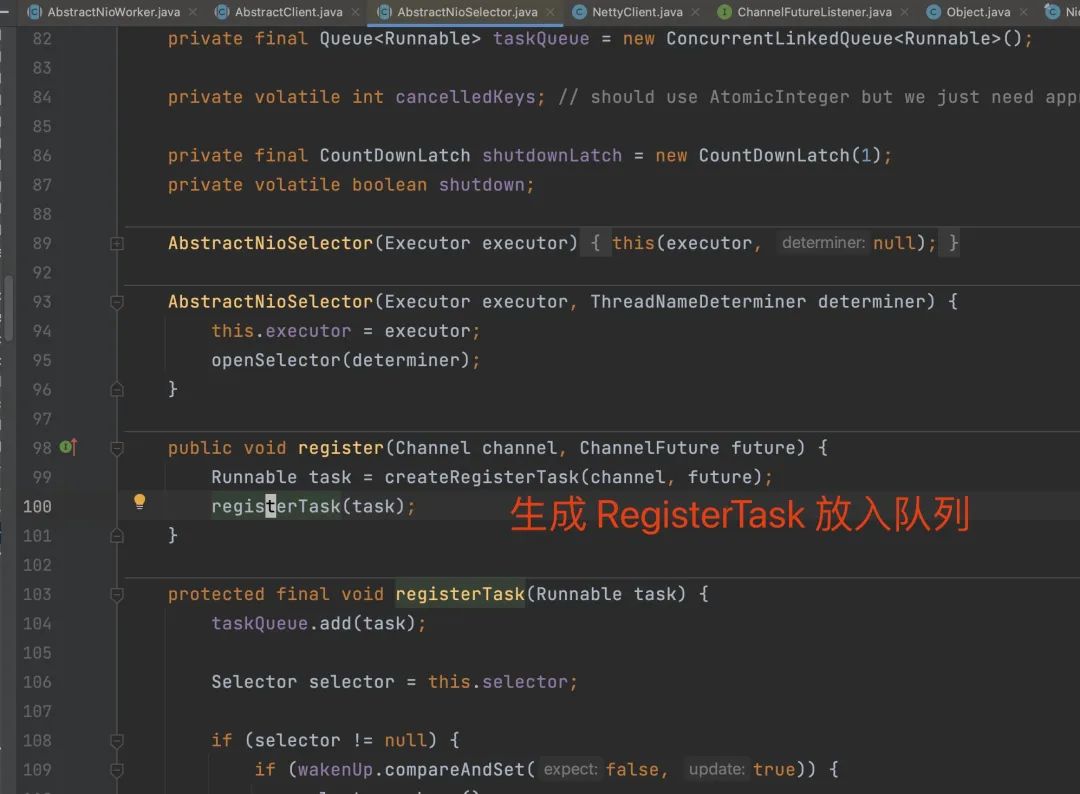
通过注入 stack java.util.concurrent.ConcurrentLinkedQueue offer -n 1 就可以发现,确实如此。
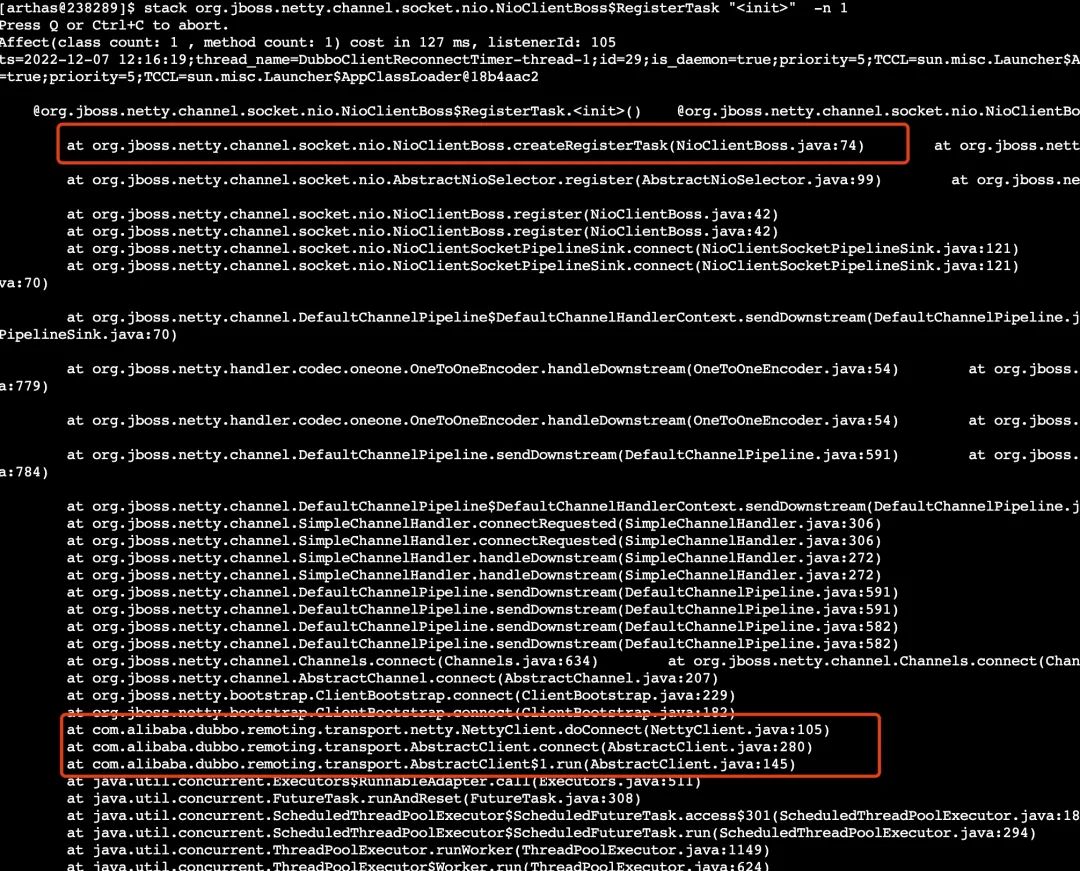
如果 RegisterTask 的 run 方法被执行时,才是真正的注册事件。
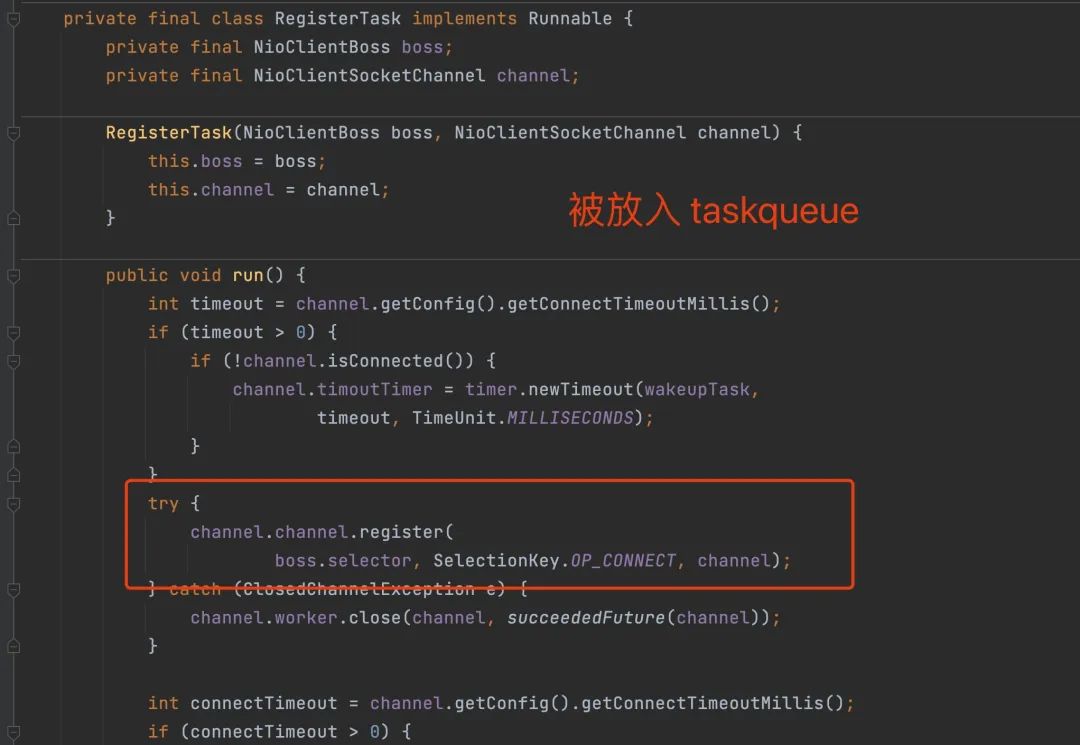
现在可以推断出 RegisterTask 的 run 没有被调用。
继续看taskqueue是如何消费的,就知道 run 为什么没有被执行了。这个队列是在 org.jboss.netty.channel.socket.nio.AbstractNioSelector#processTaskQueue 中消费的
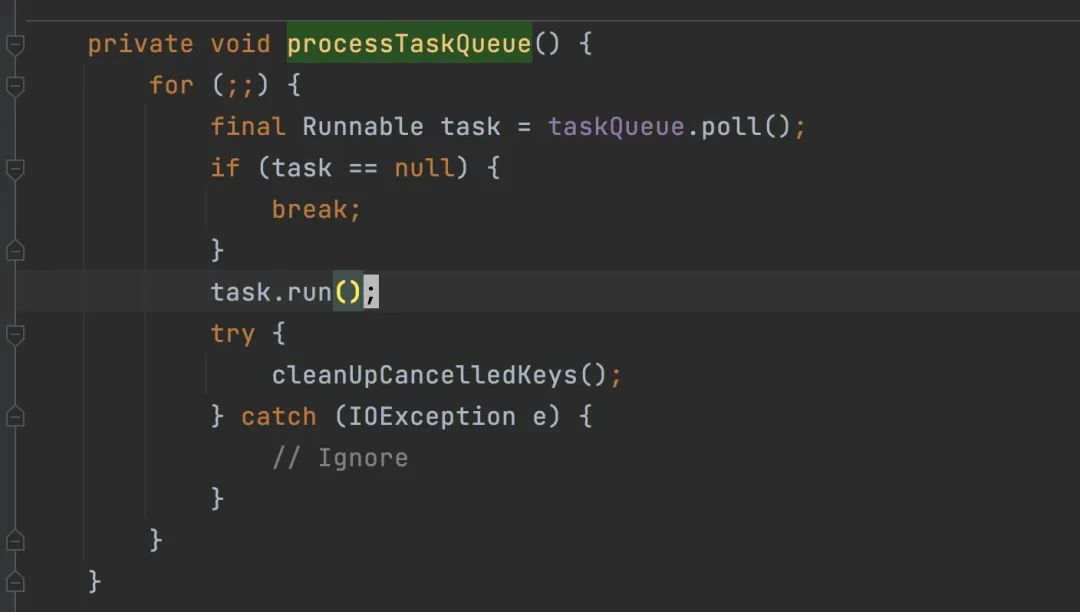
这个方法是被 org.jboss.netty.channel.socket.nio.AbstractNioSelector#run 调用的,实际是实现类 org.jboss.netty.channel.socket.nio.NioClientBoss,这个类也是一个 runnable,启动后生成一个名为 New I/O boss #N 的线程,内部是一个无限循环消费 taskqueue 以及处理就绪事件。
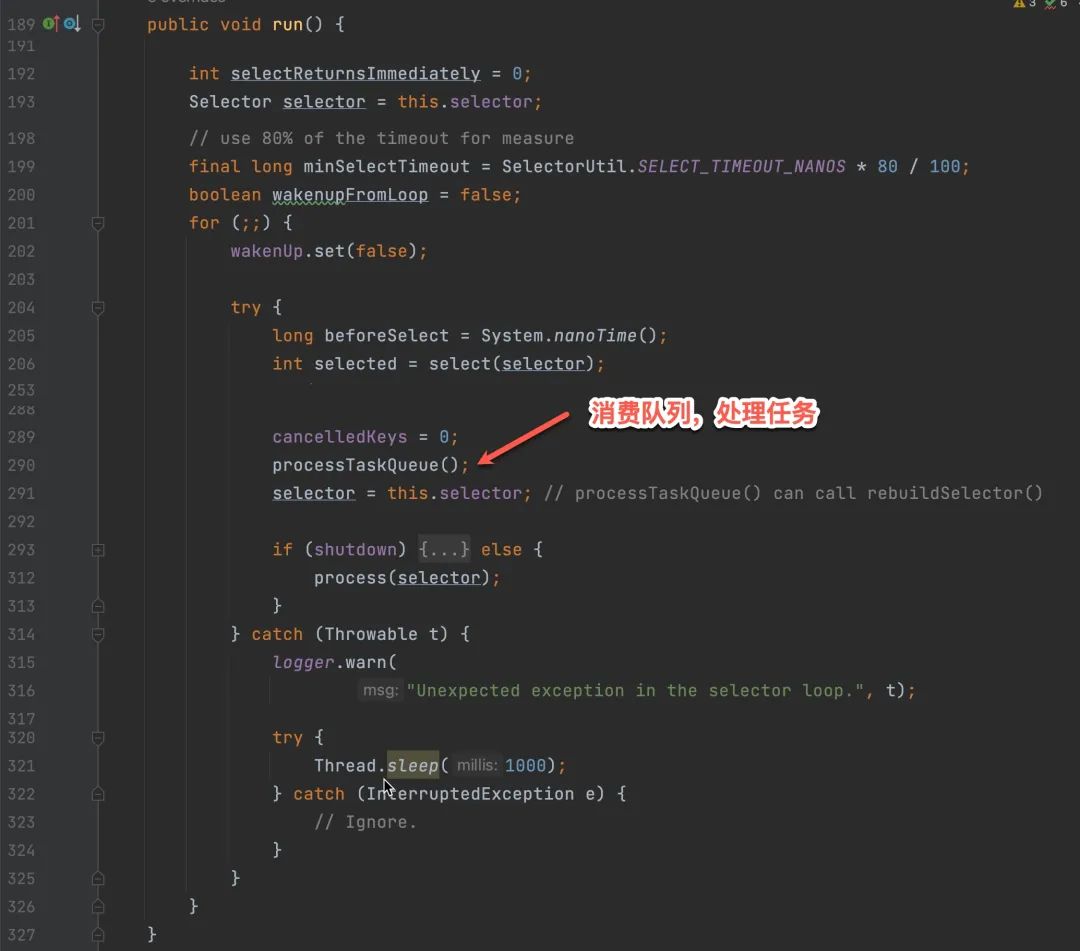
下一步就是进一步确认 taskqueue 是不是确实没有消费,这个可以通过 dump 内存的方式来验证,看看 taskqueue 里面的数据有没有变化。

这下实锤了,接下来去 dump 线程堆栈,看看 New I/O boss 线程还在不在。
通过 jstack 对比确认,无限重连的服务确实没有 New I/O boss 线程。
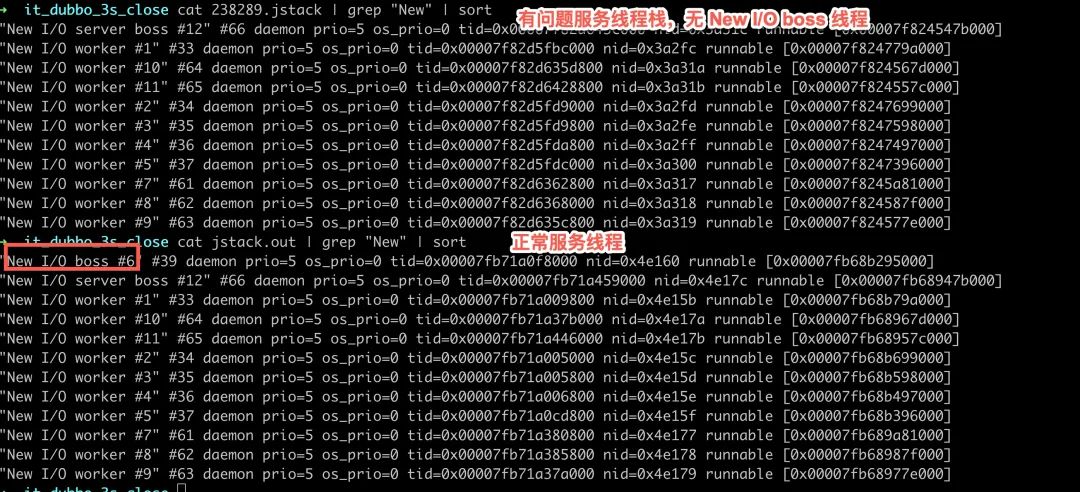
结合服务在半夜定时任务时堆内存 OOM 的日志,可以合理怀疑因为 OOM 导致 New I/O boss 线程退出,没有能继续执行 run 方法消费队列,导致非阻塞建连 connect 以后没有用 epoll_ctl 注册感兴趣事件。
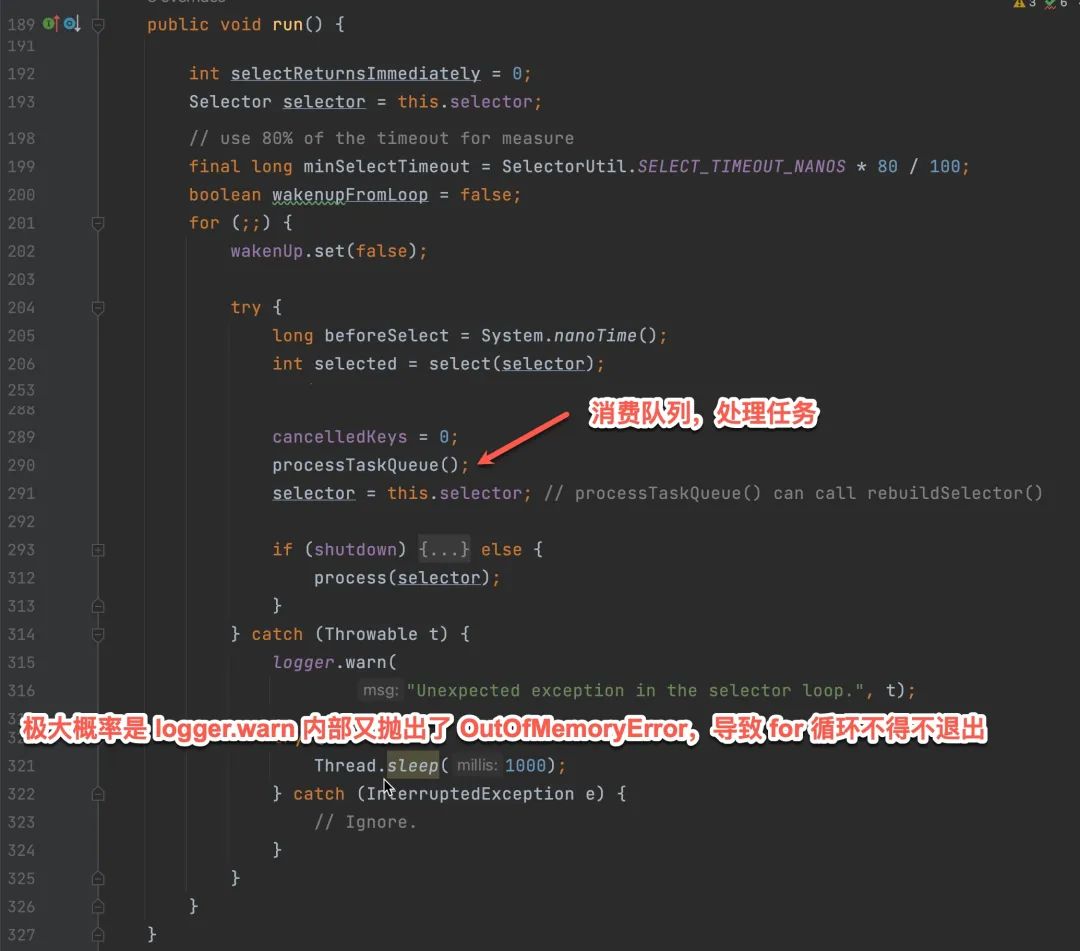
通过分析,run 方法是有捕获 Throwable 异常的,如果有 OutOfMemoryError 会进入 catch 中,理论上线程不会挂掉。但是好死不死 catch 块还有逻辑,有 logger 去打印 warn 日志,这里如果再次抛出 OutOfMemoryError,那就凉凉。
如何修改
-
优化代码,杜绝 OOM -
完善 Netty 对 OOM 的处理逻辑,核心线程退出以后重建 -
升版本。。
后记
只要能复现的基本上都可以被解决,稳定复现的那就更容易了。这个问题出现的概率比上次那个大量 CLOSE_WAIT 情况更低,但是好在开发的同学没改 bug,昨天又出现了。
Dubbo 版本真难升啊,不好用。。。



