
【全网首发】一次 Netty 代码不健壮导致的大量 CLOSE_WAIT 连接原因分析原创
背景
我们线上有一个 dubbo 的服务,出现大量的 CLOSE_WAIT 状态的连接,这些 CLOSE_WAIT 的连接出现以后不会消失,这就有点意思了,于是做了一下分析记录如下。
首先从 TCP 的角度看一下 CLOSE_WAIT
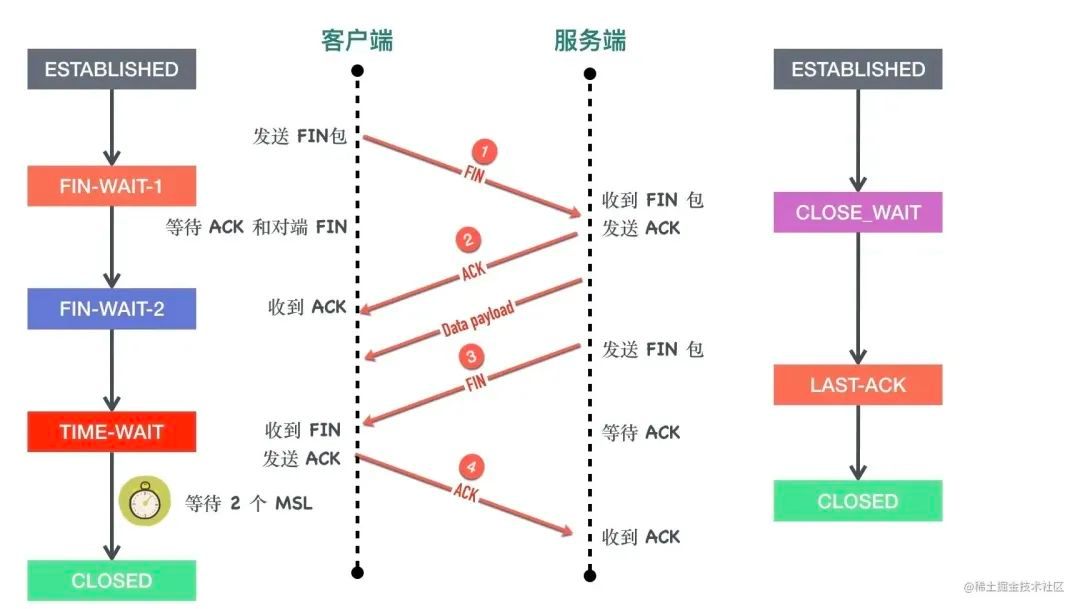
CLOSE_WAIT 状态出现在被动关闭方,当收到对端 FIN 以后回复 ACK,但是自身没有发送 FIN 包之前。
所以这里的原因就很清楚了,出现永远存在的 CLOSE_WAIT 的连接是因为,收到了对端的 FIN 包,但是自己一直没有回复 FIN。通过抓包确实验证了这个的想法。

问题就落在了为什么没有回复 ACK,这是一个健康检查探测的请求,三次握手成功以后,探测服务会马上发送 FIN,理论上 dubbo 服务也会立刻回复 FIN,但是没有任何反应。
对于 dubbo 底层使用的 netty 来说,它就是一个普通的 tcp 服务端,无非就这几步:
-
bind、listen -
注册 accept 事件到 epoll -
epoll_wait 等待连接到来 -
连接到来时,调用 accept 接收连接 -
注册新连接的 EPOLLIN、EPOLLERR、EPOLLHUP 等事件到 epoll -
epoll_wait 等待事件发生
如果是没有发送 fin,有几个比较明显的可能原因。
-
第 2 步没有做,压根没有注册 accept 事件(可以排除,肯定有注册) -
第 4 步没有做,连接到来时,netty 「忘了」调用 accept 把连接从内核的全连接队列里取走。这里的「忘」可能是因为逻辑 bug 或者 netty 忙于其他事情没有时间取走,这个待会验证 -
第 5 步没有做,取走了连接,三次握手真正完成,但是没有注册新连接的后续事件
第 2 个原因可以通过半连接队列、全连接队列的积压来确认。ss 命令可以查看全连接队列的大小和当前等待 accept 的连接个数。
ss -lnt | grep :9090
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 51 50 *:9090 *:*
-
处于 LISTEN 状态的 socket,Recv-Q 表示当前 socket 的完成三次握手等待用户进程 accept 的连接个数,Send-Q 表示当前 socket 全连接队列能最大容纳的连接数 -
对于非 LISTEN 状态的 socket,Recv-Q 表示 receive queue 的字节大小,Send-Q 表示 send queue 的字节大小
通过 ss 命令确认过 Recv-Q 为 0,全连接队列没有积压。

至此最大的嫌疑在第 3 个原因,netty 确实调用了 accept 取走了连接,但是没有注册此连接的任何事件,导致后面收到了 fin 包以后无动于衷。
为什么 netty 没有能注册事件?
到这里暂时陷入了僵局,但是有一个跟此次问题强相关的现象浮出了水面,就是业务实例在凌晨 1 点有个定时任务,一开始就 load 了大量的数据到内存中,导致堆内存占满,持续进行 fullgc
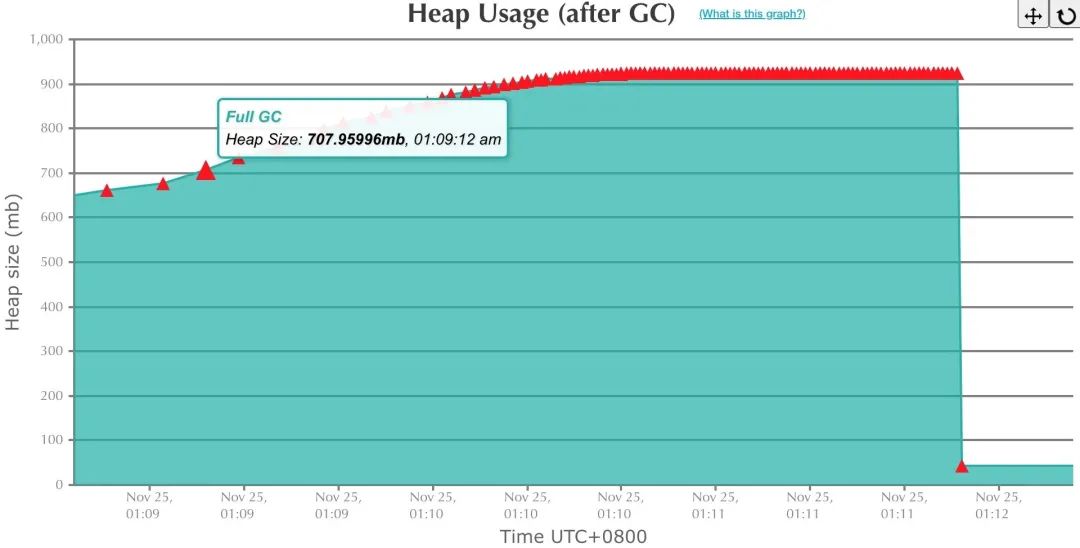
netty 线程也有打印 oom 异常。

这里的 OOM 异常上面的一个 warning 引起了同事斌哥的主意,去 netty 源码中一搜索,发现出现在 org.jboss.netty.channel.socket.nio.NioServerBoss#process 方法中(netty 版本很古老 3.7.0.final)
1 @Override
2 protected void process(Selector selector) {
3 Set<SelectionKey> selectedKeys = selector.selectedKeys();
4 if (selectedKeys.isEmpty()) {
5 return;
6 }
7 for (Iterator<SelectionKey> i = selectedKeys.iterator(); i.hasNext();) {
8 SelectionKey k = i.next();
9 i.remove();
10 NioServerSocketChannel channel = (NioServerSocketChannel) k.attachment();
11
12 try {
13 // accept connections in a for loop until no new connection is ready
14 for (;;) {
15 SocketChannel acceptedSocket = channel.socket.accept(); // 调用 accept 从全连接队列取走连接
16 if (acceptedSocket == null) {
17 break;
18 }
19 registerAcceptedChannel(channel, acceptedSocket, thread); // 为新连接注册事件
20 }
21 } catch (CancelledKeyException e) {
22 // Raised by accept() when the server socket was closed.
23 k.cancel();
24 channel.close();
25 } catch (SocketTimeoutException e) {
26 // Thrown every second to get ClosedChannelException
27 // raised.
28 } catch (ClosedChannelException e) {
29 // Closed as requested.
30 } catch (Throwable t) {
31 if (logger.isWarnEnabled()) {
32 logger.warn(
33 "Failed to accept a connection.", t);
34 }
35
36 try {
37 Thread.sleep(1000);
38 } catch (InterruptedException e1) {
39 // Ignore
40 }
41 }
42 }
43 }
第 15 行 netty 调用 accept 从全连接队列取走连接,第 19 行调用 registerAcceptedChannel,将当前 fd 设置为非阻塞同时为新连接 fd 注册事件,具体的逻辑是在 org.jboss.netty.channel.socket.nio.NioWorker.RegisterTask#run中。
从错误日志中可以知道,这个方法确实抛出了 java.lang.OutOfMemoryError 异常。
因此这里的原因就很清楚了,netty 这里的处理确实不健壮,一个 try-catch 包裹了 accept 连接和注册事件这两个逻辑,当第 15 行 accept 成功,但在 19 行 registerAcceptedChannel 内部尝试注册事件时因为线程 OOM 排除异常时就凉凉了,没有close 这个新连接,就导致了后面收到 fin 以后根本不会回复任何包(epoll 里压根没有这个 fd 的感兴趣事件)。
模拟复现
有几种方法,直接字节码注入一下,抛出异常或者直接改 netty 源码重新构建一下。因为本地有 netty 的源码,采用了此方法更快。
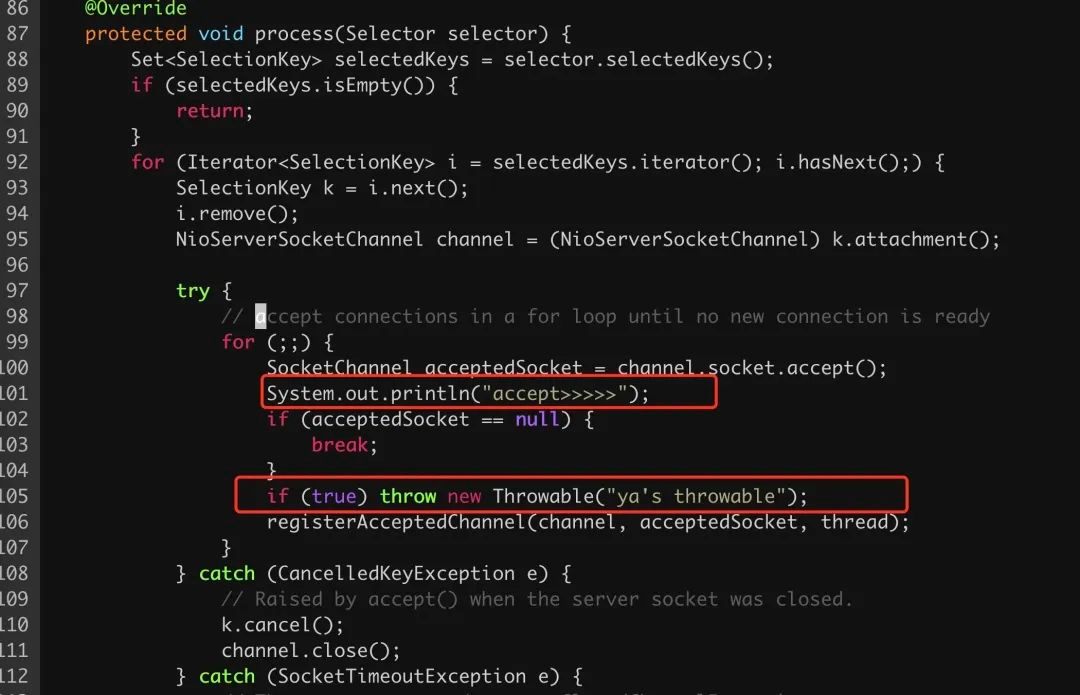
重新构建项目,然后用 nc 模拟健康检查握手然后 ctrl-c 断开连接。
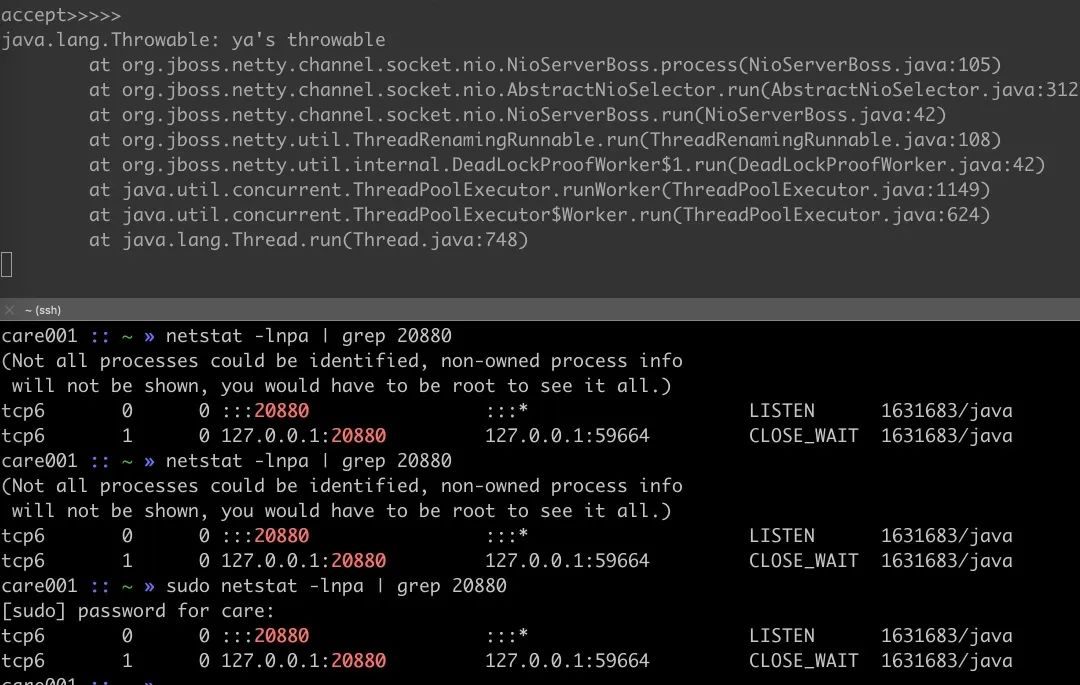
这个 CLOSE_WAIT 就一直存在了直到 netty 进程退出。再来一次 nc 然后断开就又多了一个 CLOSE_WAIT。
因为我们线上的服务的健康检查一直在进行,导致 OOM 期间 CLOSE_WAIT 持续增加。写一个最简单的 go 程序模拟持续的健康检查
func main() {
for i := 0; i < 200; i++ {
println(i)
conn, err := net.Dial("tcp", "192.168.31.197:20880")
if err != nil {
println(err)
time.Sleep(time.Millisecond * 1500)
continue
}
conn.Close()
time.Sleep(time.Millisecond * 1500)
}
time.Sleep(time.Minute * 20000000)
}
确实会出现大量 CLOSE_WAIT
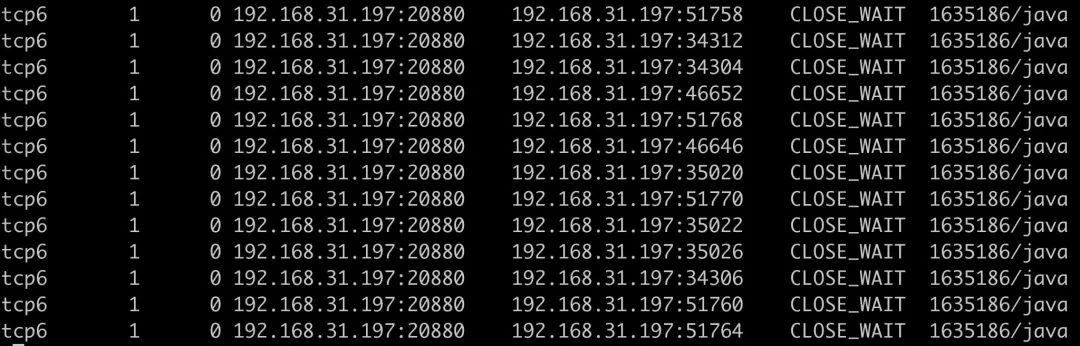
到这里的问题就很清楚了,总结就是 netty 的代码不够健壮,一个 try-catch 包裹的逻辑太多,在 OOM throwable 异常处理时,没能成功注册事件也没有 close 已创建的连接,导致连接存在但是没有人监听事件处理。
可能有人会的一些疑问,为什么没有人监听事件了,收到 fin 包,还是会回复 ACK?
因为回复 ACK 是内核协议栈的行为,不需要应用参与,也不需要关心是否有人感兴趣。
如何修改
修改就很简单了,在 catch 的 throwable 逻辑里关闭一下就可以了,这里就不贴代码了。
最新版本的 netty 代码这部分代码看起来应该是完善了(没有去做实验),它把 accept 和注册事件拆分开了,感兴趣的同学可以试试。
后记
学好 TCP、网络编程是解决这些类似问题的利器,隔离在家一起学起来。



