
记一次线上RPC超时故障排查及后续GC调优思路原创
本文记录了一次线上RPC服务调用超时问题的排查流程,排查过程中涉及到 JVM 优化的过程与思路,包括 JVM GC 原理以及问题排查思路,分享出来希望对大家有所帮助。
本文概要
-
RPC服务异常和排查过程 -
排查方向 -
问题根因和解决方案 -
JVM GC 原理与优化方案 -
基础排查工具使用
问题背景
RPC 服务调用方反馈服务有时会有超时。
查看监控平台发现有客户端调用超时,调用方的超时时间设置为 1s。
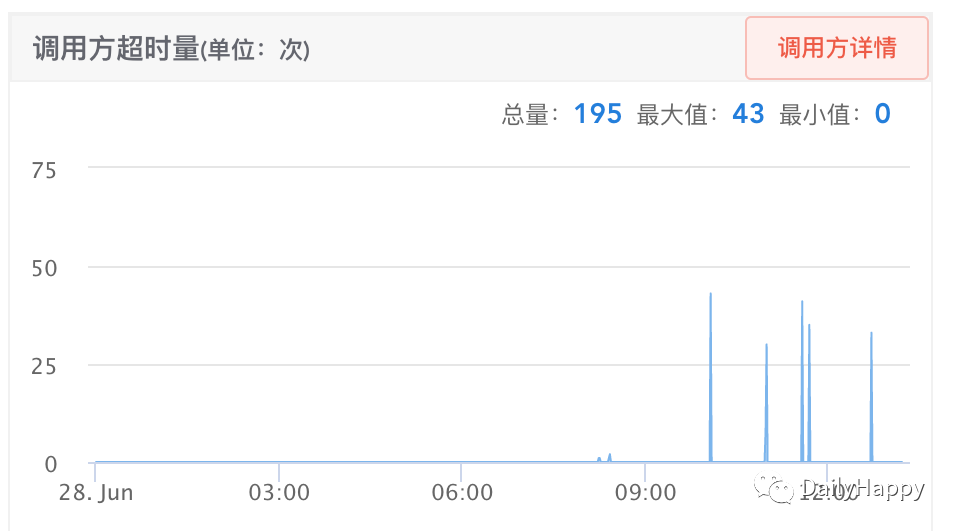
追根溯源
猜测1:JVM GC 时业务线程停顿,导致客户端超时。
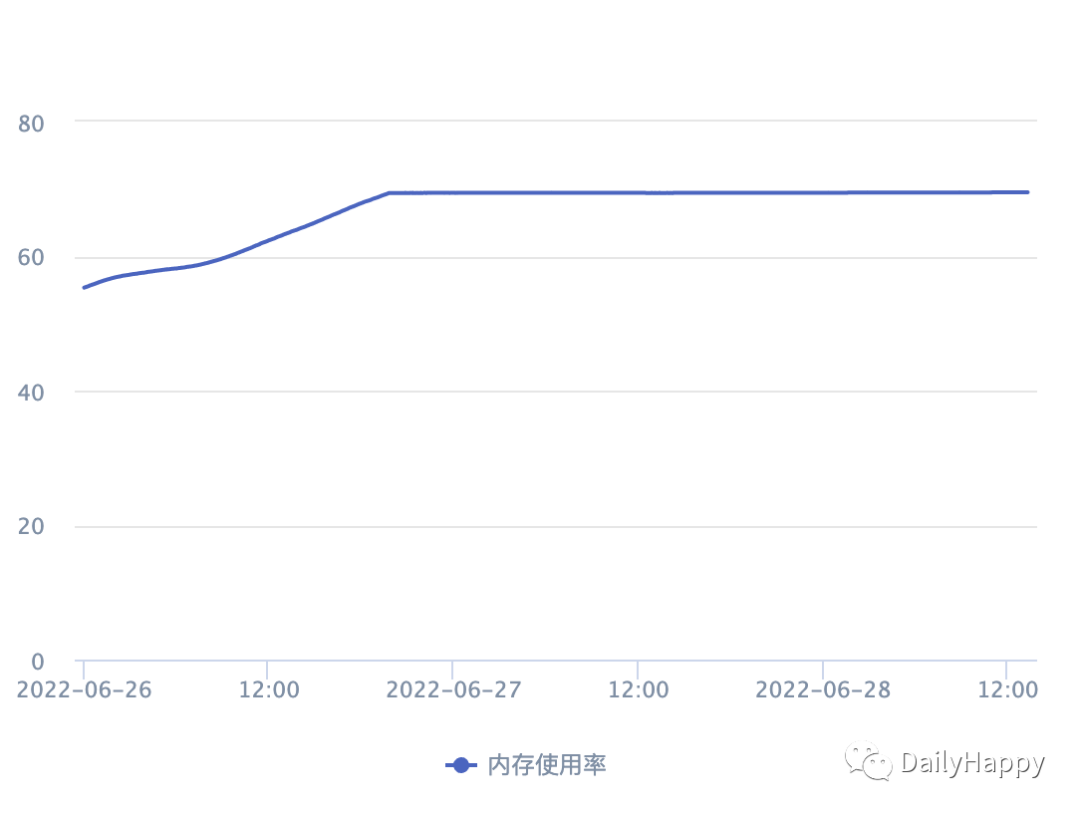
遂查看节点的内存使用率,发现在有大量超时异常时,服务节点的内存使用率并没有明显的变化。此时觉得应该不是 GC 导致的问题。(埋下大坑)
查看 RPC 服务配置的线程为 128。

猜测3:批量调用接口时,所有请求都没用命中缓存,导致客户端超时。
服务处理请求时,如果没有命中缓存会从 DB,Wtable(内部组件,类Redis),HTTP 获取原始数据,然后逐个设置缓存,方便下次使用。每次设置缓存的方式如下:
infos.forEach(info -> {
cacheService.setCache(CacheKey.V1_DETAILINFO.getKey(), info, CacheExpire.HOUR_1.getTime());
});
获取了每个原始数据后,挨个设置缓存,过期时间统一为 1 小时。一小时后这些缓存同时过期,过期后的请求就会再次获取原始数据,导致请求响应时间变长。
优化如下:
infos.forEach(info -> {
cacheService.setCache(CacheKey.DETAILINFO.getKey(), info, CacheExpire.HOUR_1.getTime() + random.nextInt(300));
});
同一批设置缓存的过期时间有一个随机数误差,让这一批缓存数据不至于同时过期,部分缓存过期后的请求时间相比全部缓存过期就会变短。分散同时获取原始数据的数量,降低延迟。
这一优化上线后,查看监控确实有效果,客户端超时数量锐减。此时,眉头舒展,觉得问题已经解决。
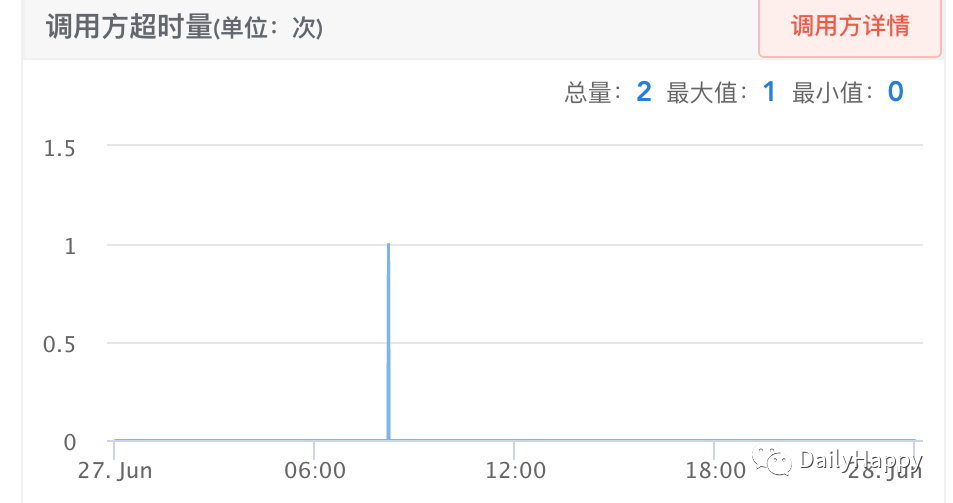
好景不长,没过两天,调用方同学反馈又有超时。
猜测4:数据库连接池不够用,需要 DB 操作时等待连接,导致客户端超时。
通过 trace 平台查看请求的调用链:
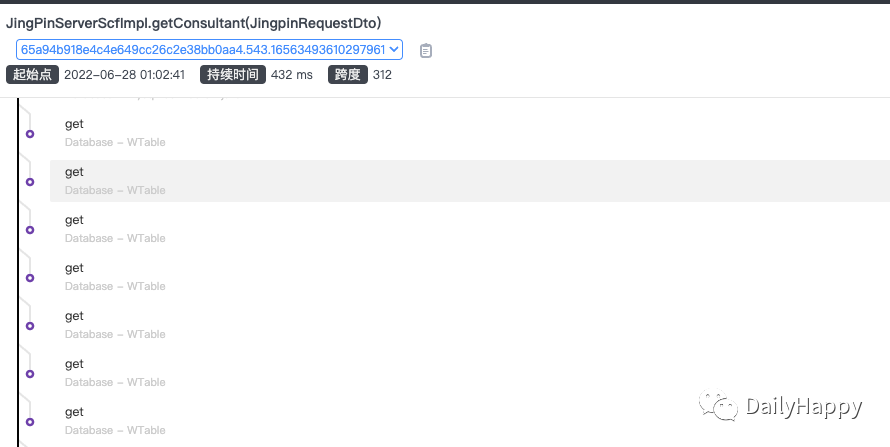
发现在一个请求调用链中有出现大量的 Wtable(内部组件,类Redis) 和 Redis 的 get 或者 set 操作,有的高达上百个。按每个 wtable、redis 的操作 1ms 算,那加起来也有上百毫秒。查看代码发现部分接口在循环里获取、设置缓存。但是这种情况不至于导致接口超时,所以没有立即着手优化。(尽量不要为了方便,在循环里有任何 IO 操作,最好批量 IO)

在有些慢请求中发现 MySQL 操作占用了时间线的绝大部分,怀疑可能有慢查询。但是查看数据库平台发现超时时刻并没有慢查询。
这时大胆怀疑起了 MySQL 的连接池不够(连接池最大连接数设置为 30),有需要操作 DB 时等待获取连接,导致 trace 统计 MySQL 操作时间长但是又没有慢查询的问题。很河狸。
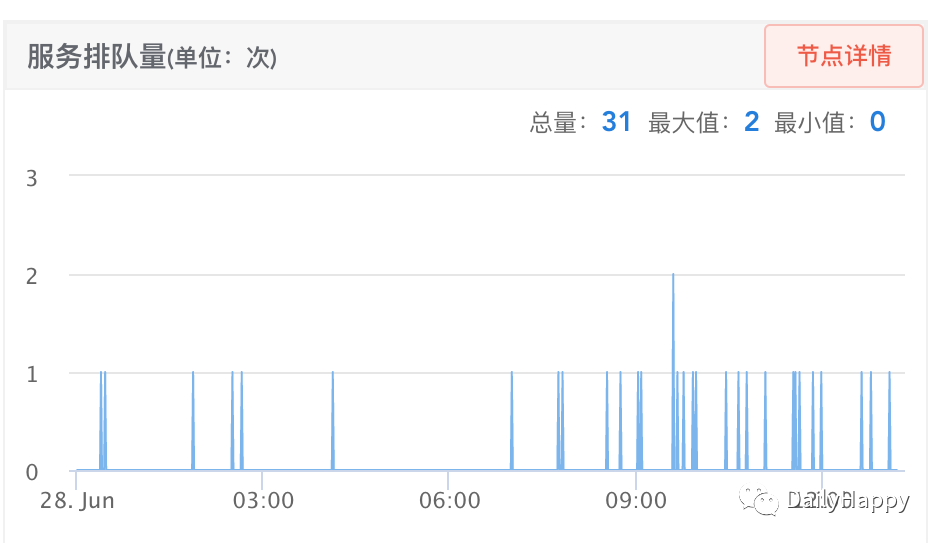
为了方便观察连接池的状态,在服务增加了连接池监控,包含连接数量,活跃数量,空闲数量以及等待连接的数量,监控内容如下图所示:
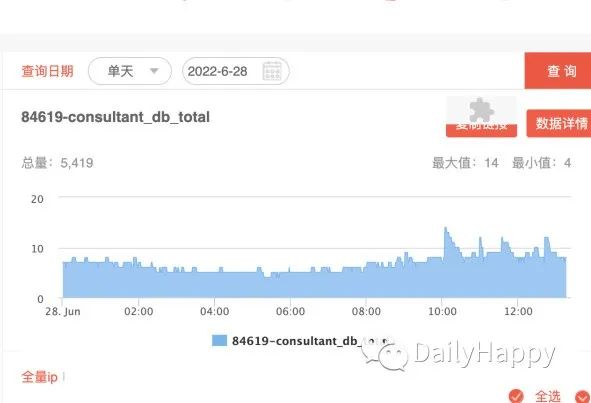
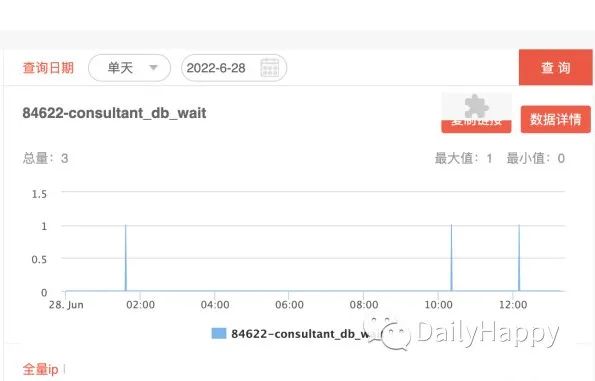
查看连接池监控,在有客户端超时时,总的连接数量最高为 14,并没有超过设定的 30,等待获取连接的也基本没有,说明我们猜测连接池不够导致超时的设想也不成立。
一顿操作猛如虎,一看战绩零杠五,心态已经爆炸。
水落石出
没有其他排查方向,重新怀疑最先排除的 GC 问题。
服务节点的配置是 8C16G,服务使用的垃圾收集器为 CMS,堆内存为 12G。
因为没有输出 GC 日志,只能通过 jstat 简单查看 GC 情况,准备修改 JVM 参数,输出详细 GC 日志时,在监控平台发现了详细的 JVM 监控:
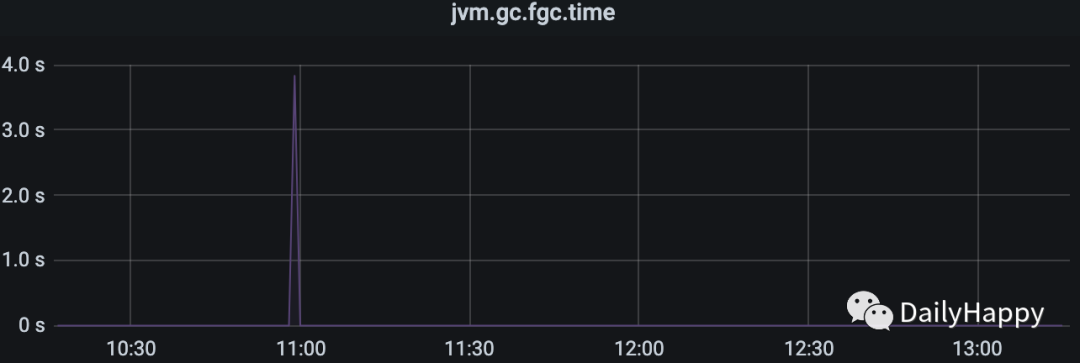
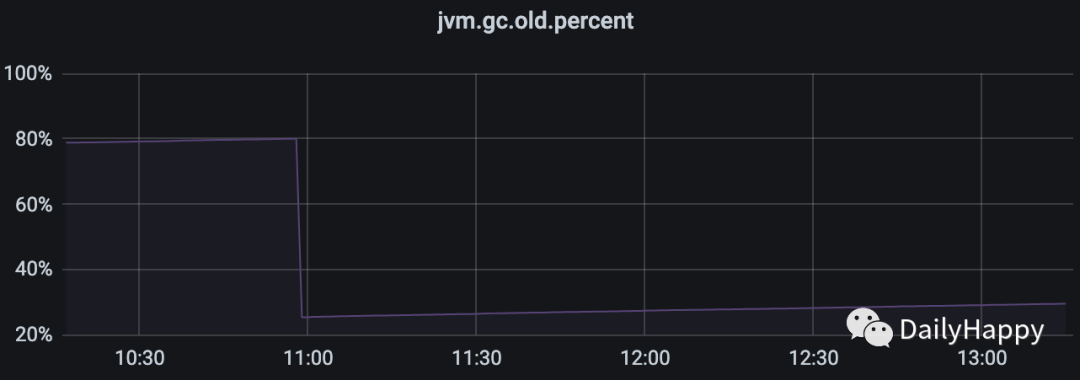
在 11 点钟 FGC 的时间接近 4s,老年代使用率从 80% 降到 20% 多。堆内存为 12G,新生代配置 4G,老年代为 8G,意味着回收近 4.8G 老年代内存耗时 4s。此时这个节点有客户端超时的情况。
为什么 FGC 的时间会突然这么长?五月下旬发现容器的内存有 16G 但堆内存只配了 8G,所以将堆内存调整为 12G。从历史监控数据可以看到调整之前每天一次 FGC 的频率,变成每 1.7 天一次,FGC 的时间 1s 增加到 3s。
因为堆内存较大,CMS 比较适合小内存的 JVM,大内存时在 FGC 需要回收较多对象时会造成长时间停顿。
目前在小内存应用上 CMS 的表现大概率仍然要会优于 G1,而在大内存应用上 G1 则大多能发挥其优势,这个优劣势的 Java 堆容量平衡点通常在 6GB 至 8GB 之间,当然,以上这些也仅是经验之谈,不同应用需要量体裁衣地实际测试才能得出最合适的结论,随着 HotSpot 的开发者对 G1 的不断优化,也会让对比结果继续向 G1 倾斜。《深入理解Java虚拟机》
所以没有优化 CMS FGC 的耗时直接将垃圾收集器调整为 G1,并输出 GC 日志:
-Xms12g
-Xmx12g
-Xss1024K
-XX:MetaspaceSize=128m
-XX:MaxMetaspaceSize=256m
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/opt/logs/server.hprof
-XlogGC:/opt/logs/GC-server.log
-verbose:GC
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails
观察三天发现问题解决,没有 FGC, YGC 频率降低,GC time下降:
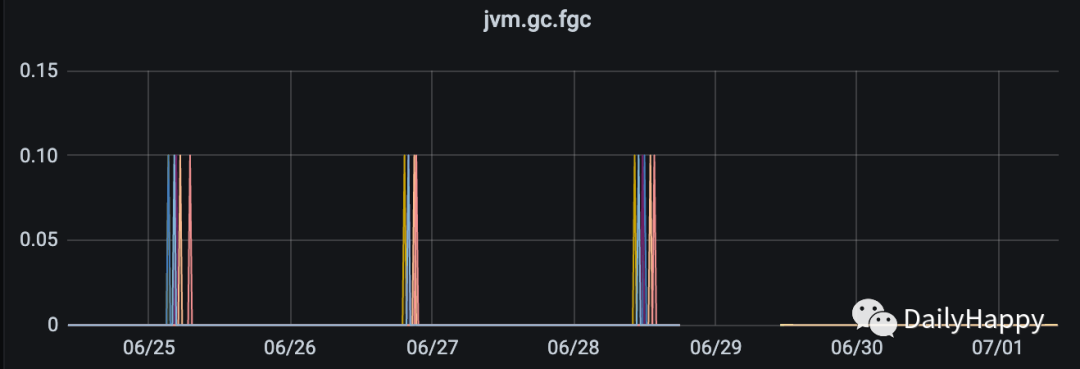
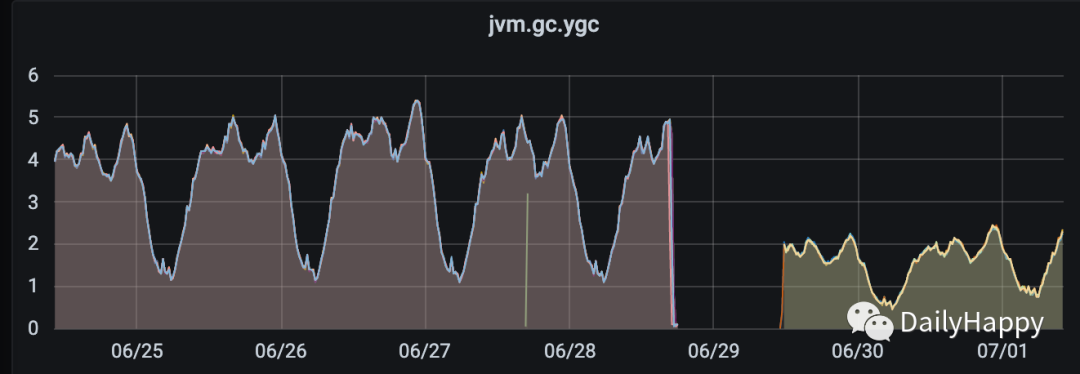
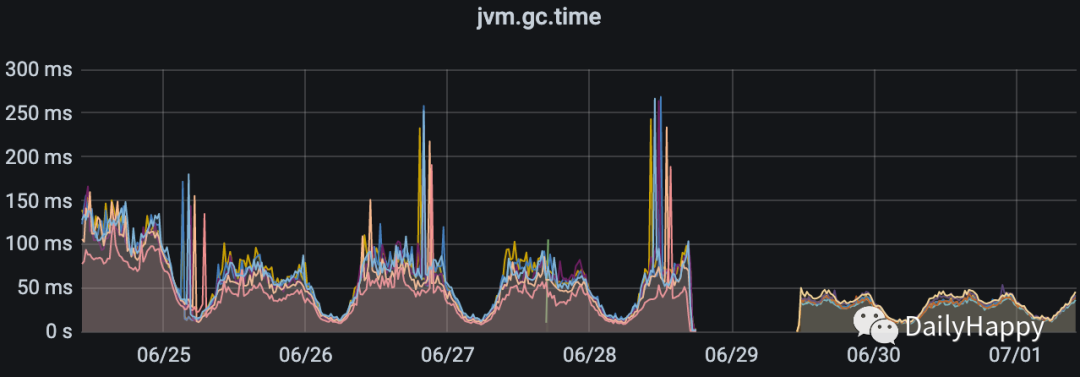
G1 GC 优化
正当我截出上面三张图时,传来噩耗,又出现大量超时,查看 GC 日志:
//初始标记阶段 - Initial Mark
2022-07-01T10:08:05.605+0800: 236284.460: [GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.0225183 secs]
[Eden: 5460.0M(5460.0M)->0.0B(5484.0M) Survivors: 32.0M->20.0M Heap: 10.7G(12.0G)->5500.9M(12.0G)]
[Times: user=0.07 sys=0.02, real=0.03 secs]
2022-07-01T10:08:05.627+0800: 236284.482: [GC concurrent-root-region-scan-start]
2022-07-01T10:08:05.640+0800: 236284.495: [GC concurrent-root-region-scan-end, 0.0124812 secs]
//并发标记阶段 - Concurrent Mark
2022-07-01T10:08:05.640+0800: 236284.495: [GC concurrent-mark-start]
2022-07-01T10:08:05.856+0800: 236284.711: [GC concurrent-mark-end, 0.2160935 secs]
//最终标记阶段 - Remark
2022-07-01T10:08:05.860+0800: 236284.715: [GC remark 2022-07-01T10:08:05.860+0800: 236284.715: [Finalize Marking, 0.0010205 secs] 2022-07-01T10:08:05.861+0800: 236284.716: [GC ref-proc, 4.9682204 secs] 2022-07-01T10:08:10.829+0800: 236289.684: [Unloading, 0.0406443 secs], 5.0155142 secs]
[Times: user=5.06 sys=0.23, real=5.01 secs]
//清理阶段 - Clean Up
2022-07-01T10:08:10.879+0800: 236289.734: [GC cleanup 5564M->5544M(12G), 0.0093801 secs]
[Times: user=0.04 sys=0.02, real=0.01 secs]
2022-07-01T10:08:10.889+0800: 236289.744: [GC concurrent-cleanup-start]
2022-07-01T10:08:10.889+0800: 236289.744: [GC concurrent-cleanup-end, 0.0000416 secs]
2022-07-01T10:08:51.933+0800: 236330.788: [GC pause (G1 Evacuation Pause) (young), 0.0200670 secs]
[Eden: 5484.0M(5484.0M)->0.0B(576.0M) Survivors: 20.0M->36.0M Heap: 10.7G(12.0G)->5498.2M(12.0G)]
//第一次mixed GC
2022-07-01T10:08:55.212+0800: 236334.067: [GC pause (G1 Evacuation Pause) (mixed), 0.1236984 secs]
[Eden: 576.0M(576.0M)->0.0B(580.0M) Survivors: 36.0M->32.0M Heap: 6074.2M(12.0G)->5177.9M(12.0G)]
[Times: user=0.91 sys=0.00, real=0.12 secs]
//第二次mixed GC
2022-07-01T10:08:58.241+0800: 236337.096: [GC pause (G1 Evacuation Pause) (mixed), 0.2377220 secs]
[Eden: 580.0M(580.0M)->0.0B(584.0M) Survivors: 32.0M->28.0M Heap: 5757.9M(12.0G)->4877.3M(12.0G)]
[Times: user=1.29 sys=0.37, real=0.24 secs]
//第三次mixed GC
2022-07-01T10:09:01.041+0800: 236339.896: [GC pause (G1 Evacuation Pause) (mixed), 0.2694744 secs]
[Eden: 584.0M(584.0M)->0.0B(584.0M) Survivors: 28.0M->28.0M Heap: 5461.3M(12.0G)->4589.9M(12.0G)]
[Times: user=1.66 sys=0.31, real=0.27 secs]
//第四次mixed GC
2022-07-01T10:09:03.574+0800: 236342.429: [GC pause (G1 Evacuation Pause) (mixed), 0.2417761 secs]
[Eden: 584.0M(584.0M)->0.0B(580.0M) Survivors: 28.0M->32.0M Heap: 5173.9M(12.0G)->4312.0M(12.0G)]
[Times: user=1.48 sys=0.32, real=0.24 secs]
//第五次mixed GC
2022-07-01T10:09:06.137+0800: 236344.992: [GC pause (G1 Evacuation Pause) (mixed), 0.2646752 secs]
[Eden: 580.0M(580.0M)->0.0B(580.0M) Survivors: 32.0M->32.0M Heap: 4892.0M(12.0G)->4038.0M(12.0G)]
[Times: user=1.59 sys=0.21, real=0.26 secs]
//第六次mixed GC
2022-07-01T10:09:08.762+0800: 236347.617: [GC pause (G1 Evacuation Pause) (mixed), 0.1496482 secs]
[Eden: 580.0M(580.0M)->0.0B(572.0M) Survivors: 32.0M->40.0M Heap: 4618.0M(12.0G)->3911.4M(12.0G)]
[Times: user=1.05 sys=0.05, real=0.15 secs]
2022-07-01T10:09:23.415+0800: 236362.270: [GC pause (G1 Evacuation Pause) (young), 0.0135612 secs]
[Eden: 588.0M(588.0M)->0.0B(584.0M) Survivors: 24.0M->28.0M Heap: 4535.6M(12.0G)->3953.6M(12.0G)]
[Times: user=0.06 sys=0.03, real=0.02 secs]
//多次young GC后,新生代扩容
2022-07-01T10:09:26.096+0800: 236364.951: [GC pause (G1 Evacuation Pause) (young), 0.0145410 secs]
[Eden: 584.0M(584.0M)->0.0B(7028.0M) Survivors: 28.0M->24.0M Heap: 4537.6M(12.0G)->3950.7M(12.0G)]
[Times: user=0.07 sys=0.02, real=0.02 secs]
这次的日志可以总结出下面几个问题:
为什么发生 mixed GC ?
当达到 IHOP 阈值,-XX:InitiatingHeapOccupancyPercent(默认45%)时,老年代使用内存占到堆总大小的 45% 的时候,G1 将开始并发标记阶段 + Mixed GC。
GC 日志可以看到初始标记时老年代大概 5500.9M,堆内存 12G,5500 / 12000 ≈ 45.8%。
为什么 GC ref-proc 耗时这么长?
ref-proc 其实是对各种软弱虚引用等的处理。
日志中 ref-proc 4.9682204s 就是处理 soft、weak、phantom、final、JNI 等等引用的时间。
初步怀疑是 softReference 或者是 finalReference 导致耗时较长。
为什么新生代 5484.0M 变为 576.0M?
remark 阶段的耗时较长,导致 G1 新生代自适应策略认为需要尽可能的调小新生代大小,以满足 200ms 的期望停顿时间,但是新生代最小值 -XX:G1NewSizePercent 在未配置的情况下为 5%,大概为 12G * 5% = 600M 左右。
为什么连续 6 次 mixed GC?
-XX:G1MixedGCCountTarget,默认为8,这个参数标识最后的混合回收阶段会执行8次,一次只回收掉一部分的Region,然后系统继续运行,过一小段时间之后,又再次进行混合回收,重复8次。执行这种间断的混合回收,就可以把每次的混合回收时间控制在我们需要的停顿时间之内了,同时达到垃圾清理的效果。
清理了 6 次就已经满足了回收效果,所以没有继续 mixed GC。
为什么新生代 584.0M 变为 7028.0M?
mixed GC 之后的 YGC 耗时与期望停顿时间之间还有较大距离,所以 G1 新生代自适应策略认为加大新生代空间也能满足期望停顿时间,并能减少 YGC 的频率,所以增加了新生代的大小。
这么分析下来发现这一系列的问题都是因为 GC ref-proc 耗时较长导致的,然后在 G1 官网发现如下建议:
Reference Object Processing Takes Too Long
Information about the time taken for processing of Reference Objects is shown in the Ref Proc and Ref Enq phases. During the Ref Proc phase, G1 updates the referents of Reference Objects according to the requirements of their particular type. In Ref Enq, G1 enqueues Reference Objects into their respective reference queue if their referents were found dead. If these phases take too long, then consider enabling parallelization of these phases by using the option
-XX:+ParallelRefProcEnabled.
大意为默认情况 ref-proc 阶段是单线程执行的,若该阶段耗时较长,可以添加 -XX:+ParallelRefProcEnabled 参数,尽量在该阶段使用多线程处理,在添加该参数的基础上,我们还新增了 -XX:+PrintReferenceGC ,方便在日志中看到 ref-proc 阶段中的耗时详情:
-Xms12g
-Xmx12g
-Xss1024K
-XX:MetaspaceSize=128m
-XX:MaxMetaspaceSize=256m
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:+ParallelRefProcEnabled
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/opt/logs/server.hprof
-XlogGC:/opt/logs/GC-server.log
-verbose:GC
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails
-XX:+PrintReferenceGC
上线之后等待了 2.5 天,mixed GC 如约而至:
[GC remark 2022-07-03T20:20:45.784+0800: 200955.276: [Finalize Marking, 0.0009754 secs]
2022-07-03T20:20:45.785+0800: 200955.277: [GC ref-proc2022-07-03T20:20:45.785+0800: 200955.277: [SoftReference, 5985 refs, 0.0016774 secs]
2022-07-03T20:20:45.787+0800: 200955.279: [WeakReference, 833 refs, 0.0004107 secs]
2022-07-03T20:20:45.787+0800: 200955.279: [FinalReference, 61 refs, 0.0009986 secs]
2022-07-03T20:20:45.788+0800: 200955.280: [PhantomReference, 2922 refs, 217 refs, 0.6387731 secs]
2022-07-03T20:20:46.427+0800: 200955.919: [JNI Weak Reference, 0.0002668 secs], 0.6448878 secs] 2022-07-03T20:20:46.430+0800: 200955.922: [Unloading, 0.0426223 secs], 0.6948057 secs]
[Times: user=5.13 sys=0.22, real=0.70 secs]
新增 -XX:+ParallelRefProcEnabled 参数后,ref-proc 阶段耗时共为 0.6448878s,较 4.9682204s 有了巨大提升,虽然没有超时出现,但还是较长,不能容忍,需要继续优化。
ref-proc 阶段主要耗时在处理 PhantomReference 上,共耗时 0.64s。
PhantomReference 是什么?
-
虚引用也称为“幽灵引用”,它是最弱的一种引用关系。 -
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。 -
为一个对象设置虚引用关联的唯一目的只是为了能在这个对象被收集器回收时收到一个系统通知。 -
当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在垃圾回收后,将这个虚引用加入引用队列,在其关联的虚引用出队前,不会彻底销毁该对象。所以可以通过检查引用队列中是否有相应的虚引用来判断对象是否已经被回收了。
大概了解了一点 PhantomReference 是什么之后,为了搞清楚 PhantomReference 类型的到底是哪些对象,我们查看堆文件中的对象分布,发现 PhantomReference 类型大部分都是这个类 com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference,有2439个。(dump 文件时务必摘除该节点的流量,否则影响线上请求)
217: 2439 78048 com.mysql.jdbc.NonRegisteringDriver$ConnectionPhantomReference
ConnectionPhantomReference 是什么对象?
在 MySql jdbc 驱动代码中发现,NonRegisteringDriver 类有个虚引用集合 connectionPhantomRefs 用于存储所有的数据库连接,NonRegisteringDriver.trackConnection 方法负责把新创建的连接放入 connectionPhantomRefs 集合:
public class NonRegisteringDriver implements Driver {
...
protected static final ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference> connectionPhantomRefs = new ConcurrentHashMap();
protected static void trackConnection(com.mysql.jdbc.Connection newConn) {
ConnectionPhantomReference phantomRef = new ConnectionPhantomReference((ConnectionImpl)newConn, refQueue);
connectionPhantomRefs.put(phantomRef, phantomRef);
}
...
}
public ConnectionImpl(String hostToConnectTo, int portToConnectTo, Properties info, String databaseToConnectTo, String url) throws SQLException {
...
NonRegisteringDriver.trackConnection(this);
...
}
使用 HikariCP 连接池为何还会生成这么多连接?
HikariCP 连接池有个 maxLifeTime 配置项,意思为连接的最长存活时间,超过该时间则回收该连接,然后生成新连接。我们的配置中没有设置该值,源码中默认为 30 分钟,意味着我们生成的连接最多使用 30 分钟。
// HikariCP maxLifeTime 默认值
MAX_LIFETIME = TimeUnit.MINUTES.toMillis(30L);
因此我们虽使用了连接池,也会不断的创建新连接。新的连接不断增加 NonRegisteringDriver 类中虚引用集合 connectionPhantomRefs的虚引用数量,累计一定数量之后增加 ref-proc 的耗时。
问题定位了,我们只能减少虚引用集合中的虚引用数量,也就是减少生成新连接的速度,最大限度使用有效连接。
HikariCP 作者有如下建议:
But if you update your HikariCP version to 2.7.4 with JDK 8, i also recommend you two points:
to set maxLifeTime value to be at least 30000ms.
to set maxLifeTime value few minute less than mysql’s wait_timeout(show variables like “%timeout%”) to avoid broken connection exception.
maxLifeTime 的值至少为30000ms。
maxLifeTime 的值比数据库的 wait_timeout 值少几分钟为好。
我们 MySql 的 wait_timeout 默认为 3600 秒,所以将 maxLifeTime 设置为59分钟,同时将空闲连接的存活时间调整为 30 分钟,最大限度的减少新连接的生成。
dbConfig.setMaxLifetime(TimeUnit.MINUTES.toMillis(59L));
dbConfig.setIdleTimeout(TimeUnit.MINUTES.toMillis(30L));
连接池优化上线 3.5 天后,再次迎来了mixed GC:
2022-07-07T22:41:29.227+0800: 300734.449: [GC remark 2022-07-07T22:41:29.227+0800: 300734.449: [Finalize Marking, 0.0012842 secs]
2022-07-07T22:41:29.228+0800: 300734.451: [GC ref-proc2022-07-07T22:41:29.228+0800: 300734.451: [SoftReference, 6013 refs, 0.0020042 secs]
2022-07-07T22:41:29.230+0800: 300734.453: [WeakReference, 1138 refs, 0.0005509 secs]
2022-07-07T22:41:29.231+0800: 300734.453: [FinalReference, 196 refs, 0.0019740 secs]
2022-07-07T22:41:29.233+0800: 300734.455: [PhantomReference, 2350 refs, 235 refs, 0.5898343 secs]
2022-07-07T22:41:29.823+0800: 300735.045: [JNI Weak Reference, 0.0002747 secs], 0.5970905 secs]
2022-07-07T22:41:29.825+0800: 300735.048: [Unloading, 0.0432827 secs], 0.6473847 secs]
[Times: user=4.73 sys=0.23, real=0.65 secs]
虽然我们调长了连接池连接的生命时长,但是这次上线 3.5 天才发生 mixed GC,积累的连接虚引用还是没怎么变少,有 2000 多个,ref-proc 阶段的耗时依旧长达 0.6473847s。
因为 MySql 的 wait_timeout 值为 3600 秒,maxLifeTime 的值也无法超过一个小时,所以 ref-proc 耗时仍不理想,会导致 G1 将新生代调整的较小,连续触发 GC。
大力出奇迹
虚引用往往做为一种兜底策略,避免用户忘记释放资源,引发内存泄露。我们使用连接池会严谨处理资源的释放,可以不采用兜底策略,直接删除中 connectionPhantomRefs 中的虚引用,使对象不可达,在 GC 时直接回收,从而减少 PhantomReference 的处理时间。
使用定时任务清理 connectionPhantomRefs:
// 每两小时清理 connectionPhantomRefs,减少对 mixed GC 的影响
SCHEDULED_EXECUTOR.scheduleAtFixedRate(() -> {
try {
Field connectionPhantomRefs = NonRegisteringDriver.class.getDeclaredField("connectionPhantomRefs");
connectionPhantomRefs.setAccessible(true);
Map map = (Map) connectionPhantomRefs.get(NonRegisteringDriver.class);
if (map.size() > 50) {
map.clear();
}
} catch (Exception e) {
log.error("connectionPhantomRefs clear error!", e);
}
}, 2, 2, TimeUnit.HOURS);
定时清理 connectionPhantomRefs 的操作在某种程度上来说还是有点暴力,保险起见我们在测试平台进行了几天的稳定性测试,没有什么问题后再上线。
3.5 天后迎来喜讯, YGC 耗时 20 毫秒左右,mixed GC 耗时 10-40 毫秒左右,ref-proc 阶段耗时共为 10 毫秒,PhantomReference 阶段耗时 0.5 毫秒,符合预期:
2022-07-11T20:21:09.227+0800: 267282.500: [GC ref-proc2022-07-11T20:21:09.227+0800: 267282.500: [SoftReference, 6265 refs, 0.0018357 secs]
2022-07-11T20:21:09.229+0800: 267282.502: [WeakReference, 995 refs, 0.0004459 secs]
2022-07-11T20:21:09.229+0800: 267282.502: [FinalReference, 2312 refs, 0.0063426 secs]
2022-07-11T20:21:09.236+0800: 267282.508: [PhantomReference, 0 refs, 268 refs, 0.0005663 secs]
2022-07-11T20:21:09.236+0800: 267282.509: [JNI Weak Reference, 0.0002658 secs], 0.0116221 secs]
2022-07-11T20:21:09.238+0800: 267282.511: [Unloading, 0.0400431 secs], 0.0540532 secs]
[Times: user=0.20 sys=0.11, real=0.06 secs]
[Eden: 5016.0M(5016.0M)->0.0B(532.0M) Survivors: 24.0M->28.0M Heap: 9941.0M(11.0G)->4928.1M(11.0G)]
[Times: user=0.10 sys=0.00, real=0.02 secs]
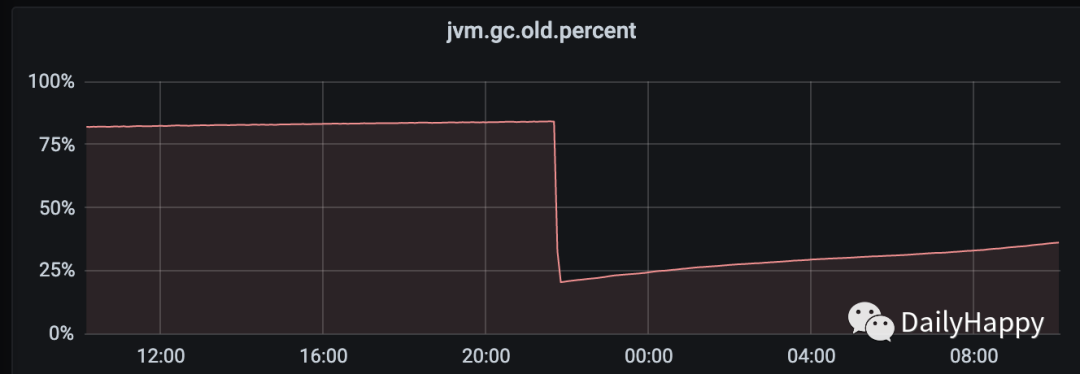
老年代使用比例图:
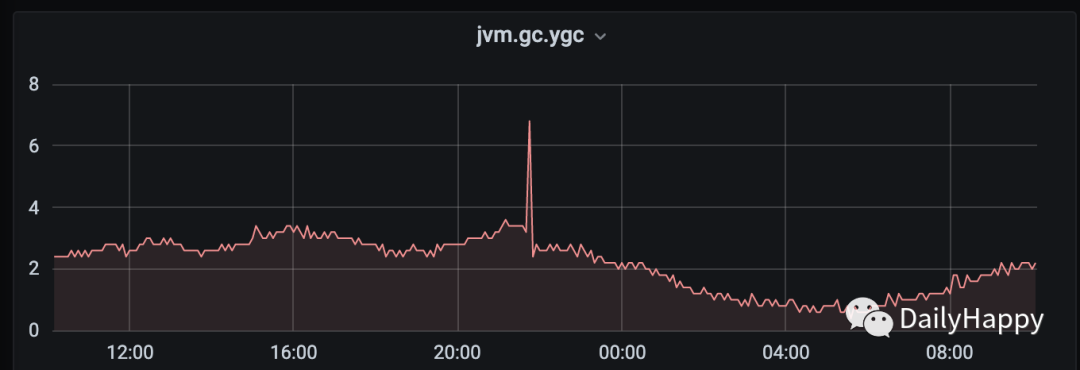
YGC 次数图:
YGC 耗时图:
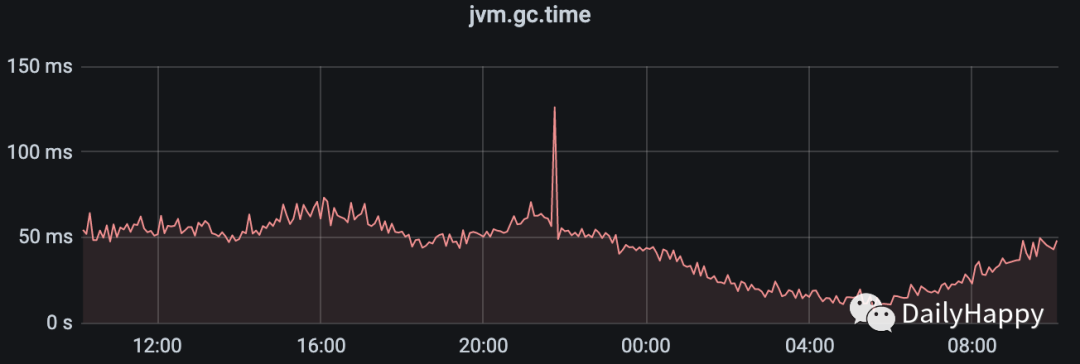
mixed GC 后老年代 85% 到 20%;一分钟内发生 7 次 YGC 或者 mixed GC,共耗时 126 毫秒,平均每次 18 毫秒,完全符合我们的停顿要求。虽然 mixed GC 的耗时已经降低,但是发现 G1 还是会将新生代降到最小,也就是堆的 5%,可能会在后续的几十秒内每两秒一次 GC(每次耗时 10-40 毫秒),如果你觉得不能忍受的话,可以通过 -XX:G1NewSizePercent 来控制最小新生代的大小。
服务的 GC 时长由原来的 CMS FGC 4s 到现在 G1 mixed GC 10-40ms,也没有因为 GC 导致的超时问题了,至此服务的 GC 优化告一段落,但是后续还需要对业务导致的超时进行优化。
G1 YGC 异常耗时探究
后续观察 JVM 监控时发现有个节点的 YGC 时间异常,正常都是几十毫秒,但这次高达 250 毫秒(MaxGCPauseMillis=200):
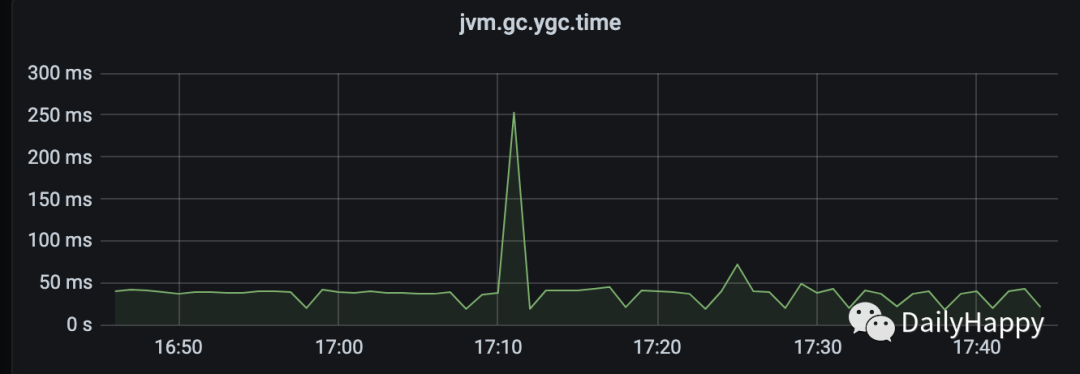
查看该节点的 GC 日志,
正常耗时的 YGC 日志:
2022-06-29T17:11:54.560+0800: 88938.859: [GC pause (G1 Evacuation Pause) (young), 0.0192881 secs]
[Parallel Time: 12.8 ms, GC Workers: 8]
[GC Worker Start (ms): Min: 88938859.5, Avg: 88938859.5, Max: 88938859.6, Diff: 0.1]
[Ext Root Scanning (ms): Min: 2.0, Avg: 2.8, Max: 5.0, Diff: 3.1, Sum: 22.0]
[Update RS (ms): Min: 0.7, Avg: 2.9, Max: 3.7, Diff: 2.9, Sum: 23.0]
[Processed Buffers: Min: 47, Avg: 71.4, Max: 100, Diff: 53, Sum: 571]
[Scan RS (ms): Min: 0.3, Avg: 0.4, Max: 0.4, Diff: 0.1, Sum: 3.1]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[Object Copy (ms): Min: 6.4, Avg: 6.5, Max: 6.6, Diff: 0.2, Sum: 52.0]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 8]
[GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.7]
[GC Worker Total (ms): Min: 12.5, Avg: 12.6, Max: 12.7, Diff: 0.2, Sum: 100.9]
[GC Worker End (ms): Min: 88938872.1, Avg: 88938872.2, Max: 88938872.2, Diff: 0.1]
[Code Root Fixup: 0.3 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.6 ms]
[Other: 5.6 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.3 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.2 ms]
[Humongous Reclaim: 0.1 ms]
[Free CSet: 3.6 ms]
[Eden: 7344.0M(7344.0M)->0.0B(7340.0M) Survivors: 28.0M->32.0M Heap: 9585.0M(12.0G)->2243.5M(12.0G)]
[Times: user=0.08 sys=0.03, real=0.02 secs]
异常耗时的 YGC 日志:
2022-06-29T17:11:19.276+0800: 88903.574: [GC pause (G1 Evacuation Pause) (young), 0.2305707 secs]
[Parallel Time: 223.6 ms, GC Workers: 8]
[GC Worker Start (ms): Min: 88903574.7, Avg: 88903574.7, Max: 88903574.7, Diff: 0.1]
[Ext Root Scanning (ms): Min: 2.1, Avg: 2.9, Max: 5.4, Diff: 3.3, Sum: 23.5]
[Update RS (ms): Min: 0.5, Avg: 3.0, Max: 3.9, Diff: 3.3, Sum: 24.0]
[Processed Buffers: Min: 54, Avg: 71.6, Max: 91, Diff: 37, Sum: 573]
[Scan RS (ms): Min: 0.3, Avg: 0.4, Max: 0.5, Diff: 0.2, Sum: 3.3]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[Object Copy (ms): Min: 5.8, Avg: 32.3, Max: 216.9, Diff: 211.1, Sum: 258.7]
[Termination (ms): Min: 0.0, Avg: 184.7, Max: 211.3, Diff: 211.3, Sum: 1477.6]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 8]
[GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.5]
[GC Worker Total (ms): Min: 223.4, Avg: 223.5, Max: 223.5, Diff: 0.1, Sum: 1787.7]
[GC Worker End (ms): Min: 88903798.1, Avg: 88903798.2, Max: 88903798.2, Diff: 0.1]
[Code Root Fixup: 0.2 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.6 ms]
[Other: 6.1 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.3 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.2 ms]
[Humongous Reclaim: 0.1 ms]
[Free CSet: 3.9 ms]
[Eden: 7344.0M(7344.0M)->0.0B(7344.0M) Survivors: 28.0M->28.0M Heap: 9584.6M(12.0G)->2241.0M(12.0G)]
[Times: user=1.49 sys=0.27, real=0.23 secs]
正常 YGC 日志为 19 毫秒左右,异常为 230 毫秒,对比发现如下异常:
//正常
[Object Copy (ms): Min: 6.4, Avg: 6.5, Max: 6.6, Diff: 0.2, Sum: 52.0]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Times: user=0.08 sys=0.03, real=0.02 secs]
//异常
[Object Copy (ms): Min: 5.8, Avg: 32.3, Max: 216.9, Diff: 211.1, Sum: 258.7]
[Termination (ms): Min: 0.0, Avg: 184.7, Max: 211.3, Diff: 211.3, Sum: 1477.6]
[Times: user=1.49 sys=0.27, real=0.23 secs]
概念介绍
Object Copy (ms) :内存回收过程中将存活对象迁移到新的 region 和 survivor,也有一部分会晋升到老年代region,对象拷贝的时间。Min 为多线程回收中最少的耗时,Avg 为平均耗时,Max 为最大耗时,Diff 为拷贝对象耗时最大差值,Sum 为所有 GC 线程拷贝对象的时间总和。
Termination (ms) :GC 工作线程终止时间。Min 为线程终止最少的耗时,Avg 为平均耗时,Max 为最大耗时,Diff 为耗时最大差值,Sum 为所有 GC 线程终止耗时的总和。
user :JVM 代码耗时。
sys:操作系统耗时。
real:业务线程停顿耗时。
日志异同
可以看到异常日志中 Termination 时间很高,最大耗时 211 毫秒,但是正常的 GC 日志中 Termination 耗时都是 0。
异常日志中的 Object Copy 时间较高,最少 5.8 毫秒,最大 216 毫秒,差值高达 211 毫秒。但是在正常日志中 Object Copy 时间比较平均,都为几毫秒。
异常情况下操作系统耗时 sys = 0.27 比正常 sys = 0.03,高了 9 倍。
初步分析是某个线程在拷贝对象时有些异常,导致 Termination 时间长。所以根因是 Object Copy 时间。
假设 8 个 GC 线程中有一个异常(配置 GC Workers: 8),最大耗时为 211 毫秒,另七个线程为正常 GC 线程的平均耗时6.5毫秒,那计算平均耗时为:
(6.5 * 7 + 211) / 8 = 32.0625,与异常日志中的 Avg: 32.3 基本一致,印证了有一个 GC 线程异常的猜想。
为何异常
查了很多资料没有确切答案,但在 stackoverflow 找到一个貌似可能的答案:
swap activity or transparent huge pages are likely suspects.
关于操作系统耗时较多:
Java Platform, Standard Edition HotSpot Virtual Machine Garbage Collection Tuning Guide 有类似说明:
Common known issues for high system time are:
Particularly in Linux, coalescing of **all pages into huge pages by the Transparent Huge Pages (THP) feature tends to stall random processes, not just during a pause. Because the VM allocates and maintains a lot of memory, there is a higher than usual risk that the VM will be the process that stalls for a long time. Refer to the documentation of your operating system on how to disable the Transparent Huge Pages feature.
意思可能是交换内存或者Transparent Huge Pages (THP) 导致内存操作耗时较长。
查看容器是否启用 Transparent Huge Pages (THP) :

always madvise [never] 表明禁用。
查看容器磁盘 IO 监控:
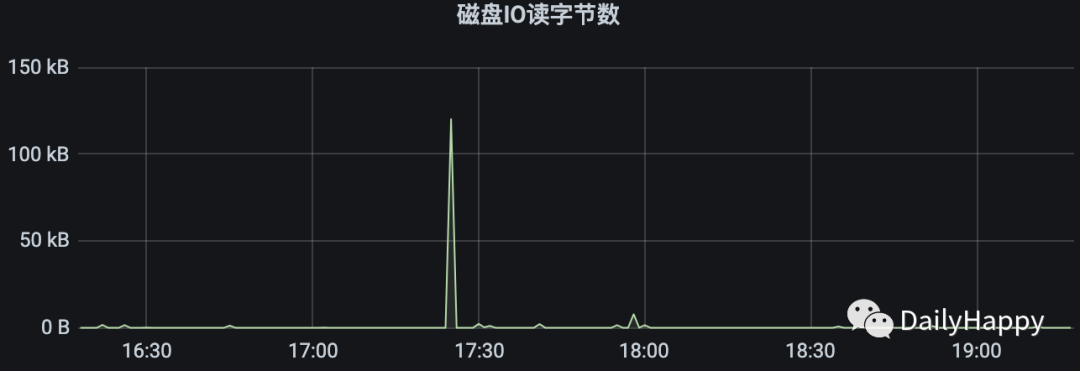
发现异常 YGC 时间附近确实有大量的 IO 操作记录。有可能与交换内存有关。
目前只发现少数异常 YGC 耗时的记录,能力有限没有继续深究根本问题,暂且定位为虚拟运行环境导致系统操作耗时较长导致的问题,有大佬了解可以指点指点。
总结
JVM 启动后会逐步申请至最大堆内存,GC 只将内存清理,并不会释放给系统,所以 FGC 时在节点的内存使用率上看不到内存波动。内存使用率图表导致了错误的判断,错失第一时间发现问题的机会。好在此次排查过程增加了类似问题的排查经验,暴露了一些问题,也增加了数据库连接池的监控。



