Native Memory Tracking 详解(4):使用 NMT 协助排查内存问题案例原创
从前面几篇文章,我们了解了 NMT 的基础知识以及 NMT 追踪区域分析的相关内容,本篇文章将为大家介绍一下使用 NMT 协助排查内存问题的案例。
6.使用 NMT 协助排查内存问题案例
我们在搞清楚 NMT 追踪的 JVM 各部分的内存分配之后,就可以比较轻松的协助排查定位内存问题或者调整合适的参数。
可以在 JVM 运行时使用 jcmd <pid> VM.native_memory baseline 创建基线,经过一段时间的运行后再使用 jcmd <pid> VM.native_memory summary.diff/detail.diff 命令,就可以很直观地观察出这段时间 JVM 进程使用的内存一共增长了多少,各部分使用的内存分别增长了多少,可以很方便的将问题定位到某一具体的区域。
比如我们看到 MetaSpace 的内存增长异常,可以结合 MAT 等工具查看是否类加载器数量异常、是否类重复加载、reflect 的 inflation 参数设置是否合理;如果 Symbol 内存增长异常,可以查看项目 String.intern 是否使用正常;如果 Thread 使用内存过多,考虑是否可以适当调整线程堆栈大小等等。
案例一:虚高的 VIRT 内存
我们还记得前文(NMT 内存 & OS 内存概念差异性章节)中使用 top 命令查看启动的 JVM 进程,仔细观察会发现一个比较虚高的 VIRT 内存(10.7g),我们使用 NMT 追踪的 Total: reserved 才 2813709KB(2.7g),这多出来的这么多虚拟内存是从何而来呢?
top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
27420 douyiwa+ 20 0 10.7g 697560 17596 S 100.0 0.3 0:18.79 java
Native Memory Tracking:
Total: reserved=2813077KB, committed=1496981KB
使用 pmap -X <pid> 观察内存情况:
27420: java -Xmx1G -Xms1G -XX:+UseG1GC -XX:MaxMetaspaceSize=256M -XX:MaxDirectMemorySize=256M -XX:ReservedCodeCacheSize=256M -XX:NativeMemoryTracking=detail -jar nmtTest.jar
Address Perm Offset Device Inode Size Rss Pss Referenced Anonymous LazyFree ShmemPmdMapped Shared_Hugetlb Private_Hugetlb Swap SwapPss Locked Mapping
c0000000 rw-p 00000000 00:00 0 1049088 637236 637236 637236 637236 0 0 0 0 0 0 0
100080000 ---p 00000000 00:00 0 1048064 0 0 0 0 0 0 0 0 0 0 0
aaaaea835000 r-xp 00000000 fd:02 45613083 4 4 4 4 0 0 0 0 0 0 0 0 java
aaaaea854000 r--p 0000f000 fd:02 45613083 4 4 4 4 4 0 0 0 0 0 0 0 java
aaaaea855000 rw-p 00010000 fd:02 45613083 4 4 4 4 4 0 0 0 0 0 0 0 java
aaab071af000 rw-p 00000000 00:00 0 304 108 108 108 108 0 0 0 0 0 0 0 [heap]
fffd60000000 rw-p 00000000 00:00 0 132 4 4 4 4 0 0 0 0 0 0 0
fffd60021000 ---p 00000000 00:00 0 65404 0 0 0 0 0 0 0 0 0 0 0
fffd68000000 rw-p 00000000 00:00 0 132 8 8 8 8 0 0 0 0 0 0 0
fffd68021000 ---p 00000000 00:00 0 65404 0 0 0 0 0 0 0 0 0 0 0
fffd6c000000 rw-p 00000000 00:00 0 132 4 4 4 4 0 0 0 0 0 0 0
fffd6c021000 ---p 00000000 00:00 0 65404 0 0 0 0 0 0 0 0 0 0 0
fffd70000000 rw-p 00000000 00:00 0 132 40 40 40 40 0 0 0 0 0 0 0
fffd70021000 ---p 00000000 00:00 0 65404 0 0 0 0 0
......
可以发现多了很多 65404 KB 的内存块(大约 120 个),使用 /proc/<pid>/**aps 观察内存地址:
......
fffd60021000-fffd64000000 ---p 00000000 00:00 0
Size: 65404 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Rss: 0 kB
Pss: 0 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Referenced: 0 kB
Anonymous: 0 kB
LazyFree: 0 kB
AnonHugePages: 0 kB
ShmemPmdMapped: 0 kB
Shared_Hugetlb: 0 kB
Private_Hugetlb: 0 kB
Swap: 0 kB
SwapPss: 0 kB
Locked: 0 kB
VmFlags: mr mw me nr
......
对照 NMT 的情况,我们发现如 fffd60021000-fffd64000000 这种 65404 KB 的内存是并没有被 NMT 追踪到的。这是因为在 JVM 进程中,除了 JVM 进程自己 mmap 的内存(如 Java Heap,和用户进程空间的 Heap 并不是一个概念)外,JVM 还直接使用了类库的函数来分配一些数据,如使用 Glibc 的 malloc/free (也是通过 brk/mmap 的方式):
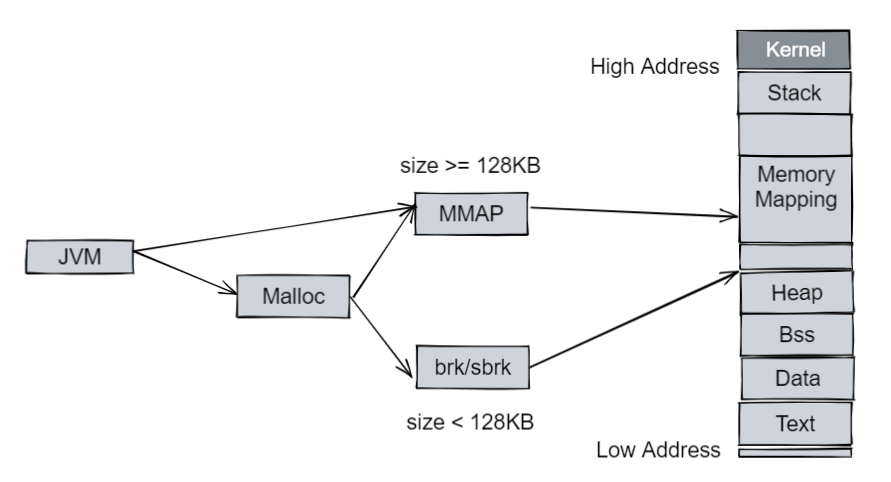
arena 的数量限制在 32 位系统上是 2 * CPU 核心数,64 位系统上是 8 * CPU 核心数,当然我们也可以使用 MALLOC_ARENA_MAX (Linux 环境变量,详情可以查看 mallopt(3)[1])来控制。查看发现运行 JVM 进程的环境 CPU 信息(物理 CPU 核数):Core(s) per socket: 64 。
我们给当前环境设置 MALLOC_ARENA_MAX=2,重启 JVM 进程,查看使用情况:
top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
36319 douyiwa+ 20 0 3108340 690872 17828 S 100.0 0.3 0:07.61 java
虚高的 VIRT 内存已经降下来了,继续查看 pmap/**aps 会发现众多的 65404 KB 的内存空间也消失了(120 * 65404 KB = 7848480 KB 正好对应了 10.7g - 3108340 KB 的内存,即 VIRT 降低的内存)。为什么我们的 JVM 进程会使用如此多的 arena 呢?因为我们在启动 JVM 进程的时候,并没有手动去设置一些进程的数目,如:CICompilerCount(编译线程数)、ConcGCThreads/ParallelGCThreads(并发 GC 线程数)、G1ConcRefinementThreads(G1 Refine 线程数)等等。这些参数大多数根据当前机器的 CPU 核数去计算默认值,使用 jinfo -flags <pid> 查看机器参数发现:
-XX:CICompilerCount=18
-XX:ConcGCThreads=11
-XX:G1ConcRefinementThreads=43
这些线程数目都是比较大的,我们也可以不修改 MALLOC_ARENA_MAX 的数量,而通过参数减小线程的数量来减少 arena 的数量。
Glibc 的 malloc 有时会出现碎片问题,可以使用 jemalloc/tcmalloc 等替代 Glibc。
案例二:堆外内存的排查
有时候我们会发现,Java 堆、MetaSpace 等区域是比较正常的,但是 JVM 进程整体的内存却在不停的增长,此时我们就可以使用 NMT 的 baseline & diff 功能来观察究竟是哪块区域内存一直增长。
比如在一次案例中发现:
Native Memory Tracking:
Total: reserved=8149334KB +1535794KB, committed=6999194KB +1590490KB
......
- Internal (reserved=1723321KB +1472458KB, committed=1723321KB +1472458KB)
(malloc=1723289KB +1472458KB #109094 +47573)
(mmap: reserved=32KB, committed=32KB)
......
[0x00007fceb806607a] Unsafe_AllocateMemory+0x17a
[0x00007fcea1d24e68]
(malloc=1485579KB type=Internal +1455929KB #2511 +2277)
......
我们可以确认内存 1590490KB 的增长,基本上都是由 Internal 的 Unsafe_AllocateMemory 所分配的,此时可以优先考虑 NIO 中 ByteBuffer.allocateDirect / DirectByteBuffer / FileChannel.map 等使用方式是不是出现了泄漏,可以使用 MAT 查看 DirectByteBuffer 对象的数量是否异常,并可以使用 -XX:MaxDirectMemorySize 来限制 Direct 的大小。设置 -XX:MaxDirectMemorySize 之后,进程异常的内存增长停止,但是 GC 频率变高,查看 GC 日志发现:.887+0800: 238210.127: [Full GC (System.gc()) 1175M->255M(3878),0.8370418 secs]。FullGC 的频率大大增加,并且基本上都是由 System.gc() 显式调用引起的(HotSpot中的System.gc()为 FulGC),查看 DirectByteBuffer 相关逻辑:
# DirectByteBuffer.java
DirectByteBuffer(int cap) { // package-private
......
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
# Bits.java
static void reserveMemory(long size, int cap) {
......
System.gc();
......
}
DirectByteBuffer 在 unsafe.allocateMemory(size) 之前会先去做一个 Bits.reserveMemory(size, cap) 的操作,Bits.reserveMemory 会显式的调用 System.gc() 来尝试回收内存,看到这里基本可以确认为 DirectByteBuffer 的问题,排查业务代码,果然发现一处 ByteBufferStream 使用了 ByteBuffer.allocateDirect 的方式而流一直未关闭释放内存,修正后内存增长与 GC 频率皆恢复正常。
参考
-
https://man7.org/linux/man-pages/man3/mallopt.3.html
往期推荐




欢迎加入Compiler SIG交流群与大家共同交流学习编译技术相关内容,扫码添加小助手微信邀请你进入Compiler SIG交流群。