
高并发服务优化篇:浅谈数据库连接池原创
被N多大号转载的一篇CSDN博客,引起了我的注意,说的是数据库连接池使用threadlocal的原因,文中结论如下图所示。
来自CSDN的一篇文章,被很多号转载过
姑且不谈threadlocal的作用和工作原理,单说数据库连接池这个知识点,猛地一看挺有理;仔细一看,怎么感觉不太对啊,同学,这是什么虎狼之词。

$ 实践是检验真理的唯一标准
个人理解,连接池提供的获取连接的能力,需要对"任务"唯一,即,只有当某一线程完成了本次数据操作,将连接放回到连接池之后,其他线程才能够再次获取并使用。原因我们后面细说,先来亲自测试一下。
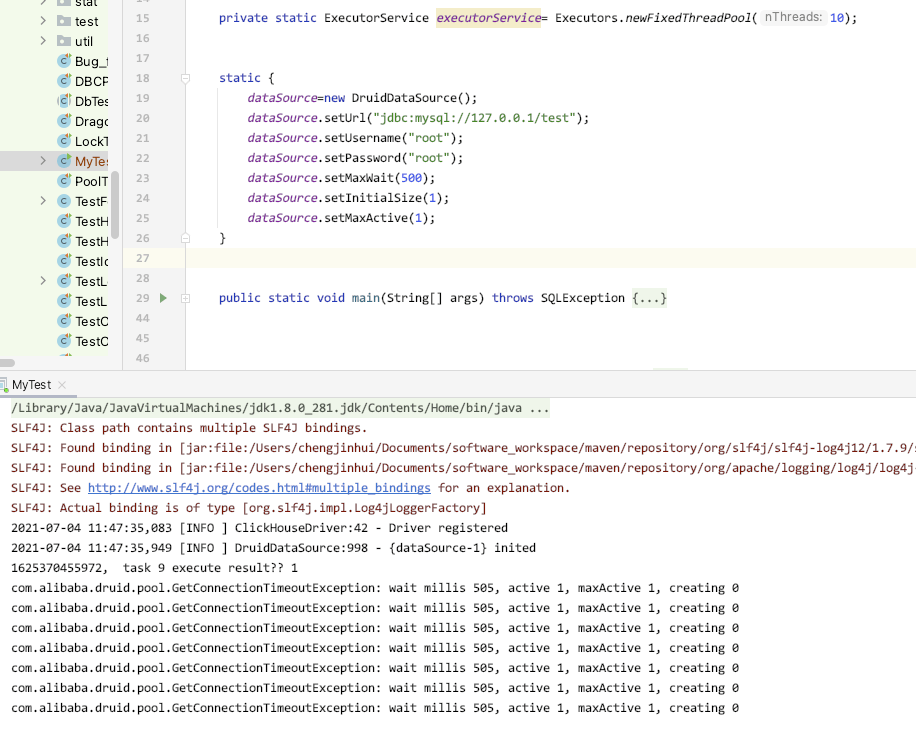
连接池选一个druid,设置连接池中只有一个connection,方便验证多线程应对同一个connection的场景。
首先,将datasource共享资源传入线程,采用datasource.getConnection()方式获取连接 :
注:Runnable中故意不执行connection.close
结果如上图:只有一个线程可以正常执行,由于没有被关闭,其他线程都获取连接失败了。说明,数据库连接池的作用方式是某个线程任务"独占"的。
$ 退一步来讲
假设如同开头文章中描述的,用了一个功能不完备的连接池,让多个线程拿到了同一个connection,那么,用threadlocal真的可以起到互不影响的作用么?
//验证思路参考自:https://blog.csdn.net/sunbo94/article/details/79409298
//Connection设置 autoCommit=false
private static final ThreadLocal<Connection> connectionThreadLocal=new ThreadLocal<>();
private static class InnerRunner implements Runnable{
@Override
public void run() {
//其他代码省略...
String insertSql="insert into user(id,name) value("+RunnerIndex+","+RunnerIndex+")";
statement=connectionThreadLocal.get().createStatement();
statement.executeUpdate(insertSql);
System.out.println(RunnerIndex+" is running");
//让特定的线程执行回滚,用来验证事务之间的影响
if (RunnerIndex==3){
//模拟异常时耗时增加
Thread.sleep(100);
//从threadlocal里拿连接对象
connectionThreadLocal.get().rollback();
System.out.println("3 rollback");
}else{
//从threadlocal里拿连接对象
connectionThreadLocal.get().commit();
System.out.println(RunnerIndex +" commit");
}
}
}
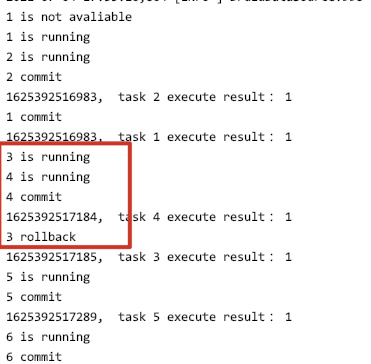
结果如下:
只要是线程3的statement.executeUpdate 语句运行在前,而事务回滚语句执行在某个commit之后,就会出现问题,即需要回滚的数据被提交的情况。
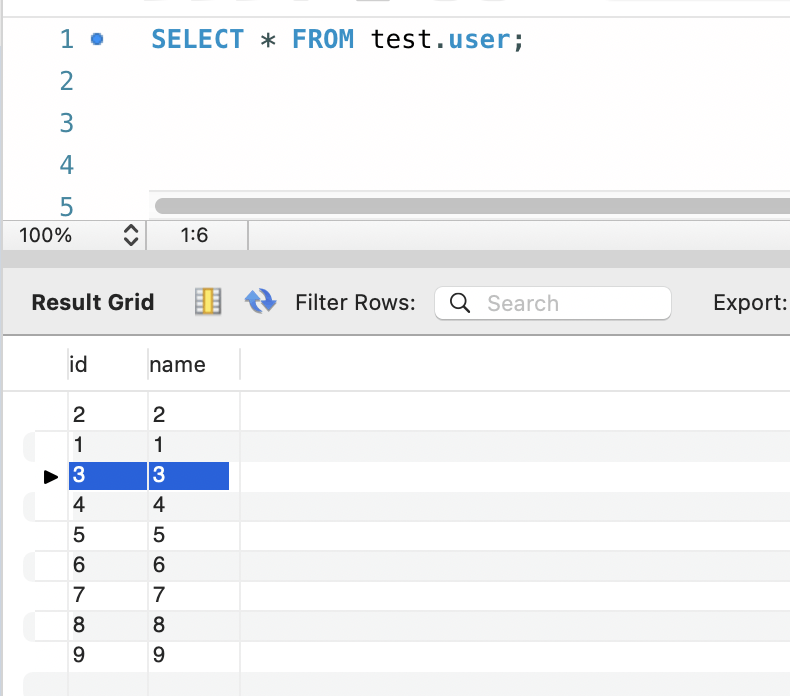
如下图,3的insert结果确实没有被回滚,而是出现在了表中:图片
所以,对于知识,大家不能盲目的接收,建议抱些怀疑的态度,还是有必要的。
$ 话说回来,为什么threadlocal对同一个数据库连接不起作用呢?
Connection是什么?
connection可以当成是服务器和数据库的一个会话,而statemant用来在会话的上下文中执行sql以及返回结果。一个connection可以包含多个statement;然而在两者中间,还有一个事务(Translation)的概念,事务用来保证其内部的语句,要么都执行,要么都不执行,如果autoCommit被开启,则默认是一个语句一个事务。
往简单点说,connection是一种共享资源,更简单一点,它是一个共享变量,在被连接池创建之后,在内存中的地址是唯一的一个变量。
ThreadLocal能存共享变量么?
存肯定能存,但不建议,因为将Connection set进ThreadLocalMap,也其实是保存一个内存对象的地址引用而已,真正使用的时候,还是唯一的那个对象在起作用。
ThreadLocal最常用的功能,是为了避免层层传递而提供了对象保存和获取方法。
高中学数学的时候曾经有过一个技巧,叫证难则反,在这里也适用。我们反过来想,如果用threadlocal的副本拷贝能实现connection的隔离,那岂不是只要一个connection就可以了?实时上呢,数据库连接常常会出现不够用的情况,结论就显而易见了~
$ 话又说回来,threadLocal想要完成数据库连接隔离的功能,需要怎么做呢?
如果非要用ThreadLocal实现这个连接隔离的功能,那么,只能是为每个线程创建新的连接,然后保存在Threadlocal中,这样,每个线程在自己的生命周期范围内只会使用这个连接,即可实现线程隔离。
$ 话又又说回来,druid、zadl等一众数据库连接池是怎么进行连接的管理工作的呢?
最大连接数为1的druid连接池原理概览:

druid维护一个数组来存放连接
同时维护了多个变量来检测连接池的状态,其中poolingCount用来表示池中连接的数量
- 当有线程来获取连接时,需要先加锁,对数量进行减一操作。
- 当获取连接时发现数量为0 ,则返回为空
- 当连接关闭时,会将连接资源放回数组,并对数量做加一操作。
*上述只是druid连接池的极简版流程叙述,实际上,还有连接池空等待、满通知、活跃数、异常数等的复杂判断。*有兴趣的同学可以看下源码。
zdal的连接池管理源码一览::
public class InternalManagedConnectionPool{
//最大连接数
private final int maxSize;
//用来存放连接的链表
private final ArrayList connectionListeners;
//内部的信号量,用来控制允许获取资源的线程总数
private final InternalSemaphore permits;
//正在使用的连接数
private volatile int maxUsedConnections = 0;
protected InternalManagedConnectionPool(...){
//构造函数中,初始化了连接池大小和信号量大小
connectionListeners = new ArrayList(this.maxSize);
permits = new InternalSemaphore(this.maxSize);
}
getConnection()方法:
//获取连接
public ConnectionListener getConnection(){
//信号量尝试获取许可
if (permits.tryAcquire(poolParams.blockingTimeout, TimeUnit.MILLISECONDS)) {
ConnectionListener cl = null;
do {
//加锁资源池
synchronized (connectionListeners) {
if (connectionListeners.size() > 0) {
//获取list的最后一个
cl = (ConnectionListener) connectionListeners.remove(connectionListeners.size() - 1);
//最大连接数 减去 正在工作的信号量
int size = (maxSize - permits.availablePermits());
if (size > maxUsedConnections){
maxUsedConnections = size;
}
}
}
if (cl != null) {
return cl;
}
}while(connectionListeners.size() > 0);
//OK, 在连接池中找不到正在工作的连接了. 那就创建个新的
createNewConnection(){...}
}else{
if (this.maxSize == this.maxUsedConnections) {
throw new ResourceException(
"数据源最大连接数已满,并且在超时时间范围内没有新的连接释放,poolName = "
+ poolName
+ " blocking timeout="
+ poolParams.blockingTimeout +
"(ms)");
}
}
这里把内部连接池的管理类的关键属性和连接获取方法流量进行了简化,连接归还就不弄了,大同小异,仔细看,我们看到了什么
volatile 标识的maxUsedConnections用来完成线程间数据可见
隶属于AQS系列的Semaphone,用来控制共享资源并发访问量。
都是些常见的八股文,不过组合起来可就了不得~
$ 话又又又说回来,在druid、zdal中,threadlocal的作用体现在哪里呢?
我们知道,诚如druid、zdal等优秀的中间件,可不止是数据库连接池这一个作用,阿里数据库中间件zdal源码解析 文中也有提及。
那么,ThreadLocal能在这里扮演什么角色呢?
就以zdal为例,因为阿里的数据库规模基本都非常大,但又有一套完备的数据库库表拆分规范,因此,分库键、分表键、主键、虚拟表名等在设计和存储时需要遵循规范,而zdal中的解析操作,也需要与之相匹配。
这个解析工作是相对复杂且繁重的,然而,针对同一用户的操作,通常库表的路由是相对固定的,因此,当我们解析过一次sql,通过各个字段和配置规则,计算出了库表路由,那么,可以直接put进线程上下文,供本次请求的后续数据库操作使用。
public Object parse(...){
SimpleCondition simpleCondition = new SimpleCondition();
simpleCondition.setVirtualTableName("user");
simpleCondition.put("age", 10);
ThreadLocalMap.put(ThreadLocalString.ROUTE_CONDITION, simpleCondition);
}
public void 后续操作(){
RouteCondition rc = (RouteCondition) ThreadLocalMap.get(ThreadLocalString.ROUTE_CONDITION);
if (rc != null) {
//不走解析SQL,由ThreadLocal传入的指定对象(RouteCondition),决定库表目的地
metaData = sqlDispatcher.getDBAndTables(rc);
} else {
// 通过解析SQL来分库分表
try {
metaData = sqlDispatcher.getDBAndTables(originalSql, parameters);
} catch (ZdalCheckedExcption e) {
throw new SQLException(e.getMessage());
}
}
}
这个也正好是对前面ThreadLocal正确使用方法的补充。
起因是对一篇文章叙述产生疑问,通过简单的验证,证实了自己的想法,然后又从几个方面对数据库连接和threadlocal进行了扩展,以上,大家如果发现有任何问题,欢迎留言帮忙指正和补充。


