【译】Maven 实现高可用性 (HA) 的 7 个小技巧转载
云计算已成为当今的一项新技术。如今,每家公司都是一家软件公司,而且想要提供更优质服务就离不开云计算。
云被视为 Internet 上的一个概念层,它使所有可用的软件和硬件资源透明化,使它们可以通过定义明确的界面进行访问。
由于公司越来越依赖这些云计算服务,为了在客户需要时始终保持稳定和可访问,自然就得避免服务和应用程序的一切停机时间。
在本文中,我们将讨论与高可用性 (HA) 相关的概念、它是什么、它是如何工作的,以及公司如何设计和使用它。
什么是高可用性 (HA)?
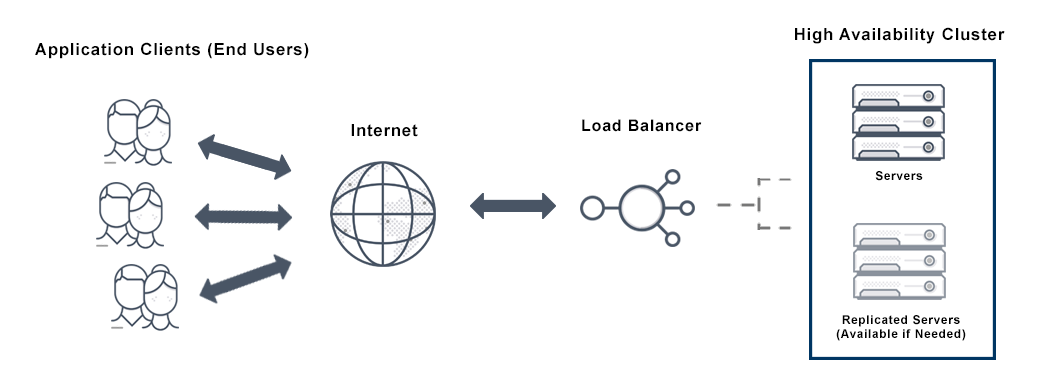
在衡量云计算可用性时,需要考虑几个因素 - 恢复时间、计划内和计划外维护期、意外负载、使用量增加等。因此,可用性作为一个整体表示为由服务级别定义的正常运行时间的百分比协议 (SLA)。HA体现了随时随地访问服务的理念。它可确保在给定时间段内保持高水平的运营性能,而不会出现任何中断或停机时间。
通常,高可用性系统通过使用更多组件来提供安全缓冲区,通过执行定期检查以确保每个组件正常工作,并在出现故障时将其替换为正常工作的组件来工作。
为什么选择高可用性 (HA)?
每家公司都喜欢 HA,仅仅是因为它使他们的服务在任何给定时间都可用且更可靠。可能会发生许多意外事件,并可能导致系统和服务器瘫痪。即使是高度稳健的系统也可能出现故障。因此,使用 HA 减少服务中断、中断和停机时间非常重要。高可用性系统可以自动恢复丢失并从服务器故障中恢复。从公司的业务角度来看,HA 变得太重要了。服务下降不是一件好事,客户会生气,这甚至可以让忠诚的客户找到替代方案并选择竞争对手的服务。今天的停机和中断意味着收入损失。这就是HA的重要性。
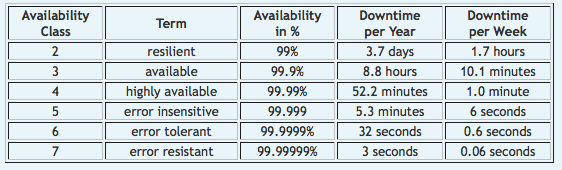
下表提供了基于相关停机时间的“可用性等级”(Zimory 提供)
高可用基础架构的特征
高度可用的基础架构具有以下列出的这些特征,
- 没有单点故障
- 硬件冗余
- 可靠的分频器
- 软件和应用程序冗余
- 数据冗余
- 自我监控失败
如何实现高可用?
1. 放大缩小
在公司中,高可用性是通过根据应用程序服务器的负载和可用性向上或向下扩展服务器来实现的。它主要在服务器级别的应用程序之外完成。
缩放在这里如何工作?
在缩放方面有两种类型。让我简单地描述一下。
-
水平扩展:这是通过在您的资源池中添加更多机器来实现的。
-
垂直扩展:这是通过向现有设备/机器添加更多功率(CPU、RAM)来实现的。
2.实现多个应用服务器
负担过重的服务器可能会崩溃并导致中断;建议在多台服务器上部署应用程序以保持应用程序始终运行。它创造了一种始终在运作的感觉。
3. 监控
一个集成良好的监控工具可以深入了解应用程序的性能及其当前功能;如果超过预定义的阈值,它还会监控错误率。例如,一个购物网站的工程团队可以监控支付网关,这样如果信用卡/借记卡交易的失败率超过 15%,团队就会自动收到关于自我修复任务的警报。
4.负载均衡
负载均衡器是充当反向代理并将应用程序流量分配到多个服务器的东西。这种方法用于增加应用程序的容量和可靠性。
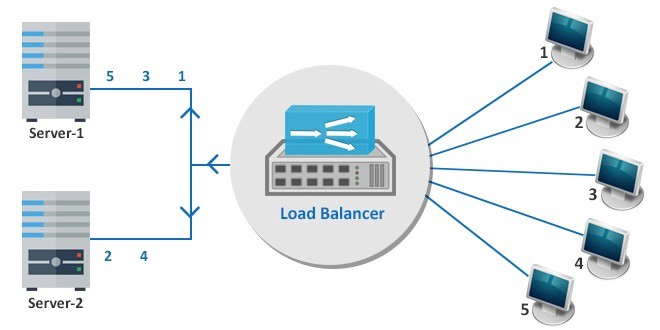
高可用性负载平衡 (HALB) 在阻止潜在的灾难性灾难和组件故障方面非常重要。使用主负载均衡器和辅助负载均衡器在您的数据中心之间自动分配工作负载。
负载平衡器和服务器中的这种冗余保证了近乎连续的应用程序交付。
5. 故障转移设置
在同一个位置,依赖多个元素会带来风险;即使是一台数据库服务器也会带来风险。如果该链上任何位置的任何组件发生故障,它就会让位于单点故障 (SPoF)。降低 SPoF 风险的一种方法是实施尽可能多的网络冗余。
如果正在运行自己的基础架构,则应考虑许多基础架构区域,以确保它们都具有良好的冗余设置。
6. 多区域部署
在云环境中,系统是按单元部署的,称为区域。一个区域可以定义为一个数据中心,或者它可能由一组相互靠近的数据中心组成。然后在区域内部出现了一个更细化的单元,称为可用区。因此,每个可用区都是一个区域内的单个数据中心。
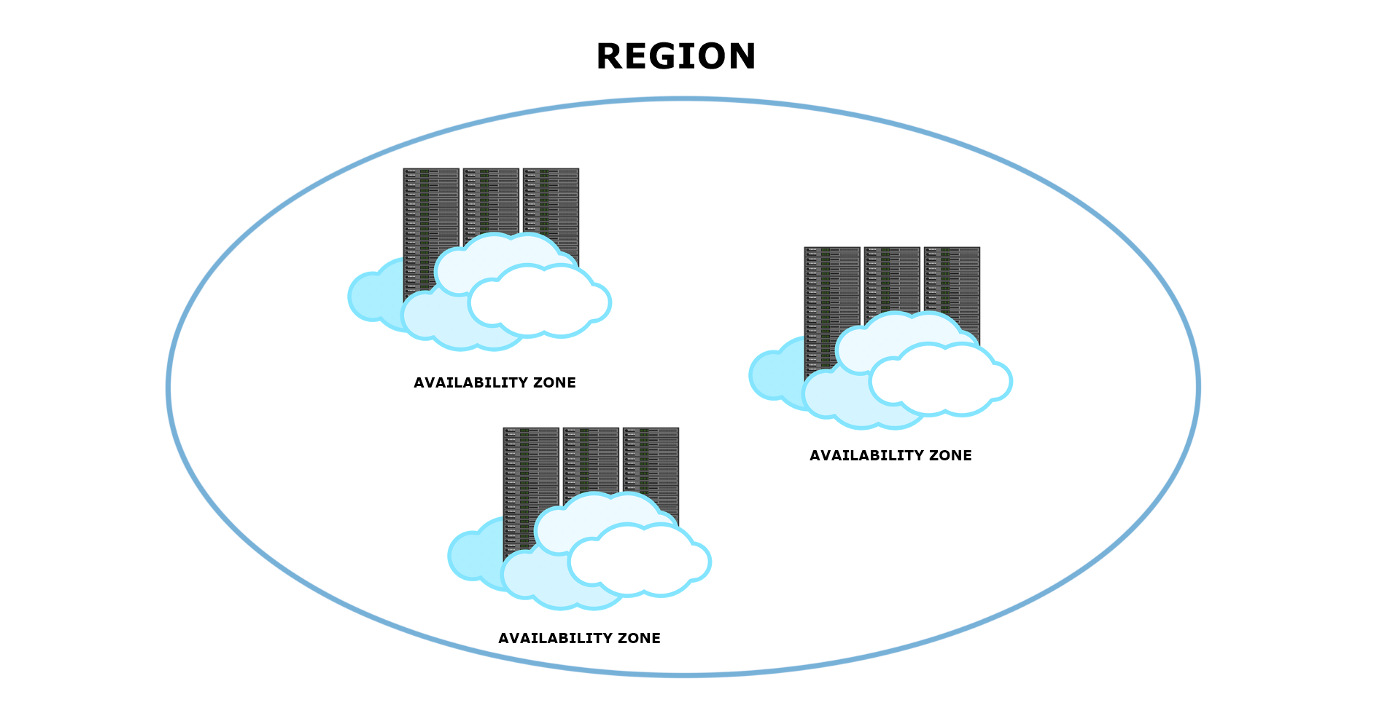
当系统部署在不同的区域和/或多个可用区中时,区域故障变得更加抵抗。它为架构增加了更多冗余。
7. 聚类技术
聚类技术通常用于改进和提高复杂系统的性能和可用性。集群通常被设计为提供相同功能和能力的一组冗余服务。
HA 集群或故障转移集群只不过是一个高度冗余的多服务器网络,可确保关键服务器应用程序全年 24/7 全天候运行。碰巧的是,在极少数情况下,如果高可用性集群中的一台服务器崩溃,那么在检测到漏洞的那一刻,任务关键型应用程序和服务就会立即在另一台服务器上重新启动。
注意:使用 Enterprise 许可证, 在同一局域网 (LAN) 上具有 2 个或更多活动/活动、读/写 Artifactory 服务器的集群的高可用性网络配置。这提供了业内无与伦比的稳定性和可用性。
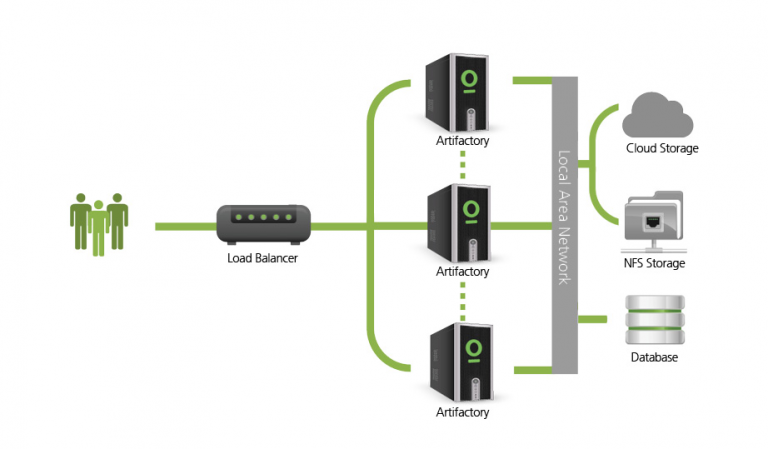
亚马逊的高可用性部署方法
持续交付失败通常会导致服务可用性降低和糟糕的客户体验,从而严重打击您的业务。为了实现零部署失败,亚马逊的开发团队已经针对端到端发布流程实施了一些策略。
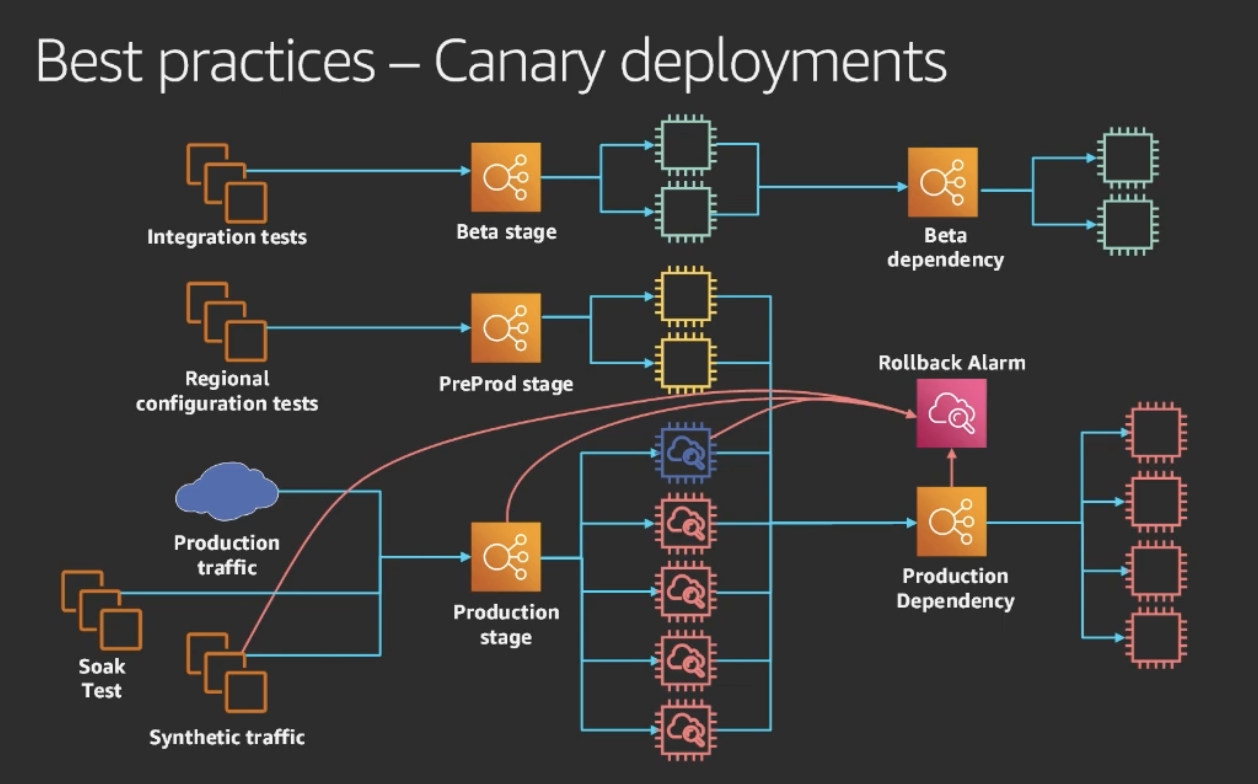
在这里列出亚马逊开发团队在处理高可用性部署时的经验教训,
-
集成测试:他们希望所有服务团队在他们的管道中实施集成测试。
-
预生产测试:预生产车队仅具有生产依赖项。这里的测试是为了确保他们即将推出的所有配置都正确配置。
-
Canary 部署:它是一种部署到生产队列的单个实例的类型。现在这里的实例慢慢地占用生产流量。金丝雀部署的目的是限制生产部署对生产队列的影响。
-
回滚警报:这用于警报客户的体验。
在此 视频中,你还可以了解有关 Amazon 发明的持续交付实践的更多信息,这些实践有助于提高标准并防止代价高昂的部署失败。
高可用性架构
让我们以 Artifactory 为例,看看 HA 架构的样子。
HA 架构由 3 个构建块组成:负载平衡器、应用程序和公共资源。
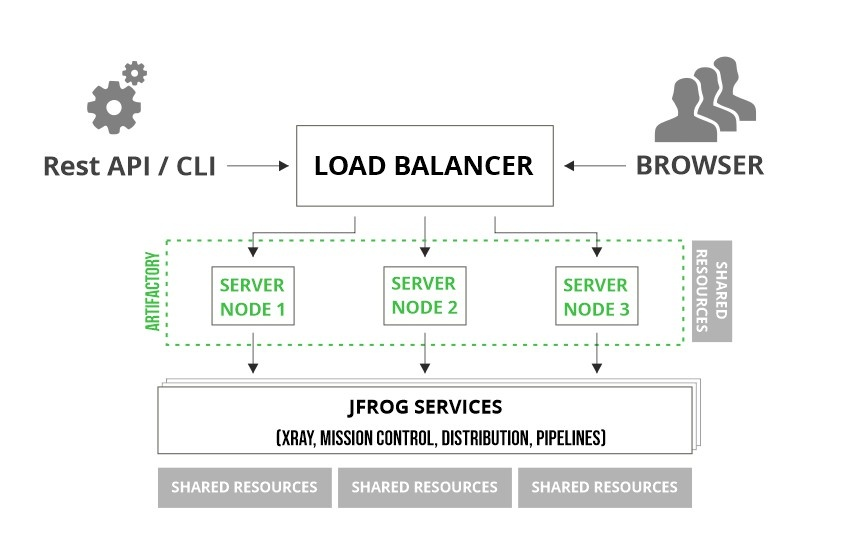
-
负载均衡器
负载均衡器是入口点,并以最佳方式将请求分发到系统中的节点。
-
应用
以 HA 模式运行的应用程序代表共享公共资源的两个或多个节点的集群。每个集群节点运行所有微服务。
-
公共资源
每个服务都需要一组公共资源。资源因服务而异,但通常至少包括一个数据库。
当谈到 Artifactory HA时,它被设计为可扩展的。Artifactory 允许你根据需要从最小的设置和规模开始,并且不会强制执行增长限制。如前所述,JFrog 提供一致的性能和出色的稳定性,从少量节点开始具有 HA。这还支持滚动升级。JFrog 可以通过 Splunk 的内置集成轻松监控集群内部发生的事情,因此拥有一个全面的生态系统对于适当的 HA 是必不可少的。
JFrog HA 适用于本地、NFS 或对象存储,包括实时故障转移和无中断生产升级。HA 模式也支持所有受支持的 Artifactory 包类型。
由于 Artifactory 支持在同一局域网上具有 2 个或更多活动/活动 Artifactory 服务器集群的高可用性配置。
这种冗余网络架构有几个好处:
- 没有单点故障
只要至少有一个 Artifactory 节点处于运行状态,您的系统就可以继续运行。这可以最大限度地延长您的正常运行时间,并将其提高到“五个九”的可用性水平。
- 适应更大的负载突发
借助水平服务器可扩展性,您可以在不影响性能的情况下增加容量,并满足随着组织发展而不断增加的负载需求。
- 多服务器架构
Artifactory HA 让您无需系统停机即可执行大多数维护任务。
任何公司的关键任务系统都应部署在高可用性配置中,以增强稳定性和可靠性。在高可用性配置中,不会出现任何单点故障。通过 HA 配置中的冗余节点高度维护冗余,因此系统继续无缝且不间断地运行。
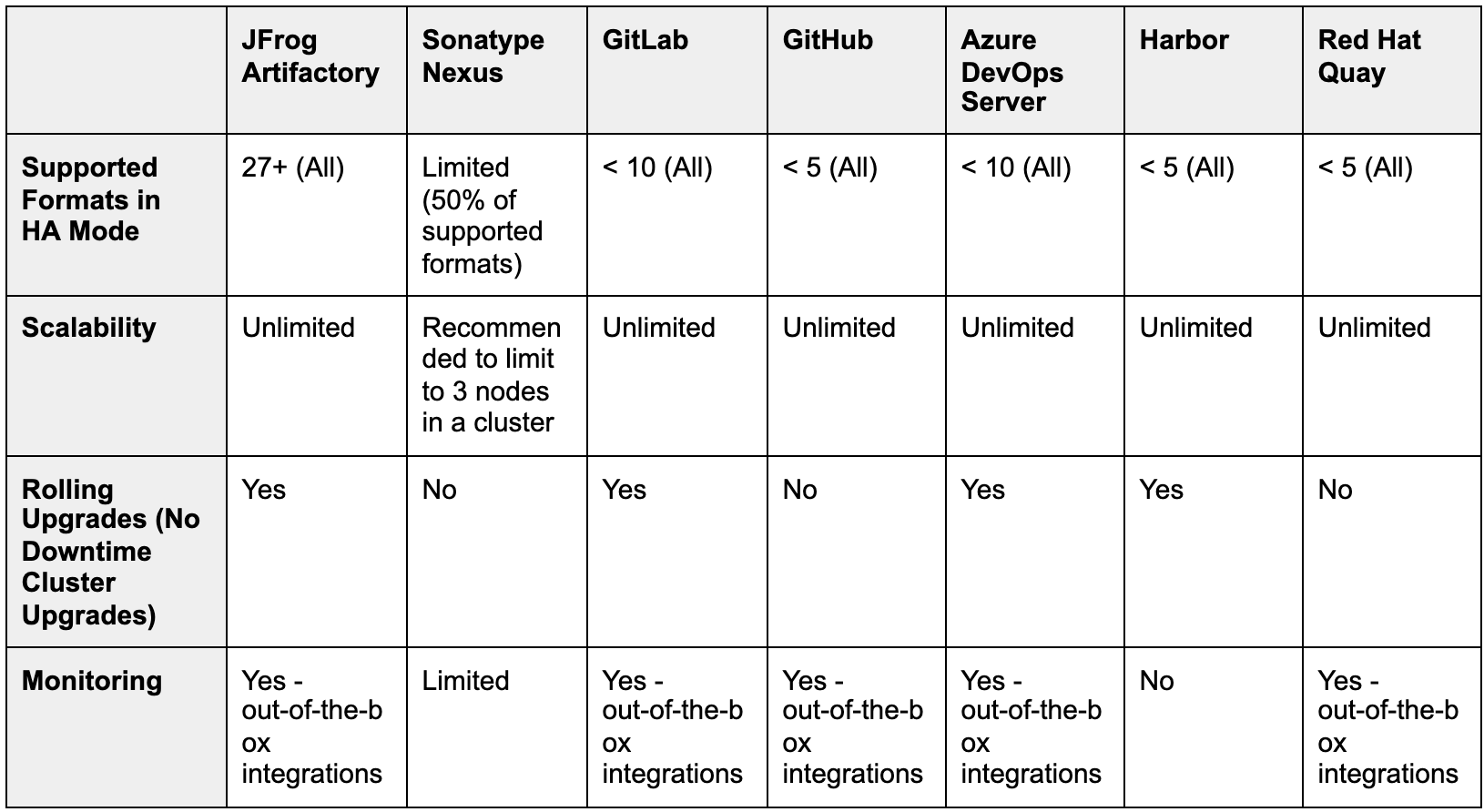
看看这个不同公司的 HA 比较图。