
高并发之存储篇:你必须要知道的索引原理和优化吧!原创
不管是啥业务,最终数据都要落地,数据库这一环是肯定少不了的。随着业务发展,并发越来越高,数据库很容易成为整个链路的短板。这也是大厂面试中比较常被问到的。而调优的第一步,都是从sql语句、索引入手。先得保证单个数据库执行没问题,才会有更高层次的分库分表、弹性、容灾等等。
Part1、为什么Kafka不需要我们关心索引,而Mysql却需要?
Kafka 和 MySQL 虽然最终数据都是落磁盘,但是两者在用途和数据查询方式上有着很大的差异,所以决定了数据的存储结构不同,进而决定了索引的复杂程度。
我们先看下kafka的存储结构:
由于 kafka 的定位是进行稳定的高性能数据读写。所以对磁盘来说,是采用顺序读写的方式,落在了一些 .log 文件中,并以基准偏移量补0命名。
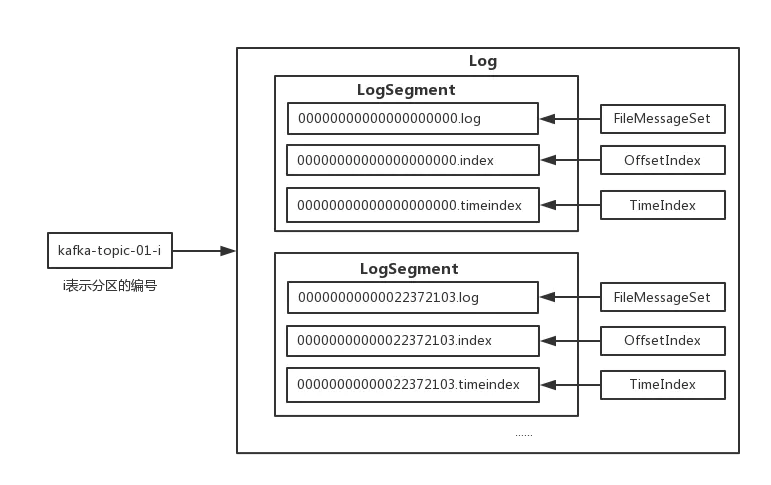
为了实现高速查找 kafka 创建了稀疏索引文件(隔一段数据创建一条,而非全量),即index文件。其中维护消息的 offset 和 .log文件的物理位置。通过二分查找快速定位log文件并顺序扫描找到目标。
所以,kafka的索引组织方式是相对简单、方案相对固定,但MySQL却不行。Mysql是关系型数据库,是为了支持复杂的业务数据查询而创建的,查询方式、数据获取需求多种多样,要求MySQL具备更加复杂的索引机制来加速复杂业务查询场景。
Part2、MySQL数据怎么被组织
以InnoDB存储引擎来看mysql数据存储:
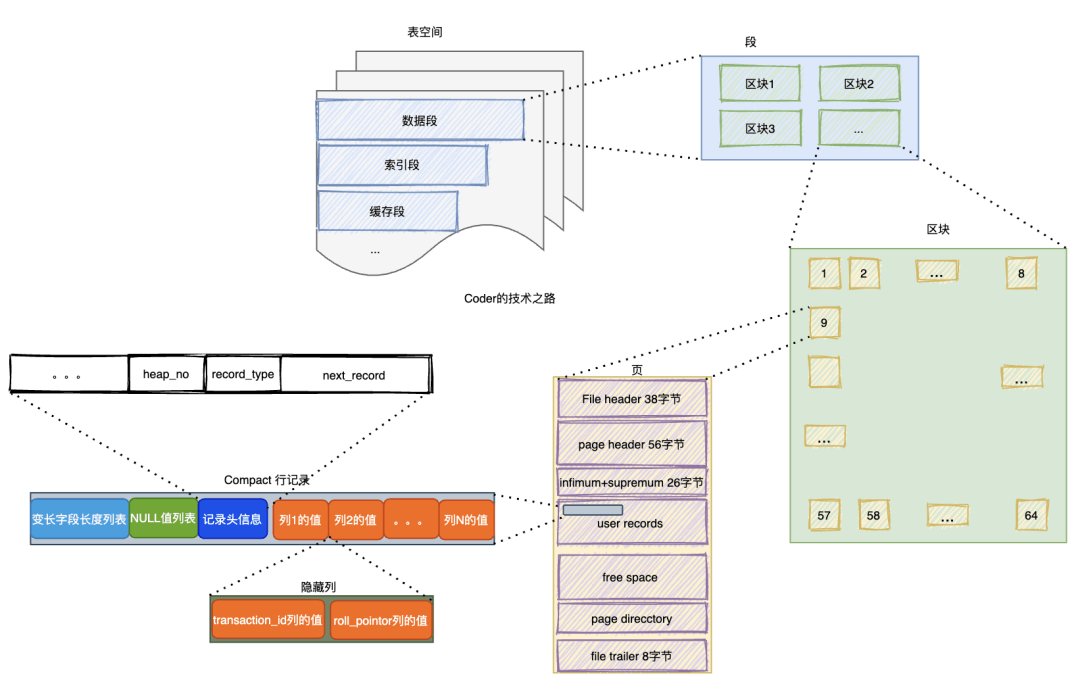
数据被分了多个逻辑层:行->页->区块->段->表空间。
我们知道,InnoDB存储引擎表是Index organized的(数据即索引,索引即数据),他们都维护在一个B+树上,数据段就是叶子节点,索引段就是非叶子节点;
而我们划分的段、区块 其实都是为了利用操作系统的资源(比如每次从磁盘加载到内存的数据大小按区块来约定等等`)来达到更高效读写的目的,逻辑划分的。
其中页是MySQL和磁盘交互的最小单位,怎么从页找到行,怎么聚合到块、到段再到空间呢。
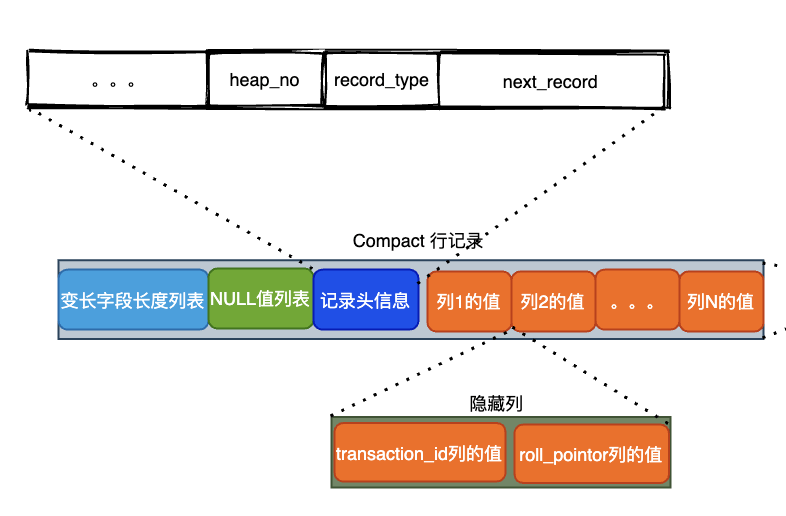
1、数据记录最小单位-- 行
从上面总图中摘出一条记录的结构如下图:图片我们可以看到,记录头中除了行号,还有下一条记录的标识next_record,所以,我们可以通过next_record将记录连接起来,以单向链表的形式,所以这就决定了,当我们在记录链中寻找某记录时,只能顺序遍历,这也决定了一条数据链不会太长。
但一个页默认是16K,加上行溢出等处理,一页最多存放7992行记录,这么多的记录,必须顺序遍历么?当然不需要,让我看看页是怎么组织记录行的。
2、与磁盘最小交互单位-- 页
作为与磁盘交互的最小单位,是用来存放实际数据的(页类型是b-tree Node存真实数据,还有其他类型如索引目录页等用来加速查询)从上面的大图中可以大致看到一个页的整体结构:
让我们来看几个关键的字段参数:
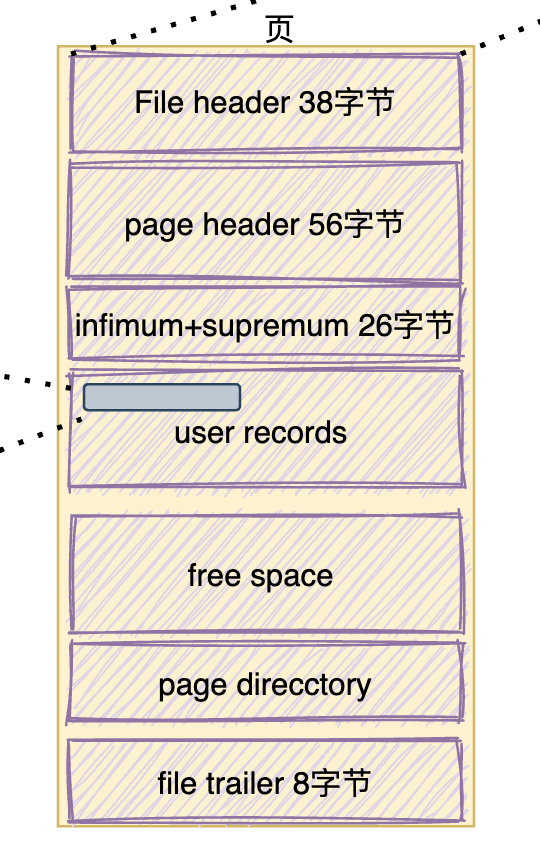
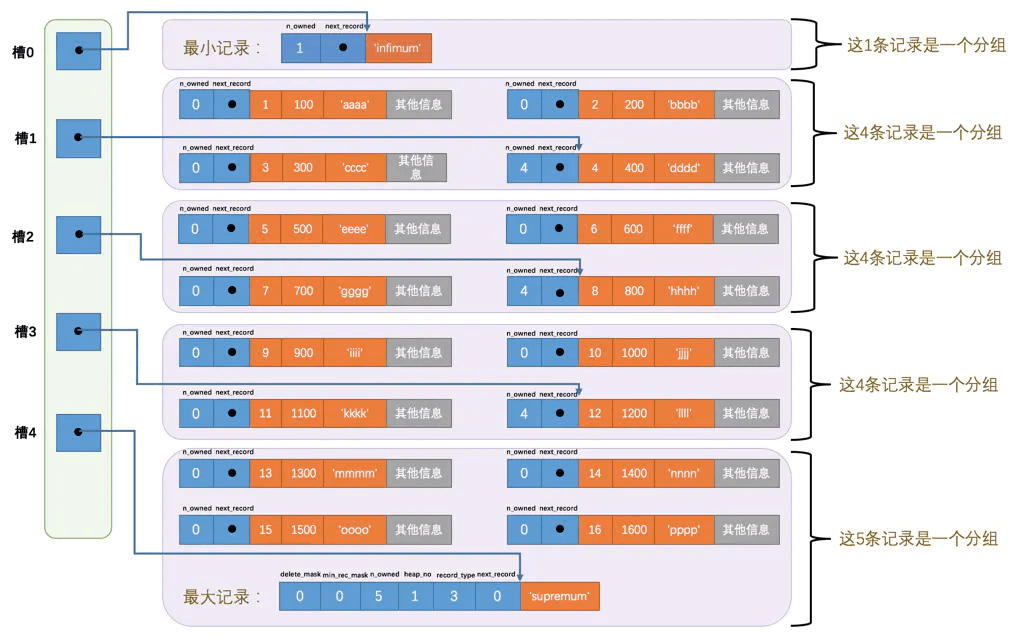
Page Directory 决定着记录项在页内的查询效率
为了更快速的查询,页目录存储的本页的数据目录(槽),包含最大最小记录和 分组数据链的最大记录的偏移量。方便使用二分法快速查找数据,不需要再从最小值开始遍历,如下图:
File Header决定页和页之间怎样关联
记录本页的一些通用信息,主要包含< 本页页号、上一页、下一页、页类型、所属表空间等等>。
通过页号来找到本页、通过上下页进行双向链表串联、通过类型判断是索引页还是数据页。。。
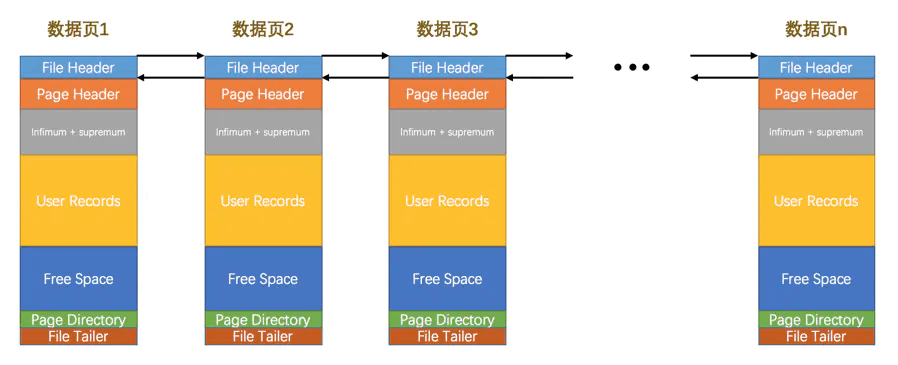
此字段决定了页和页之间可以很方便的通过上述属性进行关联。
Page Header决定页的层级
存储的本页的数据信息,主要包含**<** 本页记录数量、在B+树中的层级、归属的索引ID、插入方向、最大事务ID等等 >。
有了页面的数据组织概念,那么,怎么利用这些结构来实现的数据快速查询呢?
Part3、索引的演进思路
从上面的数据组织的知识里可以看到,行记录之间串联成单向链表,在每页中都按分组方式分布在此页的最小记录和最大记录之间。
页面之间通过上一页、下一页的指针,串联成双向链表,在磁盘中进行存储,如下图:
那么,要查询一条记录,可以怎么做?
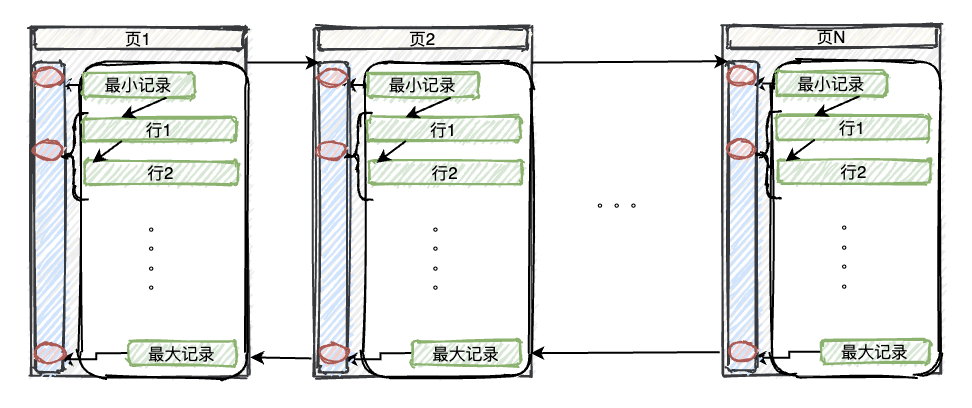
3、原始:顺序方式
如上图所示的数据串联方式,自然的提供了一种查询方式:即按主键顺序遍历每页和页中的记录行。
但是,这样的查询方式,除了在页内有二分优化,再无效率可言。怎么办?
寻求改进:既然页内的行记录可以分组入槽,那数据页之间为什么不行呢?
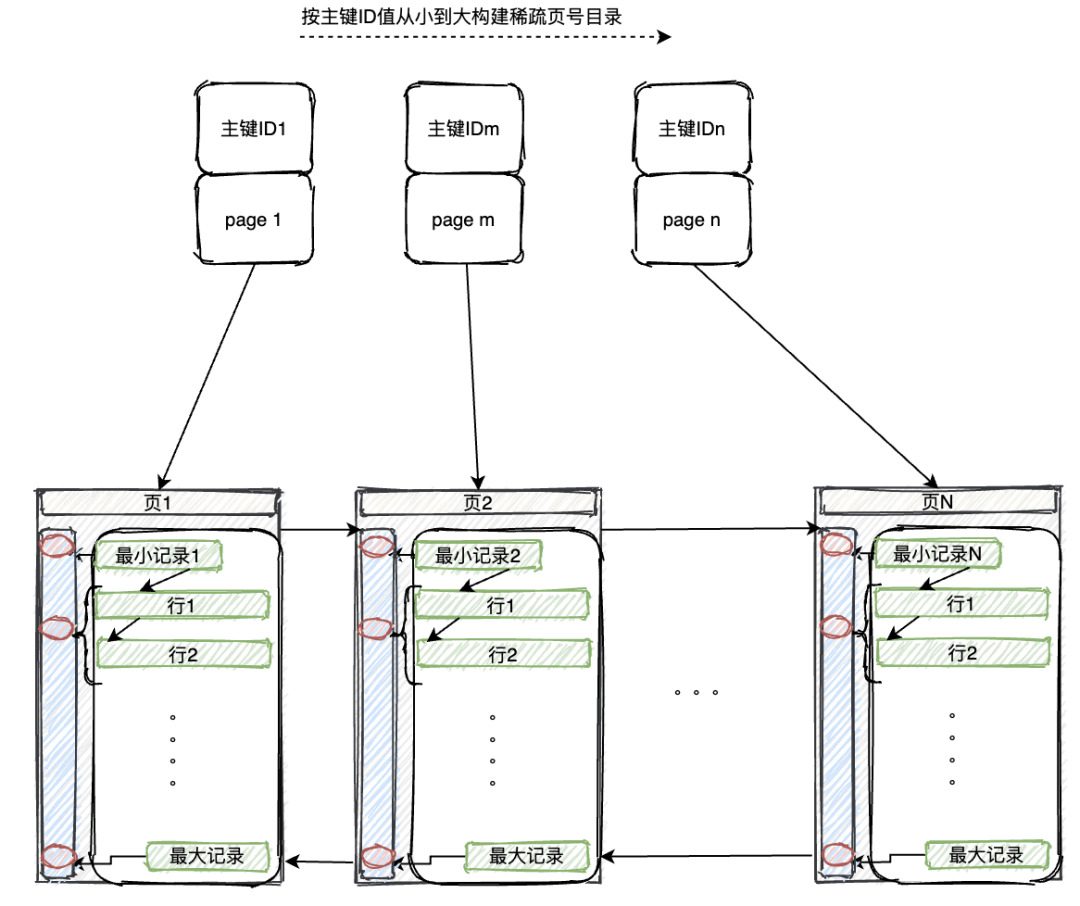
4、改进:目录方式
我们将页向上聚蔟,构建一个页号目录,先在目录中查找,再到对应页中查找,就比顺序查找要快很多了。图片
寻求改进:这样的方式所需大量连续空间 + 目录会随数据变动而频繁变动,怎么办?
5、演进:主键B+树方式
其实,在叙述行记录结构的时候,我们就看到,数据行的结构中,除了实际业务数据外,还有很多额外空间。
如record_type用来表示该记录的类型是数据还是索引。正是这些额外的空间的设计,给InnoDB以更加适合的方式组织索引提供了支持:
这就是一棵B+树,页节点有层级区分,页中的行记录有类型区分。
业务数据都包含在叶子节点中,目录数据都包含在其他非叶节点中。
这样组织方式的优势,是允许足够少的层级容纳足够多的数据项(可以简单的假设每一页的数据项大小来预估)。
而这个索引方式就是我们常说的聚蔟索引。即使用主键值进行记录和页的排序,且叶子节点含有全部用户数据。
寻求改进:如果我想用其他列来查询,怎么办?
6、扩展:二级索引、联合索引
二级索引
比如用户需要根据某一列(a列)的值来查询,那就再重新创建一个B+树。此索引树和聚蔟索引树的差别在于,索引节点是以a列的值为目录,且叶子节点只包含a列的值和主键两个值。
如果用户需要查询除c列以外的更多信息,则需要拿主键ID再去聚蔟索引查一次,也叫回表。
联合索引
二级索引是除主键外的单列索引,而联合索引则是多个列共同排序。假设用户需要用a 、b 两个列进行有序查询,那内在含义是,在a列值相同的情况下,再判断b的值。
同二级索引一样,InnoDB也需要再创建一棵B+树,且目录项的排序按先a,后b进行排序串联,叶子节点的数据项只包含 a 、b、主键三个值。
Part4、生产实践之触类旁通
7、美团定时任务索引优化
系统需要定时的捞取特定时间段内特定状态、特定类型、特定操作者的任务进行定时处理。
select * from task
where
status=x
and operator_id=xxxx
and operate_time>xxxxxxxx01
and operate_time<xxxxxxxx99
and type=x;
开发发现此sql运行的越来越慢,希望给每个字段加二级索引,被优化师叫停,而是考虑的该表所有查询方式后,创建了一个联合索引:
(status,operator_id,type,operate_time)
为什么不建多个的二级索引?为什么范围查询的字段要放在最后?
分析:
(1)从前面的原理部分我们知道,索引是要占内存的,不是越多越好,能起作用就行。
(2)用于范围匹配的字段的索引位置要严谨。因为创建索引的时候,根据索引字段的顺序来进行排序,如果把time字段放在type字段前面建索引,在查询时,因为time是一个范围值,那么多个time值延续到type字段,整体是无序的,无法用到type索引。
8、蚂蚁分布式主事务表的索引运用
蚂蚁的分布式事务中的主事务表起到了维护整体事务状态的作用,其中包含了整体事务状态、操作时间等字段。而在业务支付发生异常,且实时回滚失败时,需要事务恢复系统从远程捞取前1分钟的异常数据,并捞取对应的分支记录表发起异步回滚。
考虑查询效率,查询sql会限定业务发生时间在[前10分钟,前1分钟],是有范围查询,所以,针对其他字段,业务时间的索引顺序需要置于联合索引的最后。此操作的原理和上一部分美团定时任务的原理是一样的。
9、阿里开发手册中几条典型的规范
【强制】 在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。
原理关联:字段越长,索引占内存越多,只要其长度可以保证区分度即可
【强制】 字符搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
原理关联:左模糊的字段不是有序的,无法用到索引
【推荐】 如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。
原理关联:如果条件中有范围查询,则后续字段是无序的,order by时无法用到索引
【推荐】 建组合索引的时候,区分度最高的在最左边。
原理关联:区分度越高,查询路径越短,效率越高
等等,参见阿里Java开发手册
Part5、总结
本文从MySQL的存储结构、索引的设计思路演进、美团阿里大型系统索引使用等几个部分,阐述了索引的原理和对业务系统的重要作用。
当然,对于高并发下的数据库的优化远不止索引优化这一个方面,本文只从索引这一个点出发,让大家对其优化原理和优化方向


