
可观测性:如何使用 OpenTelemetry进行端到端的追踪转载
无论你是否用了微服务,系统都由多个组件组成,即使最简单的系统也可能由反向代理、应用程序和数据库组成。
所以监控就显得特别有必要。而且请求流经的组件数量越多,必要性就越高。
监控只是一个开始,想要让系统更稳定,我们需要在各种场景下都有方案,比如当请求开始集体失败时,你就需要一个跨所有组件的聚合视图。它就是追踪,和指标,日志成为可观察性的三大支柱。
在这篇文章中,我们关注追踪,并描述如何开始你的可观察性之旅。
W3C 跟踪上下文规范
跟踪解决方案应提供跨异构技术堆栈工作的标准格式。这种格式需要遵守规范,无论是理论还是实际应用中。
我们需要知道,规范很少会凭空出现。一般来说,市场已经有几个不同的实现。
而且,一个新的规范会导致一个额外的实现,正如著名的 XKCD 漫画所描述的:

然而,有时会发生奇迹:市场遵守新规范。在这里,Trace Context 是一个 W3C 规范,它似乎成功了:
“该规范定义了标准的 HTTP 标头和一种值格式来传播支持分布式跟踪场景的上下文信息。该规范标准化了上下文信息在服务之间的发送和修改方式。上下文信息唯一地标识了分布式系统中的各个请求,还定义了一种方法添加和传播提供者特定的上下文信息。”
文件中出现了两个关键概念:
- 追踪遵循跨越多个组件的请求的路径。
- 跨度绑定到单个组件并通过子父关系链接到另一个跨度。
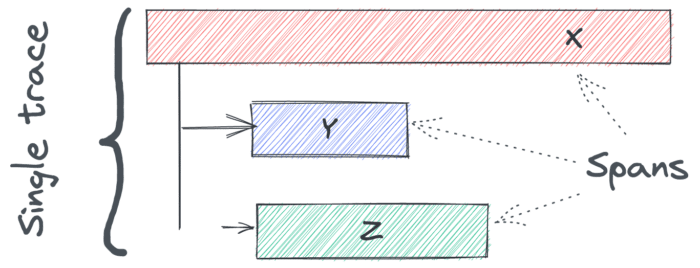
在撰写本文时,该规范是 W3C 推荐,这是最后阶段。
Trace Context 已经有很多实现。其中之一是 OpenTelemetry。
OpenTelemetry 作为黄金标准
你越接近程序的运维工作,听说OpenTelemetry的机会就越高:
“OpenTelemetry 是工具、API 和 SDK 的集合。使用它来检测、生成、收集和导出遥测数据(指标、日志和跟踪),以帮助您分析软件的性能和行为。OpenTelemetry 通常可用于多个语言,适合使用。”
OpenTelemetry 是一个由CNCF管理的项目。在 OpenTelemetry 之前有两个项目:
- OpenTracing,顾名思义就是专注于trace
- OpenCensus,其目标是管理指标和跟踪
两个项目合并并在顶部添加了日志。OpenTelemetry 现在提供了一组专注于可观察性的“层”:
- 多种语言的检测 API
- 规范的实现,同样用不同的语言
- 基础设施组件,例如收集器
- 互操作性格式,例如 W3C 的 Trace Context
请注意,虽然 OpenTelemetry 是一个 Trace Context 实现,但它的功能更多。Trace Context 将自身限制为 HTTP,而 OpenTelemetry 允许 span 跨非 Web 组件,例如 Kafka。它超出了这篇博文的范围。
来个用例
我最喜欢的用例是电商场景,所以我们不要更改它。在这种情况下,商店是围绕微服务设计的,每个微服务都可以通过 REST API 访问,并受到 API 网关的保护。为了简化博客文章的架构,我将只使用两个微服务:catalog管理产品和pricing处理产品价格。
当用户到达应用程序时,主页会获取所有产品,获取它们各自的价格并显示它们。
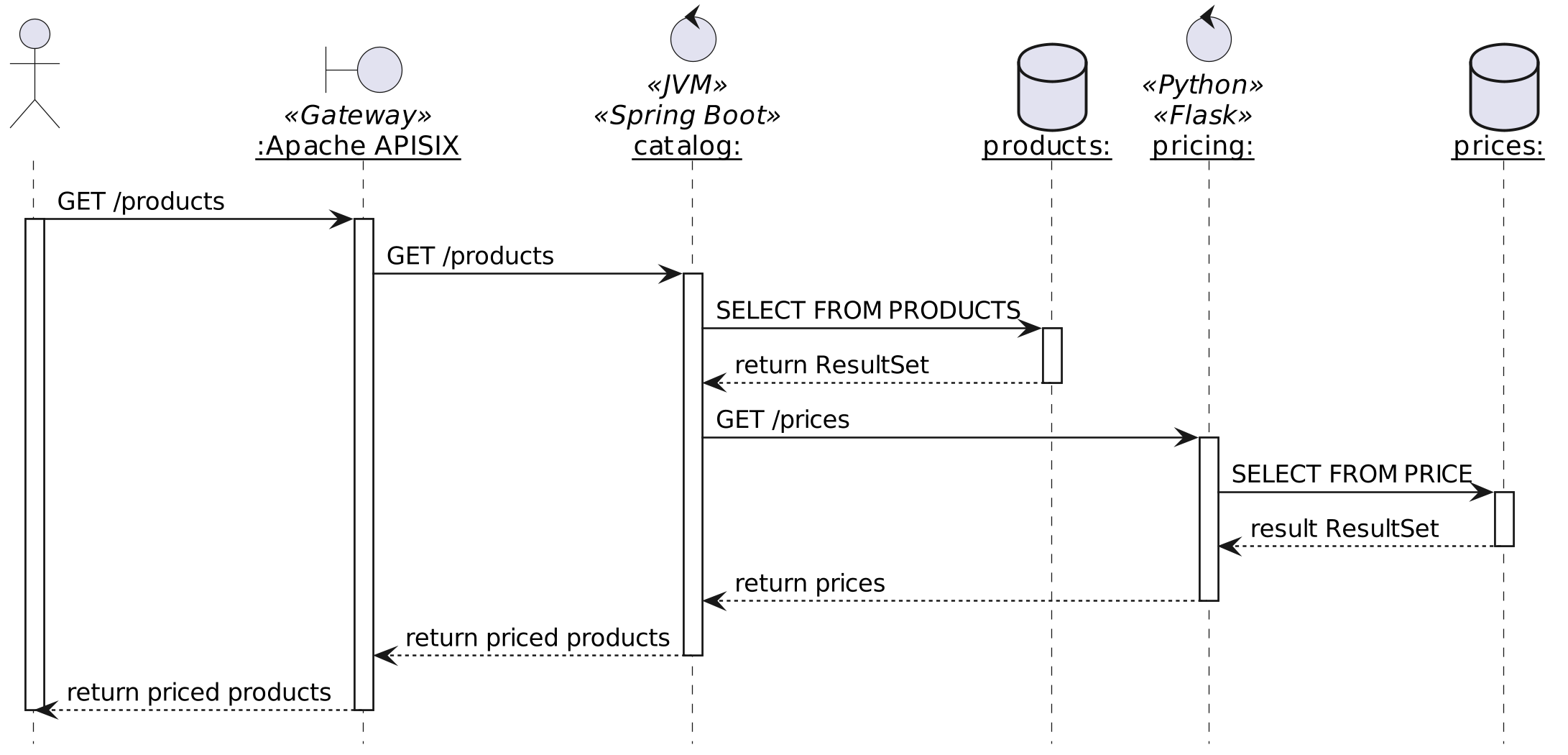
更有趣的是,catalog是一个用 Kotlin 编码的 Spring Boot 应用程序,而pricing一个 Python Flask 应用程序。
跟踪应该允许我们通过网关跟踪请求的路径,包括微服务和(如果可能的话)数据库。
网关处的痕迹
入口点是跟踪中最令人兴奋的部分,因为它应该生成跟踪 ID。在这种情况下,入口点是网关。我将用Apache APISIX来演示:
“Apache APISIX 提供了丰富的流量管理功能,如负载均衡、动态上游、金丝雀发布、断路器、身份验证、可观察性等。”
Apache APISIX 基于插件架构并提供OpenTelemetry 插件:
“该
opentelemetry插件可用于根据 OpenTelemetry 规范报告跟踪数据。
该插件仅支持基于 HTTP 的二进制编码 OLTP。”
让我们配置opentelemetry插件:
apisix:
enable_admin: false #1
config_center: yaml #1
plugins:
- opentelemetry #2
plugin_attr:
opentelemetry:
resource:
service.name: APISIX #3
collector:
address: jaeger:4318 #4#1:在独立模式下运行 Apache APISIX 以使演示更易于理解。无论如何,这在生产中是一个很好的做法。
#2:配置opentelemetry为全局插件。
#3:设置服务的名称。它将出现在跟踪显示组件中的名称。
#4:将跟踪发送到jaeger服务。以下部分将对其进行描述。
我们想跟踪每条路由,所以我们应该将插件设置为全局插件,而不是向每条路由添加插件:
global_rules:
- id: 1
plugins:
opentelemetry:
sampler:
name: always_on #1#1:跟踪对性能有影响。我们追踪的越多,我们的影响就越大。因此,我们应该仔细平衡性能影响与可观察性的好处。但是,对于演示,我们希望跟踪每个请求。
收集、存储和显示的轨迹
虽然 Trace Context 是 W3C 规范,而 OpenTelemetry 是事实上的标准,但市场上存在许多收集、存储和显示跟踪的解决方案。每个解决方案都可以提供所有三种功能或仅提供其中的一部分。例如,Elastic 堆栈处理存储和显示,但您必须依靠其他东西来收集。另一方面,Jaeger和Zipkin确实提供了一个完整的套件来实现所有三个功能。
Jaeger 和 Zipkin 早于 OpenTelemetry,因此每个都有其跟踪传输格式。不过,它们确实提供了与 OpenTelemetry 格式的集成。
在这篇博文的范围内,确切的解决方案并不相关,因为我们只需要功能。我选择 Jaeger 是因为它提供了一个一体化的 Docker 镜像:每个功能都有其组件,但它们都嵌入在同一个镜像中,这使得配置更加轻松。
镜像的相关端口如下:
| PORT | 协议 | COMPONENT | 功能 |
|---|---|---|---|
16686 |
HTTP | query | 服务前端 |
4317 |
HTTP | collector | 接受通过 gRPC 的 OpenTelemetry 协议 (OTLP)(如果启用) |
4318 |
HTTP | collector | 接受通过 HTTP 的 OpenTelemetry 协议 (OTLP)(如果启用) |
Docker Compose 位如下所示:
services:
jaeger:
image: jaegertracing/all-in-one:1.37 #1
environment:
- COLLECTOR_OTLP_ENABLED=true #2
ports:
- "16686:16686" #3#1:使用all-in-one图像。
#2:非常重要:启用 OpenTelemetry 格式的收集器。
#3:暴露 UI 端口。
现在我们已经建立了基础设施,我们可以专注于在我们的应用程序中启用跟踪。
Flask 应用程序中的追踪
该pricing服务是一个简单的Flask应用程序。它提供了一个端点来从数据库中获取单个产品的价格。
@app.route('/price/<product_str>') #1-2
def price(product_str: str) -> Dict[str, object]:
product_id = int(product_str)
price: Price = Price.query.get(product_id) #3
if price is None:
return jsonify({'error': 'Product not found'}), 404
else:
low: float = price.value - price.jitter #4
high: float = price.value + price.jitter #4
return {
'product_id': product_id,
'price': round(uniform(low, high), 2) #4
}#1:端点
#2:路线需要产品的ID。
#3:使用 SQLAlchemy 从数据库中获取数据。
#4:真实定价引擎永远不会随着时间的推移返回相同的价格。让我们将价格随机化一点以取乐。
警告:每次调用获取单一价格是非常低效的。它需要与产品一样多的调用,但它提供了更令人兴奋的跟踪。在现实生活中,路由应该能够接受多个产品 ID 并在一个请求-响应中获取所有相关价格。
现在是检测应用程序的时候了。有两种选择:自动仪表和手动仪表。自动是省力和快速的胜利;手册需要专注的开发时间。我建议从自动开始,如果需要,只添加手动。
我们需要添加几个 Python 包:
opentelemetry-distro[otlp]==0.33b0
opentelemetry-instrumentation
opentelemetry-instrumentation-flask
我们需要配置几个参数:
pricing:
build: ./pricing
environment:
OTEL_EXPORTER_OTLP_ENDPOINT: http://jaeger:4317 #1
OTEL_RESOURCE_ATTRIBUTES: service.name=pricing #2
OTEL_METRICS_EXPORTER: none #3
OTEL_LOGS_EXPORTER: none #3#1:将跟踪发送给 Jaeger。
#2:设置服务的名称。它将出现在跟踪显示组件中的名称。
#3:我们对日志和指标都不感兴趣。
现在,我们不使用标准flask run命令,而是将其包装:
opentelemetry-instrument flask run就这样,我们已经从方法调用和 Flask 路由中收集了 span。
如果需要,我们可以手动添加额外的跨度,例如. :
from opentelemetry import trace
@app.route('/price/<product_str>')
def price(product_str: str) -> Dict[str, object]:
product_id = int(product_str)
with tracer.start_as_current_span("SELECT * FROM PRICE WHERE ID=:id", attributes={":id": product_id}) as span: #1
price: Price = Price.query.get(product_id)
# ...#1:使用配置的标签和属性添加一个额外的跨度。
Spring Boot 应用程序中的追踪
该服务是用Kotlin 开发catalog的 Reactive Spring Boot应用程序。它提供了两个端点:
- 一取单品
- 另一种是获取所有产品。
两者都先查看产品数据库,然后查询上述pricing服务的价格。
至于 Python,我们可以利用自动和手动检测。让我们从唾手可得的自动化仪表开始。在 JVM 上,我们通过一个代理来实现:
java -javaagent:opentelemetry-javaagent.jar -jar catalog.jar与 Python 一样,它为每个方法调用和 HTTP 入口点创建跨度。它还检测 JDBC 调用,但我们有一个反应式堆栈,因此使用 R2DBC。作为记录,GitHub 问题已开放以添加支持。
我们需要配置默认行为:
catalog:
build: ./catalog
environment:
APP_PRICING_ENDPOINT: http://pricing:5000/price
OTEL_EXPORTER_OTLP_ENDPOINT: http://jaeger:4317 #1
OTEL_RESOURCE_ATTRIBUTES: service.name=orders #2
OTEL_METRICS_EXPORTER: none #3
OTEL_LOGS_EXPORTER: none #3#1:将跟踪发送给 Jaeger。
#2:设置服务的名称。它将出现在跟踪显示组件中的名称。
#3:我们对日志和指标都不感兴趣。
至于 Python,我们可以通过添加手动检测来提升游戏。有两个选项可用:程序化和基于注释。除非我们引入 Spring Cloud Sleuth,否则前者有点复杂。让我们添加注释。
我们需要一个额外的依赖:
<dependency>
<groupId>io.opentelemetry.instrumentation</groupId>
<artifactId>opentelemetry-instrumentation-annotations</artifactId>
<version>1.17.0-alpha</version>
</dependency>请注意:该工件是最近从io.opentelemetry:opentelemetry-extension-annotations.
我们现在可以注释我们的代码:
@WithSpan("ProductHandler.fetch") //1
suspend fun fetch(@SpanAttribute("id") id: Long): Result<Product> { //2
val product = repository.findById(id)
return if (product == null) Result.failure(IllegalArgumentException("Product $id not found"))
else Result.success(product)
}#1:使用配置的标签添加一个额外的跨度。
#2:将参数用作属性,键设置为id,值设置为参数的运行时值。
结果
我们现在可以使用我们的简单演示来查看结果:
curl localhost:9080/products
curl localhost:9080/products/1响应并不有趣,但让我们看看 Jaeger UI。我们找到了两条踪迹,每次调用一条:

我们可以深入研究单个跟踪的跨度:
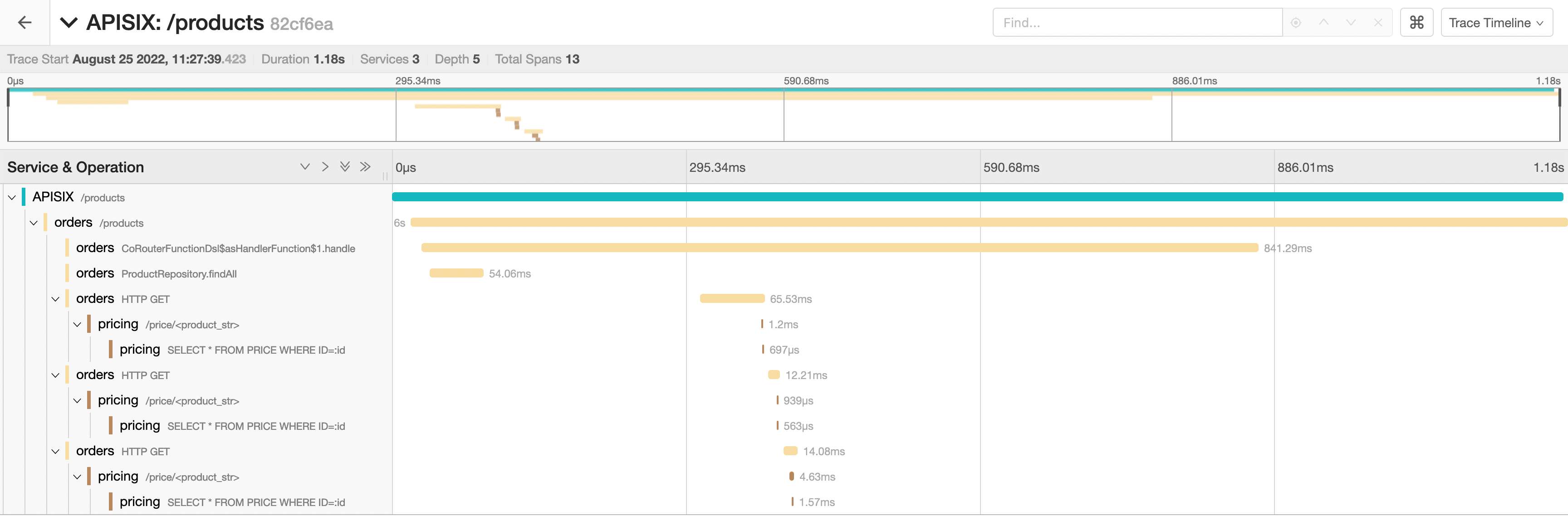
请注意,我们可以在没有上述 UML 图的情况下推断出序列流。更好的是,序列显示组件内部的调用。
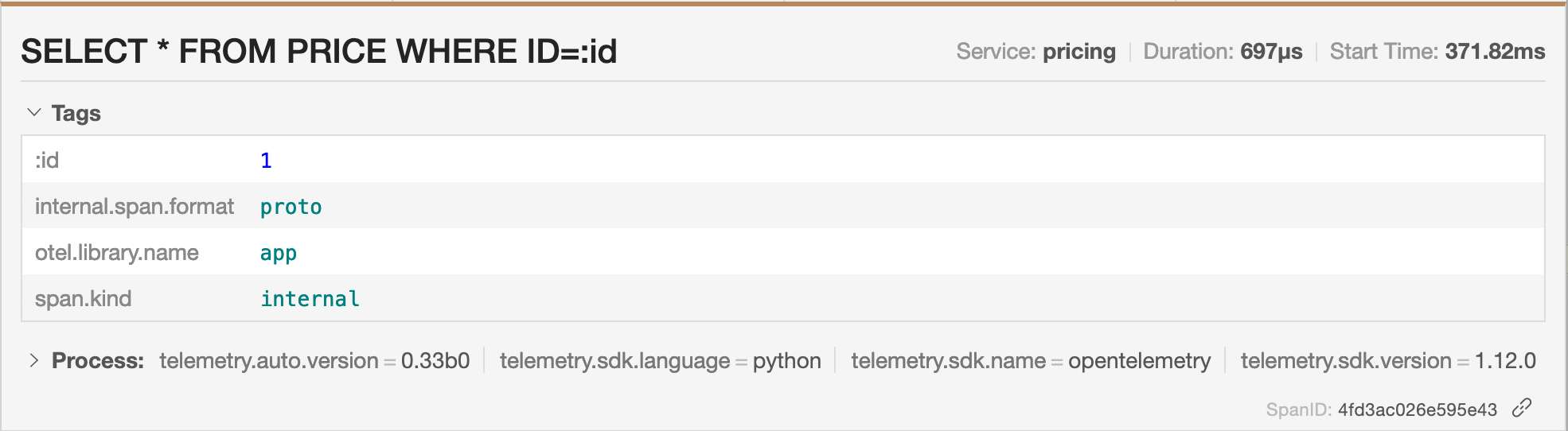
每个跨度都包含自动检测添加的属性和我们手动添加的属性:
结论
在这篇文章中,我们展示了跟踪跨 API 网关的请求、基于不同技术堆栈的两个应用程序以及它们各自的数据库。这里只介绍了追踪的表层:在现实世界中,跟踪可能会涉及与 HTTP 无关的组件,例如 Kafka 和消息队列。
尽管如此,大多数系统还是以一种或另一种方式依赖 HTTP。虽然设置起来比较麻烦,但也不难。
反正,跨组件跟踪 HTTP 请求肯定是你实现系统可观察性之旅的开端第一步。
这篇文章的完整源代码可以在 GitHub 上找到。


