
【译】比较低延迟消息队列中的持久性方法转载
Chronicle Queue Enterprise 的一个重要特性是支持跨多个服务器的 TCP 复制,以确保应用程序基础架构的高可用性。我通常认为将数据复制到辅助系统比同步到磁盘要快,假设往返网络延迟不高,因为高质量的网络和位于同一位置的冗余服务器。这是我第一次用一个现实的例子对它进行基准测试。
利特尔定律和为什么延迟很重要
在许多情况下,假设只要吞吐量足够高, 延迟就不会成为问题。但是,延迟通常是导致吞吐量不够高的关键因素。
利特尔定律指出,“固定系统中客户的长期平均数量L等于长期平均有效到达率λ乘以客户在系统中花费的平均时间W。 ”
在计算机术语中,系统必须支持的并发或 并行级别必须至少是平均吞吐量乘以平均延迟。
为了达到给定的吞吐量,并发级别会随着延迟而增加。为了实现这种并发性,这通常也会增加复杂性和风险级别。许多系统具有很高的内在并行性;但是金融系统通常不会,这限制了理论上可以实现多少并发。更多的活动部件也会增加失败的风险。
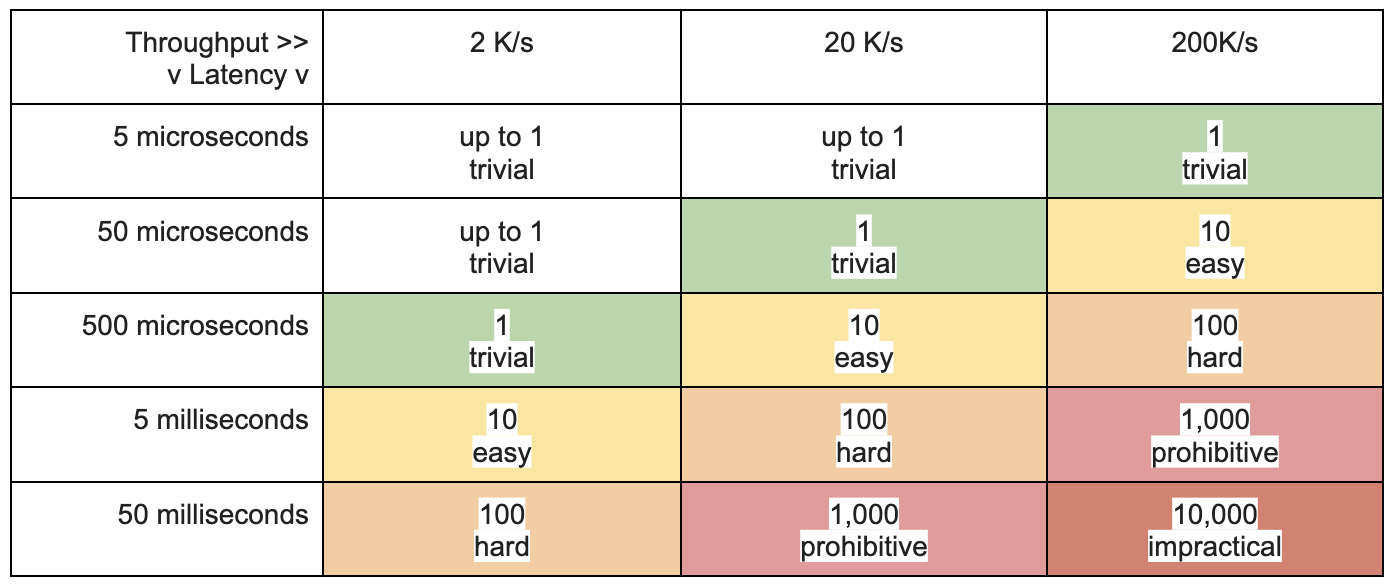
表 1. 实现给定吞吐量和延迟所需的并发/并行级别。
两全其美
虽然同步到磁盘通常被视为对消息持久性的要求,但它会在性能方面付出代价,直接增加延迟但间接降低吞吐量。确认复制提供了类似的保证并且(剧透警报)更快。
但是,有时您可能会收到诸如订单、交易或付款之类的消息,这些消息太大而不会有损失的风险。
权衡是使用确认复制,但在达到某些业务风险阈值时同步到磁盘,无论是在单个消息中还是在消息聚合中。在此测试中,我探讨了每秒仅同步 10 次可能产生的差异。
平衡技术和商业风险
许多 IT 系统倾向于将技术风险与商业风险分开处理。例如,Kafka 可以选择定期将数据同步到磁盘,比如每 100 毫秒。这与这些消息的内容或价值无关。不幸的是,您不知道当时可能丢失的消息的价值 。
但是,您可以通过使技术解决方案与商业风险保持一致来获得更好的结果。例如,使用 Chronicle 堆栈,您可以根据内容同步到磁盘。单独的大订单或付款或大量累计付款可以触发同步。您可以设置 1000 万美元的上限(您也可以按时间设置上限),而不是 100 毫秒的未知价值上限。
Chronicle Queue 有多种触发同步的方式;然而,最简单的方法是在ExcerptAppender上调用sync()以同步所有内容,直到写入的最后一条消息。在 Chronicle Services 中,编写一个 sync()事件会触发底层队列的同步,并记录它的执行时间。如果下游服务需要知道已执行同步,则可以等待此事件。
低延迟与耐用性要求
低延迟系统“对速度的需求”通常胜过对可靠性的需求,因此通常会选择可用的最快选项。消息通常保持尽可能小。例如,40 – 256 字节。
然而,许多金融系统具有更高的耐用性,但对延迟速度的要求更低。消息大小通常也更大,例如 1 – 8 KB。

基础场景
许多系统支持定期刷新或同步到磁盘;但是,这不是基于消息的内容。使用 Chronicle,您可以选择必须同步到磁盘的重要消息。您可以进行几个编程调用来触发或等待基于消息内容的同步。假设我们的应用程序有一小部分消息必须根据业务需求同步到磁盘,我们只能在写入这些消息时进行同步。
在这个基准测试中,(1) 客户端通过 TCP 向服务器发布 1 KB 消息,(2) 服务器将数据写入磁盘上的 Chronicle Queue,或者使用异步作为 msync(MS_ASYNC),同步作为 msync(MS_SYNC) ,或基于模拟的业务风险同步 10 次/秒,您的用例会有所不同,(3) 数据通过 TCP 复制到第二个服务器,(4) 数据得到确认,(5) 在副本上的数据也在操作系统的控制下通过异步刷新写入磁盘,(6)在第 2 步和第 4 步之后,将提交消息发送回客户端。
每个案例都使用快速机器(Ryzen 9 5950X)和低延迟网络。操作系统针对隔离进行了调整以减少延迟。但是,没有添加额外的优化。较慢的机器、磁盘子系统和网络延迟将增加下面的时间。没有进行调整来优化同步的执行方式。
小消息的低延迟选项
减少延迟的一个简单方法是减少工作量。低延迟系统倾向于使用 256 字节左右的较小消息;如果我们不需要强大的弹性保证,我们可以获得什么延迟?在每种情况下,都使用相同的配置。不同之处在于哪些点是计时的。此图表说明了如果您考虑以下因素可以获得的性能:
- 仅发布时间;这是您可以做的最低限度。它所做的只是将数据写入缓冲区,以便可以异步写入网络。数据甚至没有达到上图中的第 1 步。
- 是时候等待来自服务器 1 的响应而没有来自第二个服务器的确认。这将执行步骤 1、2 和 6。
- 确认后等待服务器 1 响应的时间;这与之前的步骤 1、2、3、4 和 6 相同。
下图显示了来自同一次运行的数据,不同的线代表我们测量时间的点,以显示如果您等待不同的持久性阶段所产生的差异。
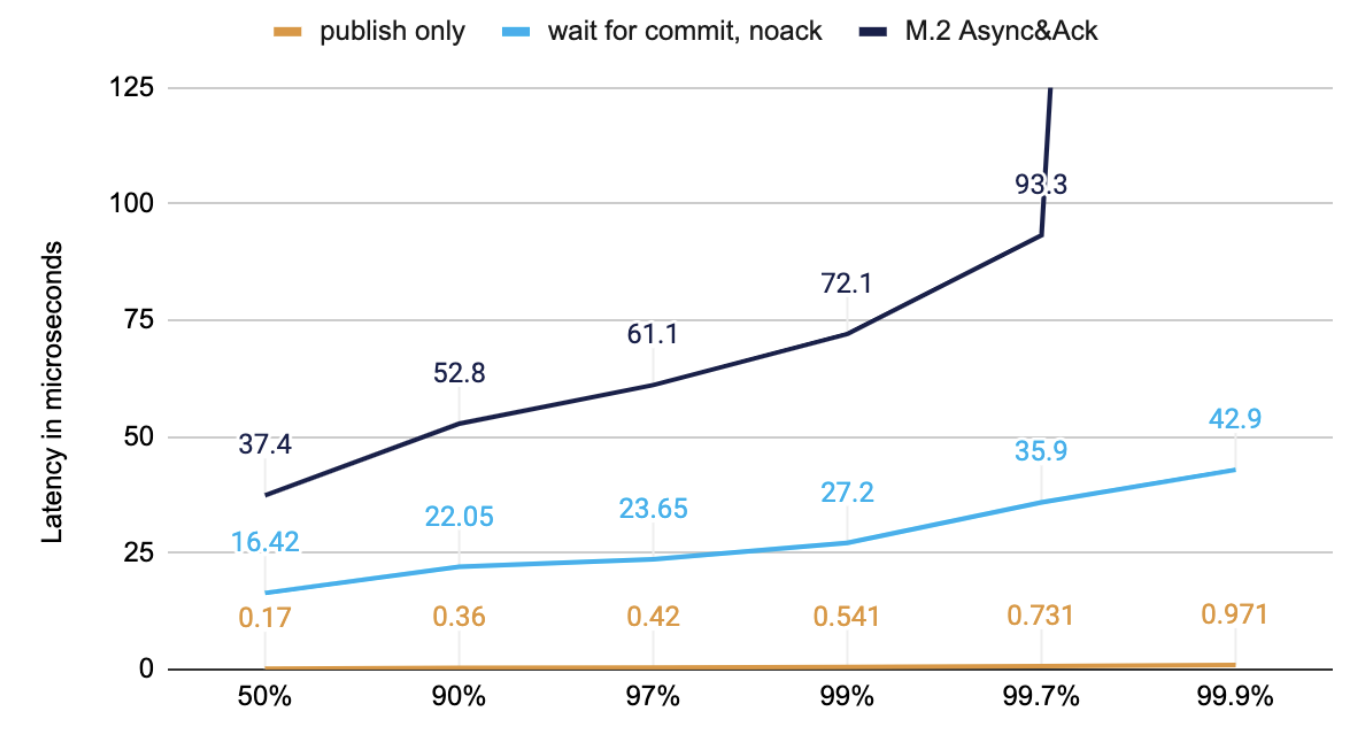
图 1. M.2 200K/s 256 Bytes 消息在不同阶段的定时
虽然这些测试受益于较小的消息(比较下面最后一张图表中的“M.2 Async&Ack”),但主要的速度改进不是等待同一阶段的持久性。
您可以在队列级别、按消息类型甚至基于消息的内容自定义系统的行为方式,以使技术风险与商业风险保持一致。
等待复制确认或同步到磁盘
对于当前需要同步到磁盘的系统,如果替代方案是等待确认复制,则可能会显着改善延迟。在这种情况下,延迟与“Async&Ack”选项(加上网络往返时间)相同,当副本不可用时(或故障转移到辅助系统后)回退到“Sync&Ack”延迟
带有中等大小消息的 SATA 固态驱动器
上面,我们比较了不同阶段的相同配置。在这种情况下,端到端是定时的,有不同的选项用于同步到磁盘。
在需要更高保证的用例中,消息通常更大。在这个测试中,1 KB 的 50K/s 消息从在客户端发布到接收来自“服务器 1”的已提交消息是计时的。“SYNC 10/s”假设平均每秒需要 10 次 SYNC。这可以基于消息的内容,例如大订单或付款,而不仅仅是周期性的。
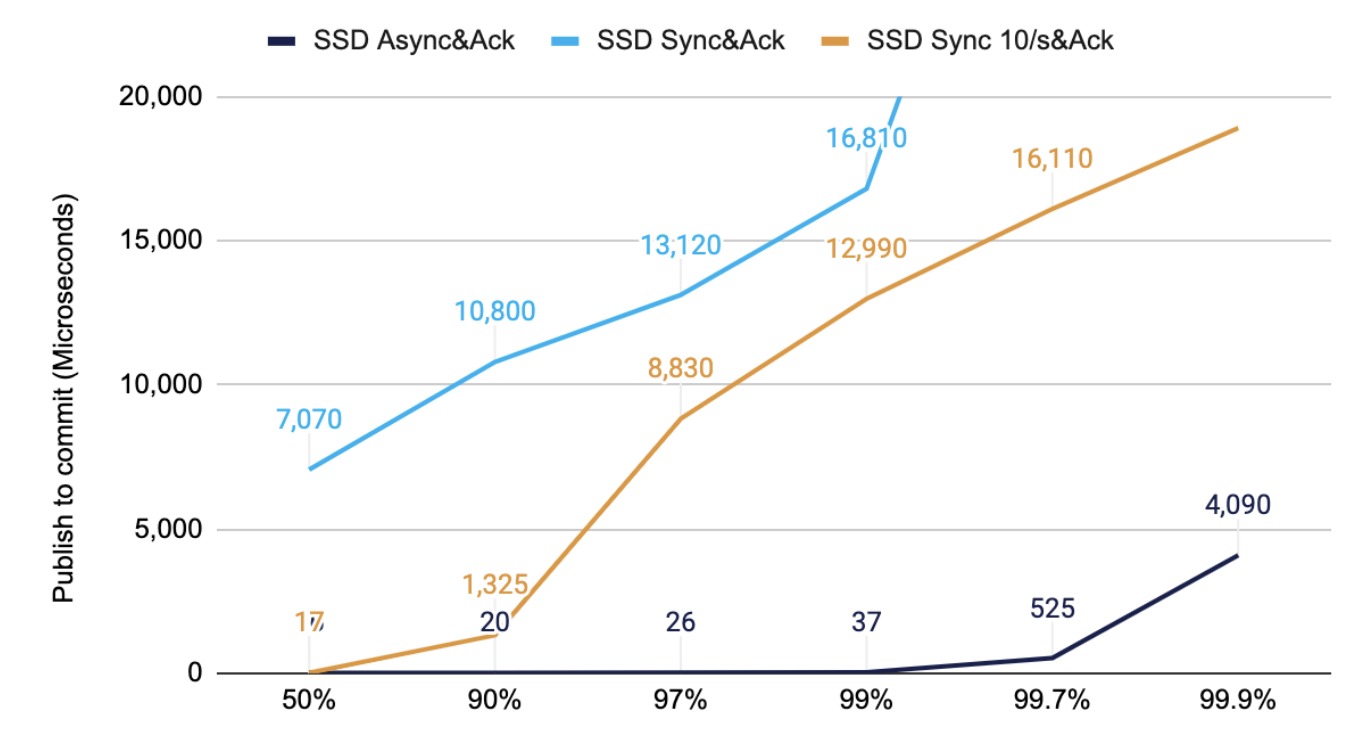
图 2. 1KB 的 50K/s 消息从在客户端发布到收到已提交消息的时间。
注意:第二台机器确认的往返时间比同步到磁盘要快得多。成本大约是网络的往返时间。
固态硬盘在企业级数据存储系统中并不罕见。它们的性能比硬盘驱动器好得多;但是,随着吞吐量的增加,它们可能会成为瓶颈。
从黄线可以看出,这显着降低了典型延迟,同时改善了该 SSD 的整体延迟分布。
具有中等大小消息的 M.2 固态驱动器
M.2 驱动器的整体性能要好得多,对于经过测试的驱动器,即使在 200Kmsg/s 的速度下也优于 SSD。尽管如此,选择性同步仍然显着改善了典型的延迟和高趋势。这是与上述相同的测试,但吞吐量更高,为 200K/s 与 50K/s
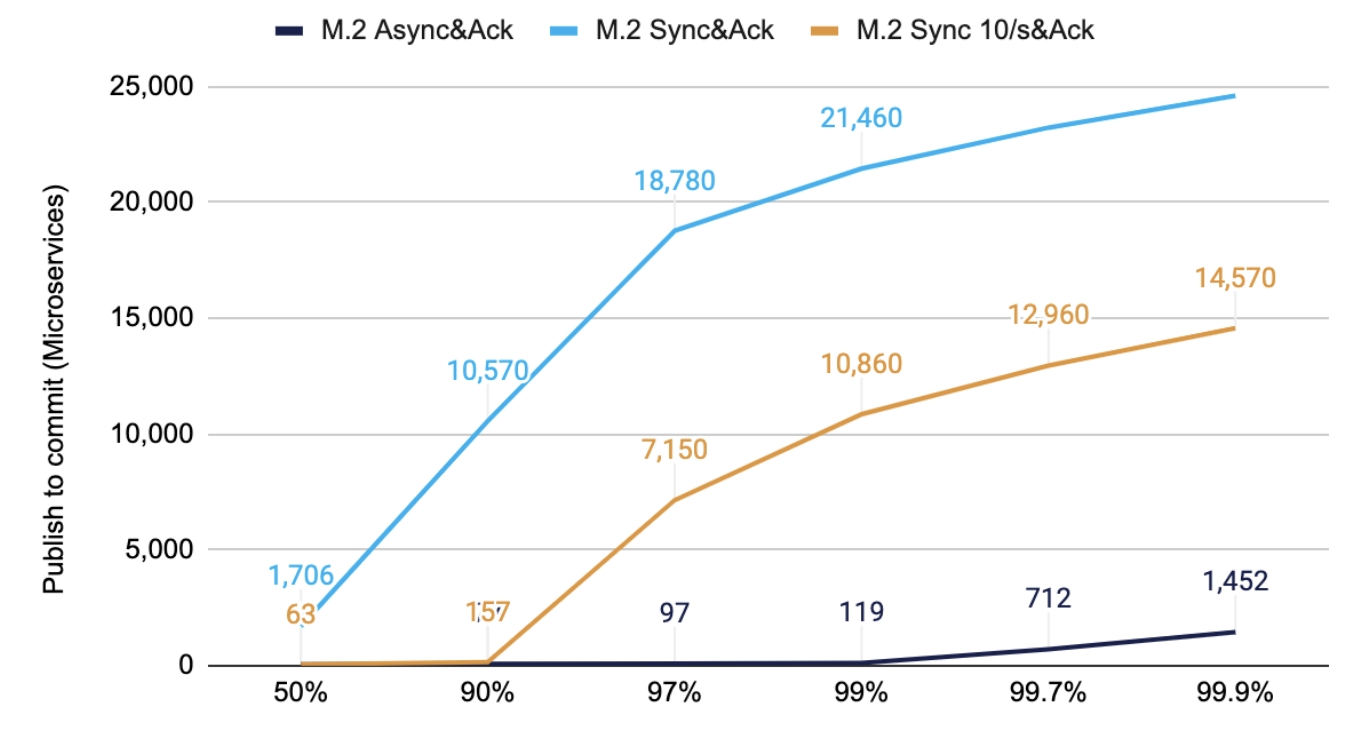
图 3. 1KB 的 200K/s 消息从在客户端发布到接收已提交消息的时间。
同样,您可以看到黄线与同步每批消息相比,选择性同步的延迟显着降低。
头部空间
为了说明这一点,VISA 的容量为每秒 65,000 条交易消息(截至 2017 年 8 月)。这是通过单个 TCP 连接的一对服务器。立即拥有更大的可用空间可以提高可靠性,降低系统在突发活动中过载的风险,并减少系统恢复正常运行所需的时间。
增加的净空减少了在活动爆发或中断时级联故障的风险。 https://en.wikipedia.org/wiki/Cascading_failure
结论
使用 SSD 同步到磁盘,大多数时间都在 25 毫秒以下,即使吞吐量也不错,最高可达 50K/s。但是,使用高性能 M.2 驱动器可将吞吐量提高到 200K/s,并且大部分时间仍低于 25 毫秒。
如果应用程序可以基于那些消息的内容(例如,基于值)选择性地同步数据,通常可以显着减少延迟。这可能导致典型的延迟接近于等待确认的复制。
测试的最快选项是异步到磁盘并等待确认复制。使用此策略,较高的百分位延迟可以是十分之一或更好。
原文地址:https://dzone.com/articles/comparing-approaches-to-durability-in-low-latency
原文作者:Peter Lawrey/Developer, Vanilla Java,伦敦


