JVM系列第8讲:JVM 垃圾回收机制原创
在第 6 讲中我们说到 Java 虚拟机的内存结构,提到了这部分的规范其实是由《Java 虚拟机规范》指定的,每个 Java 虚拟机可能都有不同的实现。其实涉及到 Java 虚拟机的内存,就不得不谈到 Java 虚拟机的垃圾回收机制。因为内存总是有限的,我们需要一个机制来不断地回收废弃的内存,从而实现内存的循环利用,这样程序才能正常地运转下去。
比起 Java 虚拟机的内存结构有《Java 虚拟机规范》规定,垃圾回收机制并没有具体的规范约束。所以很多时候不同的虚拟机有不同的实现方式,下面所说的垃圾回收都是以 HotSpot 虚拟机为例。
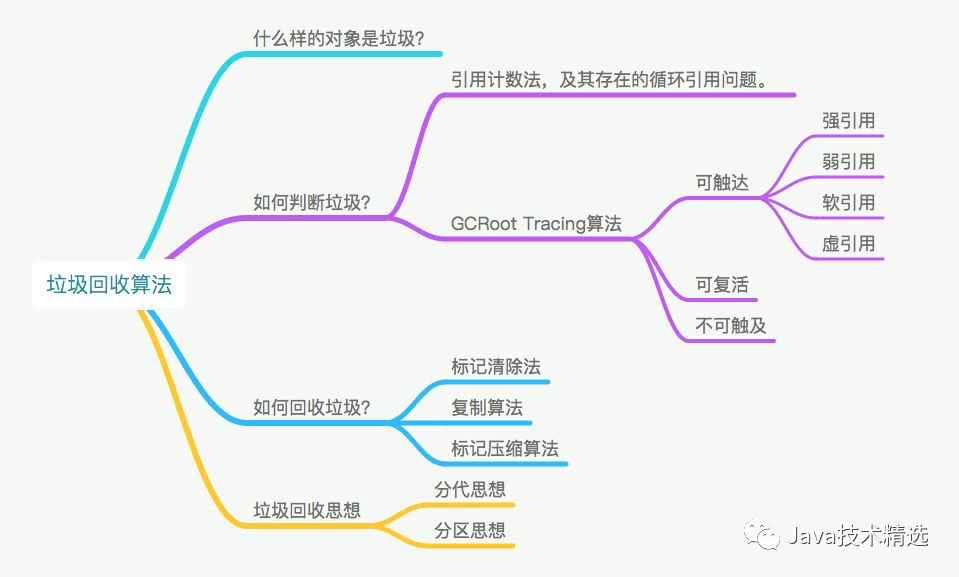
到底谁是垃圾?
要进行垃圾回收,最为重要的一个问题是:判断谁是垃圾?
联想其日常生活中,如果一个东西经常没被使用,那么这个对象可以说就是垃圾。在 Java 中也是如此,如果一个对象不可能再被引用,那么这个对象就是垃圾,应该被回收。
根据这个思想,我们很容易想到使用引用计数的方法来判断垃圾。在一个对象被引用时加一,被去除引用时减一,这样我们就可以通过判断引用计数是否为零来判断一个对象是否为垃圾。这种方法我们一般称之为「引用计数法」。
上面的这种方法虽然简单,但是其存在一个致命的问题,那就是循环引用。
A 引用了 B,B 引用了 C,C 引用了 A,它们各自的引用计数都为 1。但是它们三个对象却从未被其他对象引用,只有它们自身互相引用。从垃圾的判断思想来看,它们三个确实是不被其他对象引用的,但是此时它们的引用计数却不为零。这就是引用计数法存在的循环引用问题。
而现今的 Java 虚拟机判断垃圾对象使用的是:GC Root Tracing 算法。其大概的过程是这样:从 GC Root 出发,所有可达的对象都是存活的对象,而所有不可达的对象都是垃圾。
可以看到这里最重要的就是 GC Root 这个集合了,其实 GC Root 就是一组活跃引用的集合。但是这个集合又与一般的对象集合不太一样,这些集合是经过特意筛选出来的,通常包括:
- 所有当前被加载的 Java 类
- Java 类的引用类型静态变量
- Java类的运行时常量池里的引用类型常量
- VM的一些静态数据结构里指向GC堆里的对象的引用
- 等等
简单地说,GC Root 就是经过精心挑选的一组活跃引用,这些引用是肯定存活的。那么通过这些引用延伸到的对象,自然也是存活的。
如何进行垃圾回收?
到这里,我们了解了什么是垃圾以及 JVM 是如何判断垃圾对象的。那么识别出垃圾对象之后,JVM 是如何进行垃圾回收的呢?这就是我们下面要讲的内容:如何进行垃圾回收?
垃圾回收算法简单地说有三种算法:标记清除算法、复制算法、标记压缩算法。
- 标记清除算法。从名字可以看到其分为两个阶段:标记阶段和清除阶段。一种可行的实现方式是,在标记阶段,标记所有由 GC Root 触发的可达对象。此时,所有未被标记的对象就是垃圾对象。之后在清除阶段,清除所有未被标记的对象。标记清除算法最大的问题就是空间碎片问题。如果空间碎片过多,则会导致内存空间的不连续。虽说大对象也可以分配在不连续的空间中,但是效率要低于连续的内存空间。
- 复制算法。复制算法的核心思想是将原有的内存空间分为两块,每次只使用一块,在垃圾回收时,将正在使用的内存中的存活对象复制到未使用的内存块中。之后清除正在使用的内存块中的所有对象,之后交换两个内存块的角色,完成垃圾回收。该算法的缺点是要将内存空间折半,极大地浪费了内存空间。
- 标记压缩算法。标记压缩算法可以说是标记清除算法的优化版,其同样需要经历两个阶段,分别是:标记结算、压缩阶段。在标记阶段,从 GC Root 引用集合触发去标记所有对象。在压缩阶段,其则是将所有存活的对象压缩在内存的一边,之后清理边界外的所有空间。
对比一下这三种算法,可以发现他们都有各自的优点和缺点。
标记清除算法虽然会产生内存碎片,但是不需要移动太多对象,比较适合在存活对象比较多的情况。而复制算法虽然需要将内存空间折半,并且需要移动存活对象,但是其清理后不会有空间碎片,比较适合存活对象比较少的情况。而标记压缩算法,则是标记清除算法的优化版,减少了空间碎片。
分代思想
试想一下,如果我们单独采用任何一种算法,那么最终的垃圾回收效率都不会很好。其实 JVM 虚拟机的建造者们也是这么想的,因此在实际的垃圾回收算法中采用了分代算法。
所谓分代算法,就是根据 JVM 内存的不同内存区域,采用不同的垃圾回收算法。例如对于存活对象少的新生代区域,比较适合采用复制算法。这样只需要复制少量对象,便可完成垃圾回收,并且还不会有内存碎片。而对于老年代这种存活对象多的区域,比较适合采用标记压缩算法或标记清除算法,这样不需要移动太多的内存对象。
试想一下,如果没有采用分代算法,而在老年代中使用复制算法。在极端情况下,老年代对象的存活率可以达到100%,那么我们就需要复制这么多个对象到另外一个内存区域,这个工作量是非常庞大的。
在这里我们再深入地聊一聊新生代里采取的垃圾回收算法。如我们上面所说,新生代的特点是存活对象少,适合采用复制算法。而复制算法的一种最简单实现便是折半内存使用,另一半备用。但实际上我们知道,在实际的 JVM 新生代划分中,却不是采用等分为两块内存的形式。而是分为:Eden 区域、from 区域、to 区域 这三个区域。那么为什么 JVM 最终要采用这种形式,而不用 50% 等分为两个内存块的方式?
要解答这个问题,我们就需要先深入了解新生代对象的特点。根据IBM公司的研究表明,在新生代中的对象 98% 是朝生夕死的,所以并不需要按照1:1的比例来划分内存空间。所以在HotSpot虚拟机中,JVM 将内存划分为一块较大的Eden空间和两块较小的Survivor空间,其大小占比是8:1:1。当回收时,将Eden和Survivor中还存活的对象一次性复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Eden空间。
通过这种方式,内存的空间利用率达到了90%,只有10%的空间是浪费掉了。而如果通过均分为两块内存,则其内存利用率只有 50%,两者利用率相差了将近一倍。
分区思想
分代思想按照对象的生命周期长短将其分为了两个部分(新生代、老年代),但 JVM 中其实还有一个分区思想,即将整个堆空间划分成连续的不同小区间。
每一个小区间都独立使用,独立回收,这种算法的好处是可以控制一次回收多少个区间,可以较好地控制 GC 时间。
到这里我们基本上把 JVM 的垃圾回收都将清除了,从一开始什么是垃圾,到之后如何判断垃圾,到如何回收垃圾,到垃圾回收的两个重要思想:分代思想、分区思想。通过这么一个脉络,我们了解了垃圾回收的整体概括。在下面的章节中,我们将深入介绍这其中的细节。