
Web优化躬行记(5)——网站优化原创
目录
Web优化躬行记(1)——CSS
Web优化躬行记(2)——JavaScript
Web优化躬行记(3)——图像和网络
Web优化躬行记(4)——用户体验和工具
Web优化躬行记(5)——网站优化
Web优化躬行记(6)——优化闭环实践
正文
最近阅读了很多优秀的网站性能优化的文章,所以自己也想总结一些最近优化的手段和方法。
个人感觉性能优化的核心是:减少延迟,加速展现。
本文主要从产品设计、前端、后端和网络四个方面来诉说优化过程。
一、产品设计
在网上看到一句话:好的性能是设计出来的,而不是优化出来的。
感觉好有道理,如果将性能瓶颈扼杀在摇篮里,那么后期的维护成本将变得非常低,并且在避免改造后,都不需要浪费资源了。
1)聊天改版
最近公司有个聊天活动做改版,改版上线后惊喜的发现,监控数据居然减少了将近20W。
更深一步的探究,才知道在页面初始化时,会发一个请求,去获取一些文案,但其实这些文案都是写死的,完全可以写到页面本地。
如果在产品设计时,就不是通过接口读取的方式,那么就可以大大减少浏览器和服务器之间的通信。
2)数据迁移
公司有一个审核系统,最近审核人员反应系统使用起来越来越卡。排查后发现,定位到性能瓶颈,是因为数据表巨大导致的,目前已有6千万条。
其实在一开始设计时,就该能预估到,未来的数据量,感觉还是偷懒了,想快速完成。感叹前人挖坑,后人埋坑。
起初是想分表,但思虑后还是决定不那么做,最后采用的是MySQL归档。
前前后后花了两周的时间,才将方案落地实现,涉及到运维、QA和我们前端组,人力成本无疑是巨大的。
其实在每次完成优化后,可以再想想能不能将问题泛化,扩大维度,想想其他地方是否有类似问题,总结经验供他人学习,以及对未发生的问题进行预判。
3)大批量的504
这是在上线监控平台后不久发现的,504 的请求量太多,这类通信错误居然占了25%~30% 左右。
经过排查定位到一个常规的翻卡活动中,产品设计出现了严重的问题。
在进行一个翻卡操作时会请求两个接口,并且每个接口各自发送 3 次通信,这样会很容易发生 504 错误,每天大约有1500个这样的请求。
首先是给其中一张表加了个索引,然后是将两个接口合并成一个,并且每次返回 20 条以上的数据,这样就不用频繁的发起请求了。
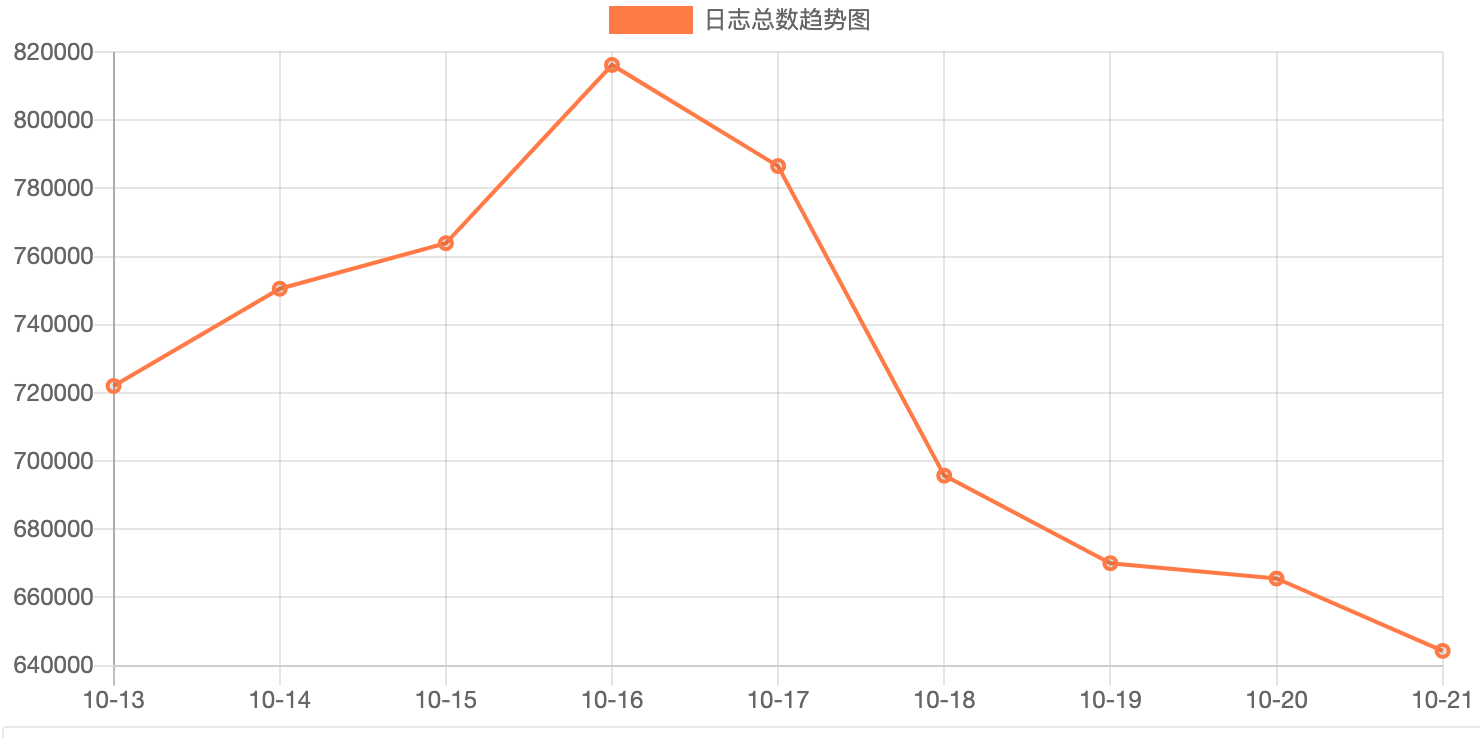
经过改造后,每日的 504 请求从 1500 个左右降低到 200 个左右,减少了整整 7.5 倍,效果立竿见影,大部分的 504 集中在 22 点到 0 点之间,这段时间的活跃度比较高。
还有一个令人意外的发现,那就是监控日志的量每天也减少了 50W 条。
二、前端
前端的优化手段非常多,常规的其实就是延迟请求和减少页面渲染次数。
1)预请求
数据预请求是将数据预请求的时机由业务发起请求的时机,提前到用户点击时,并行发送数据请求,缩短数据等待时间。
这个需要客户端配合,在Webview启动的时候,并行的去请求首屏需要的数据。
经过观察发现每次请求后端数据的API大概要花100~200ms,如果把这段时间省下来,那么也能减少白屏时间。
在与客户端沟通时,他们还是表现的比较抗拒的,在他们看来这点时间微不足道,还会增加他们的工作量。
有个人还一直强调浏览器内置的缓存规则是一剂灵药,绝对可以提升页面的性能,经过讨价还价后敲定最终的预请求方案。
2)预加载和懒加载
预加载和懒加载特指的是图片的加载,其实就是延迟请求时机。
两者的核心算法就是计算图片的相对位置,具体参考于此。
这两招非常有效,可以说是立竿见影,尤其是页面中图片量较多以及尺寸较大时,能瞬间提升页面加载。
之前做过一次偏动画的宣传页,在进入页面时,立刻请求所有图片,直接白屏好几十秒。
3)串行变并行
有一张活动页面,交互并不多,但是要展示的数据需要经过后台比较复杂的计算后才能得到。
一开始是将所有的数据都包含在一个接口中,这就导致页面发起请求后,要白屏好几秒后,才能慢慢加载。
用户的等待时间很长,经过排查后发现,其实可以将一些配置参数提取到单独的一个接口中,核心的数据再抽取到另一个接口中。
这样就是将一个串行的接口分离成两个并行的接口,先快速的让用户看到整个页面的大结构,例如头图、规则等信息。
然后在将数据渲染到合适的位置,形成了一个时间差,对用户更加友好。
三、后端
后端主要涉及是Node.js和数据库的优化,我们组涉及到的此类性能瓶颈并不多,但也会有一些。
1)内存泄露
自研了监控平台,在刚上线时,就遇到了性能问题,首先是采集的参数在大批量的发送给存储的服务器时,服务器宕机了。
因为每秒就有几百甚至几千的请求发送过来,服务器需要整理数据后加入到数据库中,当数据量暴增时,服务器就会来不及处理。
这个性能瓶颈发生后,马上加入任务队列,服务器就能平稳的运行了。
之后又出现了另一个问题,CPU会在不特定时间段(例如21~22、23~02等)飙到70%,内存也是一路飙升不会下降,明显是出现了内存泄漏,具体的排查过程可以参考于此。
开通了阿里云的 Node.js 性能平台,在前前后后调试了三周,有点像探案的过程,才最终定位到一段最为可疑的代码。
原来是为外部的一个对象反复注册了一个事件,应该是形成了一个闭包,让闭包内的变量都无法释放。
2)数据库
仍然是在研发监控平时时遇到的性能瓶颈,这次主要体现在数据库。
监控的日志我都存储在MySQL中,每日 70W 条记录,数据量很快达到了千万级别,在做查询时,变慢了很多。
那么就得让索引上了,亚洲舞王尼库拉斯赵四曾说过:一个索引解决不了的,那就来两个索引。
我也是这么做的,加了好多个索引,但唯独模糊查询,这个不是加索引能解决的,尝试了很久,最终还是决定迁移到ElasticSearch中。
效果也是立竿见影的,几千万条数据,几秒钟就出了结果,令我惊叹不已。
这里顺便说下,我会在什么场景中选择 MongoDB 作为数据库的。
MySQL是一种关系型数据库,会事先声明表结构,那么对于数据结构不定的记录,存储起来会比较费劲。
例如记录中有许多JSON格式的数据,就比较适合存在 MongoDB,当然了,这类数据也可以转换成字符串存在 MySQL 的一个字段中。
只是在读取和写入时,要经过序列化和反序列化的操作,并且如果要查询JSON数据的某一个字段时,MySQL中就只能模糊查询了。
但是平时的话,我还是会尽量将数据存在 MySQL 中,有个很直接的原因是因为线上的 MySQL 有一个功能完善的可视化界面,而 MongoDB 没有,只有一个我自制的简陋工具。
3)管理后台挂起
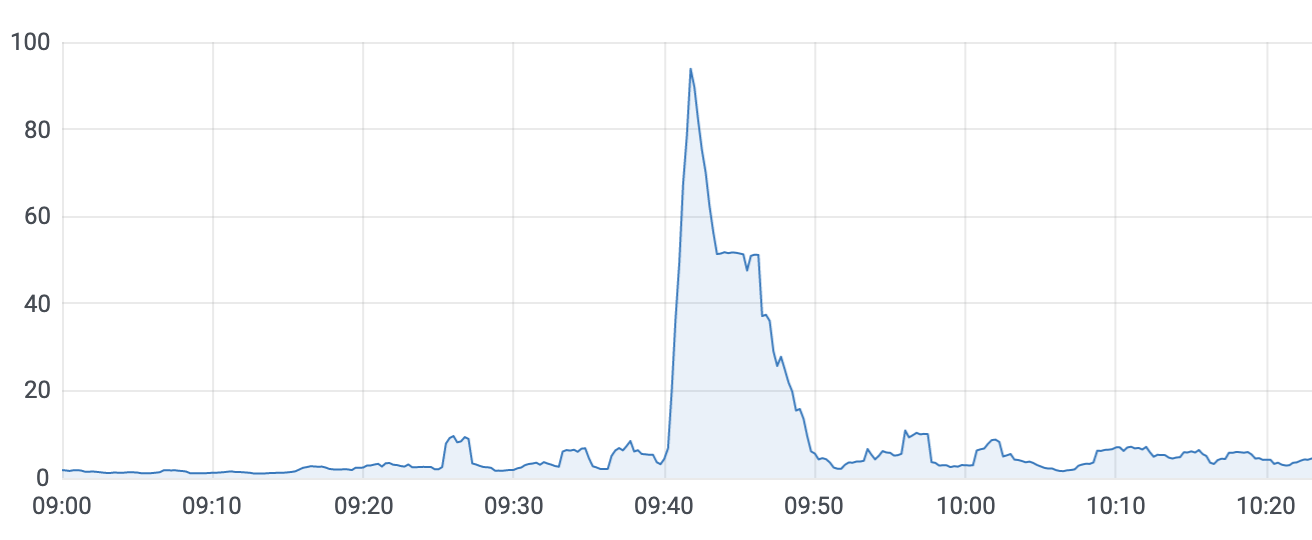
之前也会偶尔有管理后台服务挂起的情况发生,但最近会在每天的10点左右发生。
在下图中,一分钟内server服务瞬间飙到了 100%,不得不让我引起注意。
查找那段时间的日志,发现有很多送礼的记录,反向查询后,定位到一个导出链接。
初步以为是这个功能导致的服务挂起,询问相关操作人员,得到当时的操作过程。
在预发环境模拟,得到的结果是可以正常导出,所以应该可以排除它的嫌疑。
回想到前天也发生了挂起(不过前天的CPU都比较正常),再次翻查日志,新发现直指审核模块。
与审核人员沟通后,她们向我一顿吐槽,大倒苦水,说这系统11点后,经常卡顿转圈。
这个系统后续有很大的优化空间,那么目前首要任务是解决服务挂起的问题。
可以想到的是将审核模块单独配置一台服务器,做成独立服务,这样也便于观察。
服务切换其实就是将特定规则的API指向另一个服务,代码和逻辑都不需要改动,非常方面。
隔天发现仍然会挂起,但是挂起的服务可以定位到审核模块,运维也找到了一条发生504的接口。
前一天发生的挂起,也是这个接口引起的,顺着这条接口查看代码,并没有发现什么异常。
打开日志,发现这个接口的响应的确非常慢,要几分钟了,再去查其中涉及到的SQL查询语句,发现也很耗时。
将语句拿到数据库中执行 EXPLAIN 命令,影响的行数要 311W 多条,命中的索引是 idx_create_time。
而去掉其中的一个日期限制后马上降到 69 条,命中的是一个联合索引,回到代码中,查看逻辑后,发现这个时间限制是多余的,马上就将其去除。
还有一条SQL语句运行也很慢,影响的行数要 16W 多条,命中的索引是 idx_status,而这个 status 其实只有几个可选的关键字,会影响查询效率。
于是再创建一个联合索引,影响的行数降到 1785 条,优化后,再反馈给审核人员。


