
一次百万长连接压测 Nginx OOM 的问题排查分析原创
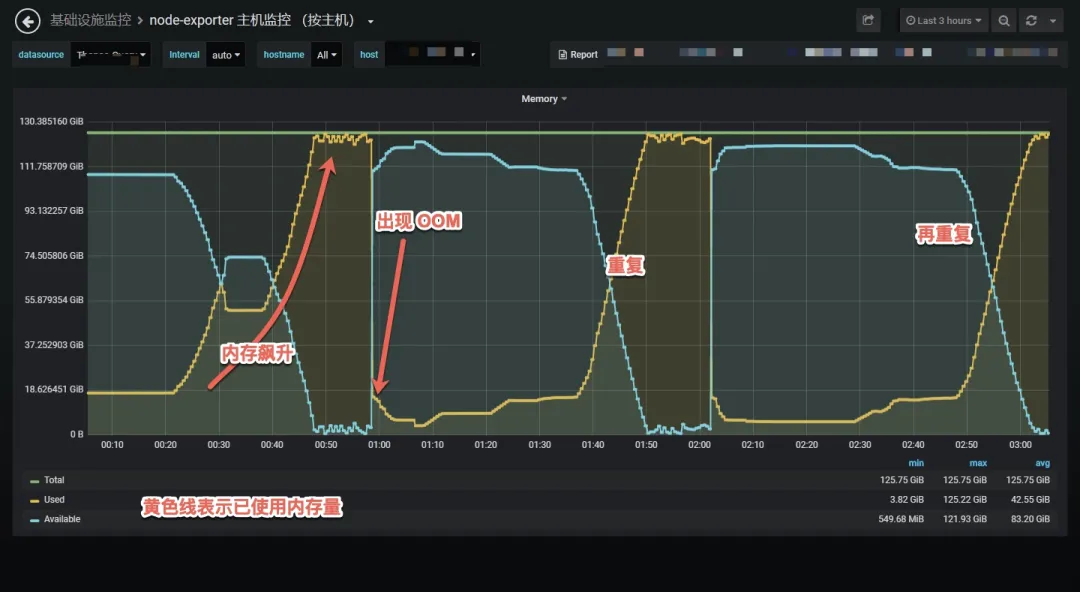
在最近的一次百万长连接压测中,32C 128G 的四台 Nginx 频繁出现 OOM,出现问题时的内存监控如下所示。
排查的过程记录如下。
现象描述
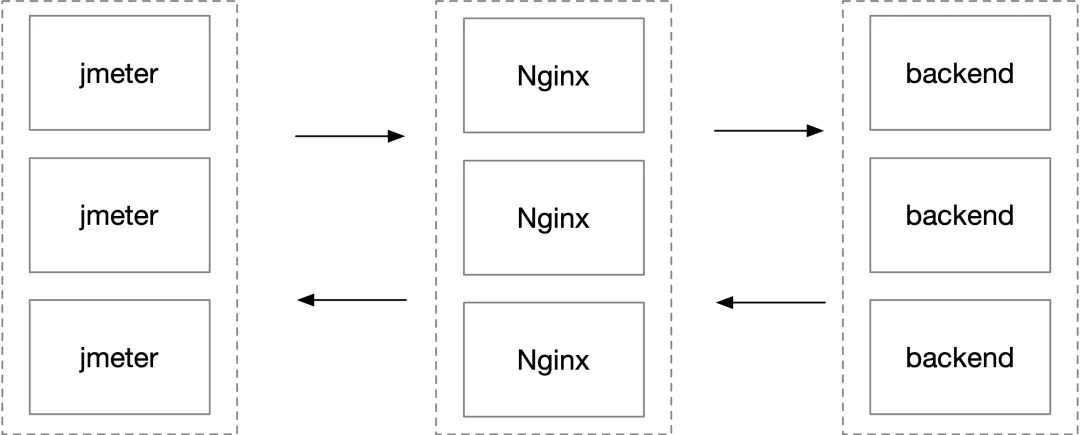
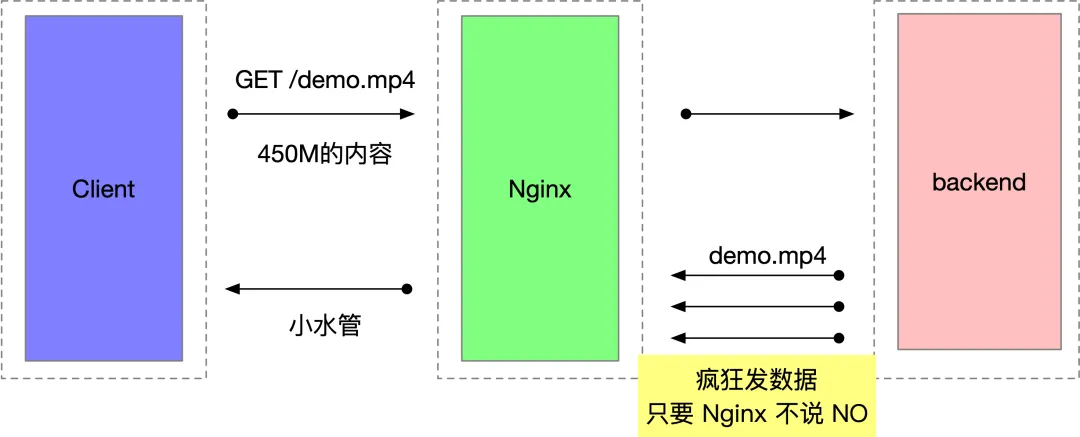
这是一个 websocket 百万长连接收发消息的压测环境,客户端 jmeter 用了上百台机器,经过四台 Nginx 到后端服务,简化后的部署结构如下图所示。
在维持百万连接不发数据时,一切正常,Nginx 内存稳定。在开始大量收发数据时,Nginx 内存开始以每秒上百 M 的内存增长,直到占用内存接近 128G,woker 进程开始频繁 OOM 被系统杀掉。32 个 worker 进程每个都占用接近 4G 的内存。dmesg -T 的输出如下所示。
[Fri Mar 13 18:46:44 2020] Out of memory: Kill process 28258 (nginx) score 30 or sacrifice child
[Fri Mar 13 18:46:44 2020] Killed process 28258 (nginx) total-vm:1092198764kB, anon-rss:3943668kB, file-rss:736kB, shmem-rss:4kB
work 进程重启后,大量长连接断连,压测就没法继续增加数据量。
排查过程分析
拿到这个问题,首先查看了 Nginx 和客户端两端的网络连接状态,使用 ss -nt 命令可以在 Nginx 看到大量 ESTABLISH 状态连接的 Send-Q 堆积很大,客户端的 Recv-Q 堆积很大。Nginx 端的 ss 部分输出如下所示。
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 792024 1.1.1.1:80 2.2.2.2:50664
...
在 jmeter 客户端抓包偶尔可以看到较多零窗口,如下所示。
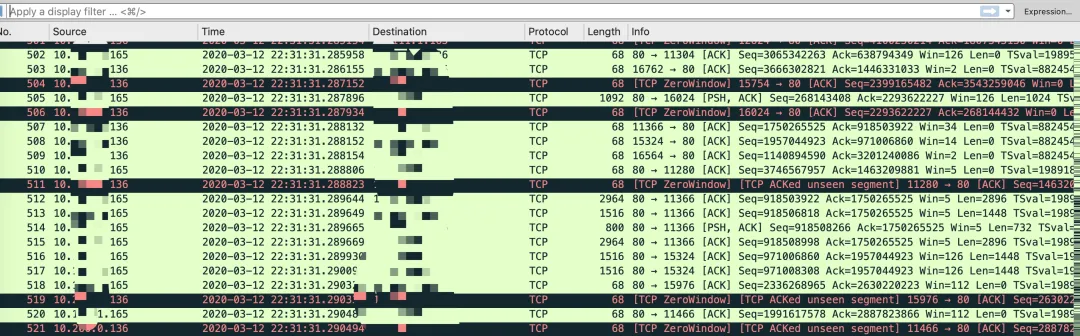
到了这里有了一些基本的方向,首先怀疑的就是 jmeter 客户端处理能力有限,有较多消息堆积在中转的 Nginx 这里。
为了验证想法,想办法 dump 一下 nginx 的内存看看。因为在后期内存占用较高的状况下,dump 内存很容易失败,这里在内存刚开始上涨没多久的时候开始 dump。
首先使用 pmap 查看其中任意一个 worker 进程的内存分布,这里是 4199,使用 pmap 命令的输出如下所示。
pmap -x 4199 | sort -k 3 -n -r
00007f2340539000 475240 461696 461696 rw--- [ anon ]
...
随后使用 cat /proc/4199/smaps | grep 7f2340539000 查找某一段内存的起始和结束地址,如下所示。
cat /proc/3492/smaps | grep 7f2340539000
7f2340539000-7f235d553000 rw-p 00000000 00:00 0
随后使用 gdb 连上这个进程,dump 出这一段内存。
gdb -pid 4199
dump memory memory.dump 0x7f2340539000 0x7f235d553000
随后使用 strings 命令查看这个 dump 文件的可读字符串内容,可以看到是大量的请求和响应内容。
这样坚定了是因为缓存了大量的消息导致的内存上涨。随后看了一下 Nginx 的参数配置,
location / {
proxy_pass http://xxx;
proxy_set_header X-Forwarded-Url "$scheme://$host$request_uri";
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Cookie $http_cookie;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 512M;
client_body_buffer_size 64M;
proxy_connect_timeout 900;
proxy_send_timeout 900;
proxy_read_timeout 900;
proxy_buffer_size 64M;
proxy_buffers 64 16M;
proxy_busy_buffers_size 256M;
proxy_temp_file_write_size 512M;
}
可以看到 proxy_buffers 这个值设置的特别大。接下来我们来模拟一下,upstream 上下游收发速度不一致对 Nginx 内存占用的影响。
模拟 Nginx 内存上涨
我这里模拟的是缓慢收包的客户端,另外一边是一个资源充沛的后端服务端,然后观察 Nginx 的内存会不会有什么变化。
缓慢收包客户端是用 golang 写的,用 TCP 模拟 HTTP 请求发送,代码如下所示。
package main
import (
"bufio"
"fmt"
"net"
"time"
)
func main() {
conn, _ := net.Dial("tcp", "10.211.55.10:80")
text := "GET /demo.mp4 HTTP/1.1\r\nHost: ya.test.me\r\n\r\n"
fmt.Fprintf(conn, text)
for ; ; {
_, _ = bufio.NewReader(conn).ReadByte()
time.Sleep(time.Second * 3)
println("read one byte")
}
}
在测试 Nginx 上开启 pidstat 监控内存变化
pidstat -p pid -r 1 1000
运行上面的 golang 代码,Nginx worker 进程的内存变化如下所示。
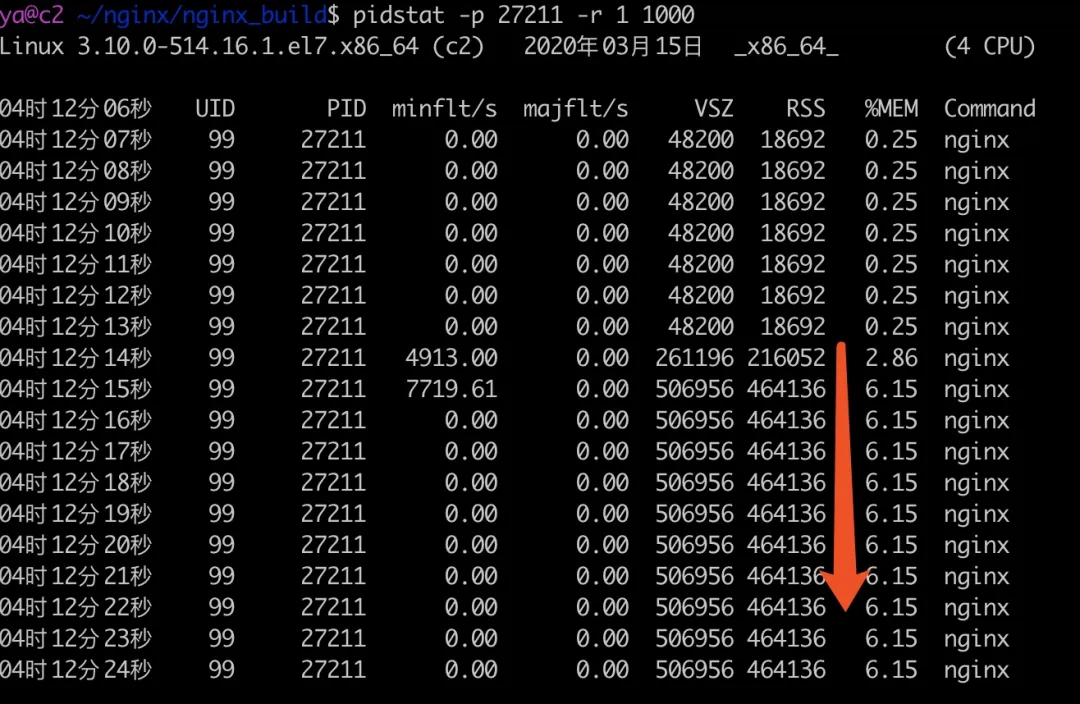
04:12:13 是 golang 程序启动的时间,可以看到在很短的时间内,Nginx 的内存占用就涨到了 464136 kB(接近 450M),且会维持很长一段时间。
同时值得注意的是,proxy_buffers 的设置大小是针对单个连接而言的,如果有多个连接发过来,内存占用会继续增长。下面是同时运行两个 golang 进程对 Nginx 内存影响的结果。
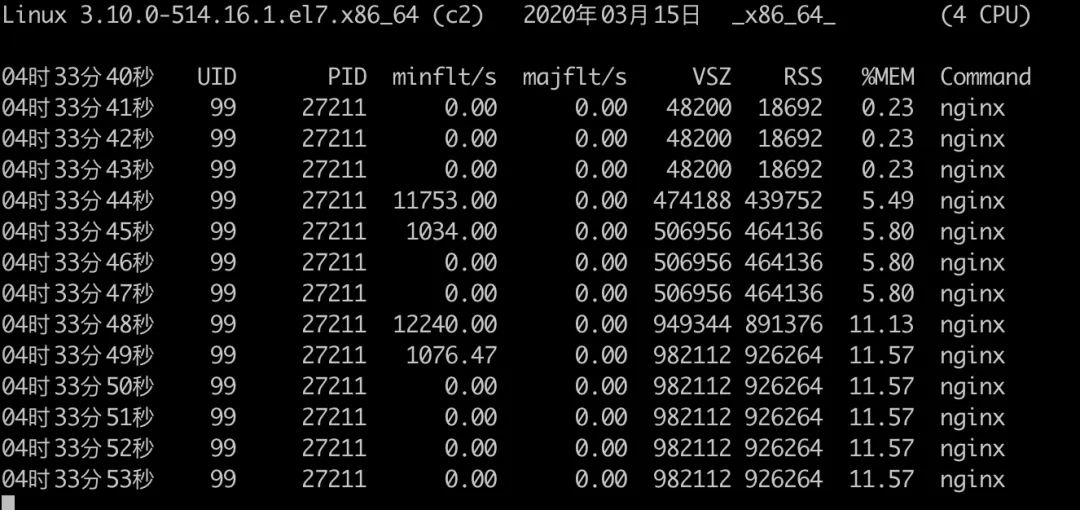
可以看到两个慢速客户端连接上来的时候,内存已经涨到了 900 多 M。
解决方案
因为要支持上百万的连接,针对单个连接的资源配额要小心又小心。一个最快改动方式是把 proxy_buffering 设置为 off,如下所示。
proxy_buffering off;
经过实测,在压测环境修改了这个值以后,以及调小了 proxy_buffer_size 的值以后,内存稳定在了 20G 左右,没有再飙升过。后面可以开启 proxy_buffering,调整 proxy_buffers 的大小可以在内存消耗和性能方面取得更好的平衡。
重复刚才的测试,结果如下所示。
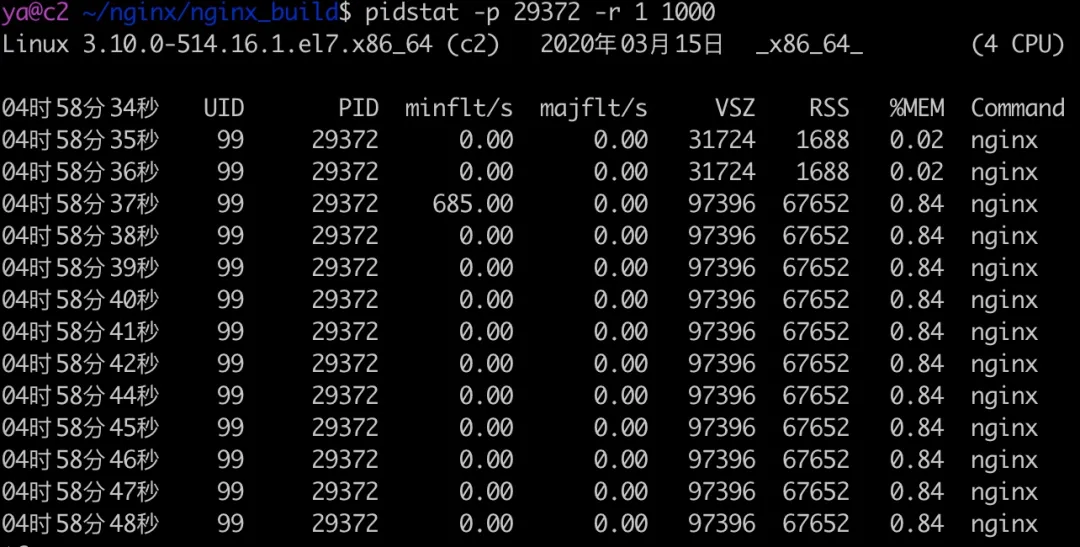
可以看到这次内存值增长了 64M 左右。为什么是增长 64M 呢?来看看 proxy_buffering 的 Nginx 文档(http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_buffering)。
When buffering is enabled, nginx receives a response from the proxied server as soon as possible, saving it into the buffers set by the proxy_buffer_size and proxy_buffers directives. If the whole response does not fit into memory, a part of it can be saved to a temporary file on the disk. Writing to temporary files is controlled by the proxy_max_temp_file_size and proxy_temp_file_write_size directives.
When buffering is disabled, the response is passed to a client synchronously, immediately as it is received. nginx will not try to read the whole response from the proxied server. The maximum size of the data that nginx can receive from the server at a time is set by the proxy_buffer_size directive.
可以看到,当 proxy_buffering 处于 on 状态时,Nginx 会尽可能多的将后端服务器返回的内容接收并存储到自己的缓冲区中,这个缓冲区的最大大小是 proxy_buffer_size * proxy_buffers 的内存。
如果后端返回的消息很大,这些内存都放不下,会被放入到磁盘文件中。临时文件由 proxy_max_temp_file_size 和 proxy_temp_file_write_size 这两个指令决定的,这里不展开。
当 proxy_buffering 处于 off 状态时,Nginx 不会尽可能的多的从代理 server 中读数据,而是一次最多读 proxy_buffer_size 大小的数据发送给客户端。
Nginx 的 buffering 机制设计的初衷确实是为了解决收发两端速度不一致问题的,没有 buffering 的情况下,数据会直接从后端服务转发到客户端,如果客户端的接收速度足够快,buffering 完全可以关掉。但是这个初衷在海量连接的情况下,资源的消耗需要同时考虑进来,如果有人故意伪造比较慢的客户端,可以使用很小的代价消耗服务器上很大的资源。
其实这是一个非阻塞编程中的典型问题,接收数据不会阻塞发送数据,发送数据不会阻塞接收数据。如果 Nginx 的两端收发数据速度不对等,缓冲区设置得又过大,就会出问题了。
Nginx 源码分析
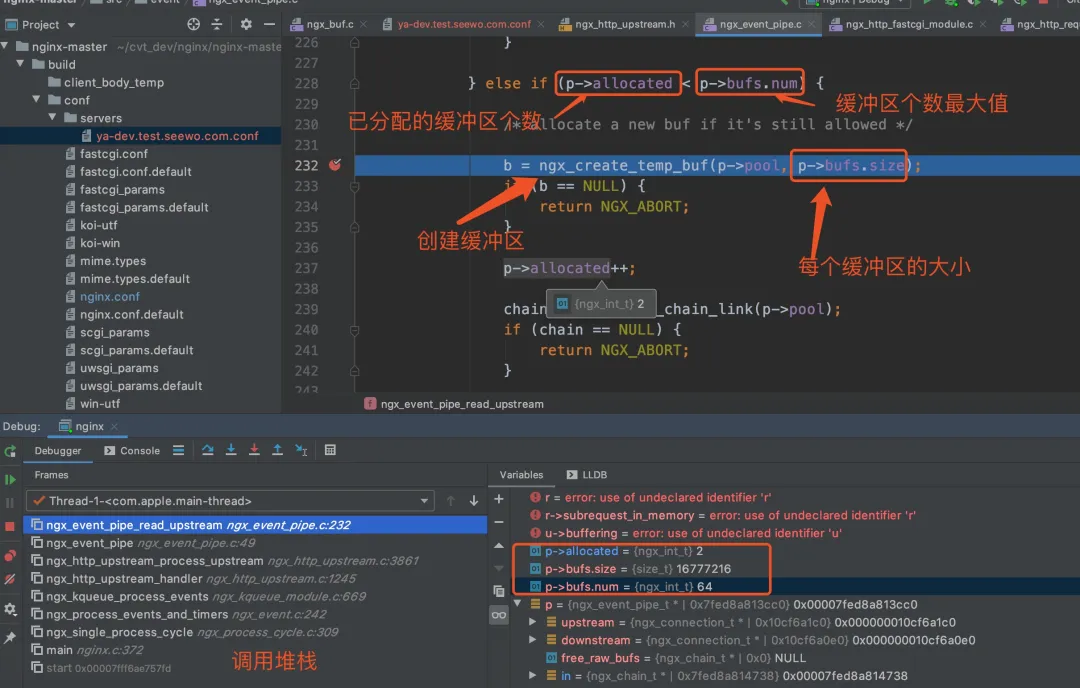
读取后端的响应写入本地缓冲区的源码在 src/event/ngx_event_pipe.c 中的 ngx_event_pipe_read_upstream 方法中。这个方法最终会调用 ngx_create_temp_buf 创建内存缓冲区。创建的次数和每次缓冲区的大小由 p->bufs.num(缓冲区个数) 和 p->bufs.size(每个缓冲区的大小)决定,这两个值就是我们在配置文件中指定的 proxy_buffers 的参数值。这部分源码如下所示。
static ngx_int_t
ngx_event_pipe_read_upstream(ngx_event_pipe_t *p)
{
for ( ;; ) {
if (p->free_raw_bufs) {
// ...
} else if (p->allocated < p->bufs.num) { // p->allocated 目前已分配的缓冲区个数,p->bufs.num 缓冲区个数最大大小
/* allocate a new buf if it's still allowed */
b = ngx_create_temp_buf(p->pool, p->bufs.size); // 创建大小为 p->bufs.size 的缓冲区
if (b == NULL) {
return NGX_ABORT;
}
p->allocated++;
}
}
}
Nginx 源码调试的界面如下所示。
后记
还有过程中一些辅助的判断方法,比如通过 strace、systemtap 工具跟踪内存的分配、释放过程,这里没有展开,这些工具是分析黑盒程序的神器。
除此之外,在这次压测过程中还发现了 worker_connections 参数设置不合理导致 Nginx 启动完就占了 14G 内存等问题,这些问题在没有海量连接的情况下是比较难发现的。
最后,底层原理是必备技能,调参是门艺术。上面说的内容可能都是错的,看看排查思路就好。



