
如何调用一个只支持batch_call的服务?原创
我们先来说下标题是什么意思。
为了更好的理解我说的是啥,我们来举个例子。
假设你现在在做一个类似B站的系统,里面放了各种视频。
用户每天在里头上传各种视频。
按理说每个视频都要去审查一下有没有搞颜色,但总不能人眼挨个看吧。
毕竟唐老哥表示这玩意看多了,看太阳都是绿色的,所以会有专门训练过的算法服务去做检测。
但也不能上来就整个视频每一帧都拿去做审查吧,所以会在每个视频里根据时长和视频类型随机抽出好几张图片去做审查,比如视频标签是美女的,算法爱看,那多抽几张。标签是编程的,狗都不看,就少抽几张。
将这些抽出来的图片,送去审查。
为了实现这个功能,我们会以视频为维度去做审核,而每个视频里都会有N张数量不定的图片,下游服务是个使用GPU去检测图片的算法服务。
现在问题来了,下游服务的算法开发告诉你,这些个下游服务,它不支持很高的并发,但请求传参里给你加了个数组,你可以批量(batch)传入一个比较大的图片数组,通过这个方式可以提升点图片处理量。
于是,我们的场景就变成。
上游服务的入参是一个视频和它的N张图片,出参是这个视频是否审核通过。
下游服务的入参是N张图片的,出参是这个视频是否审核通过。

现在我们想要用上游服务接入下游服务。该怎么办?
看上去挺好办的,一把梭不就完事了吗?
当一个视频进来,就拿着视频的十多张图片作为一个batch去进行调用。
有几个视频进来,就开几个这样的并发。
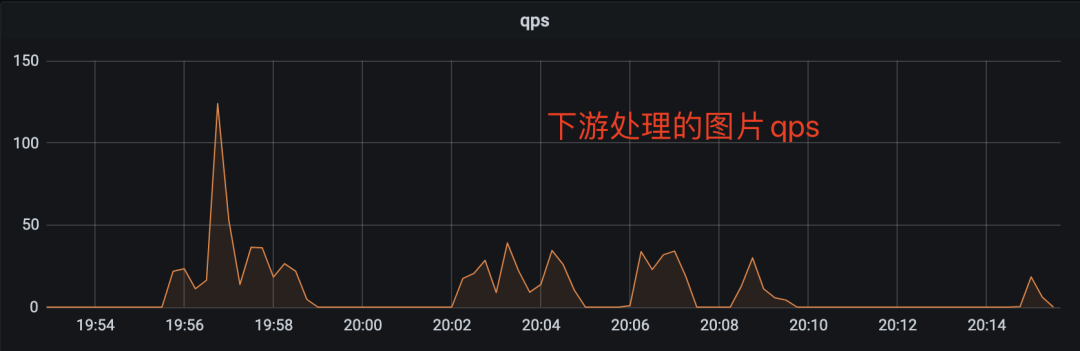
这么做的结果就是,当并发大一点时,你会发现性能很差,并且性能非常不稳定,比如像下面的监控图一样一会3qps,一会15qps。处理的图片也只支持20qps左右。
狗看了都得摇头。

这可如何是好?
为什么下游需要batch call
本着先问是不是,再问为什么的精神,我们先看看为啥下游的要求会如此别致。
为什么同样都是处理多张图片,下游不搞成支持并发而要搞成批量调用(batch call)?
这个设定有点奇怪?
其实不奇怪,在算法服务中甚至很常见,举个例子你就明白了。
同样是处理多张图片,为了简单,我就假设是三张吧。如果是用单个cpu去处理的话。那不管是并发还是batch进来,由于cpu内部的计算单元有限,所以你可以简单理解为,这三张图片,就是串行去计算的。

我计算第一张图片是否能审核通过,跟第二张图片是否能审核通过,这两者没有逻辑关联,因此按道理两张图片是可以并行计算。
奈何我CPU计算单元有限啊,做不到啊。
但是。
如果我打破计算单元有限的这个条件,给CPU加入超多计算单元,并且弱化一些对于计算没啥用处的组件,比如cache和控制单元。那我们就有足够的算力可以让这些图片的计算并行起来了。

是的,把CPU这么一整,它其实就变成了GPU。

上面的讲解只是为了方便理解,实际上,gpu会以更细的粒度去做并发计算,比如可以细到图片里的像素级别。
这也是为什么如果我们跑一些3d游戏的时候,需要用到显卡,因为它可以快速的并行计算画面里每个地方的光影,远近效果啥的,然后渲染出画面。
回到为什么要搞成batch call的问题中。
其实一次算法服务调用中,在数据真正进入GPU前,其实也使用了CPU做一些前置处理。
因此,我们可以简单的将一次调用的时间理解成做了下面这些事情。

服务由CPU逻辑和GPU处理逻辑组成,调用进入服务后,会有一些前置逻辑,它需要CPU来完成,然后才使用GPU去进行并行计算,将结果返回后又有一些后置的CPU处理逻辑。中间的GPU部分,管是计算1张图,还是计算100张图,只要算力支持,那它们都是并行计算的,耗时都差不多。
如果把这多张图片拆开,并发去调用这个算法服务,那就有 N组这样的CPU+GPU的消耗,而中间的并行计算,其实没有利用到位。
并且还会多了前置和后置的CPU逻辑部分,算法服务一般都是python服务,主流的一些web框架几乎都是以多进程,而不是多线程的方式去处理外部请求,这就有可能导致额外的进程间切换消耗。
当并发的请求多了,请求处理不过来,后边来的请求就需要等前边的处理完才能被处理,后面的请求耗时看起来就会变得特别大。这也是上面图1里,接口延时(latency)像过山车那样往上涨的原因。

按理说减少并发,增大每次调用时的图片数量,就可以解决这个问题。
这就是推荐batch call的原因。
但问题又来了。
每次调用,上游服务输入的是一个视频以及它的几张图片,调用下游时,batch的数量按道理就只能是这几张图片的数量,怎么才能增大batch的数量呢?
这里的调用,就需要分为同步调用和异步调用了。
同步调用和异步调用的区别
同步调用,意思是上游发起请求后,阻塞等待,下游处理逻辑后返回结果给上游。常见的形式就像我们平时做的http调用一样。

异步调用,意思是上游发起请求后立马返回,下游收到消息后慢慢处理,处理完之后再通过某个形式通知上游。常见的形式是使用消息队列,也就是mq。将消息发给mq后,下游消费mq消息,触发处理逻辑,然后再把处理结果发到mq,上游消费mq的结果。

异步调用的形式接入

回到我们文章开头提到的例子,当上游服务收到一个请求(一个视频和它对应的图片),这时候上游服务作为生产者将这个数据写入到mq中,请求返回。然后新造一个C服务,负责批量消费mq里的消息。这时候服务C就可以根据下游服务的性能控制自己的消费速度,比如一次性消费10条数据(视频),每个数据下面挂了10个图片,那我一次batch的图片数量就是10*10=100张,原来的10次请求就变为了1次请求。这对下游就相当的友好了。
下游返回结果后,服务C将结果写入到mq的另外一个topic下,由上游去做消费,这样就结束了整个调用流程。
当然上面的方案,如果你把mq换成数据库,一样是ok的,这时候服务C就可以不断的定时轮询数据库表,看下哪些请求没处理,把没处理的请求批量捞出来再batch call下游。不管是mq还是数据库,它们的作用无非就是作为中转,暂存数据,让服务C根据下游的消费能力,去消费这些数据。
这样不管后续要加入多少个新服务,它们都可以在原来的基础上做扩展,如果是mq,加topic,如果是数据库,则加数据表,每个新服务都可以根据自己的消费能力去调整消费速度。

其实对于这种上下游服务处理性能不一致的场景,最适合用的就是异步调用。而且涉及到的服务性能差距越大,服务个数越多,这个方案的优势就越明显。
同步调用的方式接入
虽然异步调用在这种场景下的优势很明显,但也有个缺点,就是它需要最上游的调用方能接受用异步的方式去消费结果。其实涉及到算法的服务调用链,都是比较耗时的,用异步接口非常合理。但合理归合理,有些最上游他不一定听你的,就是不能接受异步调用。
这就需要采用同步调用的方案,但怎么才能把同步接口改造得更适合这种调用场景,这也是这篇文章的重点。
限流
如果直接将请求打到下游算法服务,下游根本吃不消,因此首先需要做的就是给在上游调用下游的地方,加入一个速率限制(rate limit)。
这样的组件一般也不需要你自己写,几乎任何一个语言里都会有现成的。
比如golang里可以用golang.org/x/time/rate库,它其实是用令牌桶算法实现的限流器。如果不知道令牌桶是啥也没关系,不影响理解。

当然,这个限制的是当前这个服务调用下游的qps,也就是所谓的单节点限流。如果是多个服务的话,网上也有不少现成的分布式限流框架。但是,还是那句话,够用就好。
限流只能保证下游算法服务不被压垮,并不能提升单次调用batch的图片数量,有没有什么办法可以解决这个问题呢?
参考Nagle算法的做法
我们熟悉的TCP协议里,有个算法叫Nagle算法,设计它的目的,就是为了避免一次传过少数据,提高数据包的有效数据负载。
当我们想要发送一些数据包时,数据包会被放入到一个缓冲区中,不立刻发送,那什么时候会发送呢?
数据包会在以下两个情况被发送:
-
缓冲区的数据包长度达到某个长度(MSS)时。
-
或者等待超时(一般为
200ms)。在超时之前,来的那么多个数据包,就是凑不齐MSS长度,现在超时了,不等了,立即发送。
这个思路就非常值得我们参考。我们完全可以自己在代码层实现一波,实现也非常简单。
1.我们定义一个带锁的全局队列(链表)。
2.当上游服务输入一个视频和它对应的N张图片时,就加锁将这N张图片数据和一个用来存放返回结果的结构体放入到全局队列中。然后死循环读这个结构体,直到它有结果。就有点像阻塞等待了。
3.同时在服务启动时就起一个线程A专门用于收集这个全局队列的图片数据。线程A负责发起调用下游服务的请求,但只有在下面两个情况下会发起请求
-
当收集的图片数量达到xx张的时候
-
距离上次发起请求过了xx毫秒(超时)
4.调用下游结束后,再根据一开始传入的数据,将调用结果拆开来,送回到刚刚提到的用于存放结果的结构体中。
5.第2步里的死循环因为存放返回结果的结构体,有值了,就可以跳出死循环,继续执行后面的逻辑。

这就像公交车站一样,公交车站不可能每来一个顾客就发一辆公交车,当然是希望车里顾客越多越好。上游每来一个请求,就把请求里的图片,也就是乘客,塞到公交车里,公交车要么到点发车(向下游服务发起请求),要么车满了,也没必要等了,直接发车。这样就保证了每次发车的时候公交车里的顾客数量足够多,发车的次数尽量少。
大体思路就跟上面一样,如果是用go来实现的话,就会更加简单。
比如第1步里的加锁全局队列可以改成有缓冲长度的channel。第2步里的"用来存放结果的结构体",也可以改成另一个无缓冲channel。执行 res := <-ch, 就可以做到阻塞等待的效果。
而核心的仿Nagle的代码也大概长下面这样。当然不看也没关系,反正你已经知道思路了。
func CallAPI() error {
size := 100
// 这个数组用于收集视频里的图片,每个 IVideoInfo 下都有N张图片
videoInfos := make([]IVideoInfo, 0, size)
// 设置一个200ms定时器
tick := time.NewTicker(200 * time.Microsecond)
defer tick.Stop()
// 死循环
for {
select {
// 由于定时器,每200ms,都会执行到这一行
case <-tick.C:
if len(videoInfos) > 0 {
// 200ms超时,去请求下游
limitStartFunc(videoInfos, true)
// 请求结束后把之前收集的数据清空,重新开始收集。
videoInfos = make([]IVideoInfo, 0, size)
}
// AddChan就是所谓的全局队列
case videoInfo, ok := <-AddChan:
if !ok {
// 通道关闭时,如果还有数据没有去发起请求,就请求一波下游服务
limitStartFunc(videoInfos, false)
videoInfos = make([]IVideoInfo, 0, size)
return nil
} else {
videoInfos = append(videoInfos, videoInfo)
if videoInfos 内的图片满足xx数量 {
limitStartFunc(videoInfos, false)
videoInfos = make([]IVideoInfo, 0, size)
// 重置定时器
tick.Reset(200 * time.Microsecond)
}
}
}
}
return nil
}
通过这一操作,上游每来一个请求,都会将视频里的图片收集起来,堆到一定张数的时候再统一请求,大大提升了每次batch call的图片数量,同时也减少了调用下游服务的次数。真·一举两得。
优化的效果也比较明显,上游服务支持的qps从原来不稳定的3q~15q变成稳定的90q。下游的接口耗时也变得稳定多了,从原来的过山车似的飙到15s变成稳定的500ms左右。处理的图片的速度也从原来20qps提升到350qps。
到这里就已经大大超过业务需求的预期(40qps)了,够用就好,多一个qps都是浪费。
可以了,下班吧。


总结
-
为了充分利用GPU并行计算的能力,不少算法服务会希望上游通过加大batch的同时减少并发的方式进行接口调用。
-
对于上下游性能差距明显的服务,建议配合mq采用异步调用的方式将服务串联起来。
-
如果非得使用同步调用的方式进行调用,建议模仿Nagle算法的形式,攒一批数据再发起请求,这样既可以增大batch,同时减少并发,真·一举两得,亲测有效。
最后
讲了那么多可以提升性能的方式,现在需求来了,如果你资源充足,但时间不充足,那还是直接同步调用一把梭吧。
性能不够?下游加机器,gpu卡,买!
然后下个季度再提起一个技术优化,性能提升xx%,cpu,gpu减少xx%。
有没有闻到?
这是KPI的味道。
又是一个小细节,学到了的兄弟们,评论区里打个【学到了】。
最近原创更文的阅读量稳步下跌,思前想后,夜里辗转反侧。
我有个不成熟的请求。

离开广东好长时间了,好久没人叫我靓仔了。
大家可以在评论区里,叫我一靓仔吗?
我这么善良质朴的愿望,能被满足吗?
如果实在叫不出口的话,能帮我点下右下角的点赞和在看吗?
别说了,一起在知识的海洋里呛水吧
点击下方名片,关注公众号:【小白debug】
不满足于在留言区说骚话?
加我,我们建了个划水吹牛皮群,在群里,你可以跟你下次跳槽可能遇到的同事或面试官聊点有意思的话题。就超!开!心!

文章推荐:


