
【全网首发】如果我们是那晚负责修复 B 站崩了的开发人员原创
大家好,我是 yes。
早在十几天前,我就看到了 B 站发的那篇解释一年前网站崩溃的文章。
当时的第一反应是时间过得真快,总觉得 B 站崩了仿佛在昨日,脑子里还能浮现当时热闹的微博和朋友圈的画面。
那时候我还加班加点写了一篇文章:我是小R,昨晚我好像把B站搞崩了!
根据当时的场景,我分析的原因是 CDN 出了问题,流量都直接打到后面,由于晚上流量高峰,一下子流量太大就挂了,虽然有多活,但是可能挂了之后因为又上了热搜,导致大家都想去看看热闹,于是乎雪上加霜,导致一系列联动挂了。
不过如果仅仅是这种情况应该把流量切了,然后服务起了之后一点一点放流量进来的话应该就好了,但是最后恢复时间还是比较久的,我想着应该有什么别的问题,但是咱也不是内部人员,咱也不敢乱说。
时隔一年,答案终于来了,具体原因 B 站的文章已经写的很清楚了,我这边就不再赘述,文章链接我贴文末。
而我这篇文章主要是想站在开发人员的角度来盘一盘,假如你是当晚负责修复问题模块的开发,应该怎样做?
也就是说,如果你负责的项目线上出了问题,怎样的思路才能快速止损并快速恢复?
应对服务崩溃的思路
其实不论是在 B 站还是一些小企业,当负责的项目在线上崩了或者出了什么 BUG 的时候,我相信大家的心理压力都是一样大的。
我遇到过好多次线上问题,基本上都是全神贯注,脖子梗直地盯着屏幕查问题,随着问题成功修复,整个人就像瘫了一样,感觉非常累。
在面对服务崩溃等问题的时候,精神都是高度紧张的,脑子可能都不太好使,甚至我看到过我同事手都抖着在敲键盘看问题,所以在这种场景下,我们需要足够的心理素质和准备来应对出错,这样才能快速修复问题。
及时止损
应对线上问题,我们的首要目标不是找出问题,而是及时止损。
而及时止损的最佳操作就是:重启。
我们都说重启解决万物,这句话不无道理。在非常多的场景下重启就是最快解决问题的方式,没有之一。
很多时候,重启完就好了,事后可能也找不到原因,因为触发问题的场景碰到的概率非常低,这就需要后面专门组织团队去勘察去解决。
但是当时的服务是以最快的速度止损了,如果你想着保留案发现场,想根源性找出问题,解决了之后再把服务起来,可能你公司就要倒闭了。
像 B 站当晚就是定位到 SLB 故障了,立马就重启了,不过马上又 CPU 100% 了,这个时候重启**这招就没用了。
回溯回滚
重启**没用,就只能修了。
修也不是乱修,要根据现象进行排查,比如是 CPU 100% 问题,那就通过性能分析等工具定位问题。
如果是 OOM 问题,那就分析堆栈定位问题,主要目的就是为了找到引发问题的代码,紧接着排查近期的提交记录,分析出可能产生问题的提交,接着进行回滚,最后重新打包发布。
基本上重启无效的情况用这种方式就可以解决了。
等解决了之后,再慢慢地盘出现问题的代码,经过严格的测试之后,再进行发版。
不过这里要注意,回滚代码的时候要注意上下游的影响。
我之前就遇到过这种情况,回滚了之后影响了别的服务,然后把另一个服务给搞挂了,所以即使当时情况紧急,也要谨慎处理,注意联想上下游服务,防止二次伤害。
最好的办法就是多人一起排查,一个人有时候思维会有局限性,特别是在紧张的情况下。
即使你不是这次事故的主要处理人,但如果可以话还是陪着同事一起看问题,反过来后面也让同事帮你一起看,这种方式更加高效和保险。
人多力量大不无道理。
有条件 plan B 并行
万一回滚代码没用呢?也就是说临时性修复不了!
这时候理想状态下需要有条 plan B 的线在同步执行,不过我觉得这有点属于马后炮行为。
B站的 SLB 挂了之后,回滚了几次代码还是不行,后面就新建了一组 SLB,业务用了新的 SLB 才陆续地恢复。
所以,事后复盘来看,B 站当晚最佳修复计划应该同步是安排其他人员执行新建 SLB 的操作,预防老 SLB 修复不了导致的尴尬场景。
B 站自身是说因为人员不足,就两个人,没这个能力并行。
不过我觉得正常的思路肯定只是回滚代码重新打包发布,一般出问题都是因为近期的变更导致的。
而且像我们业务应用,其实只能修,不像基础设施这种可以重建,对吧。
所以如果是业务上出问题的话,基本上没有合适的 plan B,不过这也是一个思路,在遇到问题的时候可以想想,万一有呢?
故障事发前的准备
上面说的是事故中的处理手段,其实事故前的基础设施准备非常关键。
B 站画的公网架构图只是高纬度的抽象,具体到下面还有非常多的节点。
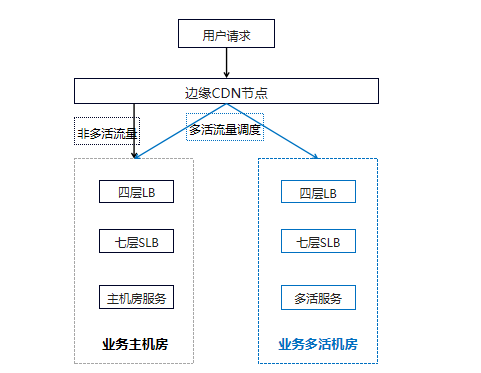
排查的关键就是快速定位到问题所在的模块,这样才好调动相关人员进行排查修复,这就涉及到监控的问题。
像 B 站就快速定位到是业务主机房的七层 SLB CPU 100%的问题,导致业务的不可用。
所以监控非常重要,它是我们在处理故障时候的眼睛。
当然,监控也非常复杂,要摊开说估计需要几篇文章,我大致讲一下监控的方向:
-
操作系统 -
缓存 -
数据库 -
消息队列 -
应用服务 -
日志
当然,如果你们的服务上了 K8S,那还需要有 K8S 的监控。
具体细分到下面还有很多,比如数据库除了一些基本要素,还需要监控连接数、线程数、锁信息、慢查询、qps等等。
想要顺畅地处理问题,还需要掌握常见的一些分析工具,比如 B 站分析 CPU 问题用的是 Linux 的 perf 命令。
当然,这些对我们开发来说可能不太熟,毕竟我们不是 SRE,不过一些基本的命令还是需要掌握的,比如 top 命令可以看进程 CPU 使用率,vmstat 看上下文切换数,dstat 可以看网络和I/O情况等。
还有基本概念,比如 CPU 相关指标里面的 us(user)、ni(nice)、sys(system)、id(idle)等等。
建议去了解一下这方面的知识,还是得有个概念的。
故障事后前的复盘
每个公司应该都会有事后复盘。
复盘产生问题的原因,流程上哪里有不足,需要对哪方面进行加强管控等等,具体就不多 BB 了。
当然,还有分锅,这个怎么说呢,该自己的还是自己的,该是别人的别愣着背了。
最后
排查问题确实不容易,特别是在已经产生资损的情况下,这需要自身实力扎实,不然直接就一个丈二和尚摸不着头脑。
说到线上问题,其实还有个混沌工程,这个工程来源于 Netflix 工程师搞得混乱猴子(Chaos Monkey)。
简单来说就好像有只上蹿下跳的猴子在给你的系统搞破坏,时不时线上系统就会出故障(自己造个猴子破坏自己的系统),所以就需要开发人员来修复,以此来模拟真实出错,从而磨炼上下游的配合能力,验证系统的恢复能力。
就是搞搞演习,自己给自己制造麻烦,强制性操练,提高系统的可靠性,有兴趣的朋友可以了解一下。
好了,今天的文章就到这了。
欢迎关注我的个人公众号:【yes的练级攻略】
💥看到这里的你,如果对于我写的内容很感兴趣,有任何疑问,欢迎在下面留言📥,会第一次时间给大家解答,谢谢!
我是yes,从一点点到亿点点我们下篇见~
B站文章:2021.07.13 我们是这样崩的

