
【全网首发】JVM性能问题的自动分析原创
文章附学习视频:https://heapdump.cn/training/course/12/36
由于许多业务开发人员对虚拟机了解很少,所以通常在遇到一些虚拟机性能问题或故障时,不得不临时抱佛脚,现学现用一些调优工具和排查方法,而这也变成为了一个有门槛,需要付出学习成本的事情,基于这个考虑,我们可以做一些简单的性能自动分析程序,直接或辅助用户快速定位一些性能问题。下面就以虚拟机参数,堆转储文件,线程Dump和GC日志这4种数据源为基础,自动分析应用程序可能出现的问题。
1 、虚拟机参数自动检测
虚拟机参数自动检测相对于内存及GC等来说比较简单,检测时不需要持续跟踪,只需要一次性获取虚拟机的启动参数即可。许多的虚拟机故障和调优都可通过调整虚拟机参数来达到目地,不过对于一般的Java开发人员来说,这并不是一项简单的工作,需要对虚拟机相关的运行原理有所了解。
我们试着自动检测一些常见错误,如下:
1.1、使用失效的虚拟机参数
如JDK8版本中使用了失效的PermSize和MaxPermSize参数.在做自动化检测时,完全可以先通过如下命令获取到虚拟机支持的参数列表:
java -XX:+PrintFlagsFinal version
所显示的参数列表不包括diagnostic或experimental相关的虚拟机参数。要在-XX:+PrintFlagsFinal的输出里看到这两种参数的信息,分别需要显式指定-XX:+UnlockDiagnosticVMOptions / -XX:+UnlockExperimentalVMOptions 。
用户配置的虚拟机参数可通过如下命令查看:
jcmd pid VM.command_line
打印的内容如下:
VM Arguments:
jvm_args: -Xms128m -Xmx1024m -XX:ReservedCodeCacheSize=512m -XX:+IgnoreUnrecognizedVMOptions -XX:+UseG1GC -XX:SoftRefLRUPolicyMSPerMB=50 -XX:CICompilerCount=2 -XX:+HeapDumpOnOutOfMemoryError -XX:-OmitStackTraceInFastThrow -ea -Dsun.io.useCanonCaches=false -Djdk.http.auth.tunneling.disabledSchemes="" -Djdk.attach.allowAttachSelf=true -Djdk.module.illegalAccess.silent=true -Dkotlinx.coroutines.debug=off -XX:ErrorFile=$USER_HOME/java_error_in_idea_%p.log -XX:HeapDumpPath=$USER_HOME/java_error_in_idea.hprof -javaagent:/media/mazhi/system2-ssd/software/ja-netfilter-all/ja-netfilter.jar=jetbrains -XX:ErrorFile=/home/mazhi/java_error_in_idea_%p.log -XX:HeapDumpPath=/home/mazhi/java_error_in_idea_.hprof -Djb.vmOptionsFile=/media/mazhi/system2-ssd/software/ja-netfilter-all/vmoptions/idea.vmoptions -Djava.system.class.loader=com.intellij.util.lang.PathClassLoader -Didea.vendor.name=JetBrains -Didea.paths.selector=IntelliJIdea2021.3 -Didea.jre.check=true -Dsplash=true
java_command: com.classloading.Main 2其中的jvm_args表示传递给虚拟机的参数,而java_command表示启动java应用时的命令,后面的2表示传递给应用程序的参数。
有了虚拟机支持的参数列表和用户配置的虚拟机参数列表后,就可以查看用户配置的虚拟机参数是否包含在列表中,如果没有,则报错。
1.2、将虚拟机参数错误配置为了程序参数
举个例子如下:
java -jar app.jar -javaagent:./agent.jar
则“-javaagent:./agent.jar”这一串参数将传递给app.jar应用的main()方法中,并不会启动代理,正确的配置应该是:
java -javaagent:./agent.jar -jar app.jar
在自动化检测的过程中,可以通过jcmd命令获取java_command信息,然后获取为应用程序传递的参数,如果这些参数是虚拟机所支持的,只要简单的进行提示即可,因为不能确定这一定是用户犯的错误。
1.3、建议配置的虚拟机参数未配置
这里列举了4个建议配置的参数:
(1)GC log参数
由于GC日志采用非阻塞式的写,所以通常不会对应用程序产生可测量的影响,我们最好将日志记录的详细一些,相关的配置参数如下:
-Xloggc:gc.log -XX:+PrintGCTimeStamps -XX:+PringGCDateStamps
其中的-Xloggc指定了垃圾收集信息写入哪个文件;而-XX:+PrintGCTimeStamps -XX:+PringGCDateStamps也是必需的,-XX:+PrintGCTimeStamps输出GC的时间戳(以基准时间的形式), -XX:+PrintGCDateStamps输出GC的时间戳(以日期的形式,如 2017-09-04T21:53:59.234+0800)。不过JDK9后GC log的参数有所变化,相关的参数都纳入了Xlog中,而且也不需要指定时间戳相关参数了,因为日志以默认形式输出。
(2)堆转储文件导出
当发生OOM时,建议自动导出堆转储文件,相关的虚拟机配置参数如下:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./
配置虚拟机崩溃时导出堆转储文件,这个文件对于我们排查OOM等异常时很重要。在配置HeapDumpPath时,最好只指定路径即可,生成的文件名类似java_pid7364.hprof,其中的数字对应着pid。如果指定了文件,而文件已经存在,反而不能写入。
(3)元空间的最大大小MaxMetaspaceSize
MaxMetaspaceSize指定JDK8+的元空间大小。默认情况下,元空间可以无限扩张。我们一般指定为256m或512m即可,因为这个空间主要存储的是类元信息,这些信息理论上来说不可能太多。除非在某些特殊情况下,如加载了大量生成的动态类,导致Metaspace空间无限制扩张,最终因为内存耗尽而发生OOM killer。
(4)加大Integer Cache的-XX:AutoBoxCacheMax参数
加大Integer Cache的-XX:AutoBoxCacheMax参数,大家可能对这个参数不熟悉,举个例子如下:
Integer a = 3;
Integer b = 3;
Integer c = 300;
Integer d = 300;
System.out.println((a==b) +" " + (c == d));运行的结果为:true false。由于我们需要的“==”比较的是对象的地址,所以a和b是同一个对象,而c和d不是同一个对象。但是如果配置了XX:AutoBoxCacheMax=500,则如上的两个比较都为true。因为JDK默认只缓存 -128 ~ +127的Integer,超出范围的数字就要即时构建新的Integer对象。Long类型也和Integer类型一样,会做缓存处理。
如上的这个虚拟机参数还需要结合一些其它信息,例如因为装箱而造成的资源浪费。
1.4、参数配置不合理
现在假设应用程序是这样的:
1、应用正常情况下很久都不发生full GC;
2、应用大量使用了NIO的direct memory,经常、反复的申请DirectByteBuffer。
那么当我们通过字节码增强检测到有调用System.gc()时,如果此时配置了虚拟机参数XX:+DisableExplicitGC,那么这个应用程序可能会报如下类似的错误:
java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:633)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:98)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:288) 所以此时就需要给用户提示,提示的3个前题条件为:
(1)有System.gc()方法在运行时被调用
(2)有DirectByteBuffer对象存在,也就是使用了direct memory
(3)配置了XX:+DisableExplicitGC参数
如上条件除了最后一个虚拟机参数,为了能更精确的判定问题,还要结合一些字节码增强,以及实例是否存在的判断。
2、堆转储文件自动检测
其实堆转储文件能够做非常多的事儿,但我们通常只是简单的拿来查看占用内存比较大的类对象,或查看实例数量比较多的类对象。下面我们基于堆转储文件来自动分析一些性能问题:
2.1、内存泄漏点自动检测
在分析堆转储文件的Eclipse MAT中有一个功能比较好用,是自动分析内存泄漏的。为了能自动分析内存泄漏,我们需要知道内存的浅堆和深堆。
浅堆(Shallow Heap):指一个对象所消耗的内存;
深堆(Retained Heap):当前对象被垃圾回收后,可以真实释放的内存大小,也就是只能通过该对象被直接或间接访问到的所有对象的集合。
举个例子如下:
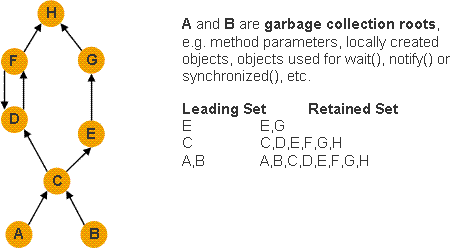
我们可以将堆中所有的对象看成一张对象图,每个对象是一个图节点,而 GC Roots 则是对象图的入口,对象之间的引用关系则构成了对象图中的有向边。假设某个对象图如上图所示,那么这个对象图的深堆(Retained Set)就如图上右边的说明文字那样。
在计算深堆时,首先要把支配树计算出来,支配树的计算是基于对象图来做的,业界已经有比较成熟的算法Lengauer Tarjan计算支配树了(这个算法可处理有向有环图),这里不再过多介绍。上图的支配树如下:
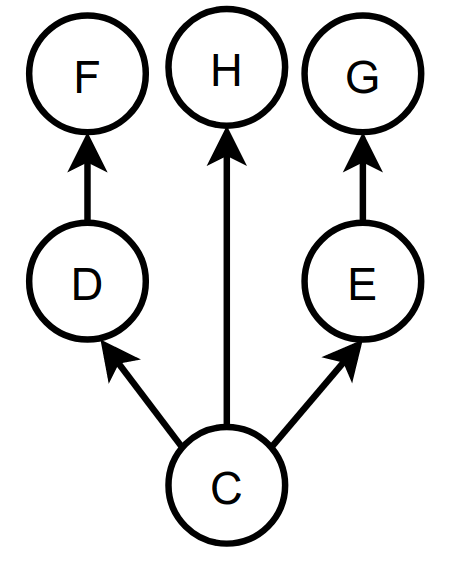
对于支配树要了解以下几点:
1、在 a 支配 b,且 a 不同于 b 的情况下(即 a 严格支配 b),如果从 a 节点到 b 节点的所有路径中不存在支配 b 的其他节点,那么 a 直接支配(immediate dominate)b。如上的支配树就是由节点的直接支配节点所组成的树状结构。
2、如果a是b的直接支配点,那么a的支配点同样也支配b,以此类推;
3、对象的引用型字段未必对应支配树中的父子节点关系。假设对象 a 拥有两个引用型字段分别指向 b 和 c,而 b 和 c 各自拥有一个引用类型字段都指向 d。如果没有其他引用指向 b、c 或 d,那么 a 直接支配 b、c 和 d,而 b(或 c)和 d 之间不存在支配关系。
现在有了支配树,我们就能自动分析可能的内存泄漏点和累积点了,在Eclipse中通常能看到类似这样的内存泄漏提示:

上图给出了内存泄漏点为org.eclipse.mat.demo.leak.LeakingQueue,而内存累积点是java.lang.Object[]这个数组。其主要原理就是先根据深堆进行排序,找出占用内存最明显的对象,如果没有特别明显的大对象,则筛选前几个比较大的对象,然后根据支配树计算出内存泄漏点和累积点,如下图所示。
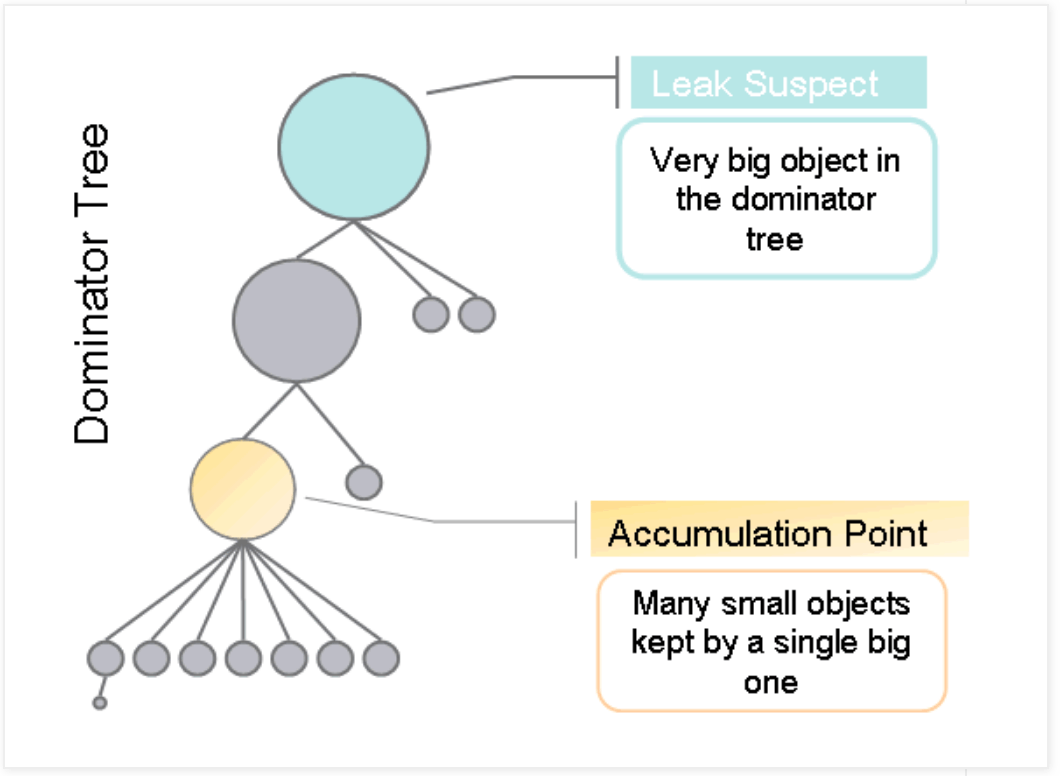
通常占用内存最大的深堆对象,其成为内存泄漏点的可能性更大一些,而累积点需要向下遍历支配树,找到一些大小明显小于直接支配点的对象。
图片来源及参考文章来自:
内存泄漏点自动分析在堆转储文件分析中比较复杂一些,其它的一些自动分析相对来说比较简单。
2.2、集合/原生数组/对象数组的使用不当
如集合/数组的使用率过低,存储的数量太多等问题。我们以ArrayList为例,在堆中遍历到所有ArrayList实例,查看每个实例的使用情况。ArrayList的定义如下:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
// ...
private transient Object[] elementData;
private int size;
// ...
}elementData数组用来存储具体的值,size为ArrayList容器中实际存储的元素数量。基于ArrayList的实现来说,至少应该自动检查如下几方面:
(1)ArrayList集合的利用率低,甚至是空的集合。先定义一个标准,比如容器的利用率不到10%时就给于提示,我们可直接读取elementData的length属性值,然后用size/length就可以得出利用率;
(2)ArrayList集合的元素过多,操作这样的集合效率会很低,尤其是做一些查找和删除等操作的时候。另外,这样的集合一旦发生扩容,很容易引起OOM,因为当前占用一大块内存,还要申请一块更大的内存。
其它的集合或数组也都可以做一些自动检测,实现原理相对简单,这里就不再过多介绍。
2.3、特定类型实例的数量
这里举3个具体的例子。
(1)等待调用finalize()方法的对象
计算需要运行finalize()方法才能释放的对象的可能大小,由于含有finalize()方法的对象不会立刻进行回收,而是存储在了一个java.lang.ref.Finalizer中,等待一个优先级比较低的Finalizer线程去执行finalize()方法,但是这个线程有时候可能没有及时执行(优先级低),有时候可能被阻塞或等待了(finalize()方法中有耗时或IO操作),这样就会导致含有finalze()方法的对象堆积,造成内存OOM。
举个例子如下:
public class Finalize {
protected void finalize() throws InterruptedException {
// 暂停1秒,模拟耗时操作
Thread.sleep(1000);
}
public static void main(String[] args) throws Exception {
while (true) {
new Finalize();
}
}
}配置虚拟机参数-Xmx100m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./后,运行一段时间会抛出如下异常:
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.lang.ref.Finalizer.register(Finalizer.java:91)
at java.lang.Object.<init>(Object.java:37)
at Finalize.<init>(Finalize.java:3)
at Finalize.main(Finalize.java:11)
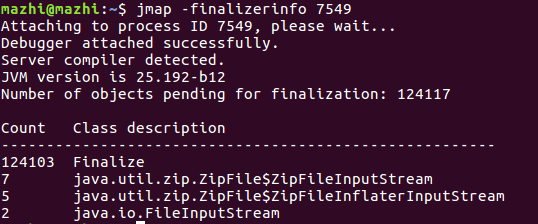
遍历堆文件来统计Finalizer类型的对象,因为在finalizer.register()方法中,所有重写finalize()方法的对象都会被封装为Finalizer对象。这些对象可能要占用一定量的内存,当内存大小或实例数量超过一定阈值就可以进行提示。分析导出的堆转储文件,如下:

以类视图查看各个类,可以看到,java.lang.ref.Finalizer类的实例数和大小都是最大的。
或者也可以通过jmap -finalizerinfo实时查看,结果如下:
(2)单例
对于一些工具类或无状态的Java对象来说,只需要一个单例即可,但是在使用过程中可能会频繁创建实例,浪费内存,此时可以给一个提示。例如XStream,这是一个实现JavaBean与XML相互转换的工具,在使用时,并不建议每次有一个转换任务都创建一个com.thoughtworks.xstream.XStream实例,而应该尽可能的复用现在的XStream实例。
(3)重复的对象
重复的对象,尤其是重复的字符串对象的出现的机率相对来说更大一些,会浪费很多的空间,这些字符串对象完全可以重用,而不是频繁的在堆中创建。当然其它重复的对象也可以进行检测。在比较对象是否相同时,需要比较对象中各个属性的值是否完全相同。
2.4、类元数据的聚合
在发生Metaspace的OOM时,应用程序通常:
- 使用了过多反射
- 使用过多的动态代理技术
- 使用了过多的
lambda
这些技术的本质就是生成了太多的类,而这些生成的类通常又会创建一个单独的类加载器来加载,我们可通过类加载器来跟踪这一类问题。例如cglib动态代理技术的实现原理就是通过生成代理类来做增强的。
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
public class MetaspaceOOM {
public static void main(String[] args) {
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Math.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy)
throws Throwable {
if (method.getName().equals("compute")) {
System.out.println("对Car.compute()方法进行增强");
return methodProxy.invokeSuper(o, objects);
} else {
return methodProxy.invokeSuper(o, objects);
}
}
});
Math m = (Math) enhancer.create();
m.compute();
}
}
static class Math {
public void compute() {
System.out.println("调用了compute()方法...");
}
}
}为了能让问题尽快浮现,我们配置虚拟机参数 -XX:MaxMetaspaceSize=10M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./,最终会看到如下异常:
...
Caused by: java.lang.OutOfMemoryError: Metaspace
...Metaspace溢出。从导出的堆转储文件查看,可以看到有大量的名称类似于MetaspaceOOM$Math$$EnhancerByCGLib$$xxxx的类,其直接父类为Math,也就是说,cglib通过生成子类对父类方法进行增强的。
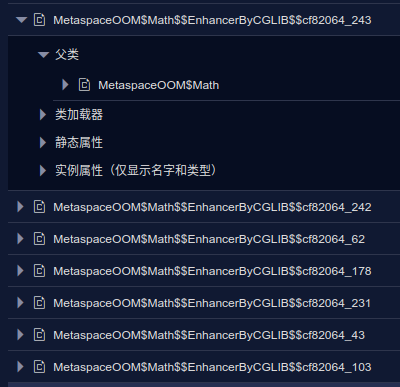
这些生成的代理类的类名通常都很相似,可以通过一定的规则聚合起来,如果超过一定量就可以进行提示了。
另外可做的事情还有:
(1)由于集合中的key需要对象类型,所以如果我们要用基本类型做为key时,需要对基本类型进行装箱,这些基本类型对象的包装类型占用的内存空间肯定要比基本类型大,所以计算了一个由于集合等原因造成装箱所浪费的空间大小;
(2)GC Root过大,例如做为GC根的某个局部变量,基引用到的对象的总大小很大时,可以给出提示;
(3)中间件使用风险,我们还能通过对象的嵌套引用关系来分析中间件的一些浅在风险,比如常见到的log4j或logback日志框架使用的问题,如:未配置异步日志落地,日志中设置了爬栈参数等等。
这里不再过多介绍,有兴趣的可自行研究。
3、线程Dump自动检测
如果我们即时分析一个线程Dump文件的内容,有哪些是我们能自动识别的呢?
3.1、死锁
在通过jstack命令导出线程堆栈时,JVM会找出所有死锁的线程,并在线程Dump中给出,例如:
class DeadLock{
private static final Object lockA =new Object();
private static final Object lockB =new Object();
public void getA(){
synchronized (lockA){
try{
Thread.sleep(5000L);
}catch (InterruptedException e){
e.printStackTrace();
}
synchronized (lockB){
System.out.println("Thread is "+Thread.currentThread().getName()+" "+", a is "+ lockA);
}
}
}
public void getB(){
synchronized (lockB){
try{
Thread.sleep(5000L);
}catch (InterruptedException e){
e.printStackTrace();
}
synchronized (lockA){
System.out.println("Thread is "+Thread.currentThread().getName()+", b is "+ lockB);
}
}
}
}
public class TestDeadLock {
public static void main(String[] args) {
DeadLock deadLock=new DeadLock();
Thread thread1=new Thread(new Runnable() {
@Override
public void run() {
deadLock.getA();
}
});
thread1.start();
Thread thread2=new Thread(new Runnable() {
@Override
public void run() {
deadLock.getB();
}
});
thread2.start();
}
}thread1在持有lockA锁的情况下等待lockB锁,而thread2在持有lockB锁的情况下等待lockA锁,这样就形成了死锁。通过jstack打印线程堆栈时会给出死锁信息,如下:
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x00007f3d740062c8 (object 0x00000000d70e3990, a java.lang.Object),
which is held by "Thread-0"
"Thread-0":
waiting to lock monitor 0x00007f3d740038d8 (object 0x00000000d70e39a0, a java.lang.Object),
which is held by "Thread-1"
Java stack information for the threads listed above:
===================================================
"Thread-1":
at DeadLock.getB(TestDeadLock.java:27)
- waiting to lock <0x00000000d70e3990> (a java.lang.Object)
- locked <0x00000000d70e39a0> (a java.lang.Object)
at TestDeadLock$2.run(TestDeadLock.java:47)
at java.lang.Thread.run(Thread.java:748)
"Thread-0":
at DeadLock.getA(TestDeadLock.java:14)
- waiting to lock <0x00000000d70e39a0> (a java.lang.Object)
- locked <0x00000000d70e3990> (a java.lang.Object)
at TestDeadLock$1.run(TestDeadLock.java:39)
at java.lang.Thread.run(Thread.java:748)
Found 1 deadlock.我们只要获取堆栈后,检测其是否有死锁信息,如果有就直接提示用户。
3.2、等待锁资源的线程数量
等待锁资源的线程数量也需要定义一个阈值,比如等待某个锁的线程多于3个时就提示用户。下面举个例子,如下:
public class LockTest {
public static void main(String[] args) throws InterruptedException {
LockTest lt = new LockTest();
new Thread() {
public void run() {
try {
lt.method();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}.start();
lt.method();
}
public synchronized void method() throws InterruptedException {
Thread.currentThread().sleep(10000000000L);
}
}
第一个调用同步的method()方法的线程在执行一个非常耗时的操作,所以一直占用锁资源,而另外一个线程调用时就会阻塞在method()方法上,通过jstack -l打印的堆栈信息如下:
"main" #1 prio=5 os_prio=0 tid=0x00007fe1c400d800 nid=0x16c9 waiting on condition [0x00007fe1ccf57000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at LockTest.method(LockTest.java:18)
- locked <0x00000000d70e0280> (a LockTest)
at LockTest.main(LockTest.java:14)
Locked ownable synchronizers:
- None
"Thread-0" #10 prio=5 os_prio=0 tid=0x00007fe1c4313000 nid=0x16de waiting for monitor entry [0x00007fe1981f0000]
java.lang.Thread.State: BLOCKED (on object monitor)
at LockTest.method(LockTest.java:18)
- waiting to lock <0x00000000d70e0280> (a LockTest)
at LockTest$1.run(LockTest.java:8)
Locked ownable synchronizers:
- None实际情况是main线程先获取了锁资源0x00000000d70e0280,导致Thread-0线程一直在等待。这样我们就能从锁资源的视角来查看线程并给出对应的线程栈。
3.3、死循环
当HashMap在多线程环境下使用时,可能产生死循环。ConcurrentHashMap由于自身的Bug也可能产生死循环,当死循环发生时,都有特定的调用堆栈。以HashMap死循环为例来介绍,HashMap在JDK1.7下在扩容时会形成链表死循环,在JDK1.8下会在链表转换树或者对树进行操作的时候会出现死循环。我们以研究JDK1.8下的死循环为例,得到可能出现的死循环的一个地方的调用栈信息如下:
"Thread-1" #13 prio=5 os_prio=0 tid=0x00007fe2a4209000 nid=0x1d1b runnable [0x00007fe28debc000]
java.lang.Thread.State: RUNNABLE
at java.util.HashMap$TreeNode.balanceInsertion(HashMap.java:2239)
at java.util.HashMap$TreeNode.treeify(HashMap.java:1945)
at java.util.HashMap$TreeNode.split(HashMap.java:2180)
at java.util.HashMap.resize(HashMap.java:714)
at java.util.HashMap.putVal(HashMap.java:663)
at java.util.HashMap.put(HashMap.java:612)
at collection.HashMapDeadCycle$MyThread.run(HashMapDeadCycle.java:68)看balanceInsertion()方法,如下:
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
x.red = true;
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
return root;
if (xp == (xppl = xpp.left)) {
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp; // 2239行
}
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else {
// ...
}
}在循环中没有调用其它方法,所以其调用栈是固定的,那么我们只需要判断当前线程是用户线程,处在运行状态并且最后一个调用栈的栈帧名称为root()即可,这样就能大概率判断准确,为了提高准确率,其实还可以多Dump几次线程栈.这里死循环指示为1824行是因为安全点的原因,在线程Dump时需要让线程进入安全点,而安全点通常在循环的尾部插入.
在循环中调用了rotateRight()方法,rotateLeft()方法,不过幸运的是死循环只是单纯发生在了2239行,调用其它方法的代码并不会走,所以也可以简单判断balanceInsertion()调用栈帧即可。假设内部还调用了其它方法,那么处理起来就没这么简单了,因为方法上也会有安全点,调用栈的栈顶不一定为balanceInsertion()方法。
另外,从一次线程Dump信息中,我们还可以统计用户线程的数量,如果用户创建了超量线程,需要给出异常提示,当前这也需要定义一个阈值,规定超过多少个线程才算线程太多。
如果我们能持续监控或一段时间内能多次Dump线程的话,我们还能检测出:
(1)线程数量不断上涨;
(2)线程的热点方法;
(3)线程的频繁创建和销毁;
(4)多次发现同一个或多个线程的调用堆栈相同,此时要重点关注,可能是死循环,资源不足等问题导致。
当前还能检测更多的问题,这里只是列举了一部分。
4、GC日志自动检测
之前在介绍虚拟机参数时提到过,建议开启GC日志。GC日志打印的日志数据包含了与Java内存管理相关的性能数据的50多个方面,我们利用这些数据能做很多的事情,如:
(1)Full GC过于频繁;
(2)STW时间过长;
(3)内存不断上涨;
(4)各内存代大小的设置是否合适;
(5)GC回收效率过低;
(6)内存分配率过大;
(7)对象晋升率过大。
当然能做的自动检测比较多,今天我们就讨论一下内存分配率和晋升率。
分配率是新创建的对象在一个时间段内所使用的内存量(通常以MB/sec为单位)。分配率可以是高度可变和突发性的。分配率的变化会增加或降低GC暂停的频率,从而影响吞吐量。但只有年轻代的 YGC 受分配速率的影响,老年代GC的频率和持续时间不受分配速率(allocation rate)的直接影响,而是受到提升速率(promotion rate)的影响。
关于分配率和晋升率,在Plumbr Handbook Java Garbage Collection中已经给出了计算的实例,我们就用它们的实例来学习一下。
4.1、分配率
在JDK1.8版本下,默认的垃圾收集器组合为Parallel Scavenge和Parallel Old。通过指定HotSpot虚拟机参数-XX:+PrintGCDetails -XX:+PrintGCTimeStamps来打印类似如下内容:
0.291: [GC (Allocation Failure) [PSYoungGen: 33280K->5088K(38400K)] 33280K->24360K(125952K), 0.0365286 secs] [Times: user=0.11 sys=0.02, real=0.04 secs]
0.446: [GC (Allocation Failure) [PSYoungGen: 38368K->5120K(71680K)] 57640K->46240K(159232K), 0.0456796 secs] [Times: user=0.15 sys=0.02, real=0.04 secs]
0.829: [GC (Allocation Failure) [PSYoungGen: 71680K->5120K(71680K)] 112800K->81912K(159232K), 0.0861795 secs] [Times: user=0.23 sys=0.03, real=0.09 secs]我们根据如上的信息通过表格来统计一些信息,如下:

计算分配率非常简单,只需要计算出YGC前后文的差值,然后除以对应的时间即可,需要提醒的是,如上表格中的Time一列的时间表示的是 当前gc发生时,虚拟机运行的时长.表格的最后一列给出了分配率的大小,我们也可以设置一个阈值,当这个分配率过大时,给出自动提示。经验表明,持续超过1GB/s的分配率几乎总是表明存在性能问题,而且这些问题无法通过调优垃圾收集器来解决)(摘自<<Java性能优化>>一书)。
4.2、晋升率
下面计算一下晋升率,使用同样的数据来绘制一个表格,如下:

从上面可以看出,平均晋升率为92MB/sec,峰值为140.95MB/sec。(第一次 promoted = heap存活对象的大小 - young存活对象的大小;第N次为 promoted = 第N次的old generation存活大小 - 第N-1次的Old Generation存活对象的大小)
同分配率一样,我们可以设置一个阈值,当超过阈值时进行提醒,也可以根据阈值晋升粗略计算一下FGC发生的频率等。



