
Linux 网络IO 优化篇 : 一种本机网络 IO 方法,让你的性能翻倍!转载
第一篇:基本原理篇:什么是IO,为什么 I/O 会经常被阻塞?
第二篇:Linux 网络IO 优化篇 : 一种本机网络 IO 方法,让你的性能翻倍!
第三篇:网络IO 实战篇 :Java电商系统:重大事故!IO问题引发线上20台机器同时崩溃
第四篇:网络 IO 高级篇:一次有趣的 Docker 网络问题排查
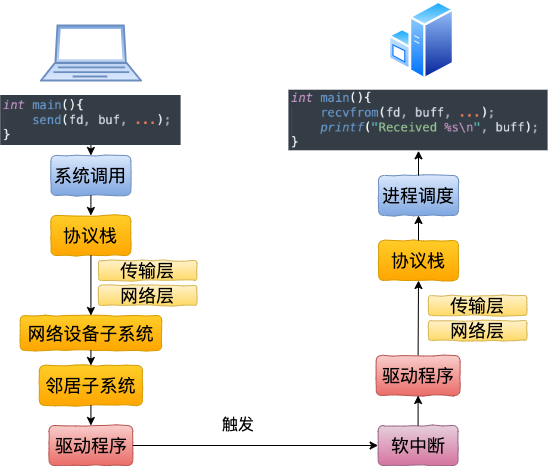
在本机网络 IO 中,我们讲到过基于普通 socket 的本机网络通信过程中,其实在内核工作流上并没有节约太多的开销。该走的系统调用、协议栈、邻居系统、设备驱动(虽然说对于本机网络 loopback 设备来说只是一个软件虚拟的东东)全都走了一遍。其工作过程如下图
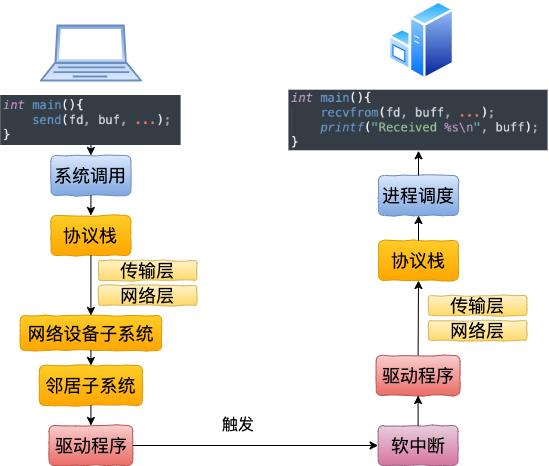
那么我们今天来看另外一种本机网络 IO 通信方式 -- Unix Domain Socket。看看这种方式在性能开销上和基于 127.0.0.1 的本机网络 IO 有没有啥差异呢。
本文中,我们将分析 Unix Domain Socket 的内部工作原理。你将理解为什么这种方式的性能比 127.0.0.1 要好很多。最后我们还给出了实际的性能测试对比数据。
相信你已经迫不及待了,别着急,让我们一一展开细说!
正文
一、使用方法
Unix Domain Socket(后面统一简称 UDS) 使用起来和传统的 socket 非常的相似。区别点主要有两个地方需要关注。
第一,在创建 socket 的时候,普通的 socket 第一个参数 family 为 AF_INET, 而 UDS 指定为 AF_UNIX 即可。
第二,Server 的标识不再是 ip 和 端口,而是一个路径,例如 /dev/shm/fpm-cgi.sock。
其实在平时我们使用 UDS 并不一定需要去写一段代码,很多应用程序都支持在本机网络 IO 的时候配置。例如在 Nginx 中,如果要访问的本机 fastcgi 服务是以 UDS 方式提供服务的话,只需要在配置文件中配置这么一行就搞定了。
fastcgi_pass unix:/dev/shm/fpm-cgi.sock;
如果 对于一个 UDS 的 server 来说,它的代码示例大概结构如下,大家简单了解一下。只是个示例不一定可运行。
int main()
{
// 创建 unix domain socket
int fd = socket(AF_UNIX, SOCK_STREAM, 0);
// 绑定监听
char *socket_path = "./server.sock";
strcpy(serun.sun_path, socket_path);
bind(fd, serun, ...);
listen(fd, 128);
while(1){
//接收新连接
conn = accept(fd, ...);
//收发数据
read(conn, ...);
write(conn, ...);
}
}
基于 UDS 的 client 也是和普通 socket 使用方式差不太多,创建一个 socket,然后 connect 即可。
int main(){
sock = socket(AF_UNIX, SOCK_STREAM, 0);
connect(sockfd, ...)
}
二、连接过程
总的来说,基于 UDS 的连接过程比 inet 的 socket 连接过程要简单多了。客户端先创建一个自己用的 socket,然后调用 connect 来和服务器建立连接。
在 connect 的时候,会申请一个新 socket 给 server 端将来使用,和自己的 socket 建立好连接关系以后,就放到服务器正在监听的 socket 的接收队列中。这个时候,服务器端通过 accept 就能获取到和客户端配好对的新 socket 了。
总的 UDS 的连接建立流程如下图。
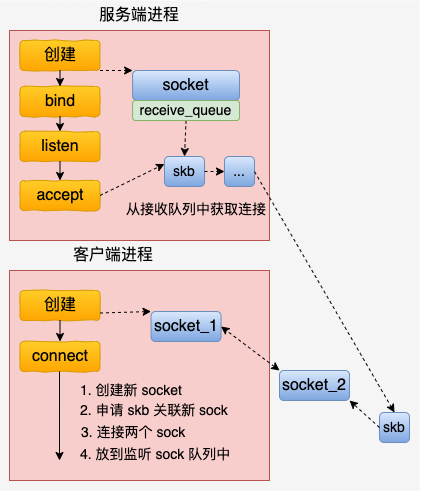
内核源码中最重要的逻辑在 connect 函数中,我们来简单展开看一下。unix 协议族中定义了这类 socket 的所有方法,它位于 net/unix/af_unix.c 中。
//file: net/unix/af_unix.c
static const struct proto_ops unix_stream_ops = {
.family = PF_UNIX,
.owner = THIS_MODULE,
.bind = unix_bind,
.connect = unix_stream_connect,
.socketpair = unix_socketpair,
.listen = unix_listen,
...
};
我们找到 connect 函数的具体实现,unix_stream_connect。
//file: net/unix/af_unix.c
static int unix_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags)
{
struct sockaddr_un *sunaddr = (struct sockaddr_un *)uaddr;
...
// 1. 为服务器侧申请一个新的 socket 对象
newsk = unix_create1(sock_net(sk), NULL);
// 2. 申请一个 skb,并关联上 newsk
skb = sock_wmalloc(newsk, 1, 0, GFP_KERNEL);
...
// 3. 建立两个 sock 对象之间的连接
unix_peer(newsk) = sk;
newsk->sk_state = TCP_ESTABLISHED;
newsk->sk_type = sk->sk_type;
...
sk->sk_state = TCP_ESTABLISHED;
unix_peer(sk) = newsk;
// 4. 把连接中的一头(新 socket)放到服务器接收队列中
__skb_queue_tail(&other->sk_receive_queue, skb);
}
主要的连接操作都是在这个函数中完成的。和我们平常所见的 TCP 连接建立过程,这个连接过程简直是太简单了。没有三次握手,也没有全连接队列、半连接队列,更没有啥超时重传。
直接就是将两个 socket 结构体中的指针互相指向对方就行了。就是 unix_peer(newsk) = sk 和 unix_peer(sk) = newsk 这两句。
//file: net/unix/af_unix.c
#define unix_peer(sk) (unix_sk(sk)->peer)
当关联关系建立好之后,通过 __skb_queue_tail 将 skb 放到服务器的接收队列中。注意这里的 skb 里保存着新 socket 的指针,因为服务进程通过 accept 取出这个 skb 的时候,就能获取到和客户进程中 socket 建立好连接关系的另一个 socket。
怎么样,UDS 的连接建立过程是不是很简单!?
三、发送过程
看完了连接建立过程,我们再来看看基于 UDS 的数据的收发。这个收发过程一样也是非常的简单。发送方是直接将数据写到接收方的接收队列里的。
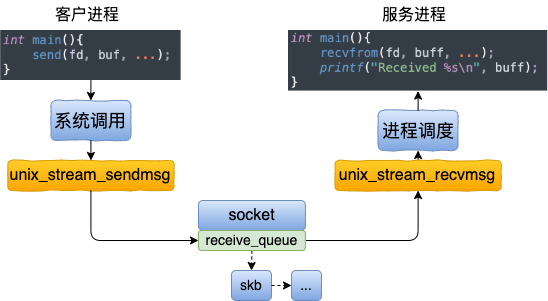
我们从 send 函数来看起。send 系统调用的源码位于文件 net/socket.c 中。在这个系统调用里,内部其实真正使用的是 sendto 系统调用。它只干了两件简单的事情:
第一是在内核中把真正的 socket 找出来,在这个对象里记录着各种协议栈的函数地址。
第二是构造一个 struct msghdr 对象,把用户传入的数据,比如 buffer地址、数据长度啥的,统统都装进去. 剩下的事情就交给下一层,协议栈里的函数 inet_sendmsg 了,其中 inet_sendmsg 函数的地址是通过 socket 内核对象里的 ops 成员找到的。大致流程如图。
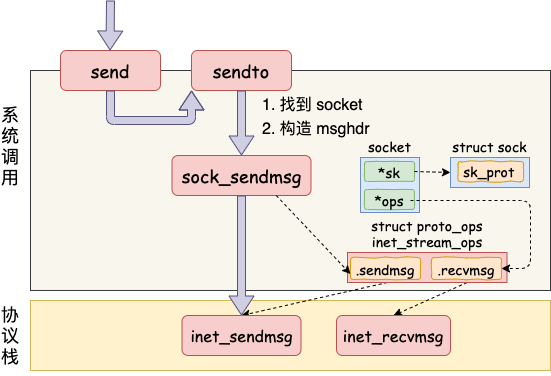
在进入到协议栈 inet_sendmsg 以后,内核接着会找到 socket 上的具体协议发送函数。对于 Unix Domain Socket 来说,那就是 unix_stream_sendmsg。我们来看一下这个函数
/file:
static int unix_stream_sendmsg(struct kiocb *kiocb, struct socket *sock,
struct msghdr *msg, size_t len)
{
// 1.申请一块缓存区
skb = sock_alloc_send_skb(sk, size, msg->msg_flags&MSG_DONTWAIT,
&err);
// 2.拷贝用户数据到内核缓存区
err = memcpy_fromiovec(skb_put(skb, size), msg->msg_iov, size);
// 3. 查找socket peer
struct sock *other = NULL;
other = unix_peer(sk);
// 4.直接把 skb放到对端的接收队列中
skb_queue_tail(&other->sk_receive_queue, skb);
// 5.发送完毕回调
other->sk_data_ready(other, size);
}
和复杂的 TCP 发送接收过程相比,这里的发送逻辑简单简单到令人发指。申请一块内存(skb),把数据拷贝进去。根据 socket 对象找到另一端,直接把 skb 给放到对端的接收队列里了,接收函数主题是 unix_stream_recvmsg,这个函数中只需要访问它自己的接收队列就行了,源码就不展示了。所以在本机网络 IO 场景里,基于 Unix Domain Socket 的服务性能上肯定要好一些的。
四、性能对比
为了验证 Unix Domain Socket 到底比基于 127.0.0.1 的性能好多少,我做了一个性能测试。在网络性能对比测试,最重要的两个指标是延迟和吞吐。我从 Github 上找了个好用的测试源码:https://github.com/rigtorp/ipc-bench。我的测试环境是一台 4 核 CPU,8G 内存的 KVM 虚机。
在延迟指标上,对比结果如下图。
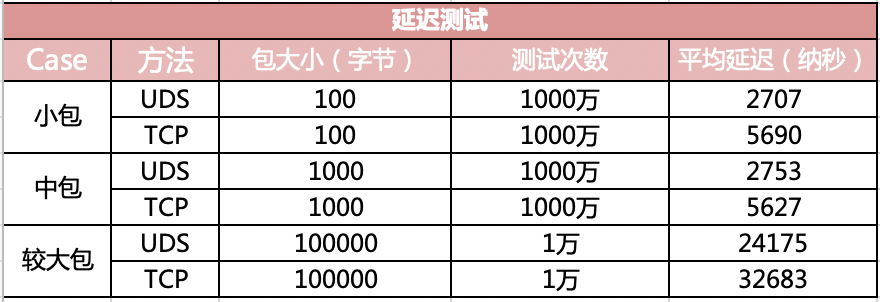
可见在小包(100 字节)的情况下,UDS 方法的“网络” IO 平均延迟只有 2707 纳秒,而基于 TCP(访问 127.0.0.1)的方式下延迟高达 5690 纳秒。耗时整整是前者的两倍。
在包体达到 100 KB 以后,UDS 方法延迟 24 微秒左右(1 微秒等于 1000 纳秒),TCP 是 32 微秒,仍然高一截。这里低于 2 倍的关系了,是因为当包足够大的时候,网络协议栈上的开销就显得没那么明显了。
再来看看吞吐效果对比。
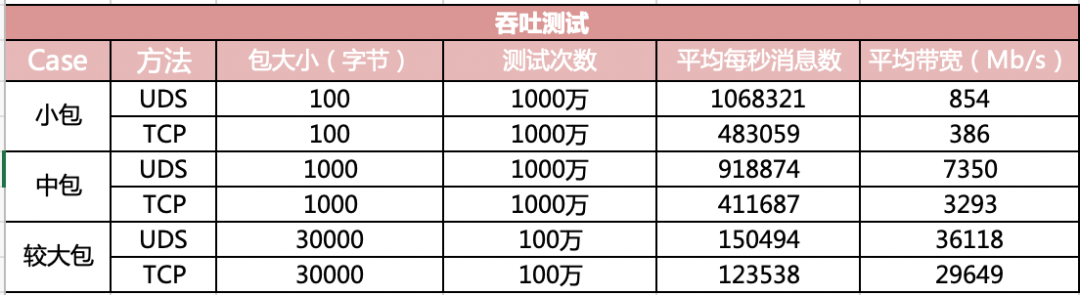
在小包的情况下,带宽指标可以达到 854 M,而基于 TCP 的 IO 方式下只有 386 M。数据就解读到这里。
五、总结
本文分析了基于 Unix Domain Socket 的连接创建、以及数据收发过程。其中数据收发的工作过程如下图。
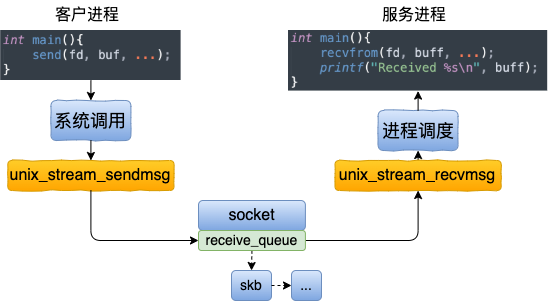
相对比本机网络 IO 通信过程上,它的工作过程要清爽许多。其中 127.0.0.1 工作过程如下图。
我们也对比了 UDP 和 TCP 两种方式下的延迟和性能指标。在包体不大于 1KB 的时候,UDS 的性能大约是 TCP 的两倍多。所以,在本机网络 IO 的场景下,如果对性能敏感,飞哥建议你使用 Unix Domain Socket。
💥看到这里的你,如果对于我写的内容很感兴趣,有任何疑问,欢迎在下面留言📥,会第一次时间给大家解答,谢谢!


