译者注
该原文是Ayende Rahien大佬业余自己在使用C# 和 .NET构建一个简单、高性能兼容Redis协议的数据库的经历。
首先这个"Redis"是非常简单的实现,但是他在优化这个简单"Redis"路程很有趣,也能给我们在从事性能优化工作时带来一些启示。
原作者:Ayende Rahien
原链接:https://ayende.com/blog/197441-A/high-performance-net-building-a-redis-clone-****ysis
另外Ayende大佬是.NET开源的高性能多范式数据库RavenDB所在公司的CTO,不排除这些文章是为了以后会在RavenDB上兼容Redis协议做的尝试。大家也可以多多支持,下方给出了链接
RavenDB地址:https://github.com/ravendb/ravendb
正文
在上一篇文章中,我用最简单的方式写了一个Redis克隆版本。它能够在我们的测试实例上每秒命中近100万个查询(c6g.4xlarge,使用16个内核和64 GB内存)。在我们更深入地进行优化之前,值得了解CPU时间实际花费在哪里。我在探查器下运行服务器,以查看各种代码所耗费的成本。
我喜欢使用dotTrace作为探查器,同时使用它的跟踪模式,因为它返回的数据中给了我各个模块、类和代码的执行时间以及调用次数。通常,我可以仅从这些细节中推断出很多关于系统性能的原因。
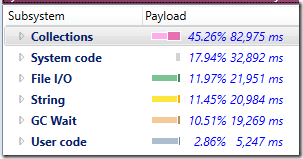
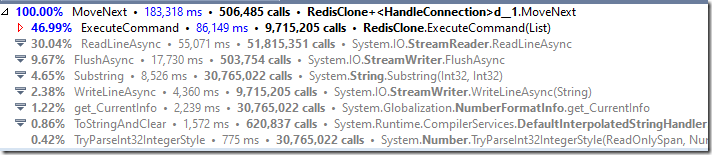
看看下面的统计数据,这是连接实际处理过程中的成本细分:
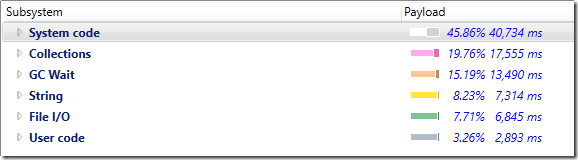
展开耗费CPU最多的System code,如下所示:
您可以看到FlushAsync()方法耗费的CPU做多。我们在这里做一个假设,当我们调用StreamWriter的FlushAsync()方法时,同样会刷新底层的流。深入研究下调用栈,似乎我们在TCP层面为每个命令都都进行了分包,这样效率是很低的。
如果我们将StreamWriter的AutoFlush属性改为true,这将导致它立即向网络流中写入数据,但不会在TCP流上调用flush,这会让TCP流更有效的利用缓冲空间。
涉及的代码更改是删除FlushAsync()调用并初始化StreamWiter,如下所示:
using var writer = new StreamWriter(stream)
{
NewLine = "\r\n",
AutoFlush = true,
};
让我们再次运行基准测试,这将给我们(在我的开发机器上):
- 138,979.57 QPS
[13.8w/s]– 使用 AutoFlush = true - 139,653.98 QPS
[13.9w/s]– 使用 FlushAsync
基本上,这两种选择都不怎么样。原因如下所示:
设置为True的AutoFlush不仅会刷新当前流,还会刷新基础流,从而使Stream他们处于相同的Position。
问题是我们需要刷新流,否则我们在内存中缓冲的结果数据不会发送给客户端。Redis基准测试在很大成都依赖管道(一次性发送多个命令),但是在实际过程中可能会收到一堆来自客户端的命令,这堆命令会写入(到输入缓冲区),然后不向客户端发送任何内容,因为输出的缓冲区并没有满。我们可以使用以下代码更改轻松地优化它:
var line = await reader.ReadLineAsync();
await writer.FlushAsync();
// 修改为以下代码
var lineTask = reader.ReadLineAsync();
if(lineTask.IsCompleted == false)
{
await writer.FlushAsync();
}
var line = await lineTask
我在这里所做的是直接写入StreamWriter,并且只有在没有更多的输入时才刷新缓冲区。这应该会大大减少包的发送次数,而且它确实做到了。再次运行基准测试可以得出以下结论:
- 229,783.30 QPS
[22.9w/s]– 使用延时刷新
我们只修改几行代码,却得到了几乎两倍的性能提升,这是令人影响深刻的。我们的想法是,缓冲更多的写入,并且不让它延时太久。如果写入足够的数据到StreamWriter缓冲区,它自己会自动的刷新。我们只会在没有其它需要读取的数据时手动刷新StreamWriter,这个操作是和读取并行进行的。
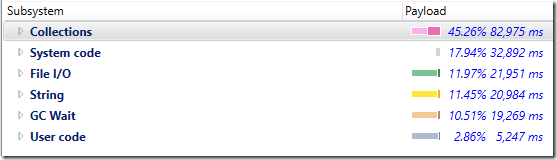
下图是新的耗时统计:
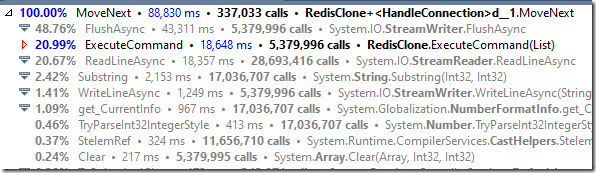
实际方法调用如下:
如果我们将其与第一次分析结果进行比较,我们可以发现一些非常有趣的数字。以前,我们为每个命令调用FlushAsync(请参阅ExecuteCommand&FlushAsync),现在我们更少调用它了。
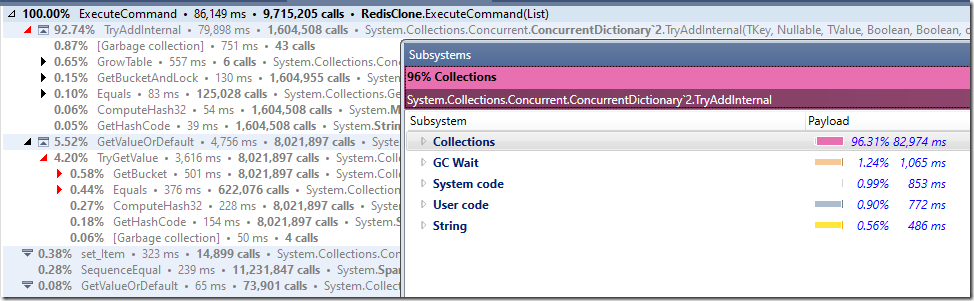
您可以看到,现在大部分时间花费都在这个系统的“业务逻辑代码”中,从子系统的细分来看,现在很多时间都花费在处理集合中。
这里的GC花费也大幅下降(~5%)。我相当确定这是因为我们使用了新的方式刷新TCP流,但我没有仔细的去检查它。
请注意,虽然字符串处理和GC需要花费大量时间,但是集合/ExecuteCommand还是占用了更多的时间。
如果我们调查一下,我们会发现:
而且这非常有趣。
主要是因为主要成本在TryAddInternal中。我们知道在这种情况下存在很高的争用,但92%的时间直接花在了这个方法上吗?让我们看一下代码,它在做什么就会很明显:
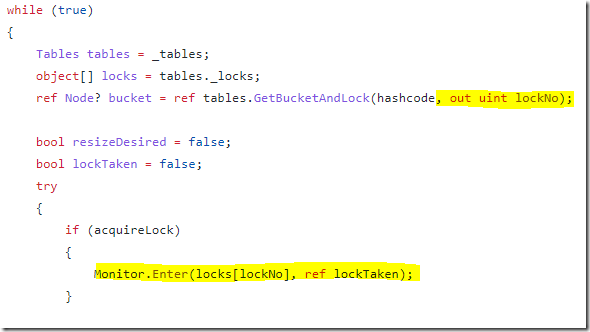
ConcurrentDictionary对锁之间的调用进行分片。锁的数量由我们默认拥有的CPU内核数量定义。我们的的并发越多,我们就越能从增加分片数量中获益。我尝试将其设置为1024,并在分析器下运行它,这给我带来了几个百分点的改进,但并不是很多。很有价值,但不是我期望的水平。
现在,我们需要找出如何在让集合操作变得更快,但我们还必须考虑总体GC成本以及字符串处理细节。在下一篇文章中会有更多关于这一点的信息。