
一次线上 FGC 问题排查,最后问题竟然是这个!转载
导语
线上的虚拟机出现了回滚的问题,通过一步步排查发现竟然是Metaspace的问题,本篇详细解读了对FGC问题的排查过程。
1.背景
先介绍下背景。服务部署在弹性云上面。弹性云是一种动态可伸缩的服务器,底层是通过docker的方式创建的虚拟机而不是物理机。
本次发布的应用 Maybach 共五台机器,分为3批发布,第一批和第二批各一台机器,第三批3台机器。
2.现象描述
1、14:34分开始发布第一批机器,14:35第一批机器部署成功。
2、14:45发布第二批机器,14:46发布成功。
登录已经发布的两台线上机器查看,服务正常运行(进程还在),且能正常打印请求log(能正常接收服务),调用方无明显异常,业务数据无明显异常,无业务监控报警。
3、14:58发布最后一批机器。
4、14:59第三台(最后一批第一台)机器发布成功。
5、15:01第四台(最后一批第二台)机器发布成功。
6、15:02最后一台机器发布成功。
7、15:02加油订单支付成功率 BI一级报警。
8、15:04SRM新导购、油站检索、门店列表、门店详情标红成功率下降延迟增高
9、15:06调用方反馈刚发布的服务全部连接超时。
这个时候刚发布的系统已经线上全挂了。接下来就是回滚了。
回滚的时候又出现了问题,导致整个回滚过程花了半个小时,也就是说线上服务全挂半个小时,15:31终于回滚成功,造成了不少的资损,不过这就是另外一件事了。
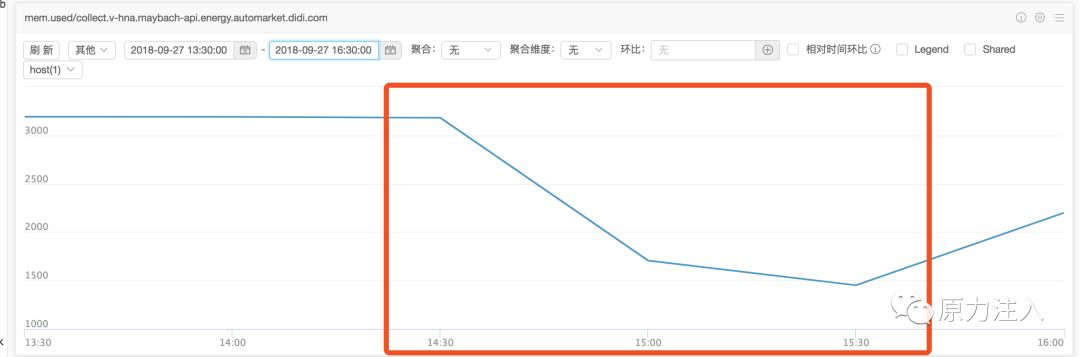
事后查看发布之后那段时间内的机器监控,以第一台机器为例:
内存使用情况:
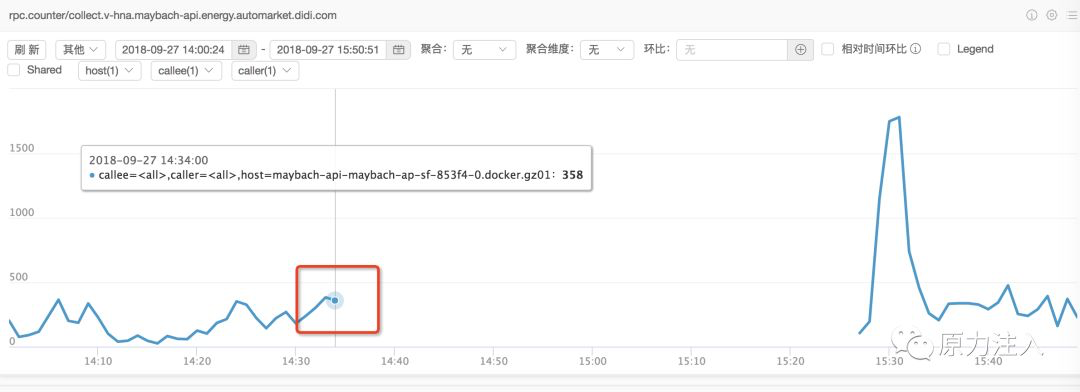
rpc调用统计:
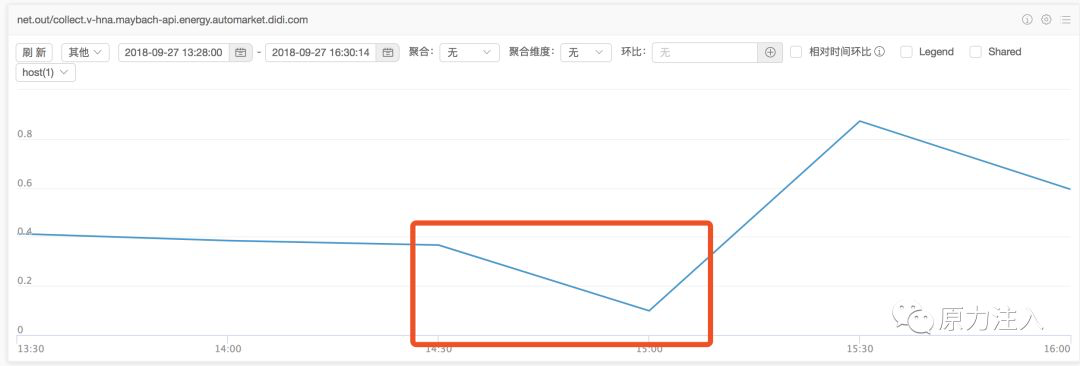
流出流量:
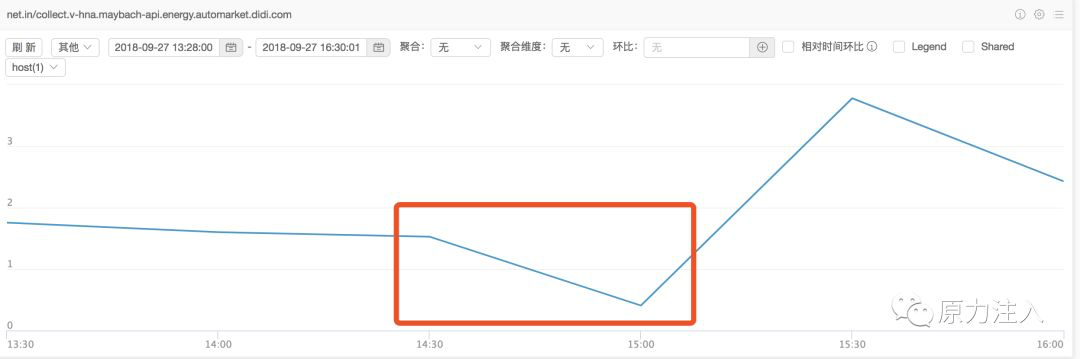
请求流量:
3. 排查分析
既然这次上线之后引起了故障,肯定得看下代码的改动点,通过mr记录发现这次上线了如下的改动点:

初步估计跟修改 jvm 参数有关,既然如此的话,第一反应应该是去查看GC日志,但是由于 maybach 没有配置 gc.log,且没有配置相应的 jvm 监控,没办法查看故障发生时候的 gc 情况,这个方法行不通,那就想办法复现吧。
在预发环境部署有问题的代码,很容易就可以复现了。
首先使用 top 命令查看机器的系统情况:
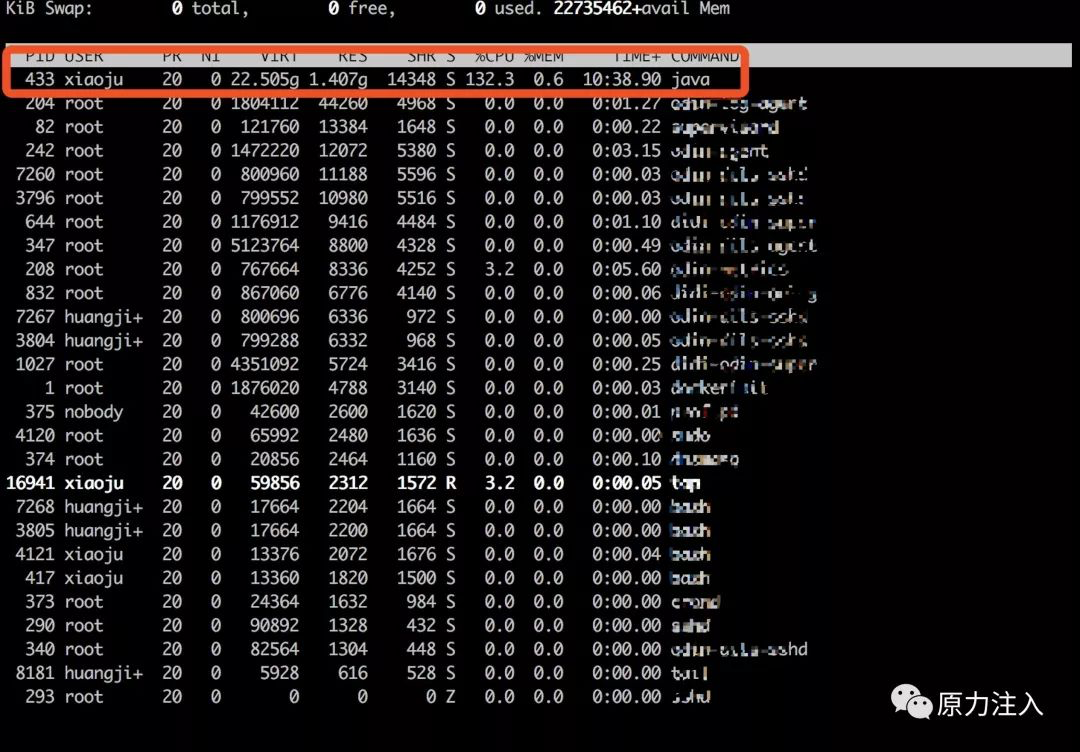
可以看到我们的服务(pid=433)占用了大量的cpu,进一步查看是哪个线程在占用cpu,使用top -H -p433查看结果如下:
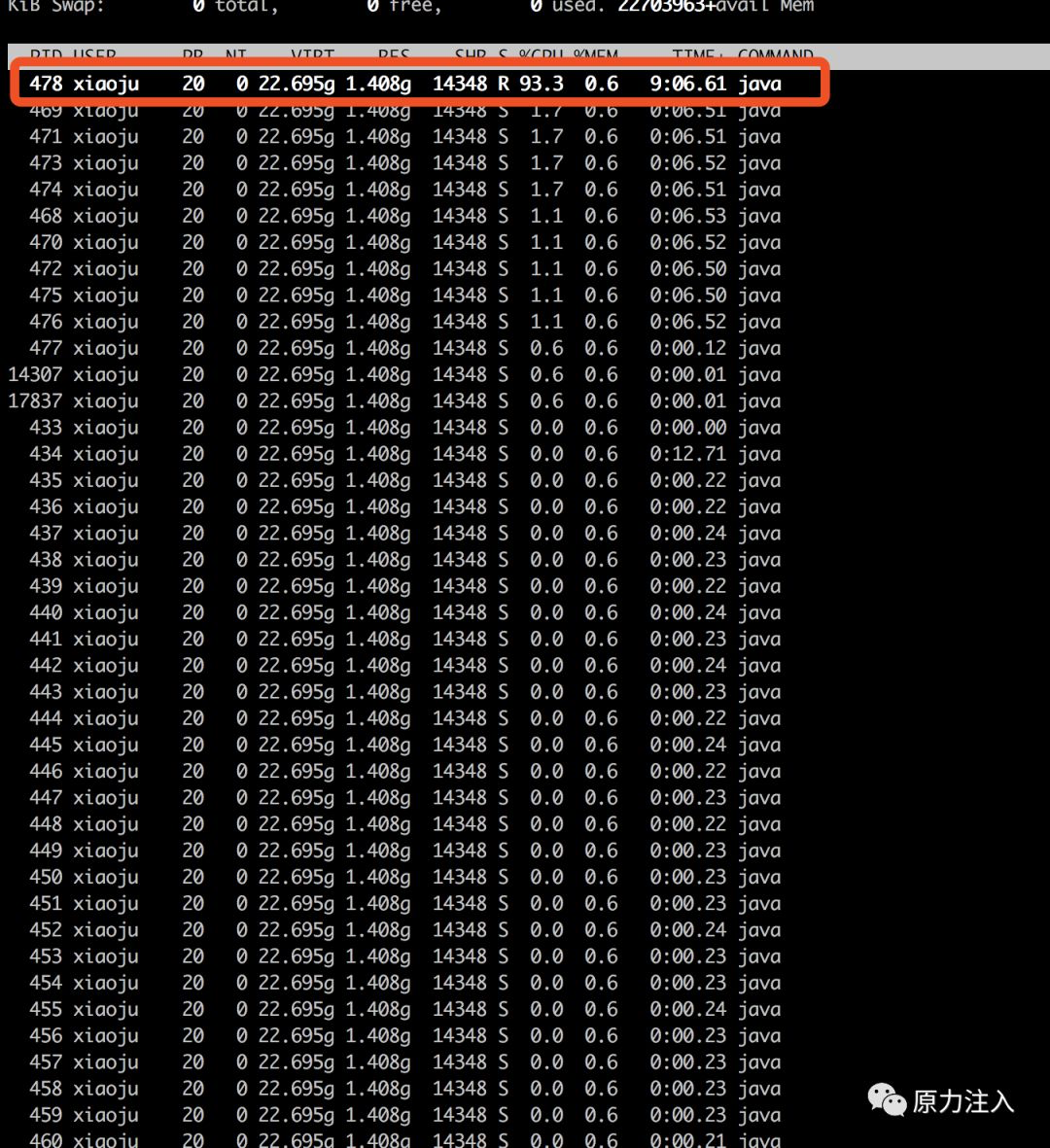
可以看到pid尾478的线程在占用cpu,转换成十六进制为1de,使用命令查看线程堆栈情况,找到nid=0x1de的线程
"VM Thread" os_prio=0 tid=0x00007f95f825b800 nid=0x1de runnable
"Gang worker#0 (Parallel GC Threads)" os_prio=0 tid=0x00007f95f801c800 nid=0x1b3 runnable
"Gang worker#1 (Parallel GC Threads)" os_prio=0 tid=0x00007f95f801e000 nid=0x1b4 runnable
"Gang worker#2 (Parallel GC Threads)" os_prio=0 tid=0x00007f95f8020000 nid=0x1b5 runnable
"Gang worker#3 (Parallel GC Threads)" os_prio=0 tid=0x00007f95f8022000 nid=0x1b6 runnable
"Gang worker#4 (Parallel GC Threads)" os_prio=0 tid=0x00007f95f8023800 nid=0x1b7 runnable
"Gang worker#5 (Parallel GC Threads)" os_prio=0 tid=0x00007f95f8025800 nid=0x1b8 runnable
"Gang worker#6 (Parallel GC Threads)" os_prio=0 tid=0x00007f95f8027800 nid=0x1b9 runnable
..........
JNI global references: 10200
可以看到,”VM Thread”就是该cpu消耗较高的线程,查看相关文档我们得知,VM Thread是JVM层面的一个线程,主要工作是对其他线程的创建,分配和对象的清理等工作的。从后面几个线程也可以看出,JVM正在进行大量的GC工作。这里的原因已经比较明显了,即大量的GC工作导致项目运行缓慢。
继续查看jvm的gc情况,如下图所示:
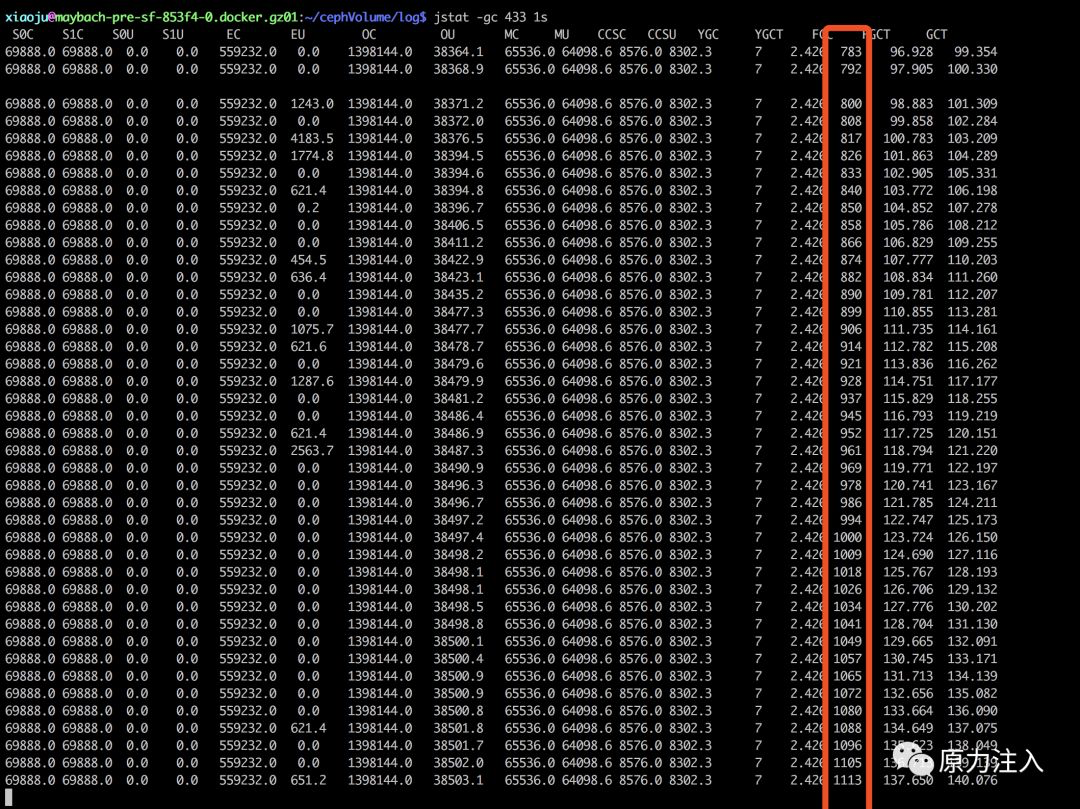
这里已经很明了了,可以清晰的看到,jvm 一直在 fgc 。
从上面那张图也可以看到,发生 fgc 的时候,新生代,老年代实际上占用的内存并不多,反倒是Metaspace,总共内存是 65536 k,目前已经使用了64098k,且 jvm 设置了-XX:MaxMetaspaceSize=64,即 Metaspace 最大可使用内存空间为64m,这个时候已经使用了97%,如果继续增大,就会发生fgc。
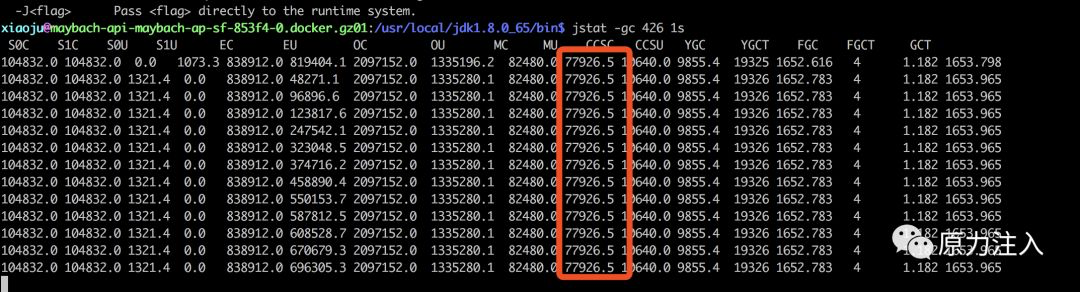
上面这张图是线上正常的时候 Metaspace 使用的大小保持在76m左右,是大于64m的,所以每次来了请求之后,Metaspace就会超过64m,这个时候jvm就会忙于fgc,造成stw,以至于调用方超时。
故障原因已清晰明了:由于本次上线设置了Metaspace最大能使用的大小为64m,Metaspace使用空间只要超过64m就会发生fgc,而这个应用Metaspace正常使用大小为76m左右,导致jvm一直忙于fgc造成stw现象而无法去处理请求,导致线上请求超时。
现在需要解释两个问题:
为什么在第三批机器发布前调用方没有异常报警?也没有业务异常报警?
为什么第三批机器发布完成之后全线连接超时?
先来看一张图,这张图展示了整个发布上线过程中的整体的流量变化情况
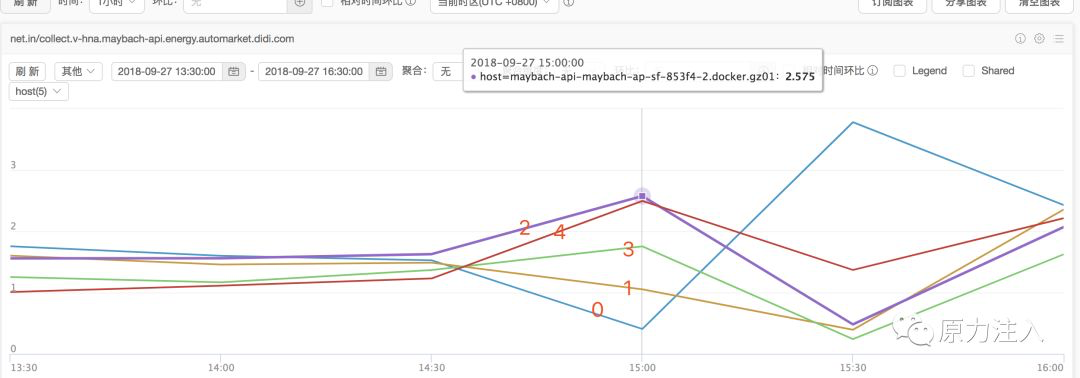
可以看到,第一二批机器发布之后,打到这两台机器上面的流量大幅减少(而且发布的时候正好是业务低峰期,本身流量就不多),另外三台未发布的机器的流量整体大幅增长(相对之前的流量)。
现在来解释第一个问题:为什么在第三批机器发布前调用方没有异常报警?也没有业务异常报警?
从图中可以看到,前两批机器发布之后,大部分流量都流向了还未发布的三台机器,只有较少部分流量会流向已经发布的两台机器,这个时候这两台机器所有的请求都会超时,但是这对整体业务影响不大,所以并没有业务异常报警。而且调用方配置的报警策略是每秒有超过十个的异常才报警,这个时候流量很少,并没有达到这个报警阈值,所以调用方也没有收到接口异常报警。
继续解释第二个问题:为什么第三批机器发布完成之后全线连接超时?
第三批机器全部发布完成之后,流向这三台机器的流量大幅降低,且这三台机器上的请求会全部超时(jvm一直处于stw状态)。大部分的流量都流向了第一台机器,本来这个时候第一台机器的所有请求都会超时,大幅流量打过来,全部超时。所以这个时候线上所有请求都会超时,导致全线挂掉。
4. 其他:关于Metaspace
Metaspace是Java8中引入的用来替代PermGen(永久带)的一块内存区域,其与永久带一个最明显的区别就是Metaspace使用的是本地内存而不是堆内存,因此,Metaspace的大小仅受限于机器本身的内存大小。
下面几个JVM参数跟Metaspace有关:
- -XX:MetaspaceSize:默认20.8M左右,主要是控制Metaspace GC发生的初始阈值,也是最小阈值。
- -XX:MaxMetaspaceSize:最大空间,默认是没有限制的。
- -XX:MinMetaspaceFreeRatio:在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集。
- -XX:MaxMetaspaceFreeRatio:在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集。
更多思考
经过排查竟然发现是Metaspace的问题,更多jvm相关的知识大家可以阅读以下内容加深阅读:

