
微医对于webpack5持久化缓存优化的实践转载
导语
1、公司的云his静态项目代码量巨大,依赖的npm包大概有100个,打包一次大概要14分钟;
2、自研的hammer工具的本地打包虽然能提升部署时间,但是依赖开发的手动操作;
3、用来存放本地构建产物的服务器容量满了,所以为了正常使用本地打包功能,还得定期去清理服务器上的老文件,不够方便。
所以对于webpack的优化势在必行,本文将从webpack5出发详解webpack5的持久化缓存实践。
解决思路
1、node版本提升 8.x -> 12.x
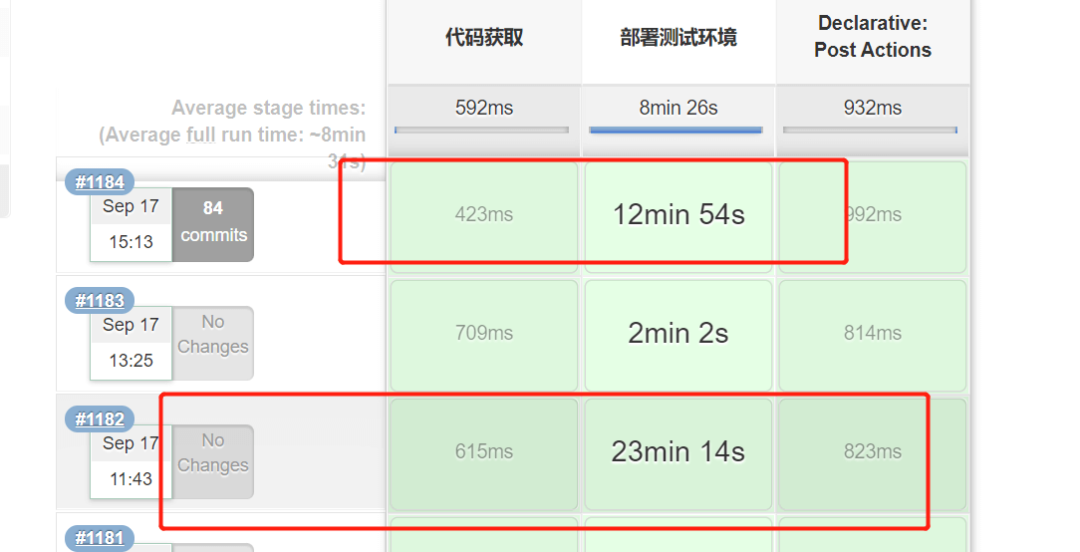
2、利用webpack5的持久化缓存提升构建效率速度大幅度提升,快了7倍。
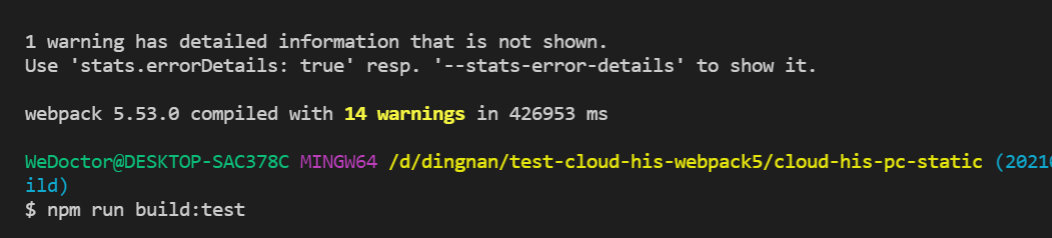

3、使用基于rust开发的swc替代babel,测试的构建速度提升一分钟半左右,因生态不成熟,不能上生产。
关键代码
module.exports = {
...
cache: {
// 将缓存类型设置为文件系统,默认是memory
type: 'filesystem',
buildDependencies: {
// 更改配置文件时,重新缓存
config: [__filename]
}
},
optimization: {
// 值为"single"会创建一个在所有生成chunk之间共享的运行时文件
runtimeChunk: 'single',
moduleIds: 'deterministic',
},
}webpack 在入口 chunk 中,包含了某些 boilerplate(引导模板),特别是 runtime 和 manifest。这些代码如果不被单独抽离会导致即使没有代码改动,打包出来的文件名仍然会改变,导致无法命中缓存。webpack4中使用HashedModuleIdsPlugin来生成hash值作为模块id,在webpack5中已经不需要了,moduleIds: 'deterministic',是用来保证模块的id不会随着解析顺序的变化而变化,生产环境默认开启。
缓存的方式(从构建层面来讲)
webpack V4
- cache-loader:建议在开销较大的loader前加,比如babel-loader、vue-loader等;
- dll:对不经常改变版本的依赖(react、lodash),单独生成动态链接库(bundle),提高构建速度,需要DllPlugin 、DllReferencePlugin 搭配使用,通过引用 dll 的 manifest 文件来把依赖的名称映射到模块的 id 上,之后再在需要的时候通过内置的 __webpack_require__ 函数来 require 他们,推荐在开发模式下使用
webpack V5
- 文件系统缓存,配置方式见上面的关键代码,作用是将Webpack运行时存在于内存中的那些缓存,不是loader的产物,更不是dll,根据Webpack运行环境的不同,在dev开发时依旧使用MemoryCachePlugin,而在build时使用IdleFileCachePlugin。dev/build的二次编译速度会远超cache-loader
一些原理浅谈
Webpack 5 令人期待的持久缓存优化了整个构建流程,原理依然还是那一套:当检测到某个文件变化时,根据依赖关系,只对依赖树上相关的文件进行编译,从而大幅提高了构建速度。官方经过测试,16000 个模块组成的单页应用,速度竟然可以提高 98%!其中值得注意的是持久缓存会将缓存存储到磁盘。
对于一个持续化构建过程来说,第一次构建是一次全量构建,然后它会将相关产物序列化缓存在磁盘中(serialize)。后续构建具体流程可以依赖于上一次的缓存进行:读取磁盘缓存 -> 校验模块 -> 解封模块内容。因为模块之间的关系并不会被显式缓存,因此模块之间的关系仍然需要在每次构建过程中被校验,这个校验过程和正常的 webpack 进行分析依赖关系时的逻辑是完全一致的。
对于 resolver 的缓存同样可以持久化缓存起来,一旦 resolver 缓存经过校验后发现准确匹配,就可以用于快速寻找依赖关系。如果 resolver 缓存校验失败的情况,将会直接执行 resolver 的常规构建逻辑。
缓存的安全性设计
unsafeCache
在webpack 4.x的构建过程中基于timestamp比对策略的一种cache方式,它有两个维度,resolve(解析器)的unsafeCache和module(模块)的unsafeCache。如果同时开启,那么从入口文件开始,webpack通过resolve规则解析所有的依赖文件,将模块之间的依赖关系和解析后的文件内容保存起来,并存储依赖的最后变更时间(timestamp),一旦发现相同引用,返回缓存。
而webpack 5.x版本已经放弃了这种缓存策略,默认只针对开启cache选项并且是node_modules下的依赖才开启unsafeCache,判断是否有文件系统序列化后的文件信息来判断是否需要重新构建。
safeCache
模块间的依赖关系被基于内容对比的算法(contentHash)被记录下来,并存入到ModulGraph的class中的weakmap,相比于依赖时间戳的方式更可靠。
缓存的容量限制
除了需要考虑缓存的安全性,缓存的容量限制也不能忽视,缓存不可能无限叠加,这里就涉及到经典的LRU cache算法(Least Recently Used 最近最少使用)。
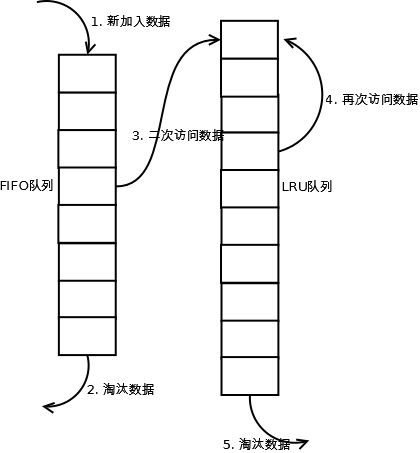
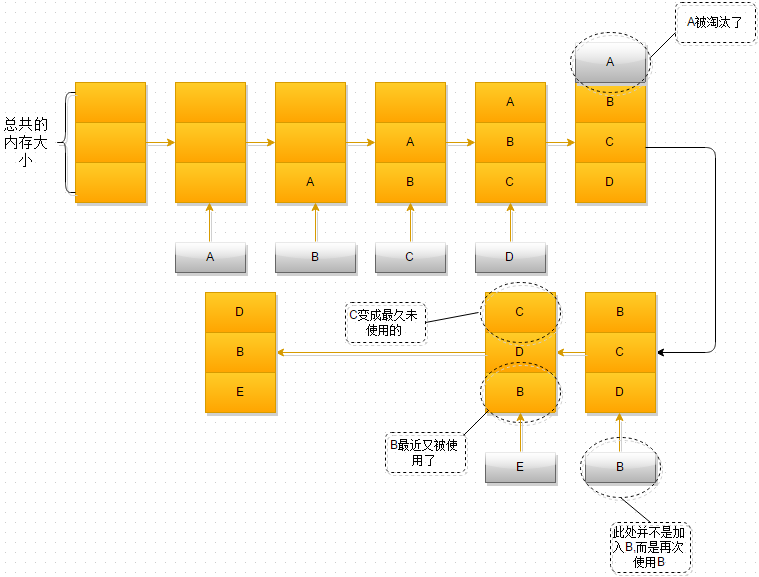
单向链表 添加、删除节点O(1),查找O(n)
双向链表加哈希表结合体 O(1)
LRU分析
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
LRU算法的改进方案
redis使用的改进算法LIRS、LRU-K等,感兴趣的同学自行查阅

