
ThreadDump堆栈分析原创
最近在进行一些系统问题追踪分析,顺便翻了翻以前的笔记和书籍,突然发现了以前写的 ThreadDump分析笔记(一)解读堆栈
),阿哈哈哈,好吧,这次顺便补个二。线程堆栈是我们排查问题常用的一种数据,具有很高的价值。但是线程堆栈打印出来是贼拉多的,上一次已经把基础概念说了,今儿就来叨叨下应该怎么看这玩意。
线程堆栈可以干嘛
线程堆栈主要是反映了当前系统线程正在干什么,堆栈可以从几个角度来分析
局部堆栈信息(就是每个线程的详细栈信息)
记录了每一个线程调用的层次关系,当前线程正在执行哪个函数,当前的线程状态是什么, 当前线程持有哪些锁,在等待哪些锁。
堆栈的统计信息(每个线程栈都会有一个统计数据)
可以看出锁的竞争状态,是不是有很多锁竞争,是不是有死锁,大部分线程处于什么状态,线程总数等。
多次堆栈对比信息
多次堆栈的好处就是可以形成对比,通过对比统计,你就才会发现问题所在。
例如每次打印堆栈这个线程一直处于同样的上下文中(比如一直在执行某一段代码),那就要考虑是否合理或者有瓶颈了。
例如某一个线程在多次堆栈中都在等待一个锁,那就要看看这个锁为什么不释放。
线程栈在问题分析上原理都是类似的,我们搞几个常见的问题,这几个问题基本就涵盖了生产环境经常发生的现象
死循环分析(多次堆栈对比信息)
代码出了BUG导致死循环,会明显拉高CPU,这时候就可以通过上面所讲的多次对比的方法进行可疑线程寻找,具体步骤如下:
- 使用jstack pid > pid.dump 导出第一次线程栈文件
- 等几十秒在重读导出第二个dump 文件
- 对比两个文件,排除掉WAITING和SLEEPING 状态的数据,因为这两种状态是不消耗CPU的
- 找出这一段时间内一直活跃的线程,如果相同的线程处于相同的上下文,那这个就要作为重点排查对象。结合代码来查看线程所执行的上下文是否属于应该长期运行的代码。
如果对比完后没有发现可以线程,那就需要考虑下CPU过高是否是因为内存设置不合理,比如是否没有设置元空间大小而导致频繁full gc,是否新生代太小导致大批量对象晋升导致的频繁GC,从而导致CPU过高。
CPU消耗分析
死循环会导致CPU 过高,这是一种BUG。但在大多数情况下,有很多CPU密集型的逻辑计算也会拉高CPU。这些问题分析起来可能会微微不太方便,因为单纯通过线程栈这一种信息是不够了,我们需要借助linux的一些小命令。
都知道我们的应用是以进程的方式运行在linux中,每个进程内又包含了很多的线程,在java 中我们使用的是。在linux中,我们可以使用top 命令查看cpu 占比。而需要知道的是linux中的本地线程(LWPID)是和java 线程一一对应的,在top显示的是10进制的线程ID,而在线程栈中的nid用16禁制来表示。 (其中涉及的知识点 内核线程KLT、轻量级进程LWP、用户线程UT可以看一下)
具体分析步骤如下:
- top -Hp pid 来获取当前该进程内所有线程的统计数据,PID就是线程ID(LWPID),这个ID对应这java thread dump 内的nid(native thread id),nid 是16进制的,所有如图PID=221 就等于 nid=0xdd,可以使用printf “%x\n” 221 来转换ID
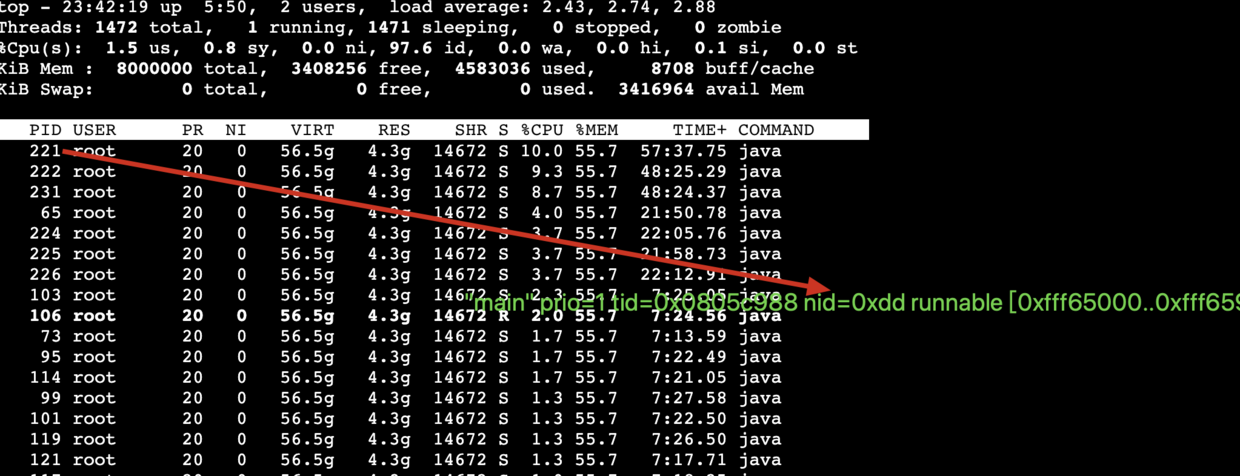
- 在java 线程栈中搜索nid=0xdd
如果找到的对应的线程PID正在执行java代码,那说明该java代码导致cpu过高,如:
"Thread-444" prio=1 tid=0xa4853568 nid=0xdd runnable [0xafcf7000..0xafcf8680]
//当前正在执行的代码是纯Java代码
at org.apache.commons.collections.ReferenceMap.getEntry(Unknown Source)
at org.apache.commons.collections.ReferenceMap.get(Unknown Source)
如果找到找到的PID 正在执行行Native code ,那说明导致CPU过高问题代码在JNI调用中,如:
"Thread-609" prio=5 tid=0x01583d88 nid=0xdd runnable [7a680000..7a6819c0]
//CheckLicense是Native方法,说明导致CPU过高的问题代码在本地代码中。
at meetingmgr.conferencemgr.Operation.CheckLicense(Native method)
at meetingmgr.MeetingAdapter.prolongMeeting(MeetingAdapter.java:171)
这种定位方式基本可以一次命中问题所在,不管什么原因导致的CPU 过高都可以排查出来,这种方式消耗小,生产环境非常是适合使用。
资源不足分析
系统资源不足犹如一条高速公路中间一截变成了羊肠小道,所有就算其他地方在宽也没有用,这就是木桶效应。比如dubbo 链路中某一服务提供者数据库连接不够了,那就会产生资源竞争,请求该资源的线程都会被阻塞或者挂起,系统设计差一点的就有可能造成系统雪崩。所以说系统资源不足和系统瓶颈是同一类问题。
如果系统资源不足,就会有大量的线程等待资源,打印线程栈就会发现这个特征,那就说明该资源就是系统瓶颈。此时打印线程栈,会发现大量线程停在同一个方法调用上。
例如:堆栈大量的http-1-Processor线程都停止在org.apache.commons.pool.impl .GenericObjectPool.borrowObject上面,说明大量的线程正在等待该资源。这就说明了该系统 资源是瓶颈。
http-8082-Processor84" daemon prio=10 tid=0x0887c000 nid=0x5663 in Object.wait()
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Object.java:485)
at org.apache.commons.pool.impl.GenericObjectPool.borrowObject(Unknown Source)
- locked <0x75132118> (a org.apache.commons.dbcp.AbandonedObjectPool)
at org.apache.commons.dbcp.AbandonedObjectPool.borrowObject()
- locked <0x75132118> (a org.apache.commons.dbcp.AbandonedObjectPool)
at org.apache.commons.dbcp.PoolingDataSource.getConnection()
at org.apache.commons.dbcp.BasicDataSource.getConnection(BasicDataSource.java:312)
at dbAccess.FailSafeConnectionPool.getConnection(FailSafeConnectionPool.java:162)
at servlets.ControllerServlet.doGet(ObisControllerServlet.java:93)
导致资源不足的原因结合堆栈信息判断有可能如下几个方面:
-
连接池配置不够导致的
-
系统当前并发突然增大导致资源耗尽
-
资源占用太久不释放导致耗尽,SQL语句不恰当没有命中索引,或者没有索引导致的数据库访问太慢
-
资源用完后,在某种异常情况下,没有关闭或者回池,导致可用资源泄漏或者减少,从而导致资源竞争
资源不足在系统的表现上来看就是性能问题,往往系统会越来越慢,最后导致不能正常响应。
锁链分析
先说一点,死锁的两个线程或多个线程是不消耗CPU的。只有死循环,并且循环内代码都是CPU密集型操作,才有可能造成CPU100%的使用率,像socket或者数据库等IO操作是不怎么消耗CPU的。
锁链不是死锁,有的时候打印出的堆栈,很多线程在等待不同的锁,有的锁竞争可能是由于另一个锁对 象竞争导致,这时候要找到根源到底在哪。如下堆栈信息,等待锁0xbef17078的线程有40多个,等待0xbc7b4110有10多个。
"Thread-1021" prio=5 tid=0x0164eac0 nid=0x41e waiting for monitor entry[...]
at meetingmgr.timer.OnMeetingExec.monitorExOverNotify(OnMeetingExec.java:262)
- waiting to lock <0xbef17078> (a [B) //等待锁0xbef17078
at meetingmgr.timer.OnMeetingExec.execute(OnMeetingExec.java:189)
at util.threadpool.RunnableWrapper.run(RunnableWrapper.java:131)
at EDU.oswego.cs.dl.util.concurrent.PooledExecutor$Worker.run(...)
at java.lang.Thread.run(Thread.java:534)
"Thread-196" prio=5 tid=0x01054830 nid=0xe1 waiting for monitor entry[...]
at meetingmgr.conferencemgr.Operation.prolongResource(Operation.java:474)
- waiting to lock <0xbc7b4110> (a [B) //等待锁0xbc7b4110
at meetingmgr.MeetingAdapter.prolongMeeting(MeetingAdapter.java:171)
at meetingmgr.FacadeForCallBean.applyProlongMeeting(FacadeFroCallBean.java:190)
at meetingmgr.timer.OnMeetingExec.monitorExOverNotify(OnMeetingExec.java:278)
- locked <0xbef17078> (a [B) //占有锁0xbef17078
at meetingmgr.timer.OnMeetingExec.execute(OnMeetingExec.java:189)
at util.threadpool.RunnableWrapper.run(RunnableWrapper.java:131)
at EDU.oswego.cs.dl.util.concurrent.PooledExecutor$Worker.run(...)
at java.lang.Thread.run(Thread.java:534)
"Thread-609" prio=5 tid=0x01583d88 nid=0x280 runnable [7a680000..7a6819c0]
at java.net.SocketInputStream.socketRead0(Native method)
at oracle.jdbc.ttc7.Oall7.recieve(Oall7.java:369)
at net.sf.hiberante.impl.QueryImpl.list(QueryImpl.java:39) |
at meetingmgr.conferencemgr.Operation.prolongResource(Operation.java:481)
- locked <0xbc7b4110> (a [B) //占有锁0xbc7b4110
at meetingmgr.MeetingAdapter.prolongMeeting(MeetingAdapter.java:171)
at meetingmgr.timer.OnMeetingExec.execute(OnMeetingExec.java:189)
at util.threadpool.RunnableWrapper.run(RunnableWrapper.java:131)
at EDU.oswego.cs.dl.util.concurrent.PooledExecutor$Worker.run(...)
at java.lang.Thread.run(Thread.java:534)
-
看到有40多个线程再等待锁0xbef17078,首先找到已经占有这把锁的线程,即"Thread-196"
-
看到"Thread-196"占有了锁0xbef17078,但又在等待锁<0xbc7b4110>,那么此时需要再找出 占有<0xbc7b4110>这个锁的线程,即"Thread-609"
-
那么占有锁<0xbc7b4110>的线程是问题的根源,下一步就要查到底为什么这个线程长时 间占有这个锁。可能的原因是持有这把锁的线程正在执行的代码性能比较低,导致锁占用时间过长。
线程堆栈不能分析什么
线程堆栈定位问题,只能定位在当前线程上留下痕迹的问题,如死锁、挂起等因为锁导致的系统性能问题。但对于不留痕迹的问题,就无能为力了。比如:
- 线程泄漏,为何没有被合理的回收
- 线程并发导致的BUG,这种问题在线程堆栈中没有任何痕迹,所以这种问题线程堆 栈无法提供任何帮助。
- 数据库锁表的问题,问题往往是由于某个事务没有提交/回 滚,但这些信息无法在堆栈中表现出来,所以堆栈分析这类问题毫无帮助。



