
记一次CPU使用率低负载高的排查过程转载
导语:
在linux的系统维护中,可能需要经常查看cpu使用率,分析系统整体的运行情况。而监控CPU的性能一般包括以下3点:运行队列、CPU使用率和上下文切换。
对于每一个CPU来说运行队列最好不要超过3,例如,如果是双核CPU就不要超过6。如果队列长期保持在3以上,说明任何一个进程运行时都不能马上得到cpu的响应,这时可能需要考虑升级cpu。另外满负荷运行cpu的使用率最好是user空间保持在65%~70%,system空间保持在30%,空闲保持在0%~5% 。
在平时的运维工作中,当一台服务器的性能出现问题时,通常会去看当前的CPU使用情况,尤其是看下CPU的负载情况(load average)。对一般的系统来说,根据cpu数量去判断。比如有2颗cup的机器。如果平均负载始终在1.2以下,那么基本不会出现cpu不够用的情况。也就是Load平均要小于Cpu的数量。
一、背景
历史原因,当前有一个服务专门用于处理mq消息,mq使用的阿里云rocketmq,sdk版本1.2.6(2016年)。随着业务的发展,该应用上的consumer越来越多,接近200+,导致该应用所在的ecs长时间load高,频繁报警。
二、现象分析
该应用所在的ecs服务器load长期飙高(该ecs上只有一个服务),但cpu、io、内存等资源利用率较低,系统负载参考下图:
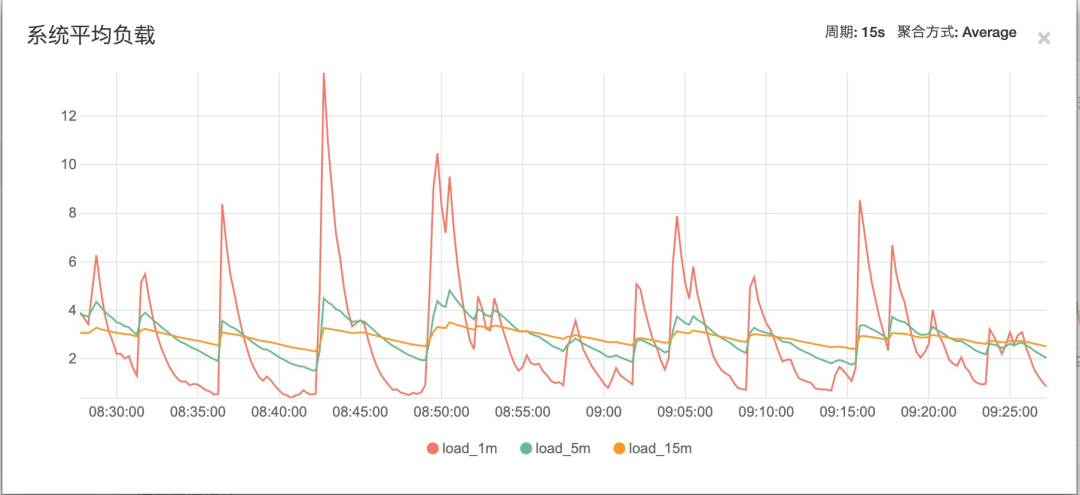
ECS配置:4核8G
物理cpu个数=4
单个物理CPU中核(core)的个数=1
单核多处理器
在系统负荷方面,多核CPU与多CPU效果类似,考虑系统负荷的时候,把系统负荷除以总的核心数,只要每个核心的负荷不超过1.0,就表明正常运行。
通常,n核cpu时,load<n,系统负载都属于正常情况。
套用以上规则:
先观察load_15m和load_5m,load基本保持在3-5之间,说明系统中长期负载保持在一个较高的量级。
再观察load_1m可以看出,波动很大,并且很多时间段内远大于cpu核心数。
短期内繁忙,中长期内紧张,很可能是一个拥塞的开始。
三、原因定位
排查导致load高的原因
tips:系统load高,不代表cpu资源不足。Load高只是代表需要运行的队列累计过多。但队列中的任务实际可能是耗cpu的,也可能是耗i/0及其他因素的
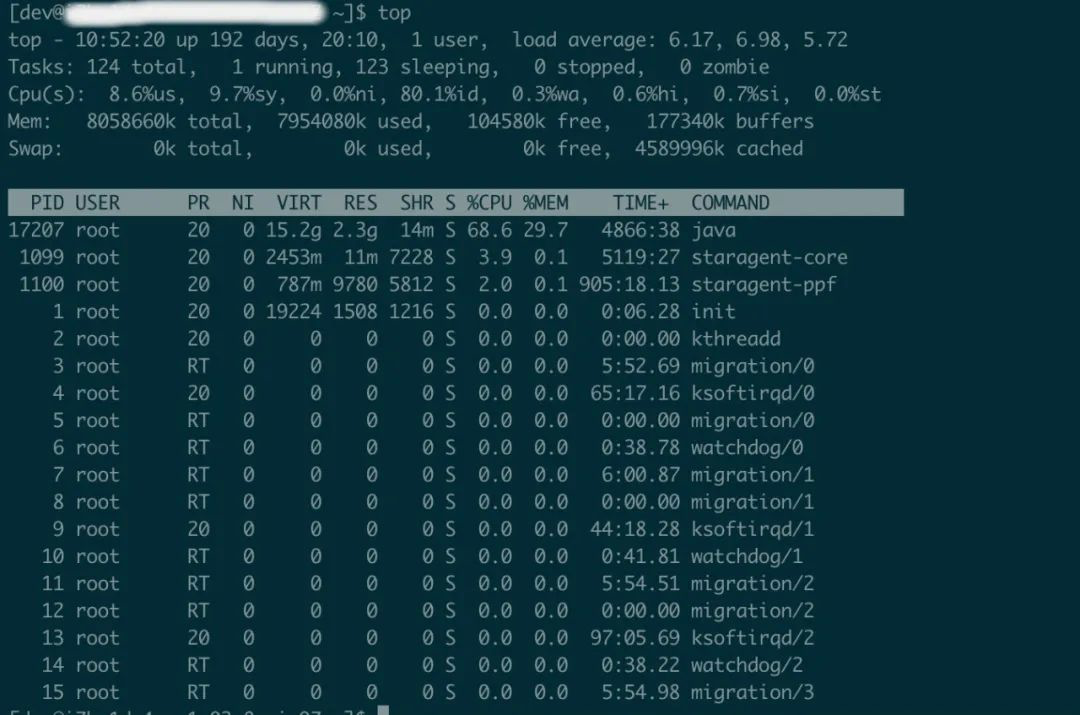
load_15,load_5,load_1均大于核心数4,超负荷运行
- 用户进程=8.6%
- 内核进程 =9.7%
- 空闲=80%
- I/O等待所占用的cpu时间百分比=0.3%
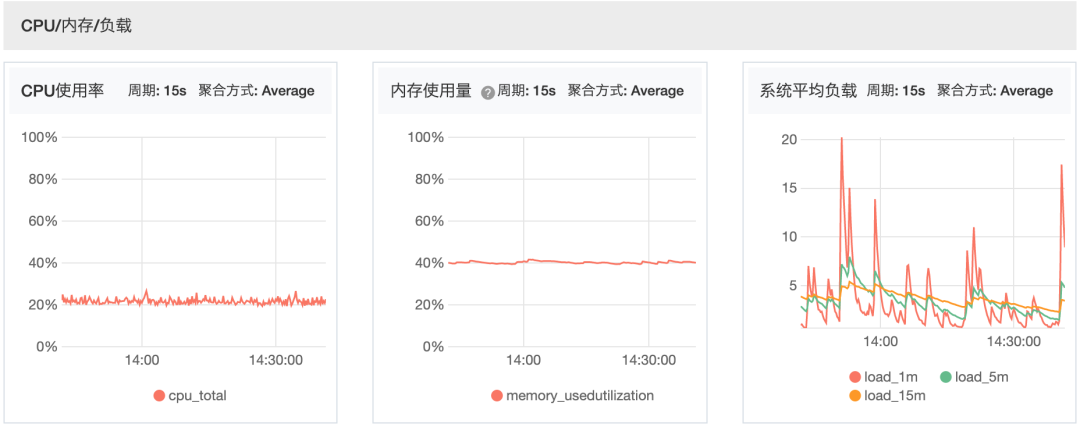
通过上图CPU、内存、IO使用情况,发现三者都不高,
CPU使用率低负载高,排除cpu资源不足导致load高的可能性。
再通过vmstat查看进程、内存、I/O等系统整体运行状态,如下图:
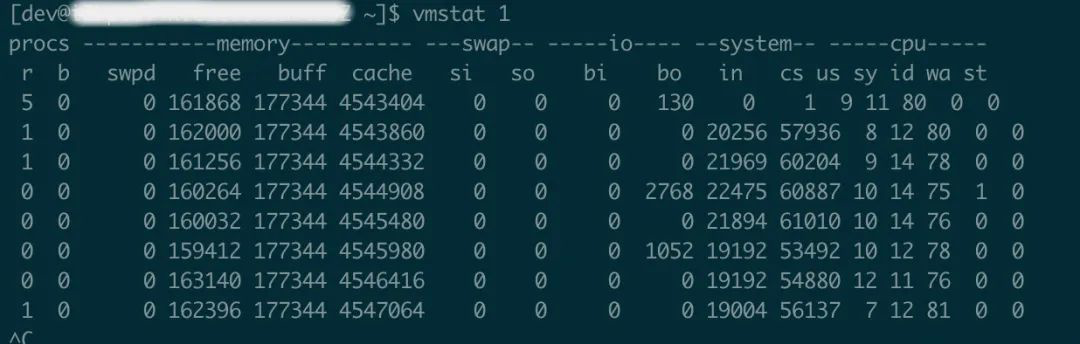
从结果上看,io的block in和block out 并不频繁,但是system的中断数(in)、上下文切换(cs)特别频繁,进程上下文切换次数较多的情况下,很容易导致CPU将大量的时间耗费在寄存器、内核栈、以及虚拟内存等资源的保存和恢复上,进而缩短了真正运行进程的时间造成load高。
CPU寄存器,是CPU内置的容量小、但速度极快的内存。程序计数器,则是用来存储CPU正在执行的指令的位置,或者即将执行的下一条指令的位置。
他们都是CPU在运行任何任务前,必须依赖的环境,因此也被叫做CPU上下文。
CPU上下文切换,就是先把前一个任务的CPU上下文(也就是CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文,到这些寄存器和程序计数器,
最后再跳转到程序计数器所指的新位置,运行新任务。
排查大方向:频繁的中断以及线程切换(由于该台ecs上只存在一个java服务,主要排查该进程)
通过vmstate只能查看总的cpu上下文切换,可通过pidstat命令查看线程层面的上下文切换信息
pidstat -wt 1(下图拉的是9s的数据,总共36w次,平均每秒4w次)
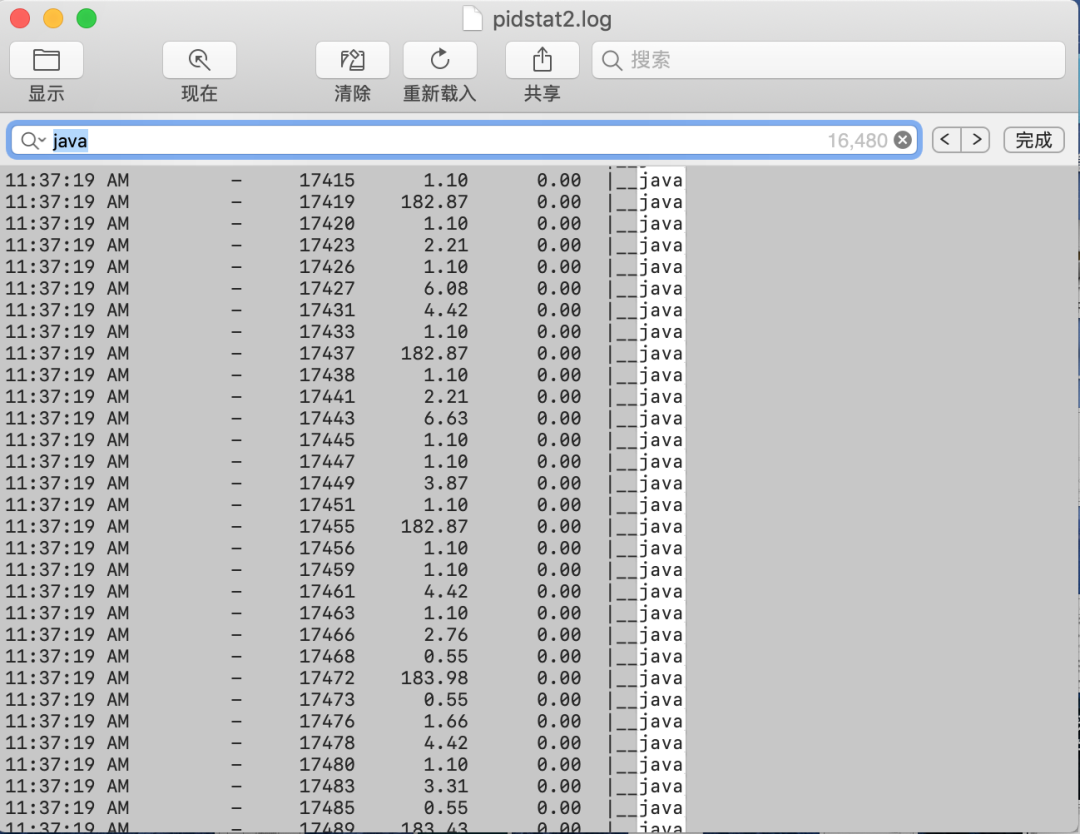
观察上图,很容易发现两个现象:
1、第一个是java线程特别多
2、第二个是很有规律的出现每秒上下文切换100+次的线程。
(具体原因后面分析)
确认一下这些java线程的来源,查看该应用进程下的线程数
cat /proc/17207/status
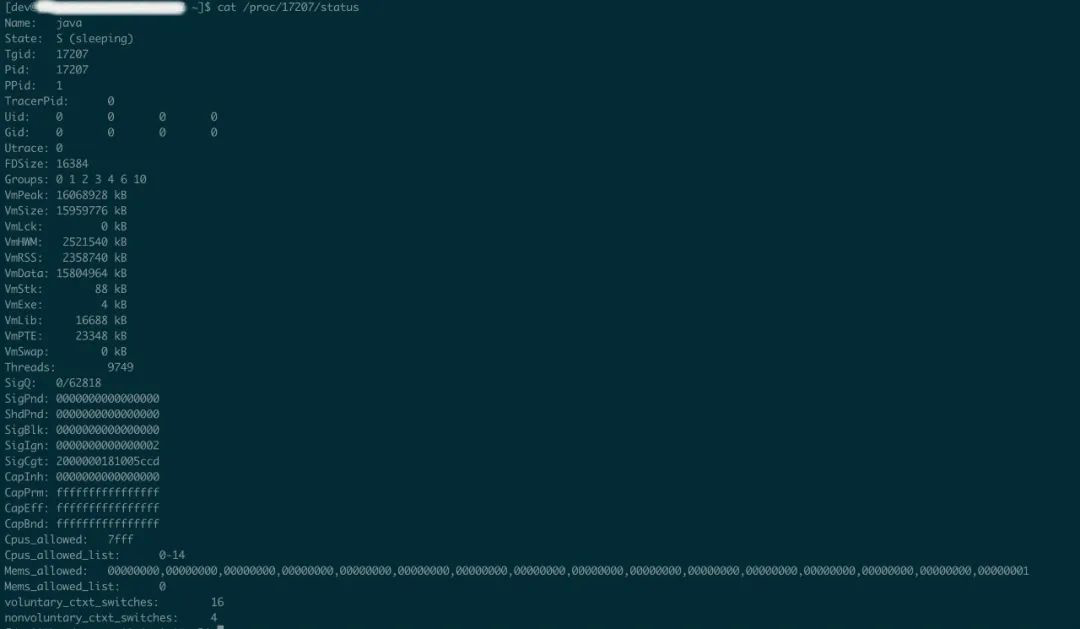
线程数9749(非高峰)
排查方向:
- 线程数过多
- 部分线程每秒上下文切换次数过高
先排查主要原因,即部分线程上下文切换次数过高
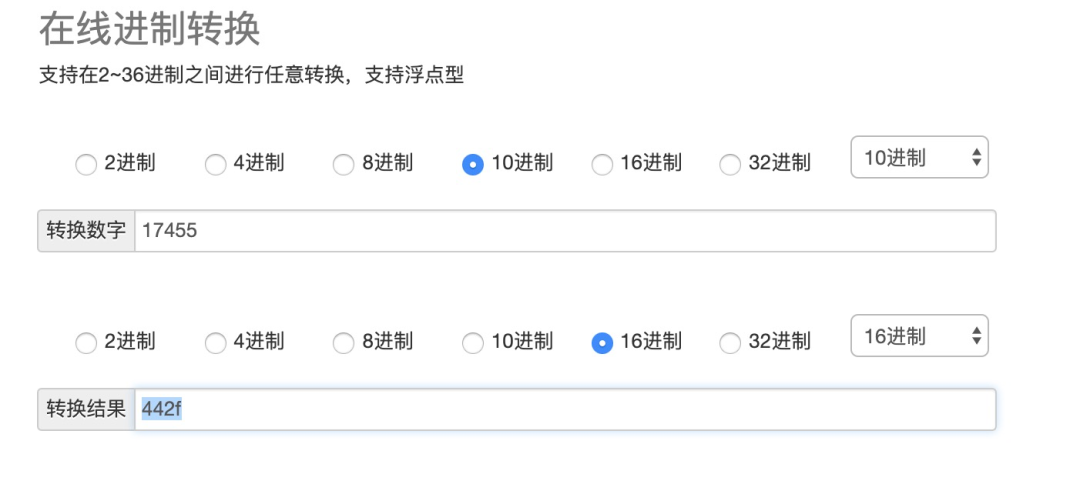
拉一下线上该进程的堆栈信息,然后找到切换次数达到100+/每秒的线程id,把线程id转成16进制后在堆栈日志中检索
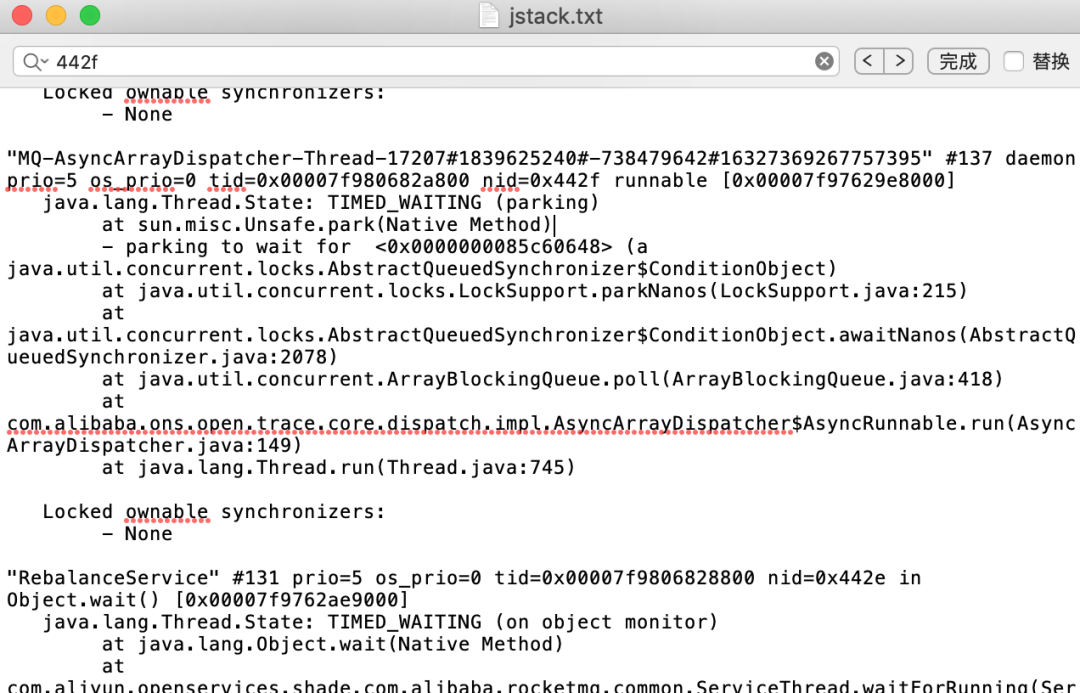
从上图可以看到进程状态TIME_WAITING,问题代码,com.alibaba.ons.open.trace.core.dispatch.impl.AsyncArrayDispatcher,多查几个其他上下文切换频繁的线程,堆栈信息基本相同。
再排查线程数过多的问题,分析堆栈信息会发现存在大量ConsumeMessageThread线程(通信、监听、心跳等线程先忽略)
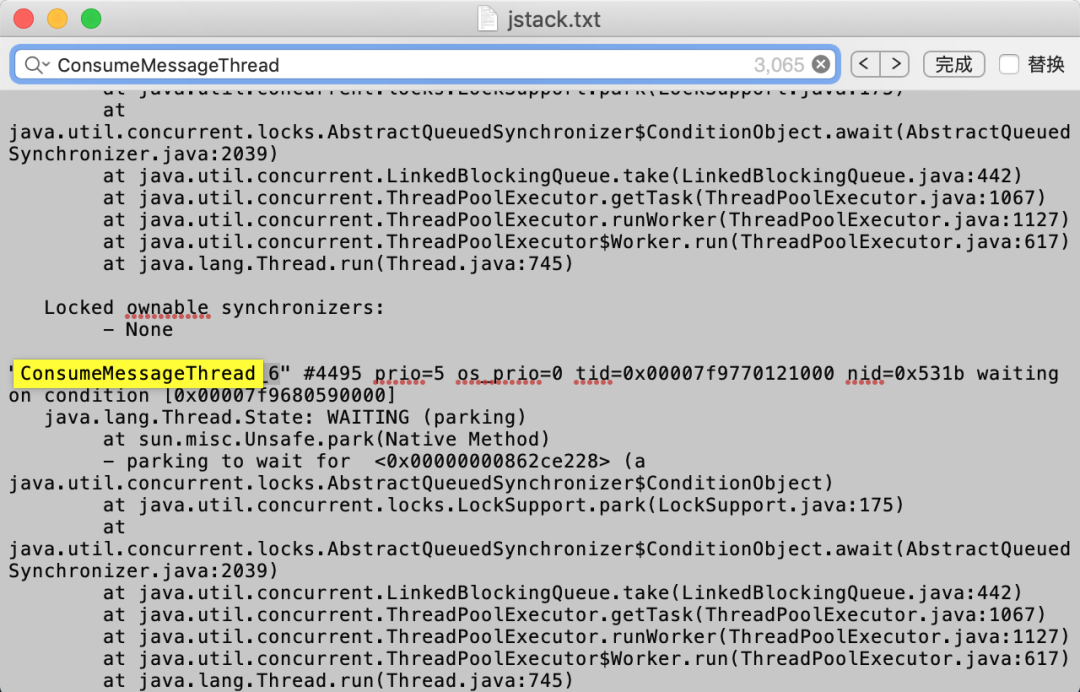
通过线程名称,在rocketmq源码中搜索基本能定位到下面这部分代码
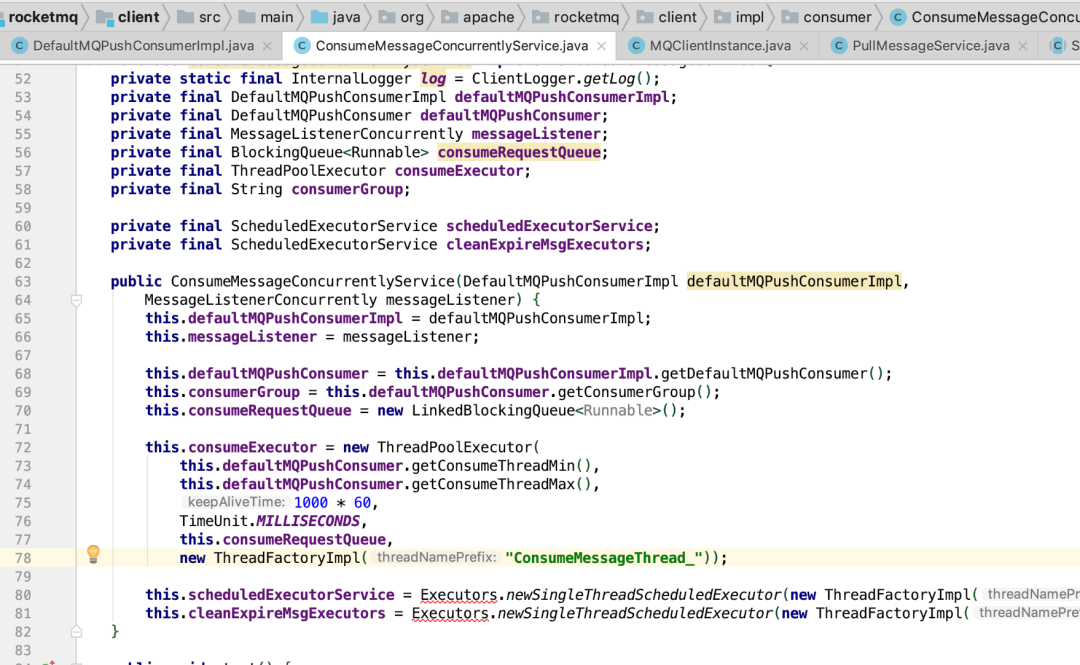
通过两段代码,基本可以定位到问题出现在mq consumer初始化以及启动的流程,后续根据代码进行分析。
四、代码分析
1、线程数过多代码层面排查,从上面代码截图可以看到,ConsumeMessageThread_由线程池进行管理,再看一下线程池的关键参数,核心线程数this.defaultMQPushConsumer.getConsumeThreadMin()、最大线程数this.defaultMQPushConsumer.getConsumeThreadMax()、无界队列LinkedBlockingQueue
ps:由于线程池队列用的LinkedBlockingQueue无界队列,LinkedBlockingQueue的容量默认大小是Integer.Max,在任务没有填满这个容量之前不会创建新的工作线程,因此最大线程数没有任何作用。
再看一下message-consumer对核心线程数以及最大线程数的配置,发现代码层面没有特殊配置,因此使用系统默认值,即下图
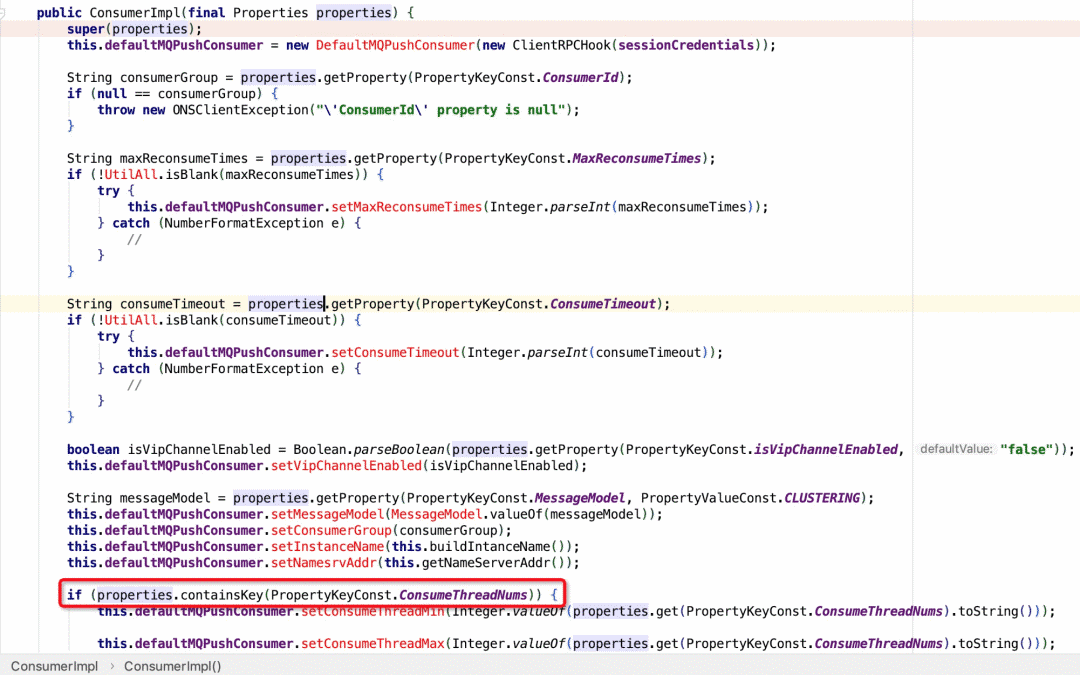

至此,大致可以定位到线程数过多的原因:
由于未指定消费线程数量(ConsumeThreadNums),采用系统默认核心线程数20,最大线程数64.每个consumer初始化的时候都会创建一个核心线程数等于20的线程池,即大概率每个consumer都会存在20个线程消费消息,导致线程数飙升(20*consumer个数),但发现这些消费线程大部分都处于sleep/wait状态,对上下文切换影响不大。
线程上下文切换次数过高代码层面排查:
在rocketmq源码中无法搜索到该段代码,该应用使用阿里云sdk,在sdk中检索,查看上下文以及调用链路,会发现这段代码属于轨迹回传模块。
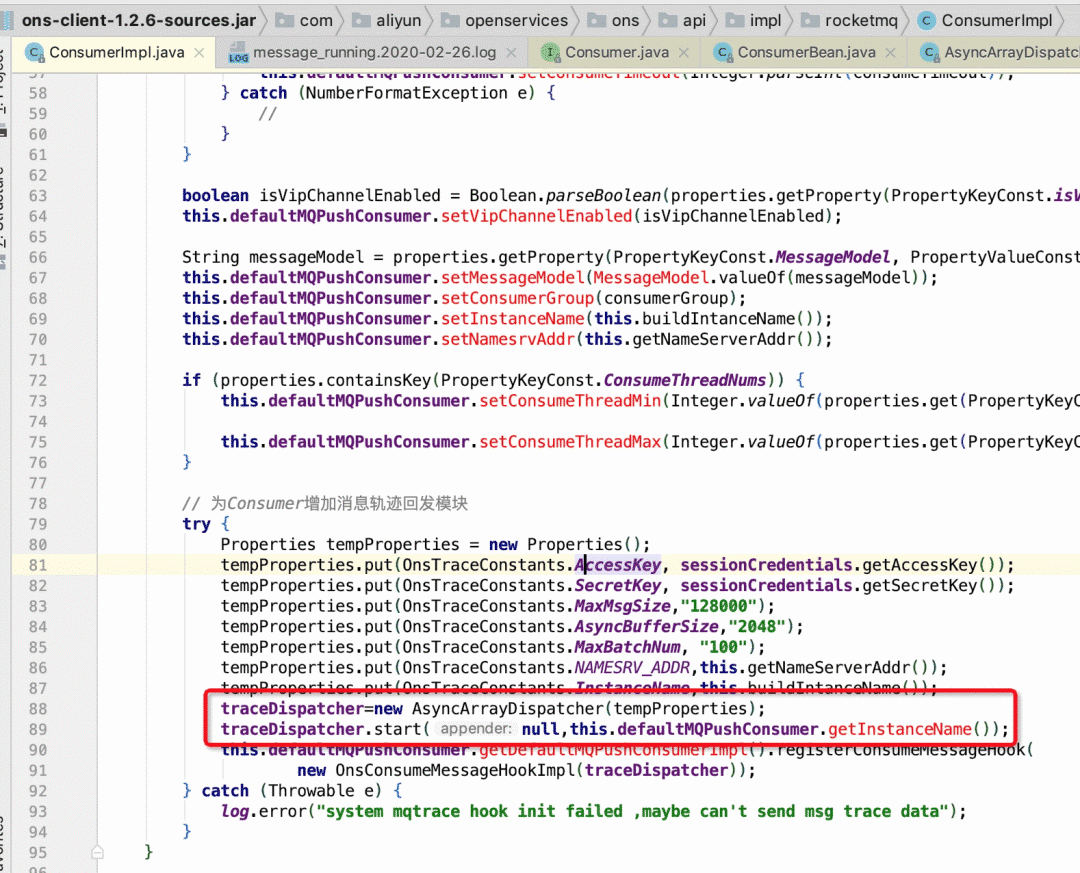
结合代码分析一下轨迹回传模块的流程(AsyncArrayDispatcher),总结如下:
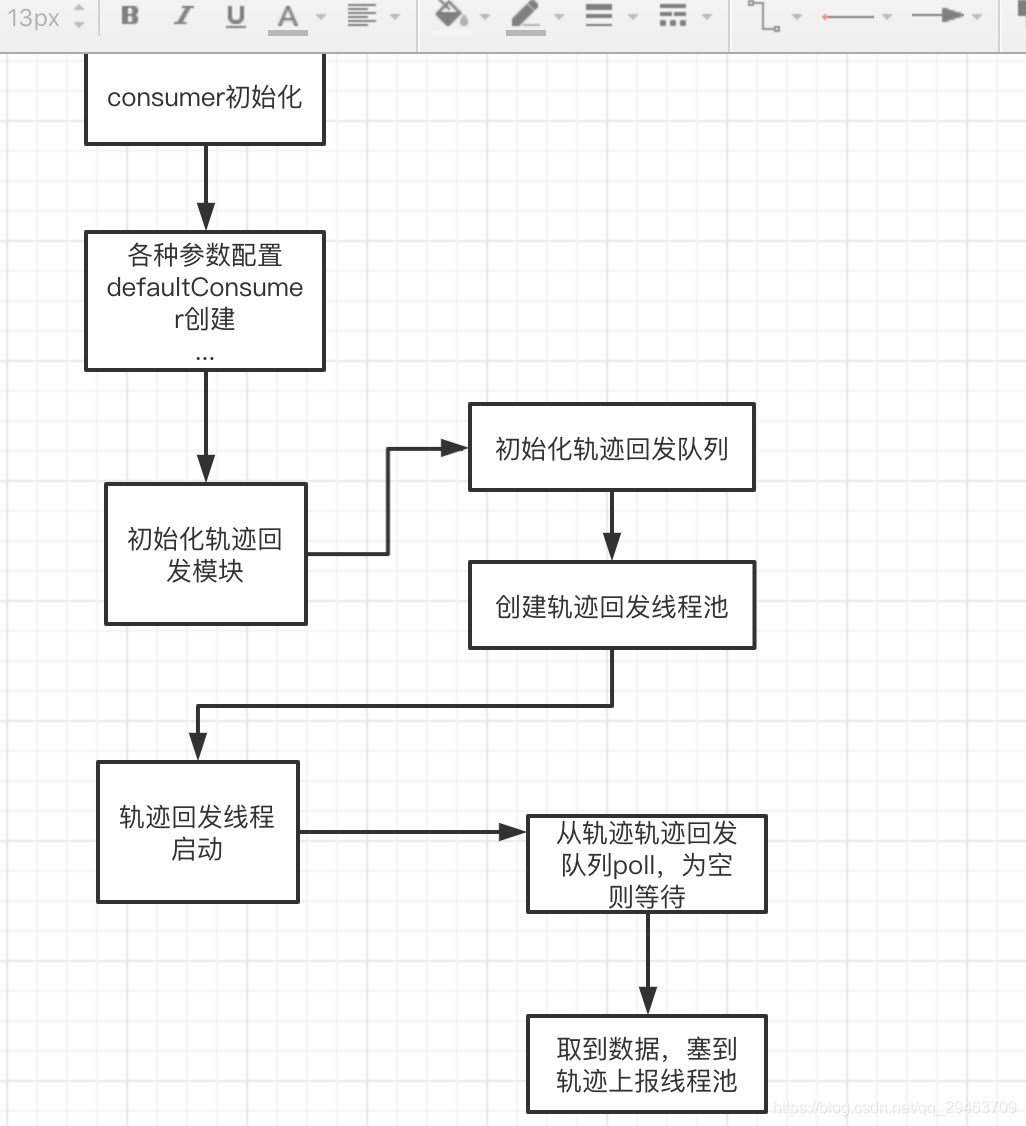
在sdk源码中定位线程堆栈日志中的代码,如下:

从这段代码以及堆栈信息可以看到问题出现在traceContextQueue.poll(5,TimeUnit.MILLISECONDS);其中traceContextQueue为有界阻塞队列,poll时,如果队列为空,会阻塞一定时间,因此会导致线程在running和time_wait之间进行频繁切换。
至于为什么要用poll(5,TimeUnit.MILLISECONDS)而不是take(),个人认为可能是为了减少网络io,5ms批量取一次丢到线程池批量上报,避免单个轨迹频繁上报?
poll()方法会返回队列的第一个元素,并删除;如果队列为空,则返回null,并不会阻塞当前线程;出队的逻辑调用的是 dequeue()方法,此外,它还有一个重载的方法,poll(long timeout, TimeUnit unit),如果队列为空,则会等待一段时间
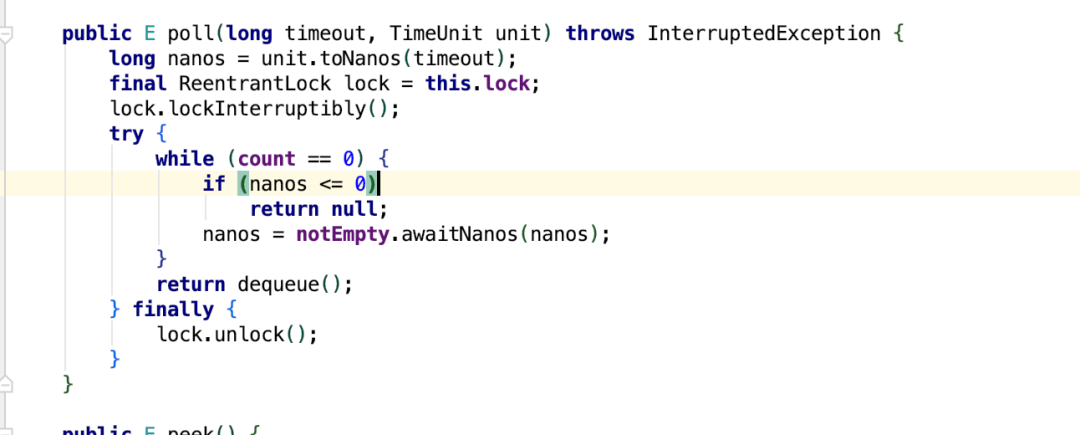
轨迹队列traceContextQueue使用的是ArrayBlockingQueue,一个有界的阻塞队列,内部使用一个数组来存放元素,通过锁来实现并发访问的,也是按照 FIFO 的原则对元素进行排列。
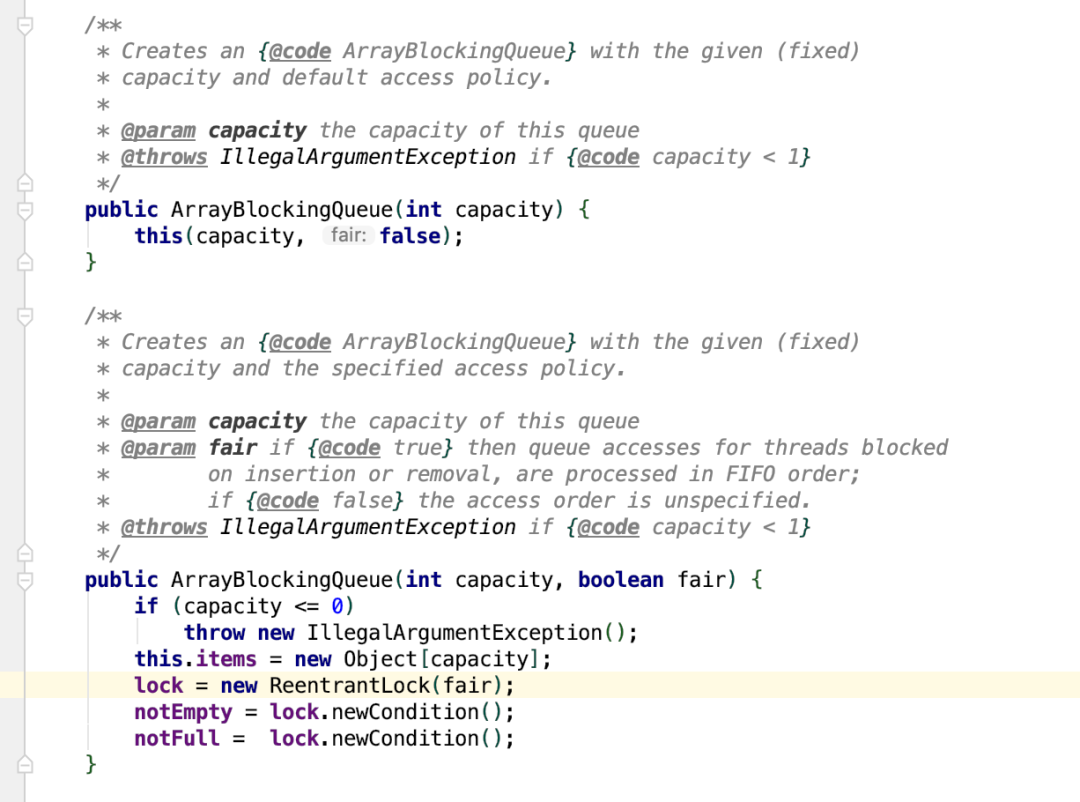
通过上面的代码可以看到,其通过reentrantLock 来实现并发的控制,ReentrantLock 提供了公平锁与非公平锁的实现,但ArrayBlockingQueue默认情况下,使用的非公平锁,不保证线程线程公平的访问队列。
所谓的公平是指阻塞的线程,按照阻塞的先后顺序访问队列,非公平是指当队列可用的时候,阻塞的线程都可以有争夺线程访问的资格,有可能先阻塞的线程最后才能访问队列。
由于每个consumer都只开了一个轨迹分发线程,所以这部分不存在竞争。
再看一下ArrayBlockingQueue的阻塞实现原理
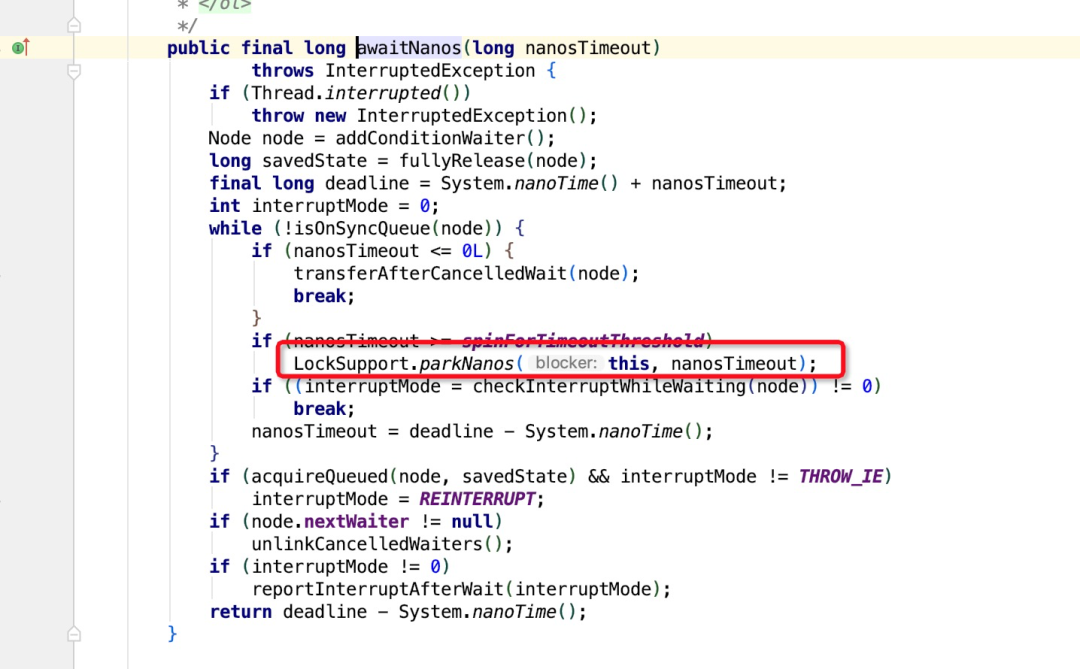
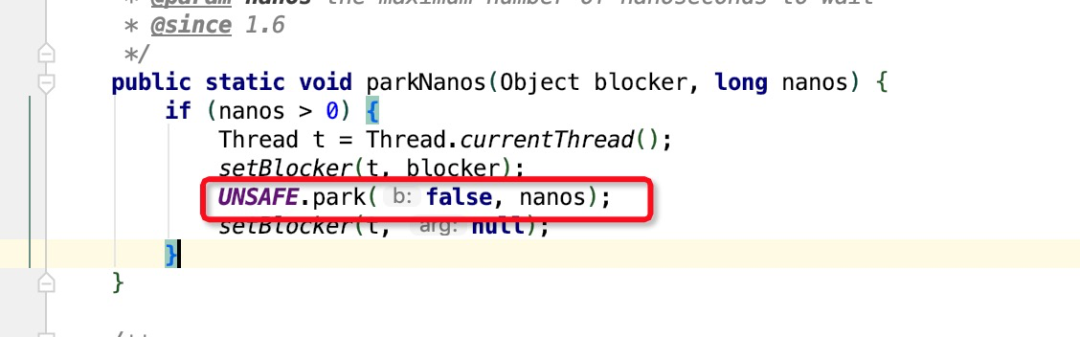

通过上面这部分代码可以看到阻塞最终是通过park方法实现,unsafe.park是个native方法
park这个方法会阻塞当前线程,当以下4种情况中的一种发生时,该方法才会返回
- 与park对应的unpark执行或已经执行时。
- 线程被中断时
- 等待完time参数指定的毫秒数时
- 异常现象发生
至此,系统线程切换以及中断频繁原因总结如下:
- 阿里云sdk中轨迹回发模块,一个consumer有一个分发线程和一个轨迹队列以及一个轨迹数据回发线程池,分发线程从轨迹队列中取,取不到则阻塞5ms,取到塞到轨迹数据回发线程池,然后数据上报。
过多的分发线程频繁在running和time_wait状态进行切换,导致系统load高。- 由于代码层面未设置每个consumer消息消费的最大最小线程数,导致每个consumer都会开20个核心线程进程消息消费,导致线程数量过多消耗系统资源以及空跑。
五、优化方案
结合以上原因,进行针对性优化
代码层面针对每个consumer设置线程数配置项,consumer可根据承载的业务等实际情况设置核心线程数,减少整体的线程数目,避免大量线程空跑。
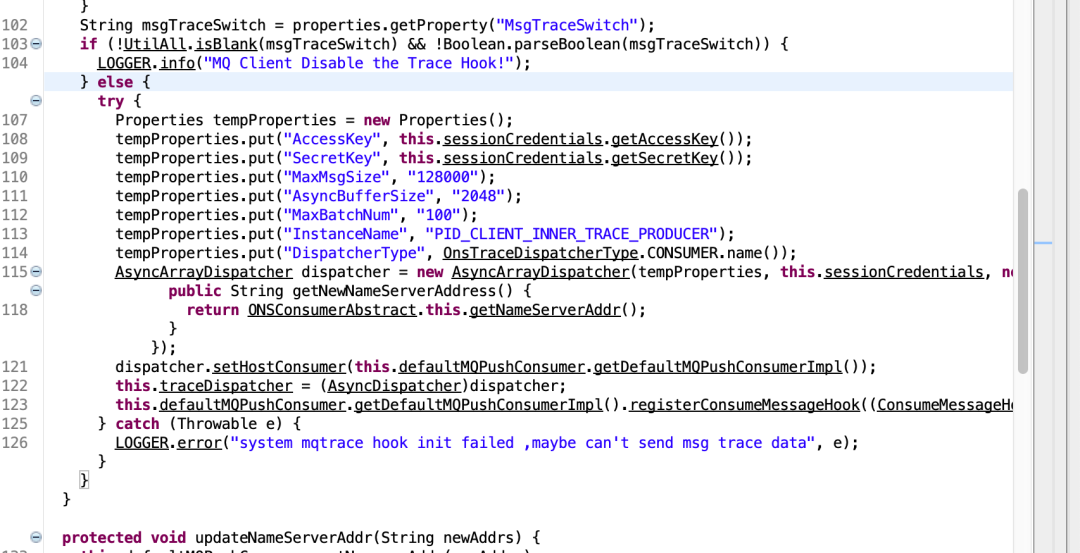
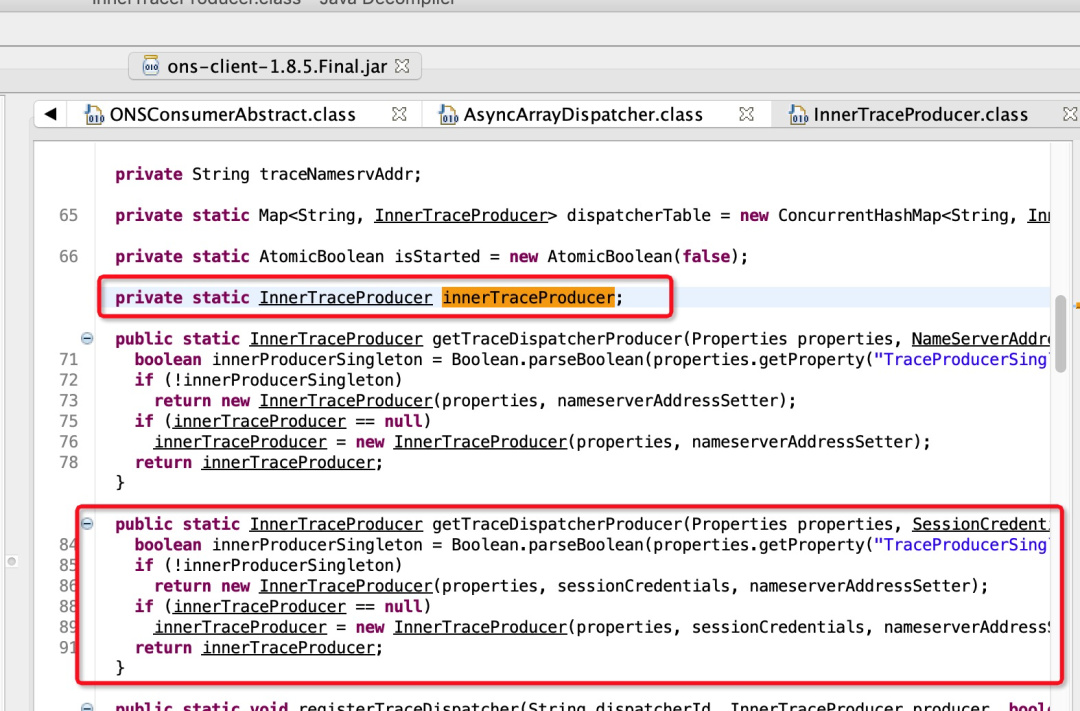
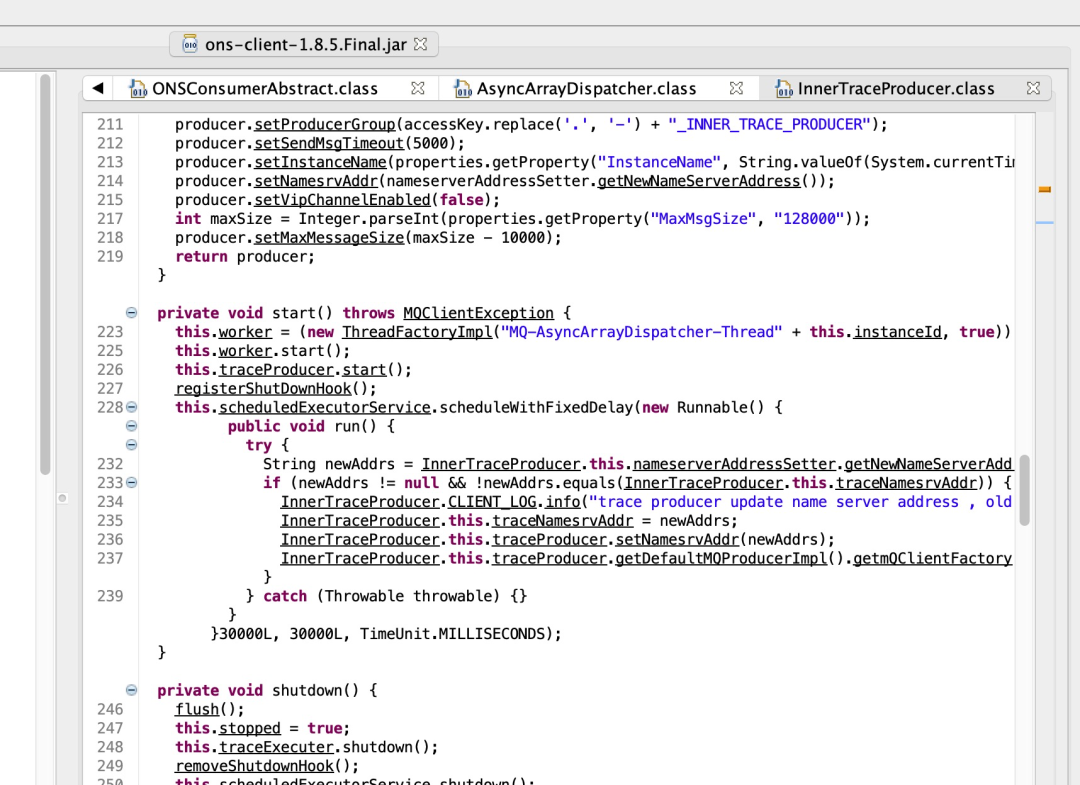
以上分析用的是阿里云ons 1.2.6的版本,当前已经迭代到了1.8.5版本,通过分析1.8.5版本的轨迹回传模块的源码,发现对轨迹回传增加了开关,配置轨迹回传使用单个线程(单例),即全部consumer使用一个分发线程、一个轨迹有界队列、一个轨迹上报线程池来处理,可以考虑验证通过后升版本。
更多思考
CPU负载高是我们在linux的系统维护中经常遇到的问题,更多关于cpu优化的内容大家可以阅读以下几篇:
一次生产 CPU 100% 排查优化实践
又一次生产 CPU 高负载排查实践
感谢月夜星星雨老师的分享~

