
JVM调优工具锦囊转载
作者:盛开的太阳
Arthas线上
分析诊断调优工具
以前我们要排查线上问题,通常使用的是jdk自带的调优工具和命令。最常见的就是dump线上日志,然后下载到本地,导入到jvisualvm工具中。这样操作有诸多不变,现在阿里团队开发的Arhtas工具,拥有非常强大的功能,并且都是线上的刚需,尤其是情况紧急,不方便立刻发版,适合临时处理危急情况使用。下面分两部分来研究JVM性能调优工具:
1.JDK自带的性能调优工具
虽然有了Arthas,但也不要忘记JDK自带的性能调优工具,在某些场景下,他还是有很大作用的。而且Arthas里面很多功能其根本就是封装了JDK自带的这些调优命令。
2.Arthas线上分析工具的使用
这一部分,主要介绍几个排查线上问题常用的方法。功能真的很强大,刚兴趣的猿媛可以研究其基本原理。之前跟我同事讨论,感觉这就像病毒一样,可以修改内存里的东西,真的还是挺强大的。
以上两种方式排查线上问题,没有优劣之分,如果线上不能安装Arthas就是jdk自带命令,如果jdk自带命令不能满足部分要求,又可以安装Arthas,那就使用Arthas。他们只是排查问题的工具,重要的是排查问题的思路。不管黑猫、白猫,能抓住耗子就是好猫。
一、JDK自带的调优工具
这里不是流水一样的介绍功能怎么用,就说说线上遇到的问题,我们通常怎么排查,排查的几种情况。
- 内存溢出,出现OutOfMemoryError,这个问题如何排查
- CPU使用猛增,这个问题如何排查?
- 进程有死锁,这个问题如何排查?
- JVM参数调优
下面来一个一个解决
1、处理内存溢出,报OutOfMemoryError错误
第一步:通过jmap -histo命令查看系统内存使用情况
使用的命令:
jmap -histo 进程号
运行结果:
num #instances #bytes class name
----------------------------------------------
1: 1101980 372161752 [B
2: 551394 186807240 [Ljava.lang.Object;
3: 1235341 181685128 [C
4: 76692 170306096 [I
5: 459168 14693376 java.util.concurrent.locks.AbstractQueuedSynchronizer$Node
6: 543699 13048776 java.lang.String
7: 497636 11943264 java.util.ArrayList
8: 124271 10935848 java.lang.reflect.Method
9: 348582 7057632 [Ljava.lang.Class;
10: 186244 5959808 java.util.concurrent.ConcurrentHashMap$Node
8671: 1 16 zipkin2.reporter.Reporter$1
8672: 1 16 zipkin2.reporter.Reporter$2
Total 8601492 923719424
num:序号
instances:实例数量
bytes:占用空间大小
class name:类名称,[C is a char[],[S is a short[],[I is a int[],[B is a byte[],[[I is a int[][]
上面这个运行结果是我启动了本地的一个项目,然后运行【jmap -histro 进程号】运行出来的结果,直接去了其中的一部分。通过这里我们可以看看大的实例对象中,有没有我们自定义的实例对象。通过这个可以排查出哪个实例对象引起的内存溢出。
除此之外,Total汇总数据可以看出当前一共有多少个对象,暂用了多大内存空间。这里是有约860w个对象,占用约923M的空间。
第二步:分析内存溢出,查看堆空间占用情况
使用命令
jhsdb jmap --heap --pid 进程号
比如,我本地启动了一个项目,想要查看这个项目的内存占用情况:
[root@iZ2pl8Z ~]# jhsdb jmap --heap --pid 28692
Attaching to process ID 28692, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 11.0.13+10-LTS-370
using thread-local object allocation.
Garbage-First (G1) GC with 4 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 2065694720 (1970.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 1239416832 (1182.0MB)
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 1048576 (1.0MB)
Heap Usage:
G1 Heap:
regions = 1970
capacity = 2065694720 (1970.0MB)
used = 467303384 (445.65523529052734MB)
free = 1598391336 (1524.3447647094727MB)
22.622093161955704% used
G1 Young Generation:
Eden Space:
regions = 263
capacity = 464519168 (443.0MB)
used = 275775488 (263.0MB)
free = 188743680 (180.0MB)
59.36794582392776% used
Survivor Space:
regions = 6
capacity = 6291456 (6.0MB)
used = 6291456 (6.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:
regions = 179
capacity = 275775488 (263.0MB)
used = 186285016 (177.65523529052734MB)
free = 89490472 (85.34476470947266MB)
67.54951912187352% used
下面来看看参数的含义
堆空间配置信息
Heap Configuration:
/**
* 空闲堆空间的最小百分比,计算公式为:HeapFreeRatio =(CurrentFreeHeapSize/CurrentTotalHeapSize) * 100,值的区间为0 * 到100,默认值为 40。如果HeapFreeRatio < MinHeapFreeRatio,则需要进行堆扩容,扩容的时机应该在每次垃圾回收之后。
*/
MinHeapFreeRatio = 40
/**
* 空闲堆空间的最大百分比,计算公式为:HeapFreeRatio =(CurrentFreeHeapSize/CurrentTotalHeapSize) * 100,值的区间为0
* 到100,默认值为 70。如果HeapFreeRatio > MaxHeapFreeRatio,则需要进行堆缩容,缩容的时机应该在每次垃圾回收之后
*/
MaxHeapFreeRatio = 70
/**JVM 堆空间允许的最大值*/
MaxHeapSize = 2065694720 (1970.0MB)
/** JVM 新生代堆空间的默认值*/
NewSize = 1363144 (1.2999954223632812MB)
/** JVM 新生代堆空间允许的最大值 */
MaxNewSize = 1239416832 (1182.0MB)
/** JVM 老年代堆空间的默认值 */
OldSize = 5452592 (5.1999969482421875MB)
/** 新生代(2个Survivor区和Eden区 )与老年代(不包括永久区)的堆空间比值,表示新生代:老年代=1:2*/
NewRatio = 2
/** 两个Survivor区和Eden区的堆空间比值为 8,表示 S0 : S1 :Eden = 1:1:8 */
SurvivorRatio = 8
/** JVM 元空间的默认值 */
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
/** JVM 元空间允许的最大值 */
MaxMetaspaceSize = 17592186044415 MB
/** 在使用 G1 垃圾回收算法时,JVM 会将 Heap 空间分隔为若干个 Region,该参数用来指定每个 Region 空间的大小 */
G1HeapRegionSize = 1048576 (1.0MB)
G1堆使用情况
Heap Usage:
G1 Heap:
regions = 1970
capacity = 2065694720 (1970.0MB)
used = 467303384 (445.65523529052734MB)
free = 1598391336 (1524.3447647094727MB)
22.622093161955704% used
G1 的 Heap 使用情况,该 Heap 包含 1970 个 Region,结合上文每个 RegionSize=1M,因此 Capacity = Regions * RegionSize = 1970 * 1M = 1970M,已使用空间为 445.65M,空闲空间为 1524.34M,使用率为 22.62%。
G1 Young Generation:
Eden Space:
regions = 263
capacity = 464519168 (443.0MB)
used = 275775488 (263.0MB)
free = 188743680 (180.0MB)
59.36794582392776% used
G1 的 Eden 区的使用情况,总共使用了 263 个 Region,结合上文每个 RegionSize=1M,因此 Used = Regions * RegionSize = 263 * 1M = 263M,Capacity=443M 表明当前 Eden 空间分配了 443 个 Region,使用率为 59.37%。
G1年轻代Survivor区使用情况和G1老年代使用情况:和Eden区类似
Survivor Space:
regions = 6
capacity = 6291456 (6.0MB)
used = 6291456 (6.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:
regions = 179
capacity = 275775488 (263.0MB)
used = 186285016 (177.65523529052734MB)
free = 89490472 (85.34476470947266MB)
67.54951912187352% used
Survivor区使用情况和Eden区类似。 老年代参数含义和Eden区类似。
第三步:导出dump内存溢出的文件,导入到jvisualvm查看
如果前两种方式还是没有排查出问题,我们可以导出内存溢出的日志,在导入客户端进行分析
使用的命令是:
jmap -dump:file=a.dump 进程号
或者是直接设置JVM参数
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=./ (路径)
然后导入到jvisualvm中进行分析,方法是:点击文件->装入,导入文件,查看系统的运行情况了。
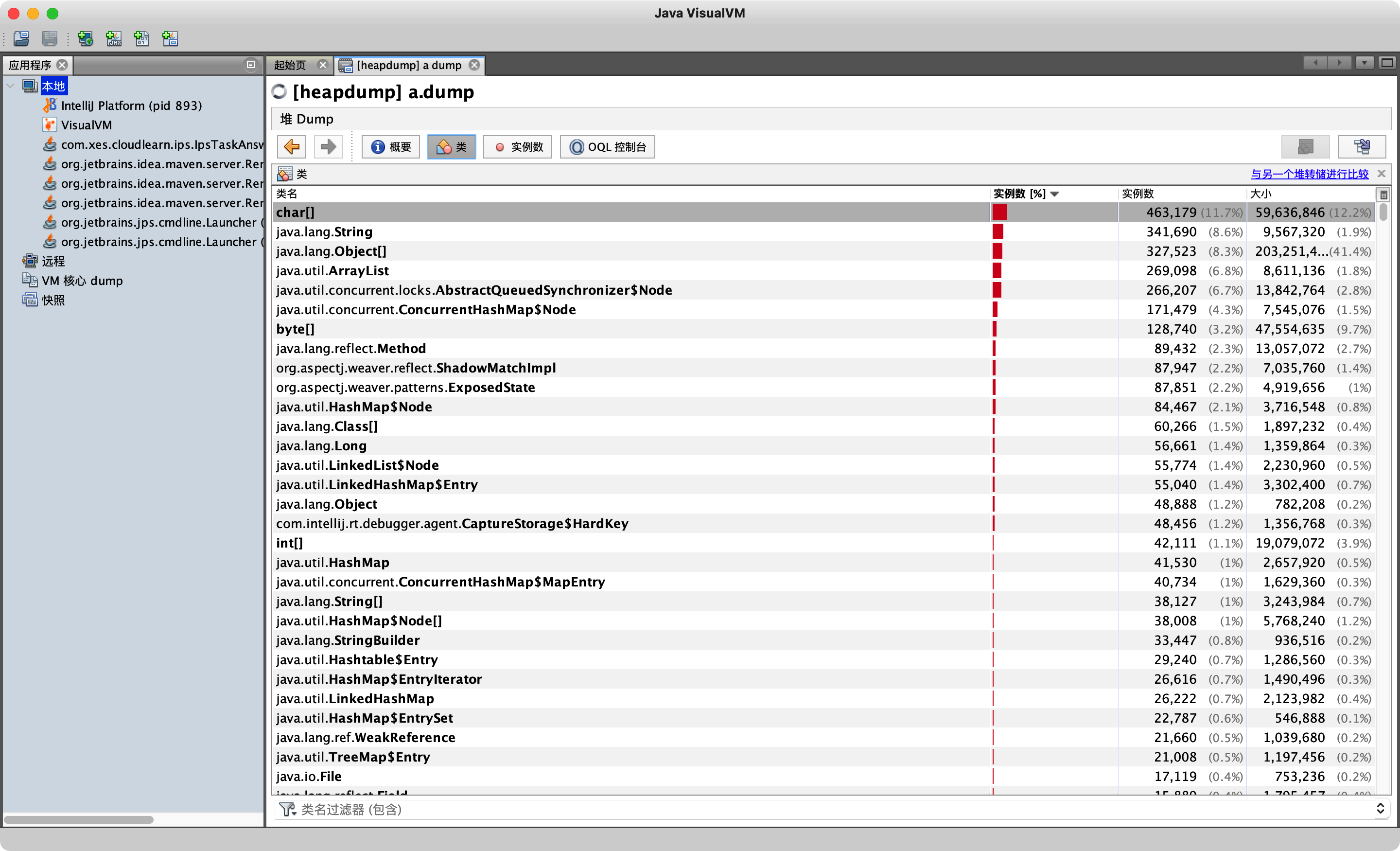
通过分析实例数,看看哪个对象实例占比最高,这里重点看我们自定义的类,然后分析这个对象里面有没有大对象,从而找出引起内存溢出的根本原因。
2、CPU使用猛增,这个问题如何排查?
我们可以通过Jstack找出占用cpu最高的线程的堆栈信息,下面来一步一步分析。
假设我们有一段死循环,不断执行方法调用,线程始终运行不释放就会导致CPU飙高,示例代码如下:
package com.lxl.jvm;
public class Math {
public static int initData = 666;
public static User user = new User();
public User user1;
public int compute() {
int a = 1;
int b = 2;
int c = (a + b) * 10;
return c;
}
public static void main(String[] args) {
Math math = new Math();
while(true){
math.compute();
}
}
}
第一步:运行代码,使用top命令查看cpu占用情况
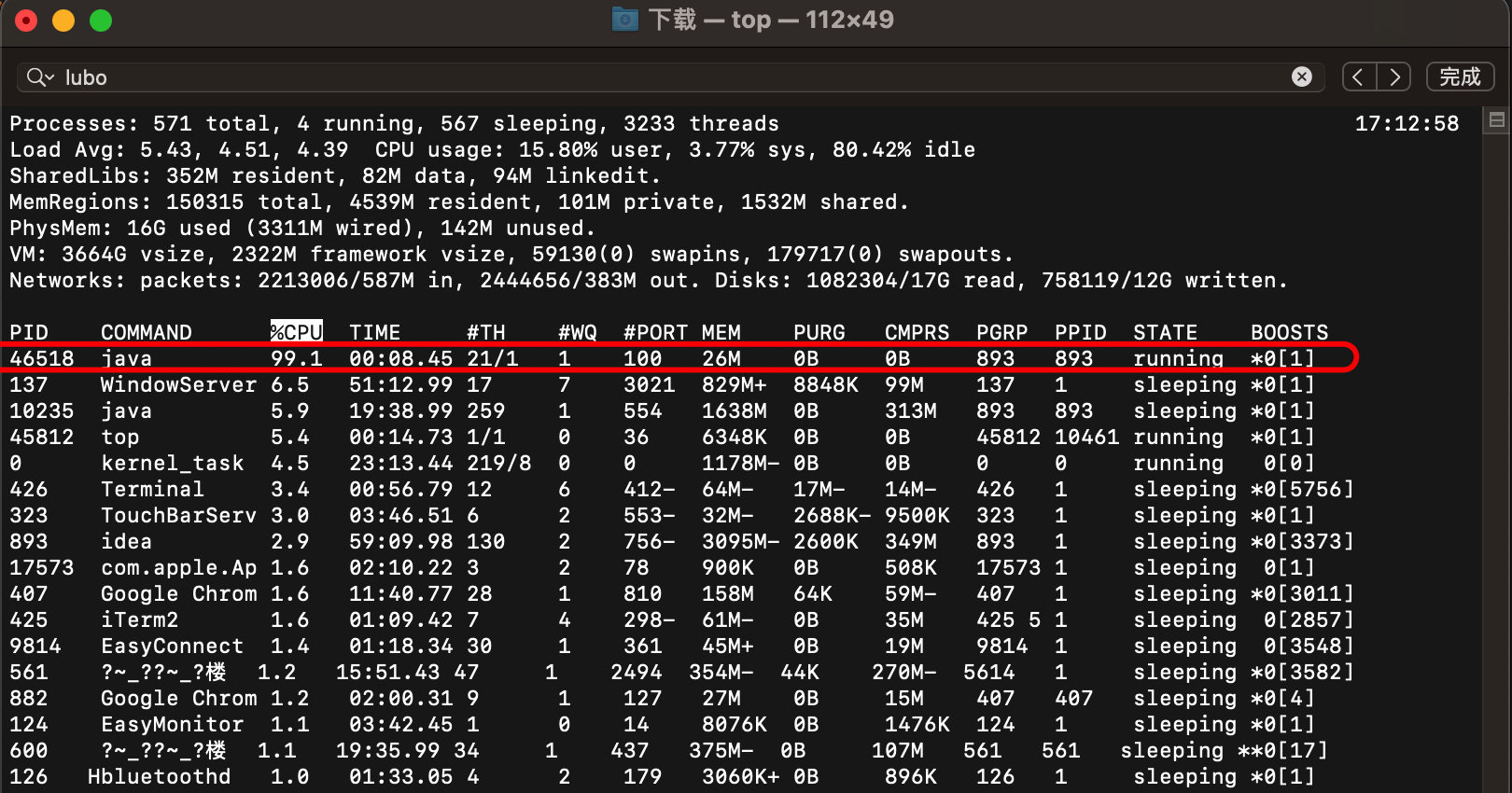
如上,现在有一个java进程,cpu严重飙高了,接下来如何处理呢?
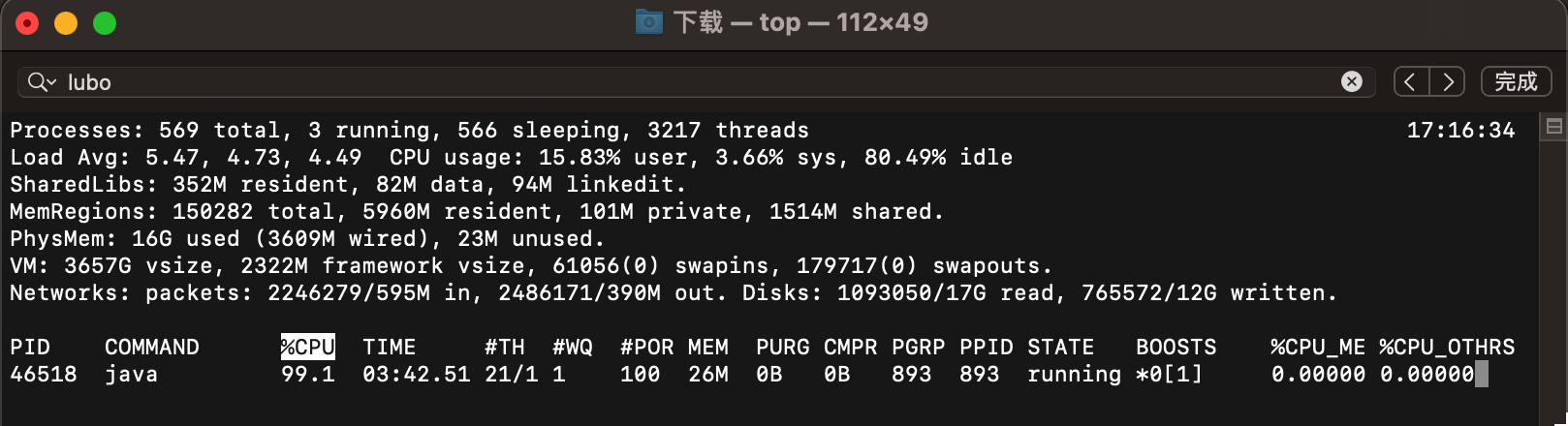
第二步:使用top -p 命令查看飙高进程
top -p 46518
我们看到了单独的46518这个线程的详细信息
第三步:按H,获取每个线程的内存情况
需要注意的是,这里的H是大写的H。
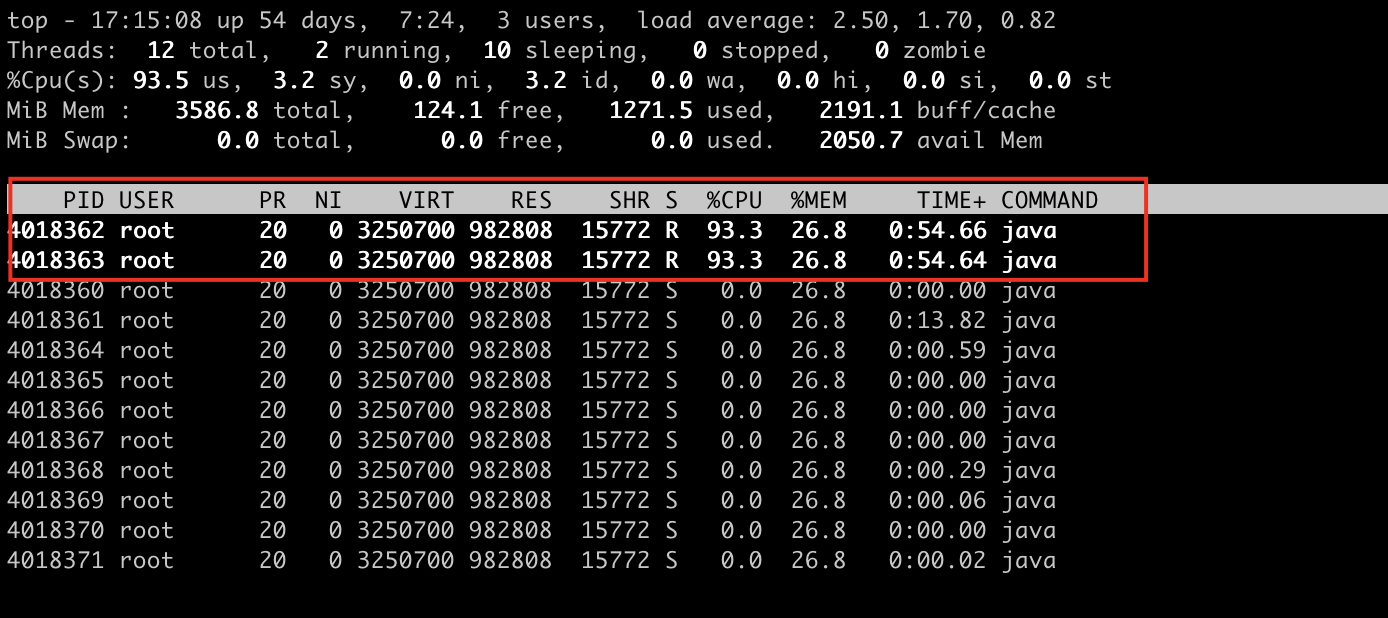
我们可以看出线程0和线程1线程号飙高。
第四步:找到内存和cpu占用最高的线程tid
通过上图我们看到占用cpu资源最高的线程有两个,线程号分别是4018362,4018363。我们一第一个为例说明,如何查询这个线程是哪个线程,以及这个线程的什么地方出现问题,导致cpu飙高。
第五步:将线程tid转化为十六进制
67187778是线程号为4013442的十六进制数。具体转换可以网上查询工具。
第六步:执行[ jstack 4018360|grep -A 10 67187778] 查询飙高线程的堆栈信息
接下来查询飙高线程的堆栈信息
jstack 4013440|grep -A 10 67190882
- 4013440:表示的是进程号
- 67187778: 表示的是线程号对应的十六进制数
通过这个方式可以查询到这个线程对应的堆栈信息
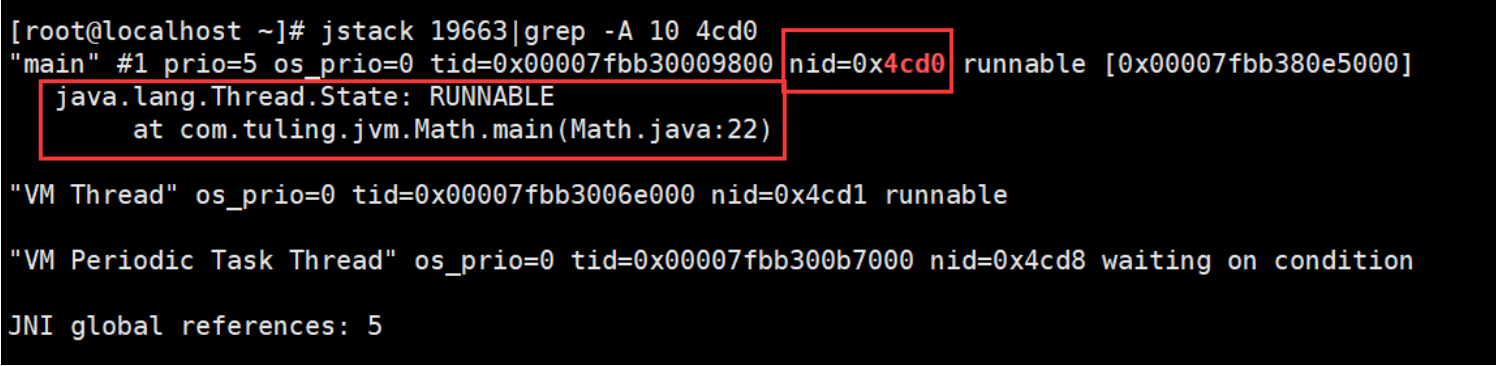
从这里我们可以看出有问题的线程id是0x4cd0, 哪一句代码有问题呢,Math类的22行。
第七步:查看对应的堆栈信息找出可能存在问题的代码
上述方法定位问题已经很精确了,接下来就是区代码里排查为什么会有问题了。
备注:上面的进程id可能没有对应上,在测试的时候,需要写对进程id和线程id
3、进程有死锁,这个问题如何排查?
Jstack可以用来查看堆栈使用情况,以及进程死锁情况。下面就来看看如何排查进程死锁
还是通过案例来分析
package com.lxl.jvm;
public class DeadLockTest {
private static Object lock1 = new Object();
private static Object lock2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
synchronized (lock1) {
try {
System.out.println("thread1 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock2) {
System.out.println("thread1 end");
}
}
}).start();
new Thread(() -> {
synchronized (lock2) {
try {
System.out.println("thread2 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock1) {
System.out.println("thread2 end");
}
}
}).start();
}
}
上面是两把锁,互相调用。
- 定义了两个成员变量lock1,lock2
- main方法中定义了两个线程。
- 线程1内部使用的是同步执行--上锁,锁是lock1。休眠5秒钟之后,他要获取第二把锁,执行第二段代码。
- 线程2和线程1类似,锁相反。
- 问题:一开始,像个线程并行执行,线程一获取lock1,线程2获取lock2.然后线程1继续执行,当休眠5s后获取开启第二个同步执行,锁是lock2,但这时候很可能线程2还没有执行完,所以还没有释放lock2,于是等待。线程2刚开始获取了lock2锁,休眠五秒后要去获取lock1锁,这时lock1锁还没释放,于是等待。两个线程就处于相互等待中,造成死锁。
第一步:通过Jstack命令来看看是否能检测到当前有死锁。
jstack 51789
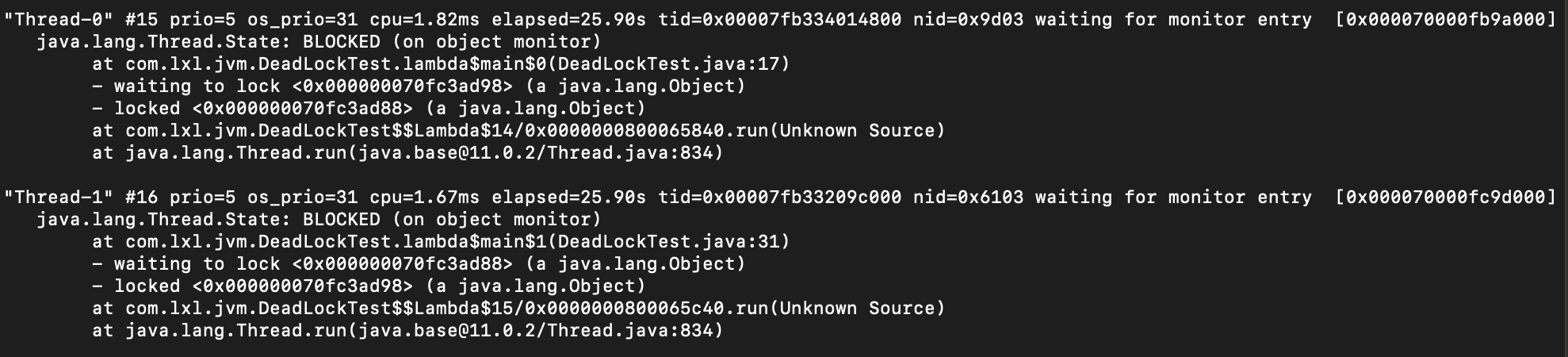
从这里面个异常可以看出,
- prio:当前线程的优先级
- cpu:cpu耗时
- os_prio:操作系统级别的优先级
- tid:线程id
- nid:系统内核的id
- state:当前的状态,BLOCKED,表示阻塞。通常正常的状态是Running我们看到Thread-0和Thread-1线程的状态都是BLOCKED.
通过上面的信息,我们判断出两个线程的状态都是BLOCKED,可能有点问题,然后继续往下看。
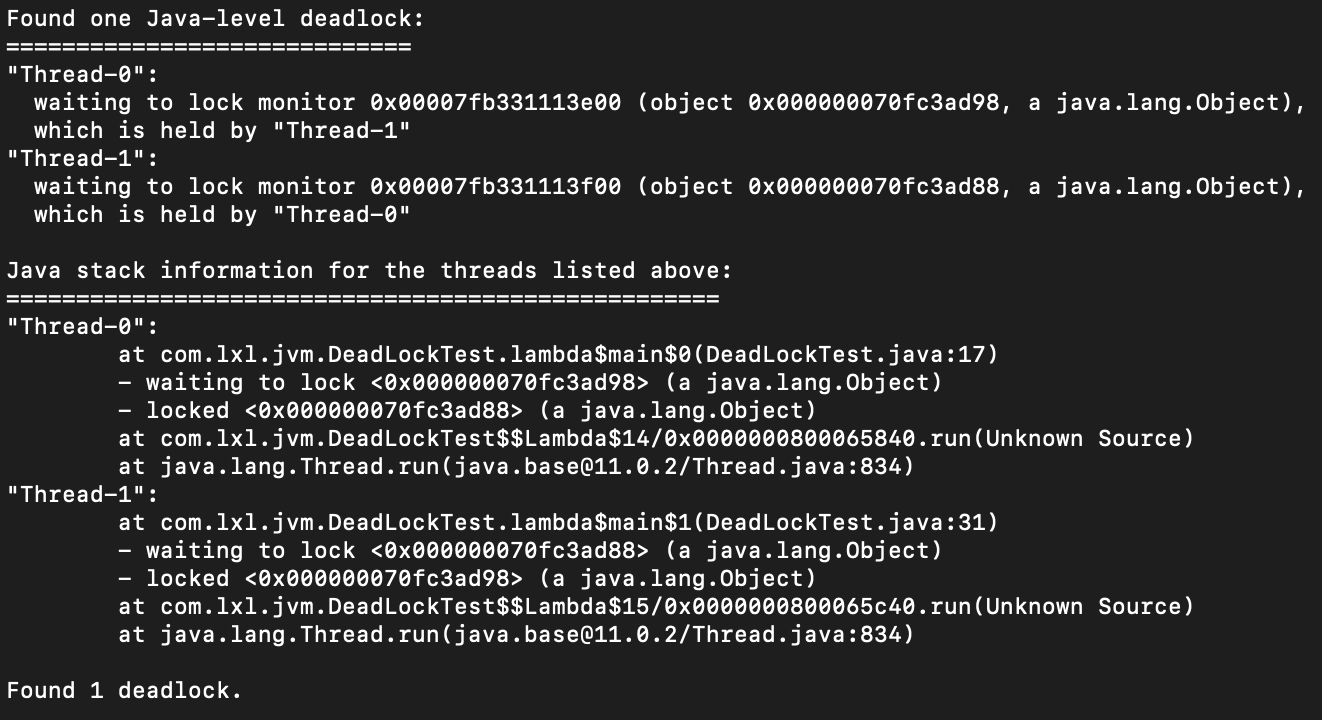
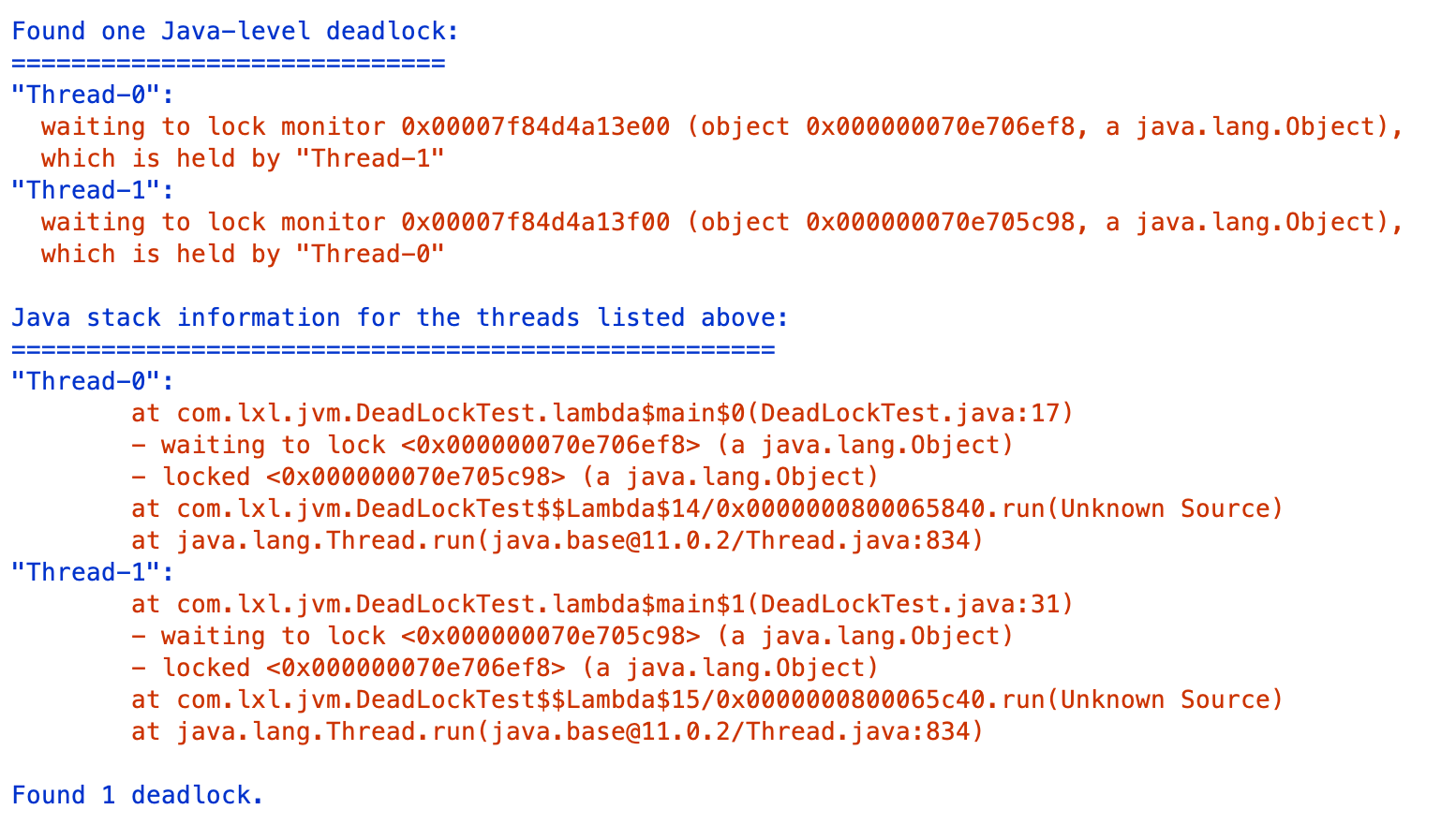
我们从最后的一段可以看到这句话:Found one Java-level deadlock; 意思是找到一个死锁。死锁的线程号是Thread-0,Thread-1。
Thread-0:正在等待0x000000070e706ef8对象的锁,这个对象现在被Thread-1持有。
Thread-1:正在等待0x000000070e705c98对象的锁,这个对象现在正在被Thread-0持有。
最下面展示的是死锁的堆栈信息。死锁可能发生在DeadLockTest的第17行和第31行。通过这个提示,我们就可以找出死锁在哪里了。
第二步:使用jvisualvm查看死锁
如果使用jstack感觉不太方便,还可以使用jvisualvm,通过界面来查看,更加直观。
在程序代码启动的过程中,打开jvisualvm工具。
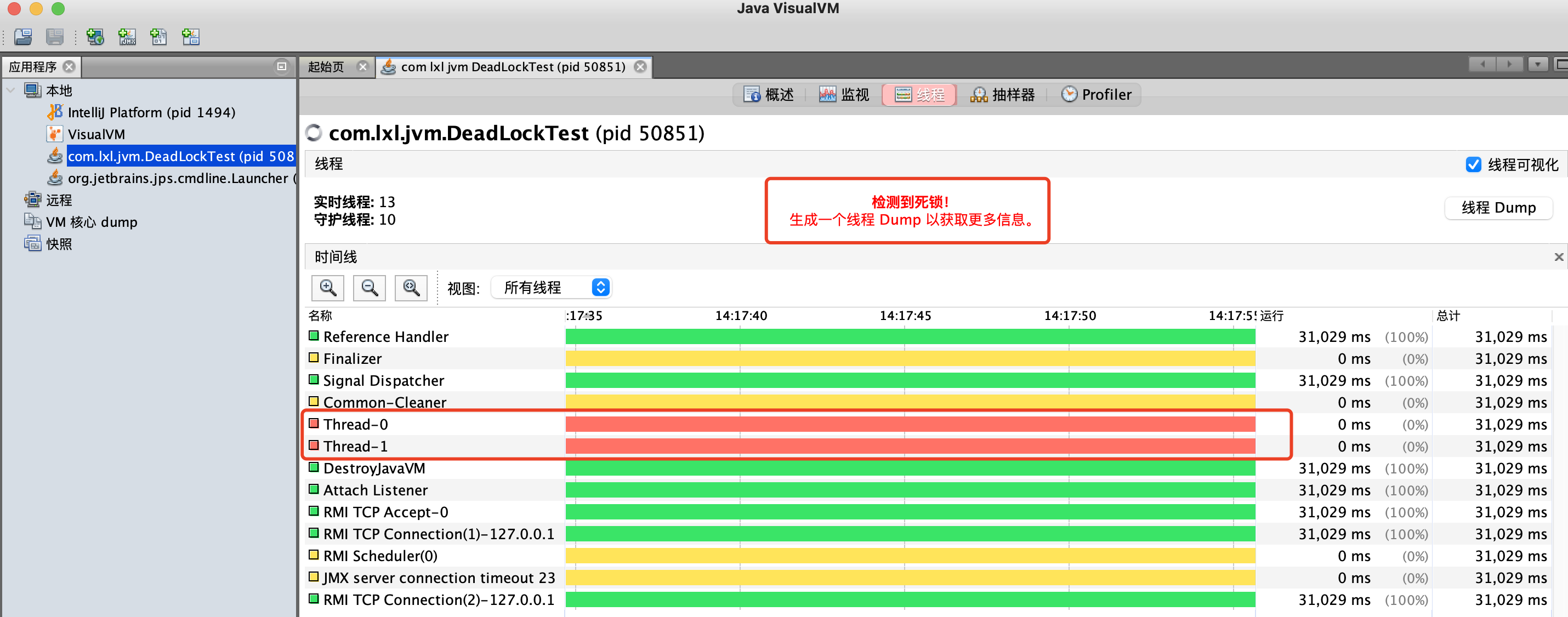
找到当前运行的类,查看线程,就会看到最头上的一排红字:检测到死锁。然后点击“线程Dump”按钮,查看相信的线程死锁的信息。
这里可以找到线程私锁的详细信息,具体内容和上面使用Jstack命令查询的结果一样,这里实用工具更加方便。
4、JVM参数调优
jvm调优通常使用的是Jstat命令。
1. 垃圾回收统计 jstat -gc
jstat -gc 进程id
这个命令非常常用,在线上有问题的时候,可以通过这个命令来分析问题。
下面我们来测试一下,启动一个项目,然后在终端驶入jstat -gc 进程id,得到如下结果:

上面的参数分别是什么意思呢?先识别参数的含义,然后根据参数进行分析
- S0C: 第一个Survivor区的容量
- S1C: 第二个Survivor区的容量
- S0U: 第一个Survivor区已经使用的容量
- S1U:第二个Survivor区已经使用的容量
- EC: 新生代Eden区的容量
- EU: 新生代Eden区已经使用的容量
- OC: 老年代容量
- OU:老年代已经使用的容量
- MC: 方法区大小(元空间)
- MU: 方法区已经使用的大小
- CCSC:压缩指针占用空间
- CCSU:压缩指针已经使用的空间
- YGC: YoungGC已经发生的次数
- YGCT: 这一次YoungGC耗时
- FGC: Full GC发生的次数
- FGCT: Full GC耗时
- GCT: 总的GC耗时,等于YGCT+FGCT
连续观察GC变化的命令
jstat -gc 进程ID 间隔时间 打印次数
举个例子:我要打印10次gc信息,每次间隔1秒
jstat -gc 进程ID 1000 10
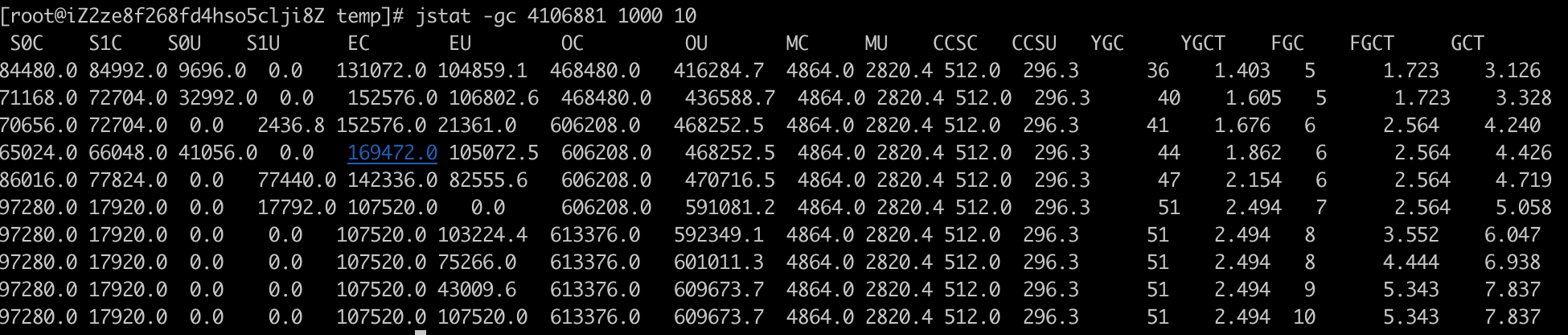
这样就连续打印了10次gc的变化,每次隔一秒。
这个命令是对整体垃圾回收情况的统计,下面将会差分处理。
2.堆内存统计
这个命令是打印堆内存的使用情况。
jstat -gccapacity 进程ID

- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0C:第一个Survivor区大小
- S1C:第二个Survivor区大小
- EC:Eden区的大小
- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC: 当前老年代大小
- MCMN: 最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:年轻代gc次数
- FGC:老年代GC次数
3.新生代垃圾回收统计
命令:
jstat -gcnew 进程ID [ 间隔时间 打印次数]
这个指的是当前某一次GC的内存情况
- S0C:第一个Survivor的大小
- S1C:第二个Survivor的大小
- S0U:第一个Survivor已使用大小
- S1U:第二个Survivor已使用大小
- TT: 对象在新生代存活的次数
- MTT: 对象在新生代存活的最大次数
- DSS: 期望的Survivor大小
- EC:Eden区的大小
- EU:Eden区的使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
4. 新生代内存统计
jstat -gcnewcapacity 进程ID

参数含义:
- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0CMX:Survivor 1区最大大小
- S0C:当前Survivor 1区大小
- S1CMX:Survivor 2区最大大小
- S1C:当前Survivor 2区大小
- ECMX:最大Eden区大小
- EC:当前Eden区大小
- YGC:年轻代垃圾回收次数
- FGC:老年代回收次数
5. 老年代垃圾回收统计
命令:
jstat -gcold 进程ID

参数含义:
- MC:方法区大小
- MU:方法区已使用大小
- CCSC:压缩指针类空间大小
- CCSU:压缩类空间已使用大小
- OC:老年代大小
- OU:老年代已使用大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间,新生代+老年代
6. 老年代内存统计
命令:
jstat -gcoldcapacity 进程ID

参数含义:
- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC:老年代大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
7. 元数据空间统计
命令
jstat -gcmetacapacity 进程ID

- MCMN:最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小指针压缩类空间大小
- CCSMX:最大指针压缩类空间大小
- CCSC:当前指针压缩类空间大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
8.整体运行情况
命令:
jstat -gcutil 进程ID

- S0:Survivor 1区当前使用比例
- S1:Survivor 2区当前使用比例
- E:Eden区使用比例
- O:老年代使用比例
- M:元数据区使用比例
- CCS:指针压缩使用比例
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
通过查询上面的参数来分析整个堆空间。
二、Arthas线上分析工具的使用
Arthas的功能非常强大,现附上官方文档:https://arthas.aliyun.com/doc/
其实想要了解Arthas,看官方文档就可以了,功能全而详细。那为什么还要整理一下呢?我们这里整理的是一些常用功能,以及在紧急情况下可以给我们帮大忙的功能。
Arthas分为几个部分来研究,先来看看我们的研究思路哈
1.安装及启动---这一块简单看,对于程序员来说,so easy
2.dashboard仪表盘功能---类似于JDK的jstat命令,
3.thread命令查询进行信息---类似于jmap命令
4.反编译线上代码----这个功能很牛,改完发版了,怎么没生效,反编译看看。
5.查询某一个函数的返回值
6.查询jvm信息,并修改----当发生内存溢出是,可以手动设置打印堆日志到文件
7.profiler火焰图
下面就来看看Arthas的常用功能的用法吧
1、Arthas的安装及启动
其实说到这快,不得不提的是,之前我一直因为arthas是一个软件,要启动,界面操作。当时我就想,要是这样,在线上安装一个单独的应用,公司肯定不同意啊~~~,研究完才发现,原来Arthas就是一个jar包。运行起来就是用java -jar 就可以。
1) 安装
可以直接在Linux上通过命令下载:
wget https://alibaba.github.io/arthas/arthas-boot.jar
也可以在浏览器直接访问https://alibaba.github.io/arthas/arthas-boot.jar,等待下载成功后,上传到Linux服务器上。
2) 启动
执行命令就可以启动了
java -jar arthas-boot.jar
启动成功可以看到如下界面:

然后找到你想监控的进程,输入前面对应的编号,就可以开启进行监控模式了。比如我要看4
看到这个就表示,进入应用监听成功
2、dashboard仪表盘--查询整体项目运行情况
执行命令
dashboard
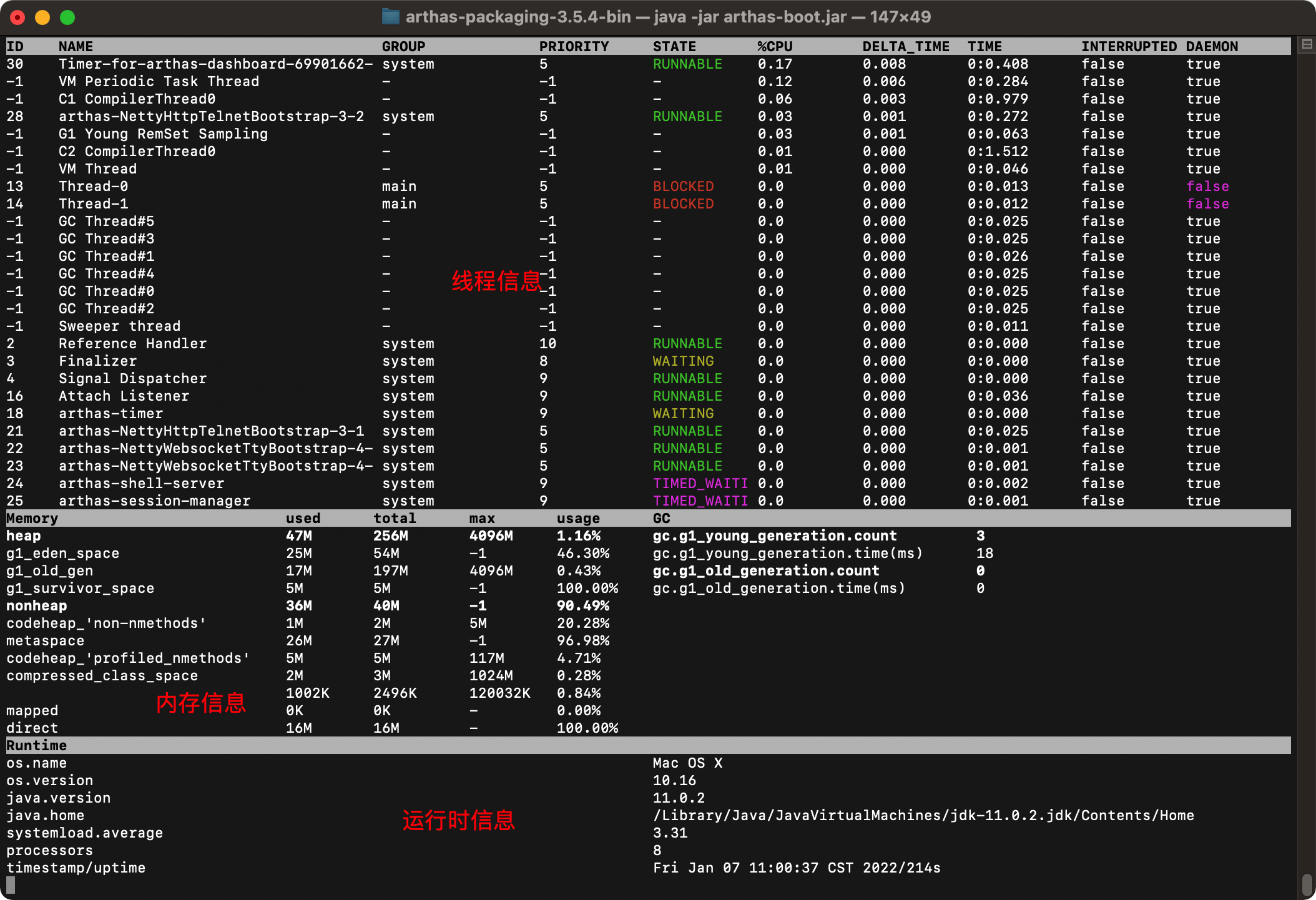
这里面一共有三块
1)线程信息
我们可以看到当前进程下所有的线程信息。其中第13,14号线程当前处于BLOCKED阻塞状态,阻塞时间也可以看到。通过这个一目了然,当前有两个线程是有问题的,处于阻塞状态GC线程有6个。
2)内存信息
内存信息包含三个部分:堆空间信息、非堆空间信息和GC垃圾收集信息
堆空间信息
- g1_eden_space: Eden区空间使用情况
- g1_survivor_space: Survivor区空间使用情况
- g1_old_gen: Old老年代空间使用情况
非堆空间信息
- codeheap_'non-nmethods': 非方法代码堆大小
- metaspace: 元数据空间使用情况
- codeheap_'profiled_nmethods':
- compressed_class_space: 压缩类空间使用情况
GC垃圾收集信息
- gc.g1_young_generation.count:新生代gc的数量
- gc.g1_young_generation.time(ms)新生代gc的耗时
- gc.g1_old_generation.count: 老年代gc的数量
- gc.g1_old_generation.time(ms):老年代gc的耗时
3) 运行时信息
-
os.name:当前使用的操作系统 Mac OS X
-
os.version :操作系统的版本号 10.16
-
java.version:java版本号 11.0.2
-
java.home:java根目录 /Library/Java/JavaVirtualMachines/jdk-11.0.2.jdk/Contents/Home
-
systemload.average:系统cpu负载平均值4.43
load average值的含义
> 单核处理器
假设我们的系统是单CPU单内核的,把它比喻成是一条单向马路,把CPU任务比作汽车。当车不多的时候,load <1;当车占满整个 马路的时候 load=1;当马路都站满了,而且马路外还堆满了汽车的时候,load>1



> 多核处理器
我们经常会发现服务器Load > 1但是运行仍然不错,那是因为服务器是多核处理器(Multi-core)。
假设我们服务器CPU是2核,那么将意味我们拥有2条马路,我们的Load = 2时,所有马路都跑满车辆。

-
processors : 处理器个数 8
-
timestamp/uptime:采集的时间戳Fri Jan 07 11:36:12 CST 2022/2349s
通过仪表盘,我们能从整体了解当前线程的运行健康状况
3.thread命令查询CPU使用率最高的线程及问题原因
通过dashboard我们可以看到当前进程下运行的所有的线程。那么如果想要具体查看某一个线程的运行情况,可以使用thread命令
1. 统计cpu使用率最高的n个线程
先来看看常用的参数。
参数说明
| 参数名称 | 参数说明 |
|---|---|
| id | 线程id |
| [n:] | 指定最忙的前N个线程并打印堆栈 |
| [b] | 找出当前阻塞其他线程的线程 |
[i <value>] |
指定cpu使用率统计的采样间隔,单位为毫秒,默认值为200 |
| [--all] | 显示所有匹配的线程 |
我们的目标是想要找出CPU使用率最高的n个线程。那么需要先明确,如何计算出CPU使用率,然后才能找到最高的。计算规则如下:
首先、第一次采样,获取所有线程的CPU时间(调用的是java.lang.management.ThreadMXBean#getThreadCpuTime()及sun.management.HotspotThreadMBean.getInternalThreadCpuTimes()接口)
然后、睡眠等待一个间隔时间(默认为200ms,可以通过-i指定间隔时间)
再次、第二次采样,获取所有线程的CPU时间,对比两次采样数据,计算出每个线程的增量CPU时间
线程CPU使用率 = 线程增量CPU时间 / 采样间隔时间 * 100%
注意: 这个统计也会产生一定的开销(JDK这个接口本身开销比较大),因此会看到as的线程占用一定的百分比,为了降低统计自身的开销带来的影响,可以把采样间隔拉长一些,比如5000毫秒。
统计1秒内cpu使用率最高的n个线程:
thread -n 3 -i 1000
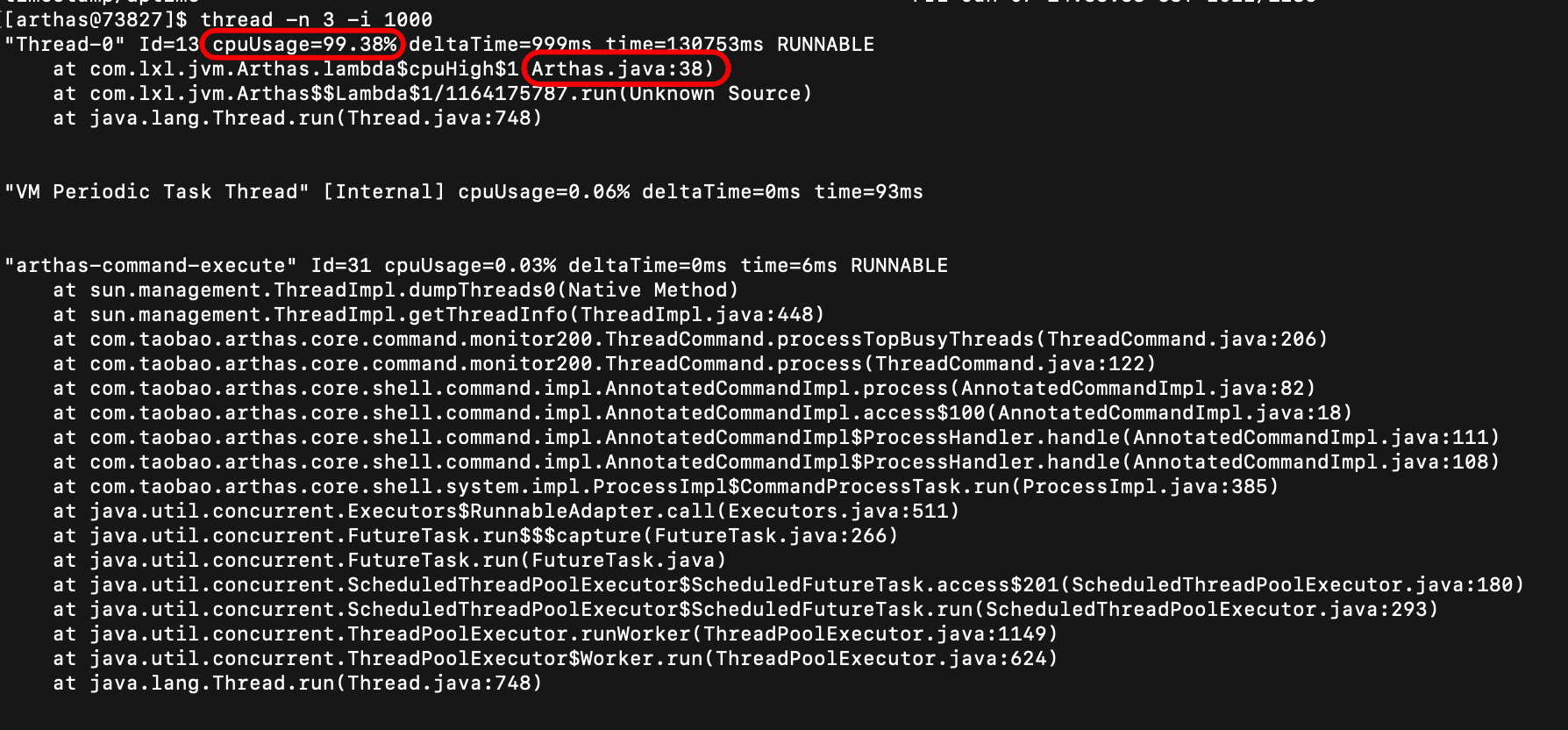
从线程的详情可以分析出,目前第一个线程的使用率是最高的,cpu占用了达到99.38%。第二行告诉我们,是Arthas.java这个类的第38行导致的。
由此,我们可以一眼看出问题,然后定位问题代码的位置,接下来就是人工排查问题了。
2、查询出当前被阻塞的线程
命令:
thread -b
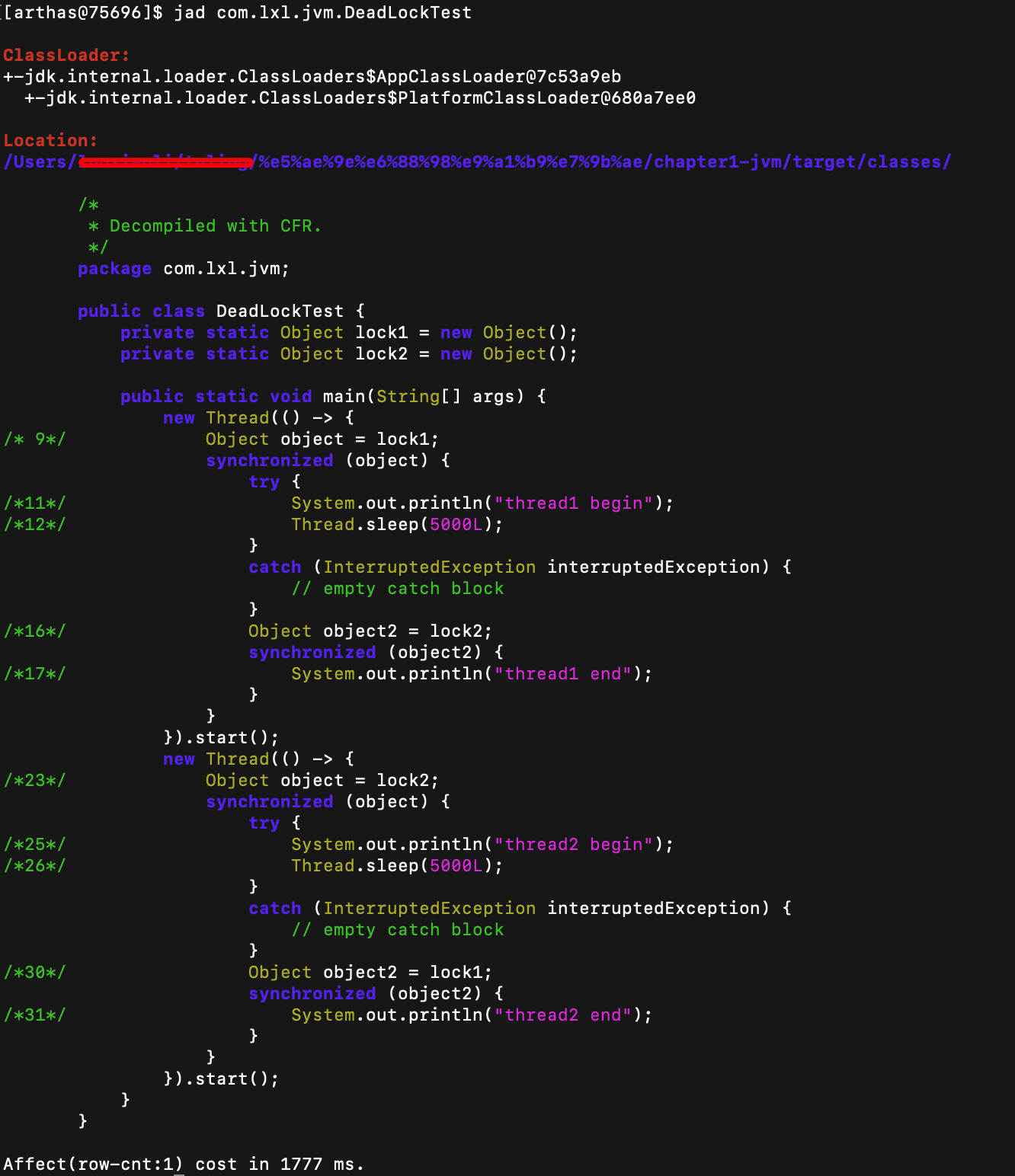
可以看到内容提示,线程Thread-1被线程Thread-0阻塞。对应的代码行数是DeadLockTest.java类的第31行。根据这个提示去查找代码问题。
3、指定采样的时间间隔
命令
thread -i 1000
这个的含义是个1s统计一次采样
4.反编译线上代码----这个功能很牛,改完发版了,怎么没生效,反编译看看。
说道Arthas,不得不提的一个功能就是线上反编译代码的功能。经常会发生的一种状况是,线上有问题,定位问题后立刻改代码,可是发版后发现没生效,不可能啊~~~刚刚提交成功了呀。于是重新发版,只能靠运气,不知道为啥没生效。
反编译线上代码可以让我们一目了然知道代码带动部分是否生效。反编译代码使用Arthas的jad命令
jad 命令将JVM中实际运行的class的byte code反编译成java代码
用法:
jad com.lxl.jvm.DeadLockTest
运行结果:

运行结果分析:这里包含3个部分
- ClassLoader:类加载器就是加载当前类的是哪一个类加载器
- Location: 类在本地保存的位置
- 源码:类反编译字节码后的源码
如果不想想是类加载信息和本地位置,只想要查看类源码信息,可以增加--source-only参数
jad --source-only 类全名
6. ognl 动态执行线上的代码
能够调用线上的代码,是不是很神奇了。感觉哪段代码执行有问题,但是又没有日志,就可以使用这个方法动态调用目标方法了。
我们下面的案例都是基于这段代码执行,User类:
public class User {
private int id;
private String name;
public User() {
}
public User(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
DeadLockTest类:
public class DeadLockTest {
private static Object lock1 = new Object();
private static Object lock2 = new Object();
private static List<String> names = new ArrayList<>();
private List<String> citys = new ArrayList<>();
public static String add() {
names.add("zhangsan");
names.add("lisi");
names.add("wangwu");
names.add("zhaoliu");
return "123456";
}
public List<String> getCitys() {
DeadLockTest deadLockTest = new DeadLockTest();
deadLockTest.citys.add("北京");
return deadLockTest.citys;
}
public static List<User> addUsers(Integer id, String name) {
List<User> users = new ArrayList<>();
User user = new User(id, name);
users.add(user);
return users;
}
public static void main(String[] args) {
new Thread(() -> {
synchronized (lock1) {
try {
System.out.println("thread1 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock2) {
System.out.println("thread1 end");
}
}
}).start();
new Thread(() -> {
synchronized (lock2) {
try {
System.out.println("thread2 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock1) {
System.out.println("thread2 end");
}
}
}).start();
}
}
1)获取静态函数
> 返回值是字符串
ognl '@全路径类名@静态方法名("参数")'
示例1:在DeadLockTest类中有一个add静态方法,我们来看看通过ognl怎么执行这个静态方法。执行命令
ognl '@com.lxl.jvm.DeadLockTest@add()'
其中,第一个@后面跟的是类的全名称;第二个@跟的是属性或者方法名,如果属性是一个对象,想要获取属性里面的属性或者方法,直接打.属性名/方法名 即可。
运行效果:
我们看到了这个对象的返回值是123456
> 返回值是对象
ognl '@全路径类名@静态方法名("参数")' -x 2
这里我们可以尝试一下替换-x 2 为 -x 1 ;-x 3;
* 案例1:返回对象的地址。不加 -x 或者是-x 1
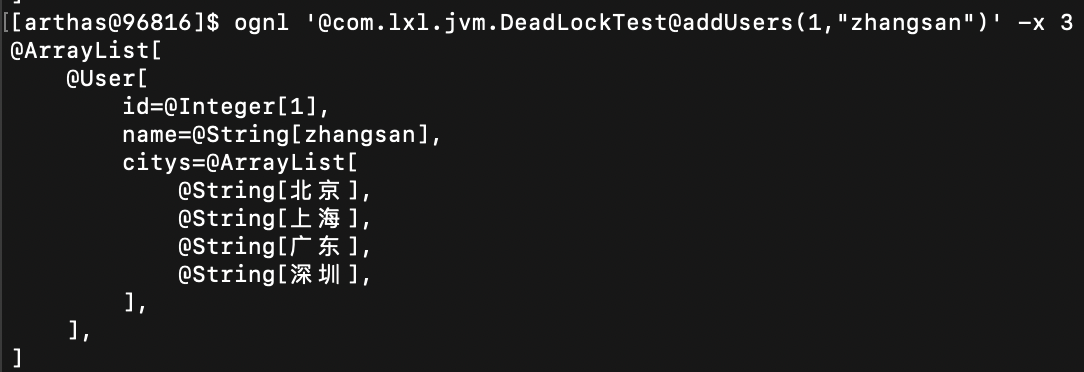
ognl '@com.lxl.jvm.DeadLockTest@addUsers(1,"zhangsan")'
或
ognl '@com.lxl.jvm.DeadLockTest@addUsers(1,"zhangsan")' -x 1
返回值
* 案例2:返回对象中具体参数的值。加 -x 2
ognl '@com.lxl.jvm.DeadLockTest@addUsers(1,"zhangsan")' -x 2
返回值

* 案例3:返回对象中有其他对象
- 命令:
ognl '@com.lxl.jvm.DeadLockTest@addUsers(1,"zhangsan")' -x 2
执行结果:
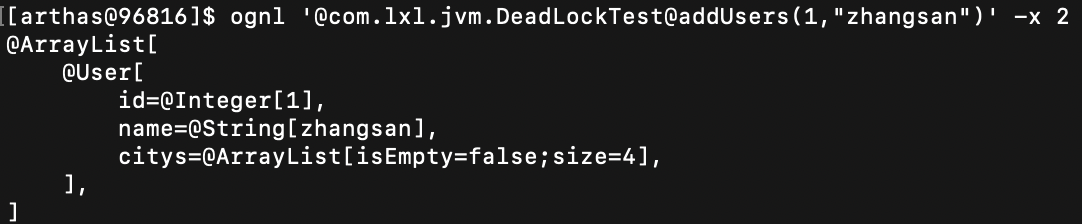
-x 2 获取的是对象的值,List返回的是数组信息,数组长度。
- 命令:
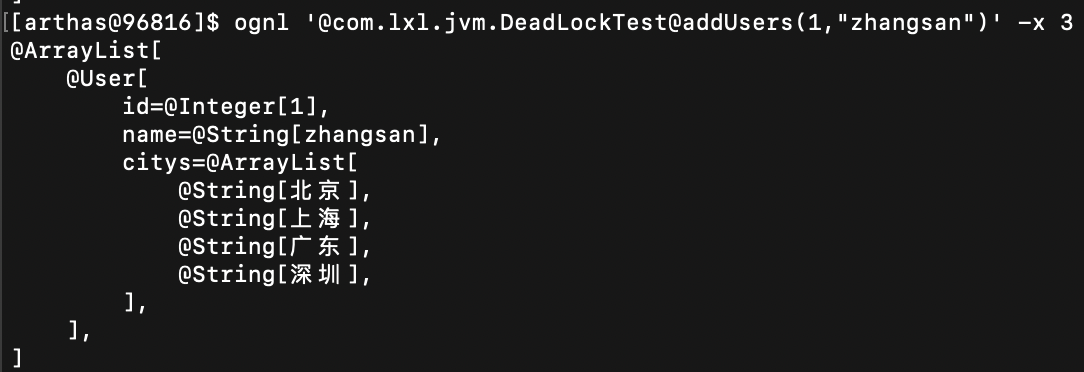
ognl '@com.lxl.jvm.DeadLockTest@addUsers(1,"zhangsan")' -x 3
执行结果:
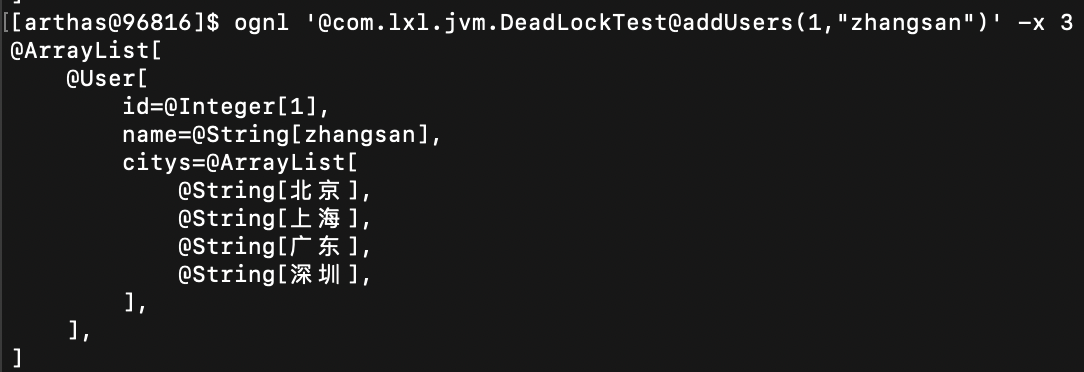
-x 3 打印出对象的值,对象中List列表中的值。
* 案例4:方法A的返回值当做方法B的入参
ognl '#value1=@com.lxl.jvm.DeadLockTest@getCitys(), #value2=@com.lxl.jvm.DeadLockTest@generatorUser(1,"lisi",#value1), {#value1,#value2}' -x 2

> 方法入参是简单类型的列表
ognl '@com.lxl.jvm.DeadLockTest@returnCitys({"beijing","shanghai","guangdong"})'

> 方法入参是一个复杂对象
ognl '#value1=new com.lxl.jvm.User(1,"zhangsan"),#value1.setName("aaa"), #value1.setCitys({"bj", "sh"}), #value2=@com.lxl.jvm.DeadLockTest@addUsers(#value1), #value2' -x 3

> 方法入参是一个map对象
ognl '#value1=new com.lxl.jvm.User(1,"zhangsan"), #value1.setCitys({"bj", "sh"}), #value2=#{"mum":"zhangnvshi","dad":"wangxiansheng"}, #value1.setFamily(#value2), #value1' -x 2

2)获取静态字段
ognl '@全路径类名@静态属性名'
示例:在DeadLockTest类中有一个names静态属性,下面来看看如何获取这个静态属性。执行命令:
ognl '@com.lxl.jvm.DeadLockTest@names'
其中,第一个@后面跟的是类的全名称;第二个@跟的是属性或者方法名,如果属性是一个对象,想要获取属性里面的属性或者方法,直接打.属性名/方法名 即可。
运行效果:
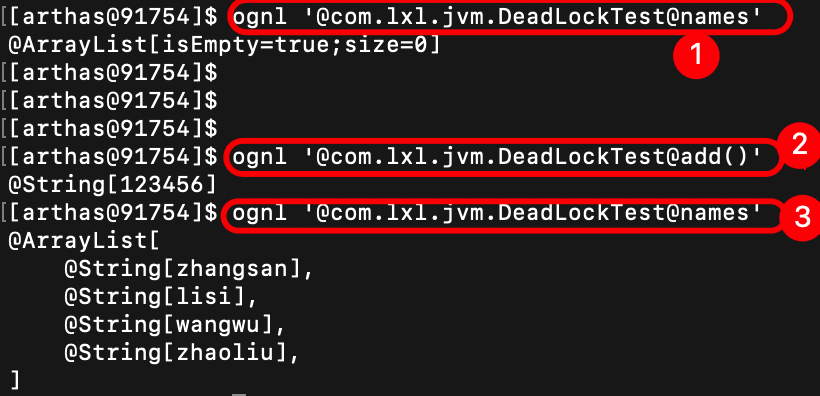
第一次执行获取属性命令,返回的属性是一个空集合;然后执行add方法,往names集合中添加了属性;再次请求names集合,发现有4个属性返回。
3) 获取实例对象
ognl '#value1=new com.lxl.jvm.User(1,"zhangsan"),#value1.setName("aaa"), #value1.setCitys({"bj", "sh"}), {#value1}' -x 2
获取实例对象,使用new关键字,执行结果:

7. 线上代码修改
生产环境有时会遇到非常紧急的问题,或突然发现一个bug,这时候不方便重新发版,或者发版未生效,可以使用Arthas临时修改线上代码。通过Arthas修改的步骤如下:
1. 从读取.class文件
2. 编译成.java文件
3. 修改.java文件
4. 将修改后的.java文件编译成新的.class文件
5. 将新的.class文件通过classloader加载进JVM内
第一步:读取.class文件
sc -d *DeadLockTest*
使用sc命令查看JVM已加载的类信息。关于sc命令,查看官方文档:https://arthas.aliyun.com/doc/sc.html
- -d : 表示打印类的详细信息
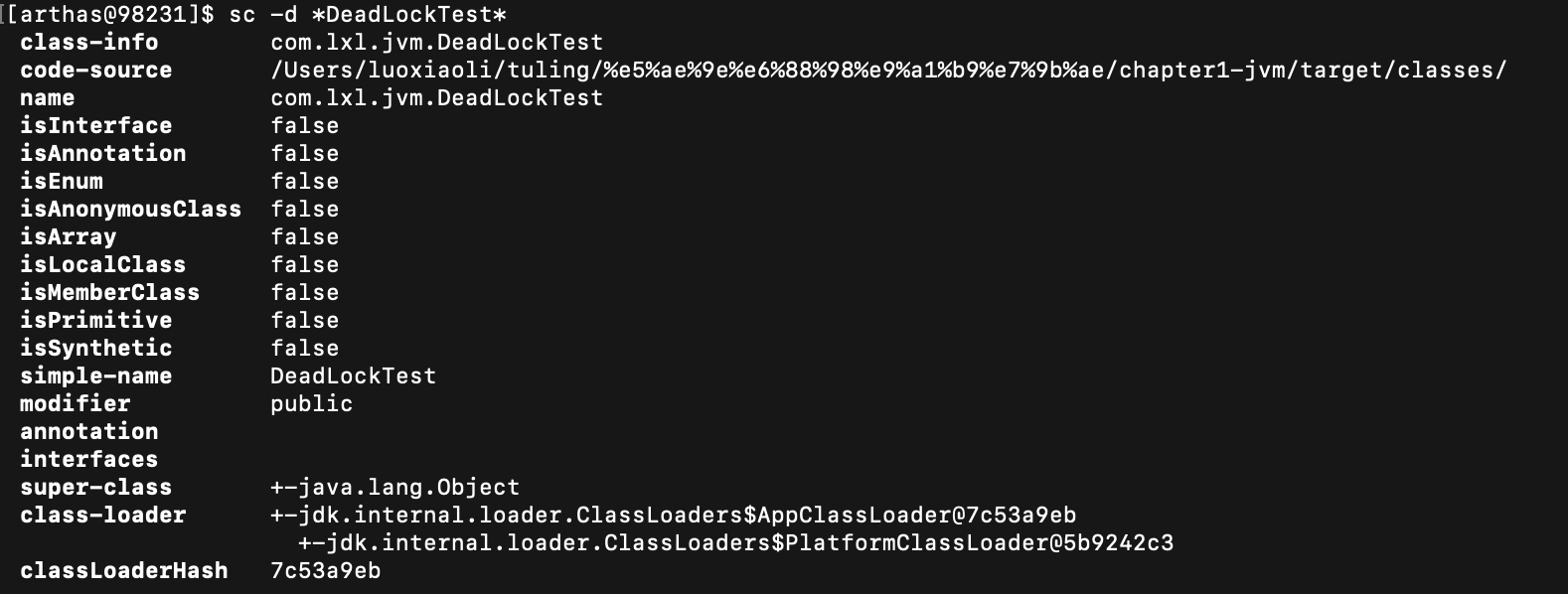
最后一个参数classLoaderHash,表示在jvm中类加载的hash值,我们要获得的就是这个值。
第二步:使用jad命令将.class文件反编译为.java文件才行
jad -c 7c53a9eb --source-only com.lxl.jvm.DeadLockTest > /Users/lxl/Downloads/DeadLockTest.java
- jad命令是反编译指定已加载类的源码
- -c : 类所属 ClassLoader 的 hashcode
- --source-only:默认情况下,反编译结果里会带有
ClassLoader信息,通过--source-only选项,可以只打印源代码。 - com.lxl.jvm.DeadLockTest:目标类的全路径
- /Users/lxl/Downloads/DeadLockTest.java:反编译文件的保存路径
/*
* Decompiled with CFR.
*
* Could not load the following classes:
* com.lxl.jvm.User
*/
package com.lxl.jvm;
import com.lxl.jvm.User;
import java.util.ArrayList;
import java.util.List;
public class DeadLockTest {
private static Object lock1 = new Object();
private static Object lock2 = new Object();
private static List<String> names = new ArrayList<String>();
private List<String> citys = new ArrayList<String>();
public static List<String> getCitys() {
DeadLockTest deadLockTest = new DeadLockTest();
/*25*/ deadLockTest.citys.add("北京");
/*27*/ return deadLockTest.citys;
}
......
public static void main(String[] args) {
......
}
}
这里截取了部分代码。
第三步:修改java文件
public static List<String> getCitys() {
System.out.println("-----这里增加了一句日志打印-----");
DeadLockTest deadLockTest = new DeadLockTest();
/*25*/ deadLockTest.citys.add("北京");
/*27*/ return deadLockTest.citys;
}
第四步:使用mc命令将.java文件编译成.class文件
mc -c 512ddf17 -d /Users/luoxiaoli/Downloads /Users/luoxiaoli/Downloads/DeadLockTest.java
- mc: 编译.java文件生.class文件, 详细使用方法参考官方文档https://arthas.aliyun.com/doc/mc.html
- -c:指定classloader的hash值
- -d:指定输出目录
- 最后一个参数是java文件路径
这是反编译后的class字节码文件
第五步:使用redefine命令,将.class文件重新加载进JVM
redefine -c /Users/***/Downloads/com/lxl/jvm/DeadLockTest.class

最后看到redefine success,表示重新加载.class文件进JVM成功了。
注意事项
redefine命令使用之后,再使用jad命令会使字节码重置,恢复为未修改之前的样子。官方关于redefine命令的说明
第六步:检验效果
这里检测效果,调用接口,执行日志即可。
8、实时修改生产环境的日志级别
这个功能也很好用,通常,我们在日志中打印的日志级别一般是infor、warn、error级别的,debug日志一般看不到。那么出问题的时候,一些日志,在写代码的时候会被记录在debug日志中,而此时日志级别又很高。那么迫切需要调整日志级别。
这个功能很好用啊,我们可以将平时不经常打印出来的日志设置为debug级别。设置线上日志打印级别为info。当线上有问题的时候,可以将日志级别动态调整为debug。异常排查完,在修改回info。这对访问量特别大日志内容很多的项目比较有效,可以有效节省日志输出带来的开销。
第一步:使用logger命令查看日志级别

- 当前应用的日志级别是info
- 类加载的hash值是18b4aac2
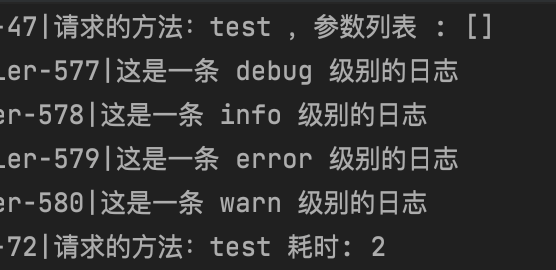
我们定义一个接口,其源代码内容如下:
@PostMapping(value = "test")
public String test() {
log.debug("这是一条 debug 级别的日志");
log.info("这是一条 info 级别的日志");
log.error("这是一条 error 级别的日志");
log.warn("这是一条 warn 级别的日志");
return "完成";
}
可以调用接口,查看日志输出代码。

我们看到,日志输出的是info及以下的级别。
第二步:修改logger日志的级别
logger -c 18b4aac2 --name ROOT --level debug
修改完日志级别以后,输出日志为debug级别。
8. 查询jvm信息,并修改----当发生内存溢出时,可以手动设置打印堆日志到文件
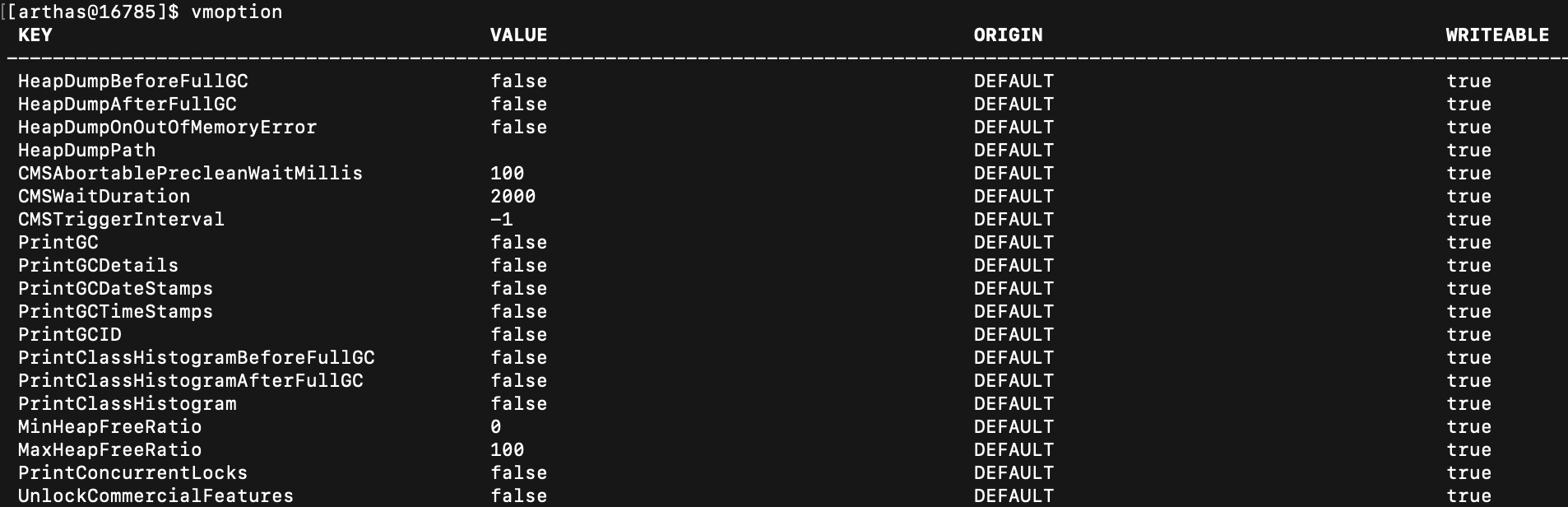
通常查询jvm参数,使用的是Java自带的工具[jinfo 进程号]。arthas中通过vmoption获取jvm参数:
假设,我们要设置JVM出现OutOfMemoryError的时候,自动dump堆快照
vmoption HeapDumpOnOutOfMemoryError true

这时,如果发生堆内存溢出,会打印日志到文件
9. 监控函数耗时
trace 待监控方法的全类名 待监控的方法名
trace com.lxl.jvm.DeadLockTest generatorUser
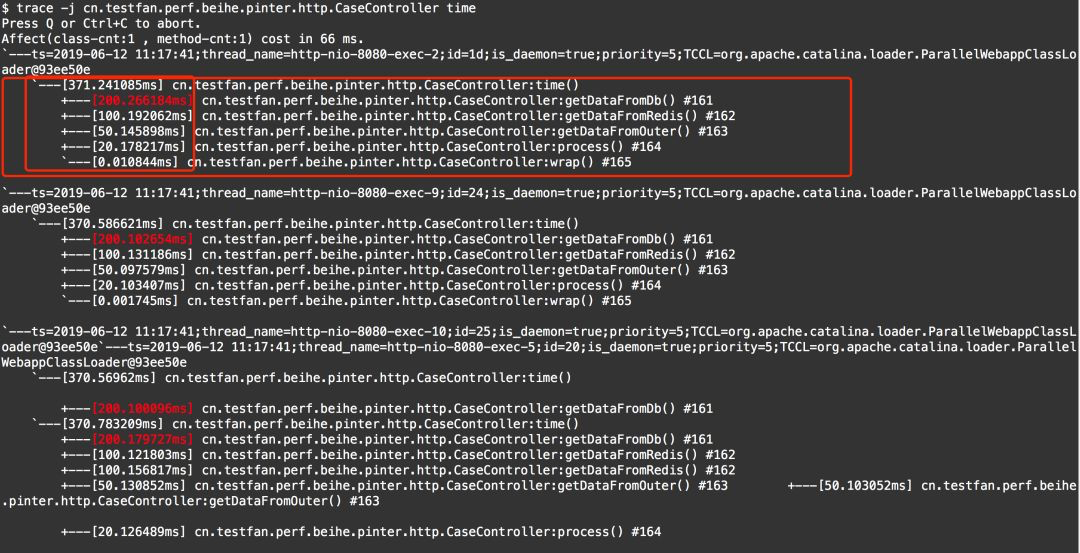
- 通过圈起来的部分可以看到,接口的入口函数time总耗时371ms
- 其中getDataFromDb函数耗时200ms
- getDataFromRedis函数耗时100ms
- getDataFromOuter函数耗时50ms
- process函数耗时20ms
很明显,最慢的函数已经找到了,接下里就要去对代码进行进一步分析,然后再进行优化



