
一次大量 JVM Native 内存泄露的排查分析(64M 问题)原创
我们有一个线上的项目,刚启动完就占用了使用 top 命令查看 RES 占用了超过 1.5G,这明显不合理,于是进行了一些分析找到了根本的原因,下面是完整的分析过程,希望对你有所帮助。
会涉及到下面这些内容
-
Linux 经典的 64M 内存问题 -
堆内存分析、Native 内存分析的基本套路 -
tcmalloc、jemalloc 在 native 内存分析中的使用 -
finalize 原理 -
hibernate 毁人不倦
现象
程序启动的参数
ENV=FAT java
-Xms1g -Xmx1g
-XX:MetaspaceSize=120m
-XX:MaxMetaspaceSize=400m
-XX:+UseConcMarkSweepGC
-jar
EasiCareBroadCastRPC.jar
启动后内存占用如下,惊人的 1.5G,Java 是内存大户,但是你也别这么玩啊。
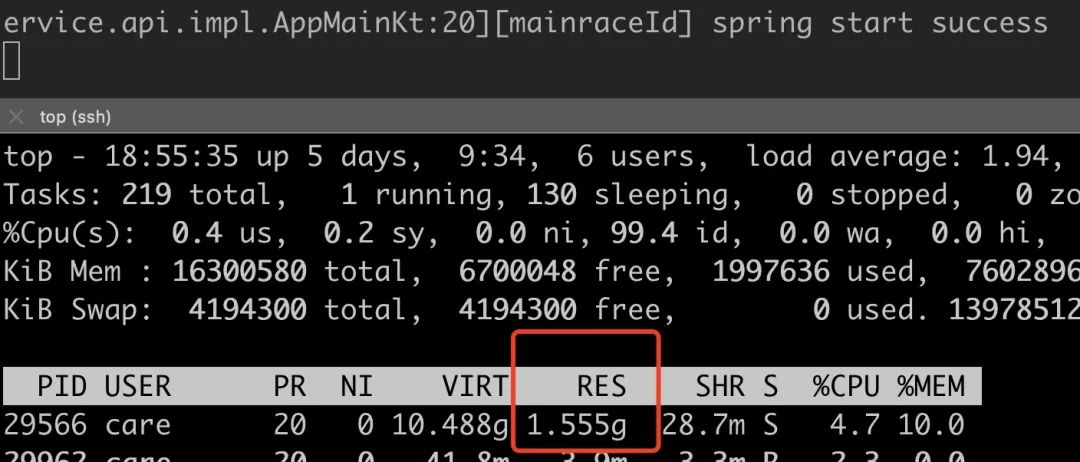
下面是愉快的分析过程。
柿子先挑软的捏
先通过 jcmd 或者 jmap 查看堆内存是否占用比较高,如果是这个问题,那很快就可以解决了。
可以看到堆内存占用 216937K + 284294K = 489.48M,Metaspace 内存虽然不属于 Java 堆,这里也显示了出来占用 80M+,这两部分加起来,远没有到 1.5G。
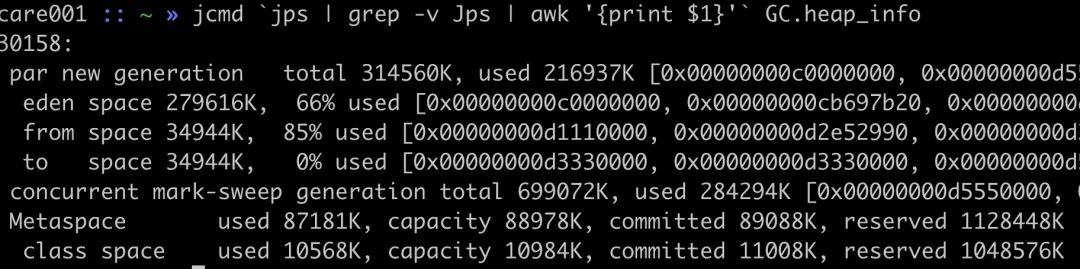
那剩下的内存去了哪里?到这里,已经可以知道可能是堆以外的部分占用了内存,接下来就是开始使用 NativeMemoryTracking 来进行下一步分析。
NativeMemoryTracking 使用
如果要跟踪其它部分的内存占用,需要通过 -XX:NativeMemoryTracking 来开启这个特性
java -XX:NativeMemoryTracking=[off | summary | detail]
加入这个启动参数,重新启动进程,随后使用 jcmd 来打印相关的信息。
$ jcmd `jps | grep -v Jps | awk '{print $1}'` VM.native_memory detail
Total: reserved=2656938KB, committed=1405158KB
- Java Heap (reserved=1048576KB, committed=1048576KB)
(mmap: reserved=1048576KB, committed=1048576KB)
- Class (reserved=1130053KB, committed=90693KB)
(classes #15920)
(malloc=1605KB #13168)
(mmap: reserved=1128448KB, committed=89088KB)
- Thread (reserved=109353KB, committed=109353KB)
(thread #107)
(stack: reserved=108884KB, committed=108884KB)
(malloc=345KB #546)
(arena=124KB #208)
- Code (reserved=257151KB, committed=44731KB)
(malloc=7551KB #9960)
(mmap: reserved=249600KB, committed=37180KB)
- GC (reserved=26209KB, committed=26209KB)
(malloc=22789KB #306)
(mmap: reserved=3420KB, committed=3420KB)
- Compiler (reserved=226KB, committed=226KB)
(malloc=95KB #679)
(arena=131KB #7)
- Internal (reserved=15063KB, committed=15063KB)
(malloc=15031KB #20359)
(mmap: reserved=32KB, committed=32KB)
- Symbol (reserved=22139KB, committed=22139KB)
(malloc=18423KB #196776)
(arena=3716KB #1)
很失望,这里面显示的所有的部分,看起来都很正常,没有特别大异常占用的情况,到这里我们基本上可以知道是不受 JVM 管控的 native 内存出了问题,那要怎么分析呢?
pmap 初步查看
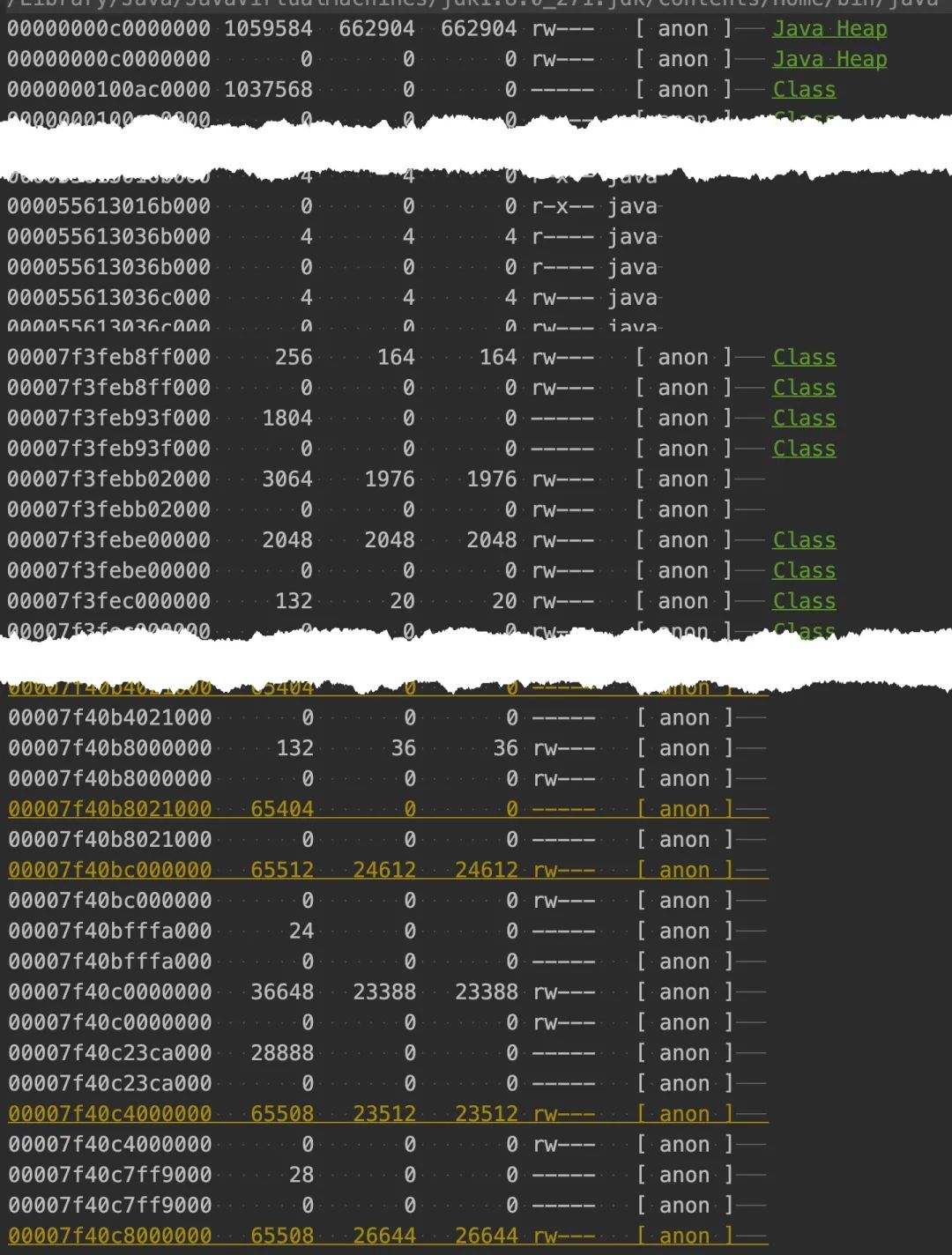
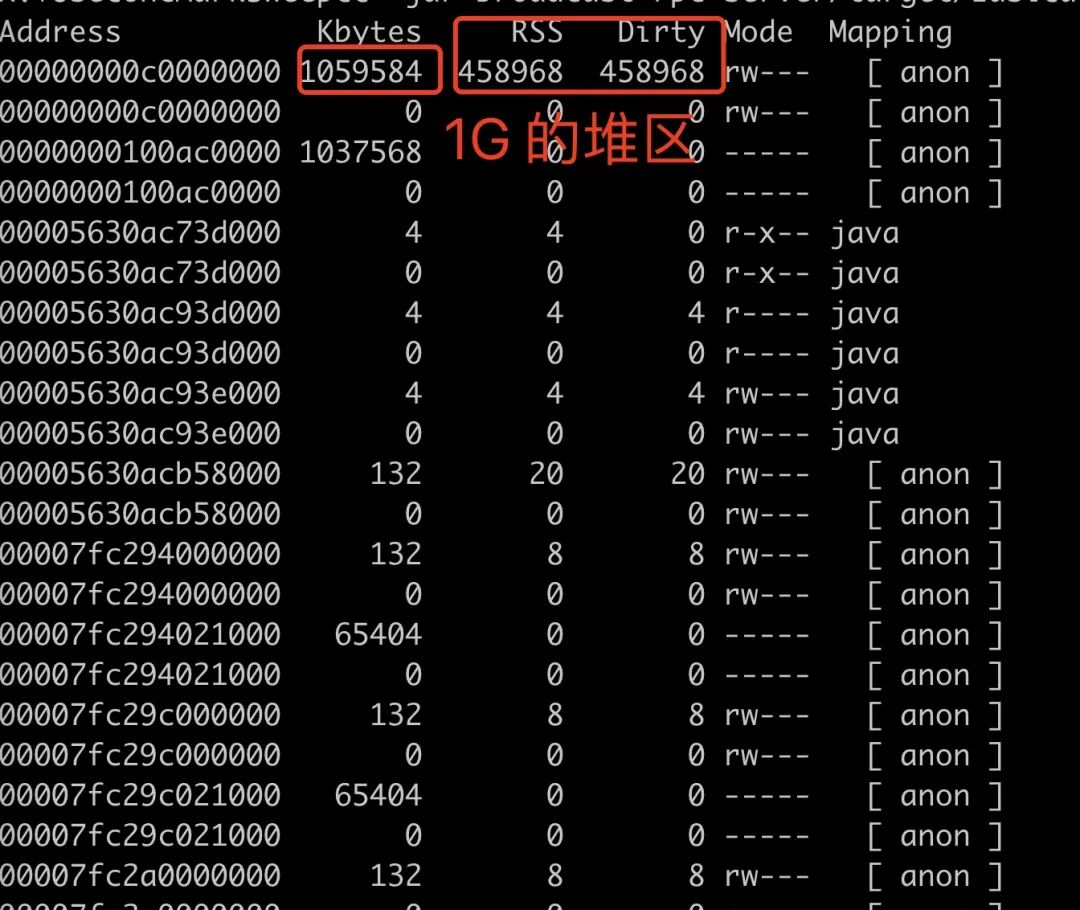
通过 pmap 我们可以查看进程的内存分布,可以看到有大量的 64M 内存区块区域,这部分是 linux 内存 ptmalloc 的典型现象,这个问题在之前的一篇「一次 Java 进程 OOM 的排查分析(glibc 篇)」已经介绍过了,详见:https://juejin.cn/post/6854573220733911048
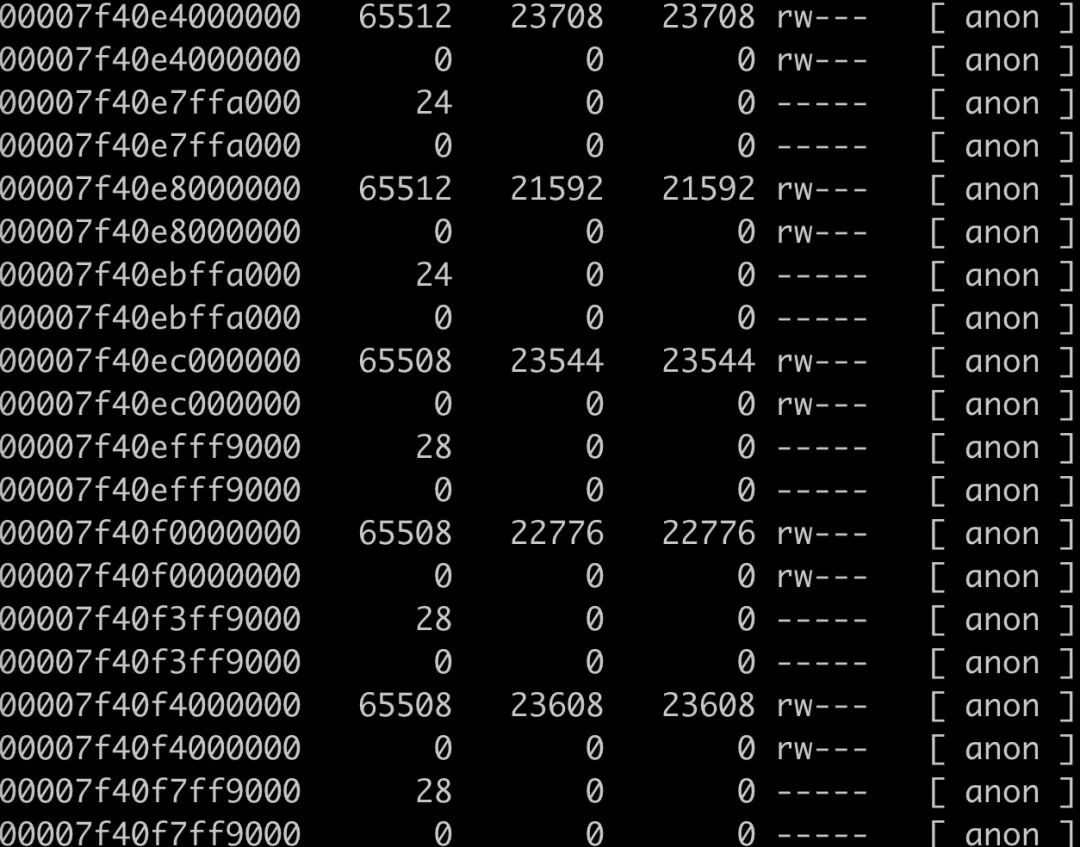
那这 64M 的内存区域块,是不是在上面 NMT 统计的内存区域里呢?
NMT 工具的地址输出 detail 模式会把每个区域的起始结束地址输出出来,如下所示。
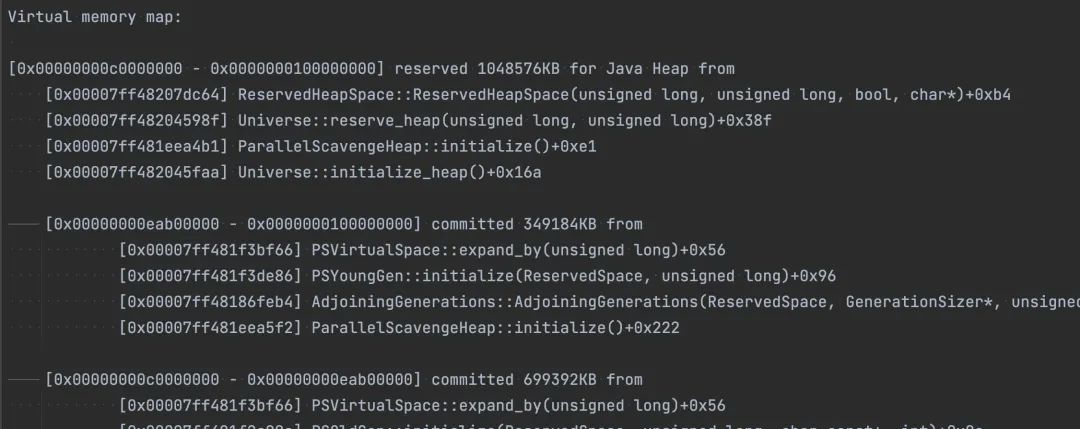
写一个简单的代码(自己正则搞一下就行了)就可以将 pmap、nmt 两部分整合起来,看看真正的堆、栈、GC 等内存占用分布在内存地址空间的哪一个部分。
可以看到大量 64M 部分的内存区域不属于任何 NMT 管辖的部分。
tcmalloc、jemalloc 来救场
我们可以通过 tcmalloc 或者 jemalloc 可以做 native 内存分配的追踪,它们的原理都是 hook 系统 malloc、free 等内存申请释放函数的实现,增加 profile 的逻辑。
下面以 tcmalloc 为例。
从源码编译 tcmalloc(http://github.com/gperftools/gperftools),然后通过 LD_PRELOAD 来 hook 内存分配释放的函数。
HEAPPROFILE=./heap.log
HEAP_PROFILE_ALLOCATION_INTERVAL=104857600
LD_PRELOAD=./libtcmalloc_and_profiler.so
java -jar xxx ...
启动过程中就会看到生成了很多内存 dump 的分析文件,接下来使用 pprof 将 heap 文件转为可读性比较好的 pdf 文件。
pprof --pdf /path/to/java heap.log.xx.heap > test.pdf
内存申请的链路如下图所示。
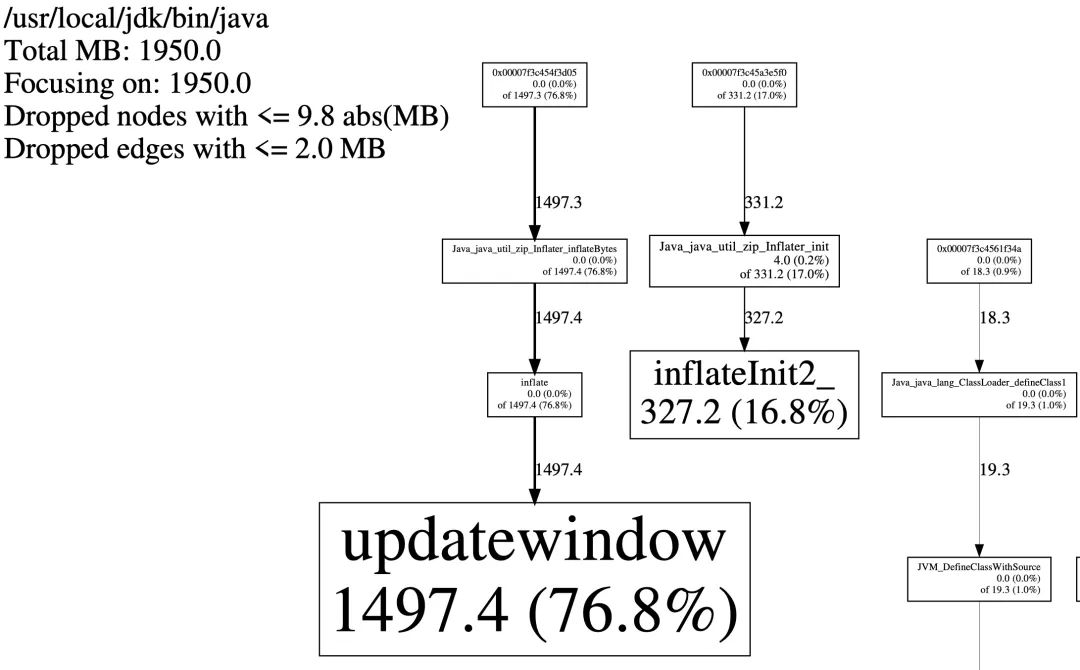
可以看到绝大部分的内存申请都耗在了 Java_java_util_zip_Inflater_inflateBytes,jar 包本质就是一个 zip 包, 在读取 jar 包文件过程中大量使用了 jni 中的 cpp 代码来处理,这里面大量申请释放了内存。
不用改代码的解决方式
既然是因为读取 jar 包这个 zip 文件导致的内存疯长,那我不用 java -jar,直接把原 jar 包解压,然后用 java -cp . AppMain 来启动是不是可以避免这个问题呢?因为我们项目因为历史原因是使用 shade 的方式,里面已经没有任何 jar 包了,全是 class 文件。奇迹出现了,不用 jar 包启动,RES 占用只有 400M,神奇不神奇!
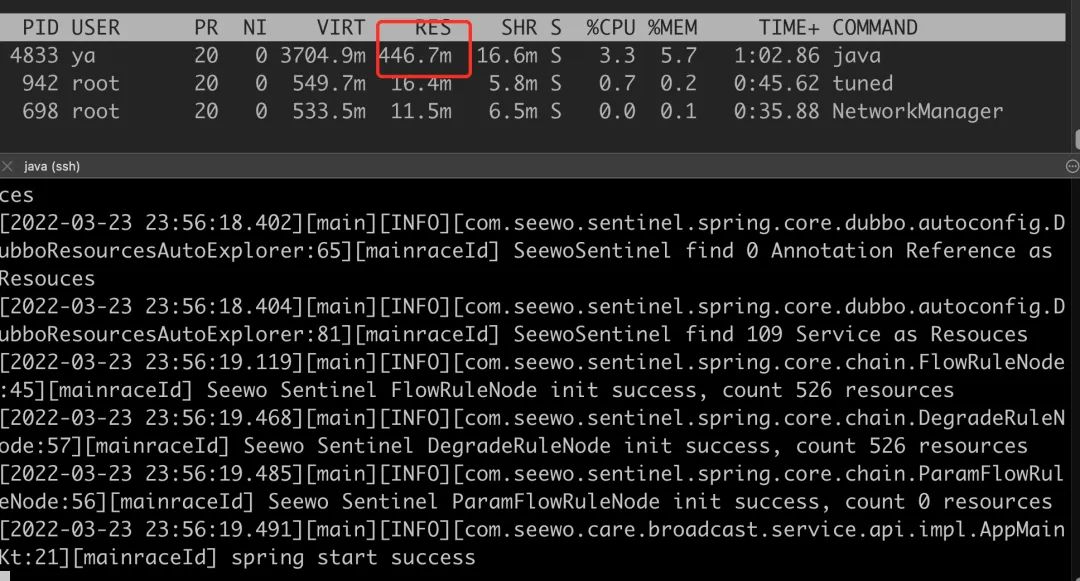
到这里,我们更加确定是 jar 包启动导致的问题,那为什么 jar 包启动会导致问题呢?
探究根本原因
通过 tcmalloc 可以看到大量申请释放内存的地方在 java.util.zip.Inflater 类,调用它的 end 方法会释放 native 的内存。
我本以为是 end 方法没有调用导致的,这种的确是有可能的,java.util.zip.InflaterInputStream 类的 close 方法在一些场景下是不会调用 Inflater.end 方法,如下所示。
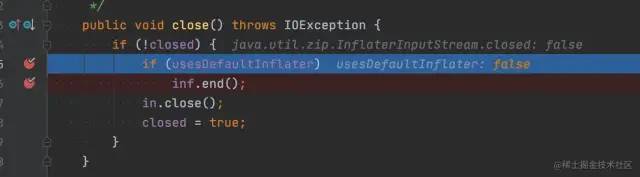
但是 Inflater 类有实现 finalize 方法,在 Inflater 对象不可达以后,JVM 会帮忙调用 Inflater 类的 finalize 方法,
public class Inflater {
public void end() {
synchronized (zsRef) {
long addr = zsRef.address();
zsRef.clear();
if (addr != 0) {
end(addr);
buf = null;
}
}
}
/**
* Closes the decompressor when garbage is collected.
*/
protected void finalize() {
end();
}
private native static void initIDs();
// ...
private native static void end(long addr);
}
有两种可能性
-
Inflater 因为被其它对象引用,没能释放,导致 finalize 方法不能被调用,内存自然没法释放 -
Inflater 的 finalize 方法被调用,但是被 libc 的 ptmalloc 缓存,没能真正释放回操作系统
第二种可能性,我之前在另外一篇文章「一次 Java 进程 OOM 的排查分析(glibc 篇)」已经介绍过了,详见:https://juejin.cn/post/6854573220733911048 ,经验证,不是这个问题。
我们来看第一个可能性,通过 dump 堆内存来查看。果然,有 8 个 Inflater 对象还存活没能被 GC,除了被 JVM 内部的 java.lang.ref.Finalizer 引用,还有其它的引用,导致 Inflater 在 GC 时无法被回收。
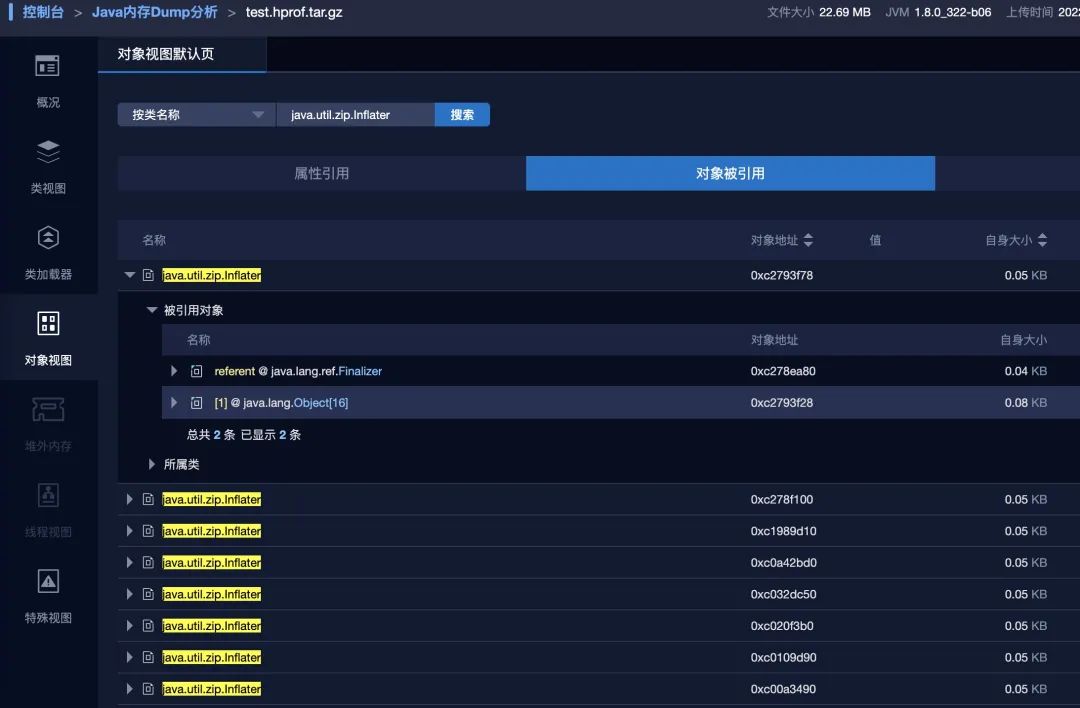
那这些内存是不是真的跟 64M 的内存区块有关呢?空口无凭,我们来确认一把。Inflater 类有一个 zsRef 字段,其实它就是一个指针地址,我们看看未释放的 Inflater 的 zsRef 地址是不是位于我们所说的 64M 内存区块里。
public class Inflater {
private final ZStreamRef zsRef;
}
class ZStreamRef {
private volatile long address;
ZStreamRef (long address) {
this.address = address;
}
long address() {
return address;
}
void clear() {
address = 0;
}
}
通过一个 ZStreamRef 找到 address 等于 140686448095872,转为 16 进制为 0x7ff41dc37280,这个地址位于的虚拟地址空间在这里:
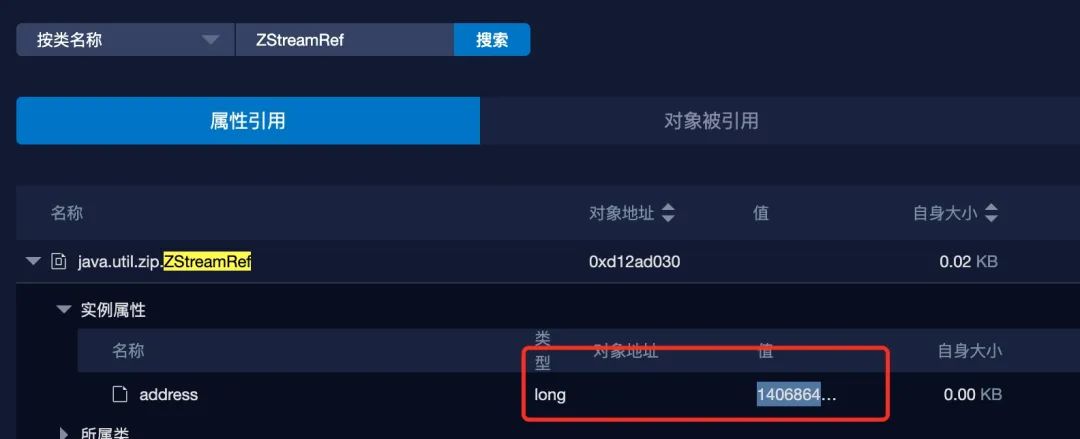
正是在我们所说的 64M 内存区块中。
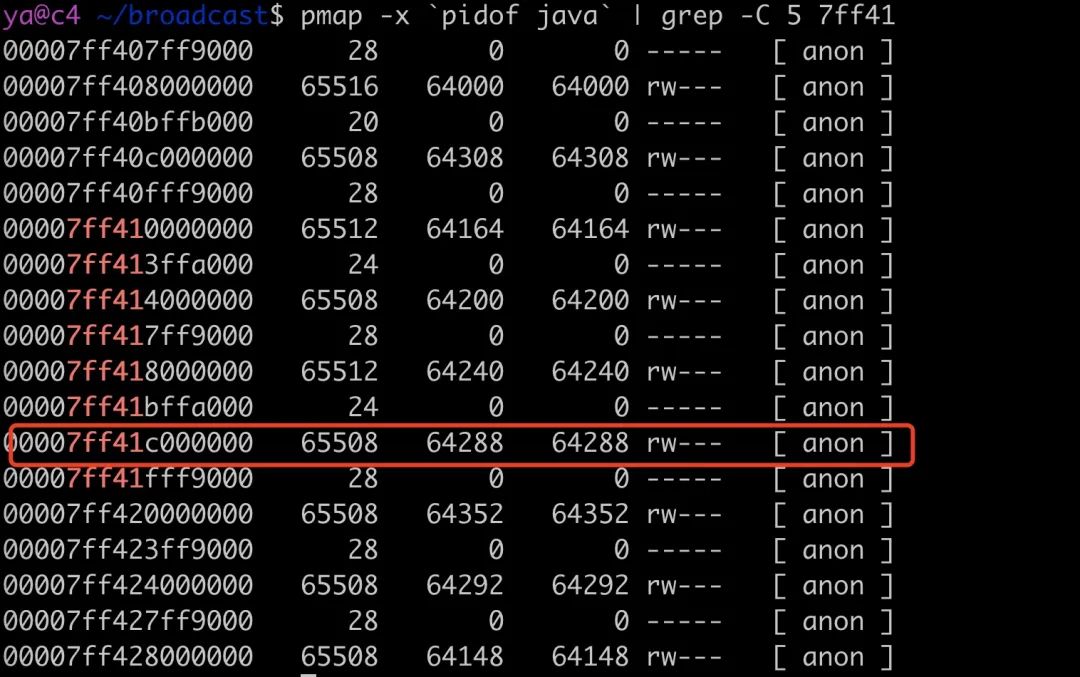
如果你还不信,我们可以 dump 这块内存,我这里写了一个脚本
cat /proc/$1/maps | grep -Fv ".so" | grep " 0 " | awk '{print $1}' | grep $2 | ( IFS="-"
while read a b; do
dd if=/proc/$1/mem bs=$( getconf PAGESIZE ) iflag=skip_bytes,count_bytes \
skip=$(( 0x$a )) count=$(( 0x$b - 0x$a )) of="$1_mem_$a.bin"
done )
通过传入进程号和你想 dump 的内存起始地址,就可以把这块内存 dump 出来。
./dump.sh `pidof java` 7ff41c000000
执行上面的脚本,传入两个参数,一个是进程 id,一个地址,会生成一个 64M 的内存 dump 文件,通过 strings 查看。
strings 6095_mem_7ff41c000000.bin
输出结果如下,满屏的都是类文件相关的信息。
到这里已经应该无需再证明什么了,剩下的就是分析的事了。
那到底是被谁引用的呢?展开引用链,看到出现了一堆 ClassLoader。
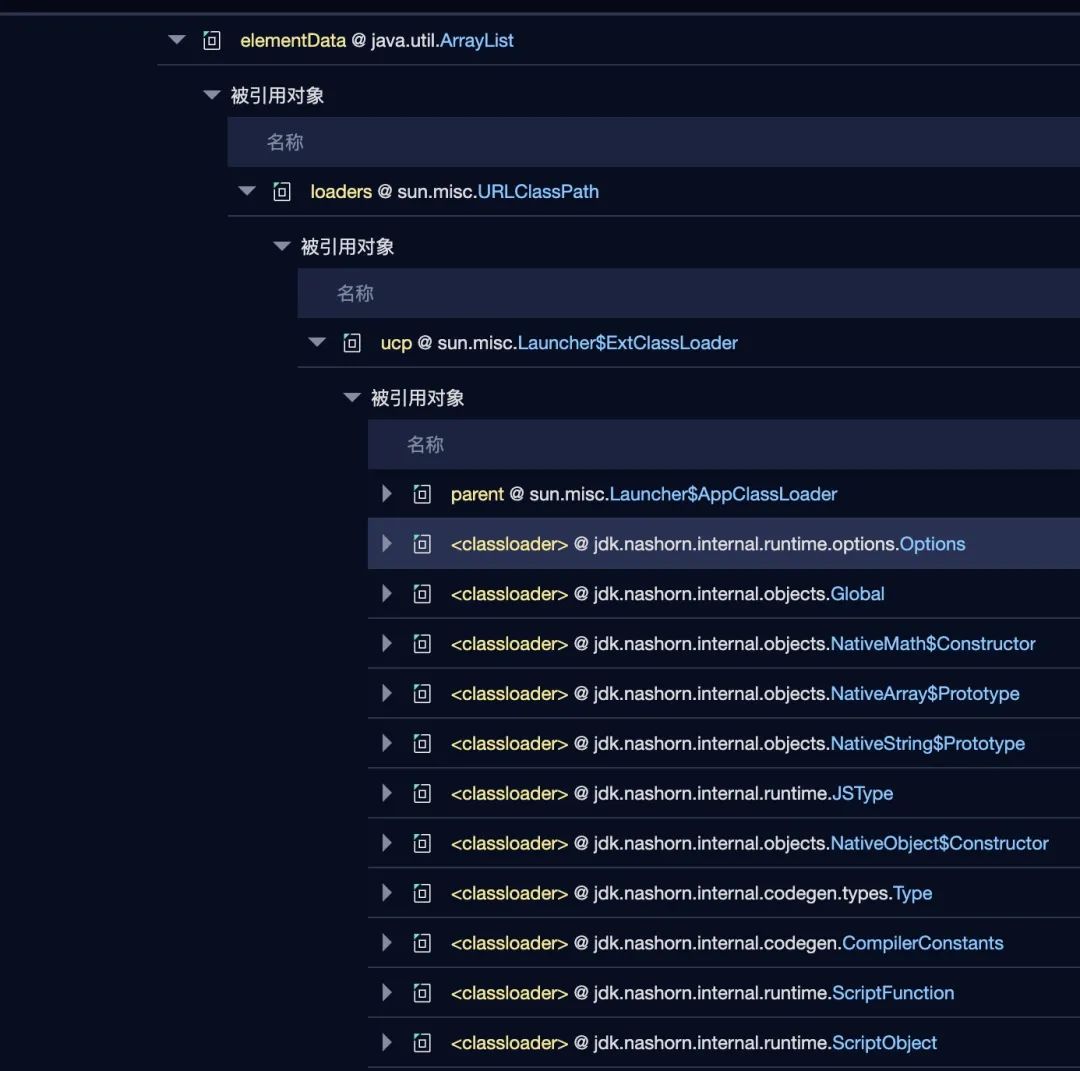
一个意外的发现(与本问题关系不大,顺手解决一下)
这里出现了一个很奇怪的 nashorn 相关的 ClassLoader,众所周不知,nashorn 是处理 JavaScript 相关的逻辑的,那为毛这个项目会用到 nashorn 呢?经过仔细搜索,项目代码并没有使用。
那是哪个坑货中间件引入的呢?debug 一下马上就找到了原因,原来是臭名昭著的 log4j2,用了这么多年 log4j,头一回知道,原来 log4j2 是支持 javaScript、Groovy 等脚本语言的。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="debug" name="RoutingTest">
<Scripts>
<Script name="selector" language="javascript"><![CDATA[
var result;
if (logEvent.getLoggerName().equals("JavascriptNoLocation")) {
result = "NoLocation";
} else if (logEvent.getMarker() != null && logEvent.getMarker().isInstanceOf("FLOW")) {
result = "Flow";
}
result;
]]></Script>
<ScriptFile name="groovy.filter" path="scripts/filter.groovy"/>
</Scripts>
</Configuration>
我们项目中并没有用到类似的特性(因为不知道),只能说真是无语,你好好的当一个工具人日志库不好吗,搞这么多花里胡哨的东西,肤浅!
代码在这里
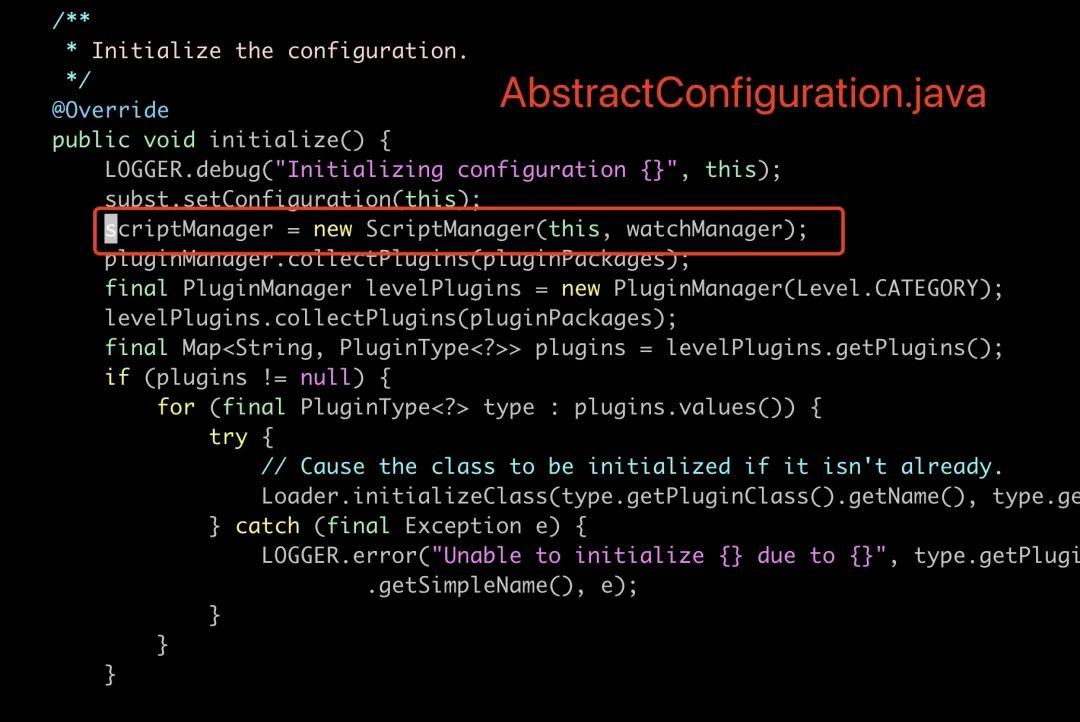
这个问题我粗略看了一下,截止到官方最新版还没有一个开关可以关掉 ScriptEngine,不行就自己上,自己拉取项目中 log4j 对应版本的代码,做了修改,重新打包运行,
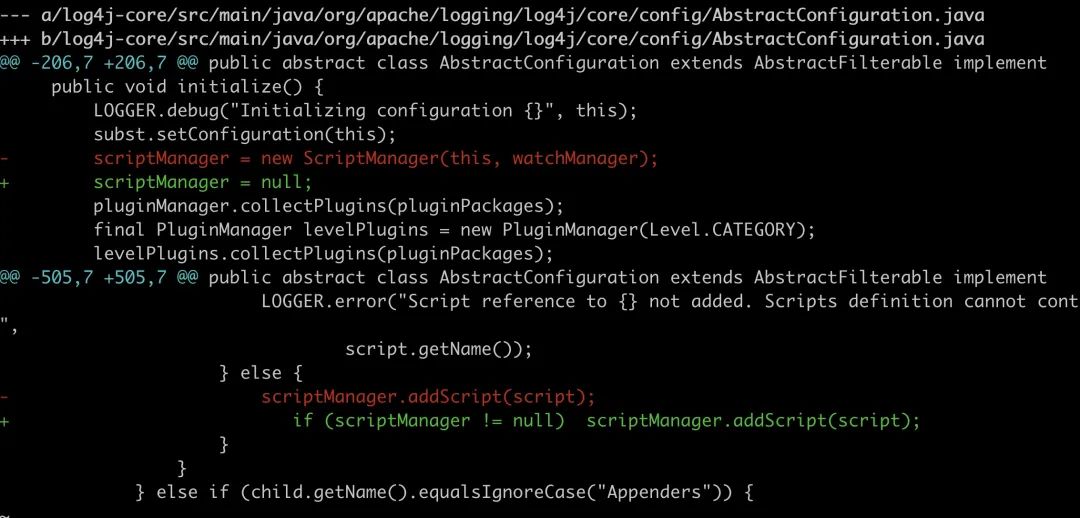
重新运行后 nashorn 部分的 ClassLoader 确实没有了,不过这里只是一个小插曲,native 内存占用的问题并没有解决。
凶手浮出水面
接下来我们就要找哪些代码在疯狂调用 java.util.zip.Inflater.inflateBytes 方法
使用 watch 每秒 jstack 一下线程,马上就看到了 hibernate 在疯狂的调用。
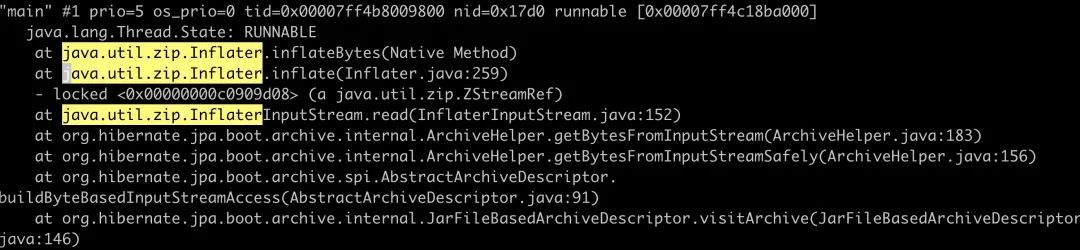
hibernate 是我们历史老代码遗留下来的,一直没有移除掉,看来还是踩坑了。
找到这个函数对应代码 org.hibernate.jpa.boot.archive.internal.JarFileBasedArchiveDescriptor#visitArchive#146
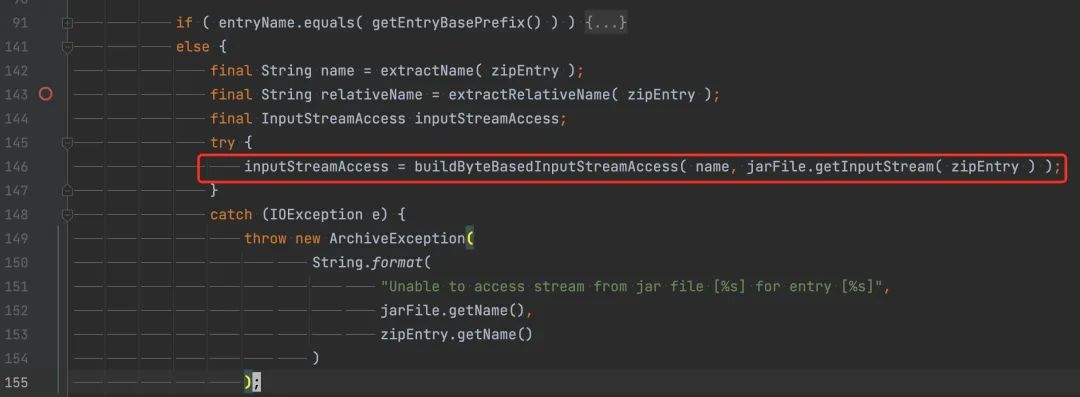
垃圾代码,jarFile.getInputStream( zipEntry ) 生成了一个新的流但没有做关闭处理。
其实我也不知道,为啥 hibernate 要把我 jar 包中所有的类都扫描解析一遍,完全有毛病。
我们来把这段代码扒出来,写一个最简 demo。
public class JarFileTest {
public static void main(String[] args) throws IOException {
new JarFileTest().process();
System.in.read();
}
public static byte[] getBytesFromInputStream(InputStream inputStream) throws IOException {
// 省略 read 的逻辑
return result;
}
public void process() throws IOException {
JarFile jarFile = null;
try {
jarFile = new JarFile("/data/dev/broadcast/EasiCareBroadCastRPC.jar");
final Enumeration<? extends ZipEntry> zipEntries = jarFile.entries();
while (zipEntries.hasMoreElements()) {
final ZipEntry zipEntry = zipEntries.nextElement();
if (zipEntry.isDirectory()) {
continue;
}
byte[] bytes = getBytesFromInputStream(jarFile.getInputStream(zipEntry));
System.out.println("processing: " + zipEntry.getName() + "\t" + bytes.length);
}
} finally {
try {
if (jarFile != null) jarFile.close();
} catch (Exception e) {
}
}
}
}
运行上面的代码。
javac JarFileTest.java
java -Xms1g -Xmx1g -XX:MetaspaceSize=120m -XX:MaxMetaspaceSize=400m -XX:+UseConcMarkSweepGC -cp . JarFileTest
内存 RES 占用立马飙升到了 1.2G 以上,且无论如何 GC 都无法回收,但堆内存几乎等于 0。
RES 内存占用如下所示。
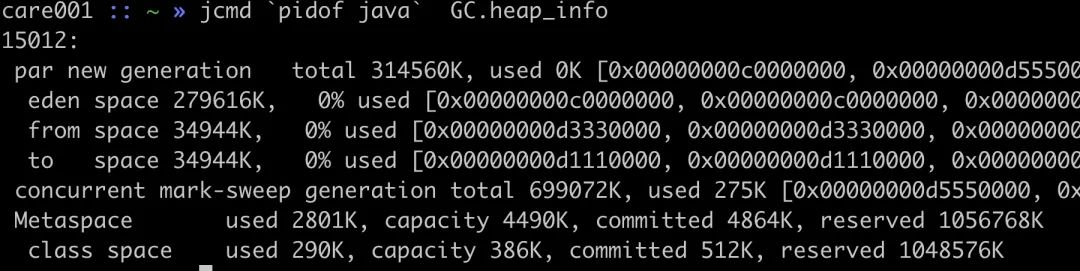
堆内存占用如下所示,经过 GC 以后新生代占用为 0,老年代占用为 275K
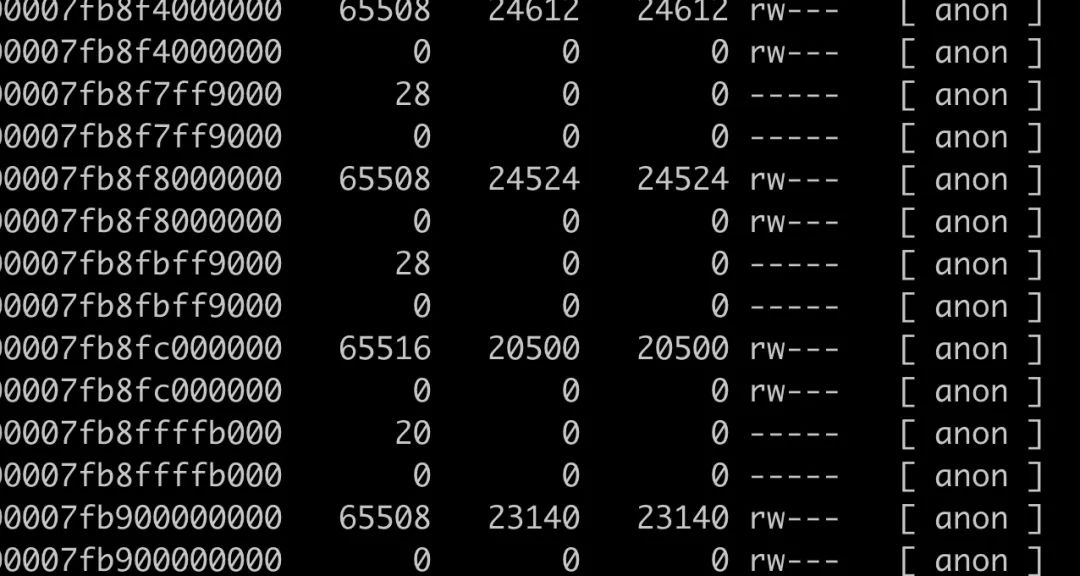
全被 64M 内存占满。
通过修改代码,将流关闭
while (zipEntries.hasMoreElements()) {
final ZipEntry zipEntry = zipEntries.nextElement();
if (zipEntry.isDirectory()) {
continue;
}
InputStream is = jarFile.getInputStream(zipEntry);
byte[] bytes = getBytesFromInputStream(is);
System.out.println("processing: " + zipEntry.getName() + "\t" + bytes.length);
try {
is.close();
} catch (Exception e) {
}
}
再次测试,问题解决了,native 内存占用几乎消失了,接下来就是解决项目中的问题。一种是彻底移除 hibernate,将它替换为我们现在在用的 mybatis,这个我不会。我打算来改一下 hibernate 的源码。
尝试修改
修改这段代码(ps这里是不成熟的改动,close 都应该放 finally,多个 close 需要分别捕获异常,但是为了简单,这里先简化),加入 close 的逻辑。
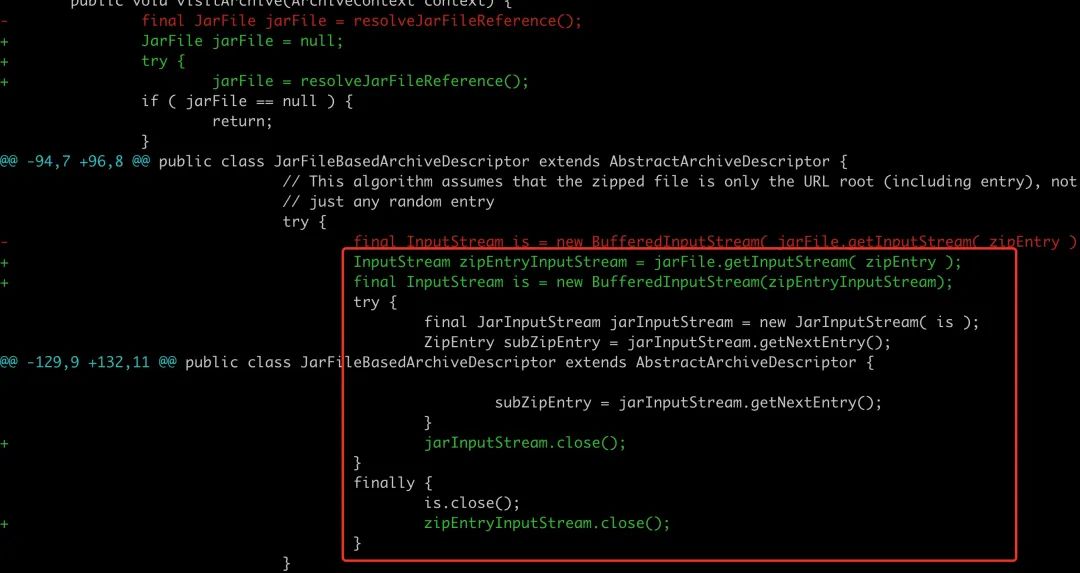
重新编译 hibernate,install 到本地,然后重新打包运行。此时 RES 占用从 1.5G 左右降到了 700 多 M。
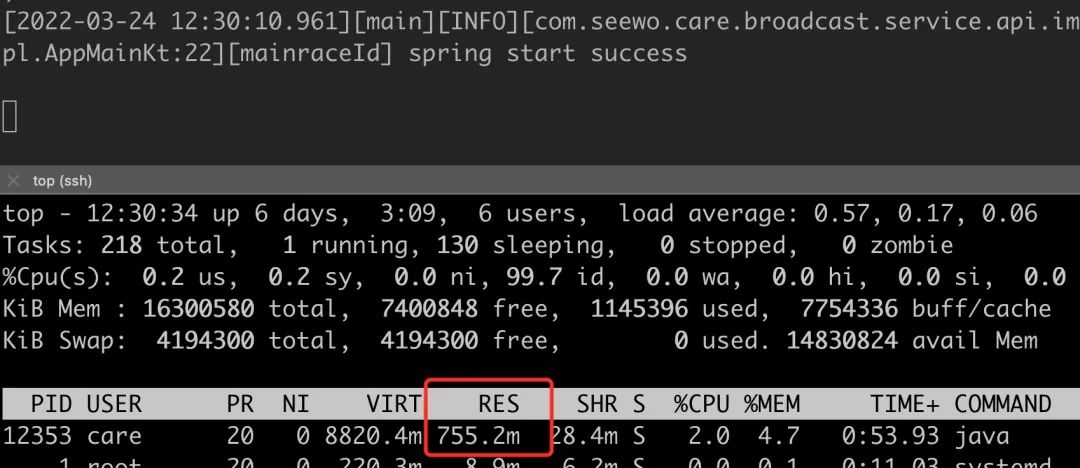
而且比较可喜的是,64M 区块的 native 内存占用非常非常小,这里 700M 内存有 448M 是 dirty 的 heap 区,这部分只是 JVM 预留的。
到这里,我们基本上已经解决了这个问题。后面我去看了一下 hibernate 的源码,在新版本里面,已经解决了这个问题,但是我不打算升级了,干掉了事。

详见:
https://github.com/hibernate/hibernate-orm/blob/72e0d593b997681125a0f12fe4cb6ee7100fe120/hibernate-core/src/main/java/org/hibernate/boot/archive/internal/JarFileBasedArchiveDescriptor.java#L116
后记
因为不是本文的重点,文章涉及的一些工具的使用,我没有展开来聊,大家感兴趣可以自己搞定。
其实 native 内存泄露没有我们想象的那么复杂,可以通过 NMT、pmap、tcmalloc 逐步逐步进行分析,只要能复现,都不叫 bug。
最后珍爱生命,远离 hibernate。



