
多机房灾备实践原创
2017年主导了公司新机房(100多台服务器规模)建设以及机房切换,前期工作主要是招标选供应商,服务器,网络设备等,定下来后就开始进行采购,2017年过年之前设备到位。年后开始规划实施。下面我就分享下机房建设以及迁移的经验。
一. 为何要做多机房
单一机房机房不可用时,业务停止,数据无法访问。不同地域的用户请求响应延时不同,CDN只能解决静态资源访问加速。多机房可以备份用户和系统数据,保证数据安全,一个机房出现故障可以切换到另外机房,提高系统可用性,按用户地域合理分配,访问就近的机房。
二. 理论依据
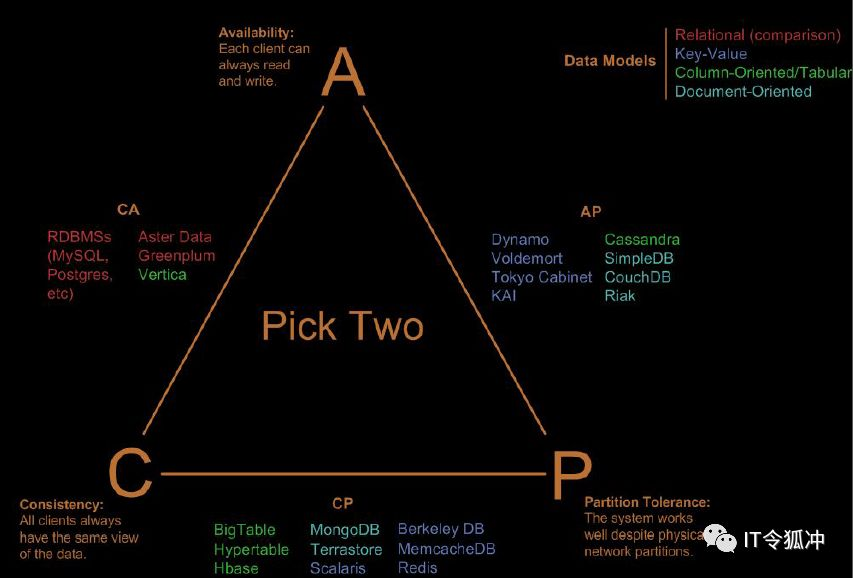
根据不同行业,以及CAP的三选二原则,支付、交易要求强一致(不允许出现脏数据),属于CA,互联网对强一致性要求不高,对可用性要求较高,一般都采用AP+弱一致性架构,也就是BSAE,BASE理论是eBay的架构师Dan Pritchett在ACM上发表文章提出的,BASE是指基本可用(Basically Available)、软状态(Soft State)、最终一致性(Eventual Consistency),允许窗口期数据不一致。
三 具体实践
1、新机房建设
-
IDC机房选购
选型、招标、参观机房、评审、商务谈判、合同签署、开通宽带 -
网络架构设计及评审
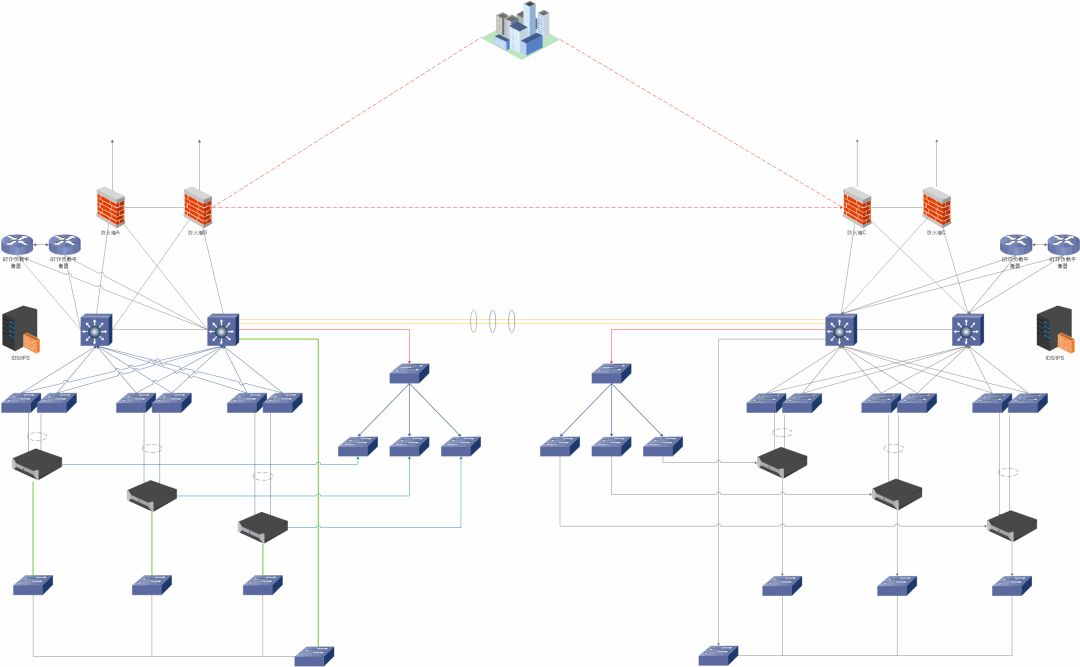
-
服务器/网络设备选购
设备选型、招标、商务谈判、合同签署、设备采购,资产管理 -
模拟网络架构测试
网络/VPN/标签等规划、双网卡绑定测试、模拟交换机/链路冗余测试、模拟VPN测试、防火墙冗余测试、负载均衡测试、专线网络测试 -
基础设施部署
IDC开通机柜带宽、设备验货、上架基础设施、部署基础设置 -
应用服务部署
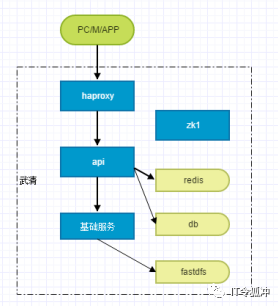
自动装机系统、自动化运维系统、KVM虚拟化、账号管理系统、DNS系统、资产管理、监控系统、nginx、haproxy、keepalived、tomcat、redis、mq、zk、fastdfs、mysql、sqlserver、应用代码
2、切换数据中心方案设计
-
数据中心测试方案设计
-
数据中心切换方案设计
-
部署架构
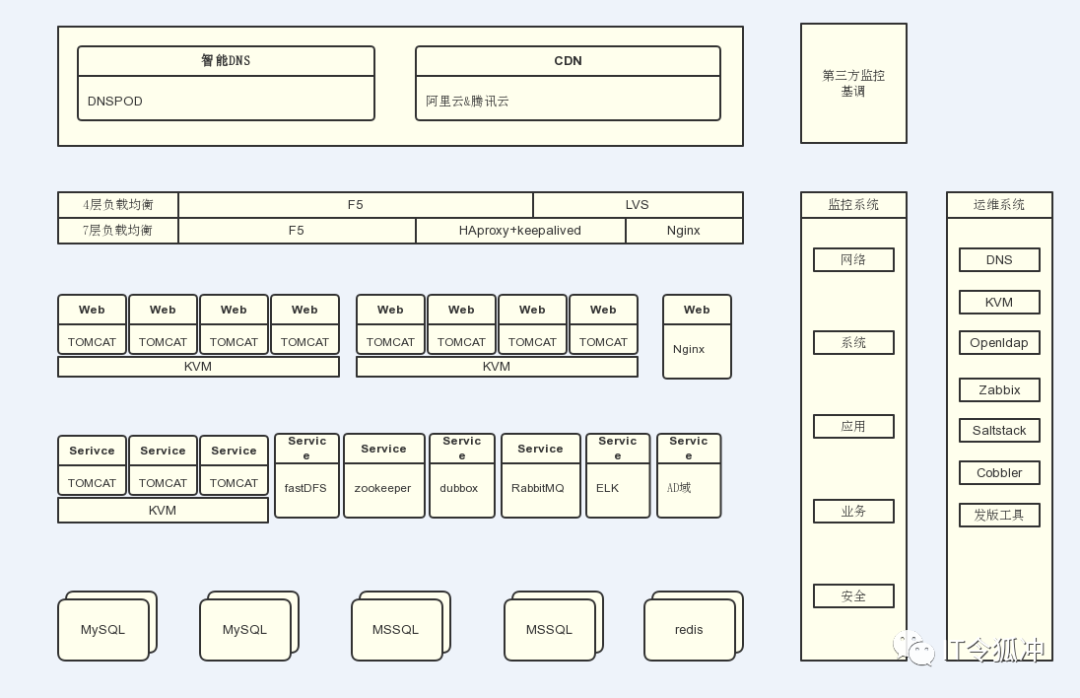
- 整体的切换原则是平滑迁移,不停服务。
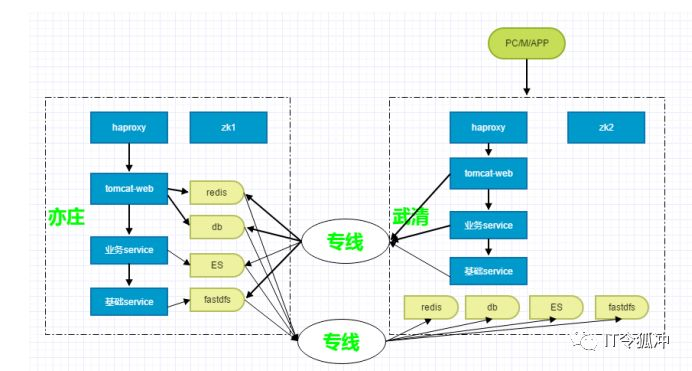
3、数据中心切换过程
迁移之前,确保新机房代码是最新的,测试人员进行回归测试,DBA部署亦庄到武清的数据库(sqlserver、mysql)、redis同步关系,文件系统,mq等都类似。
第一天凌晨进行第一波流量切换,切山东节点到武清机房,大约5%左右的流量,观察服务状况,没有异常情况,用户可正常下单。
第二天凌晨进行第二波流量切换, 上海、江苏、浙江、四川、河南、河北、福建大约50%左右的流量,继续观察服务状况,没有异常情况,用户可正常下单。
第三天凌晨进行全部切换,包括数据库等,切到武清做主,数据直接写武清的库。运维在DNSPOD上进行,把其他剩余流量切换到武清,切换后,网络工程师观察亦庄是否还有流量进入,因为DNS有缓存,所以需要观察一段时间,待到没有流量进入,开始进行存储层切换:
1、sqlserver,DBA利用手动故障转移,将vip从亦庄机房切换搭武清机房,停掉亦庄的sqlserver,sqlserver切换结束。
2、redis,DBA利用批处理脚本关掉亦庄所有redis主库实例,完成后,主库自动切换到武清,亦庄所有redis实例不提供任何服务, 不会有任何脏数据产生,运维切换DNS,DNS生效后,redis切换结束。
3、mysql,和redis切换方式类似,DBA利用批处理脚本杀掉主库,保证没有脏数据进来,运维切换DNS,生效后,mysql切换结束。
以上全部迁移OK后,所有流量、数据、存储都在新机房了,亦庄机房用于灾备。
四. 经验总结
系统比较多,大大小小的100多个系统,梳理过程中不够谨慎 ,遗漏了一些问题, 操作过程中,亦庄到武清做了很多调整,没有做好调研,整理了很多文档,做了很多工作,有不细致的地方,有些工作需要确认,没有落实到书面上,测试过程中有些不清楚的地方,欠缺沟通,信息不同步,准备工作没有准备好,还有历史遗漏原因。
迁移的过程中,有盲点,有测试不到的地方, 支付, 物流,小服务,全量push无法测试, 迁移后pay不可用, push不可用, dns解析问题导致部分缓存流量还在亦庄, 预案做的不充分,虽然有些问题,不过整体上来说,这次数据中心切换还算比较成功。
作者:白连东,北广视彩CTO,IT东方会联系会长,中商联产业互联发展处智库顾问,『IT令狐冲』公众号作者。

