
1 动态数据源的必要性
我们知道,物理服务机的CPU、内存、存储空间、连接数等资源都是有限的,某个时段大量连接同时执行操作,会导致数据库在处理上遇到性能瓶颈。而在复杂的互联网业务场景下,系统流量日益膨胀。为了解决这个问题,行业先驱门充分发扬了分而治之的思想,对大库表进行分割,然后实施更好的控制和管理,同时使用多台机器的CPU、内存、存储,提供更好的性能。参考我这篇《分库分表》。
数据库有水平拆分(Scale Out) 和垂直拆分(Scale Up)的区别,但是无论怎么变化,当你对同一业务库进行分库的时候。必然要考虑到,在你的同一个业务服务(Service),会有同时访问多个数据源的情况。如下图
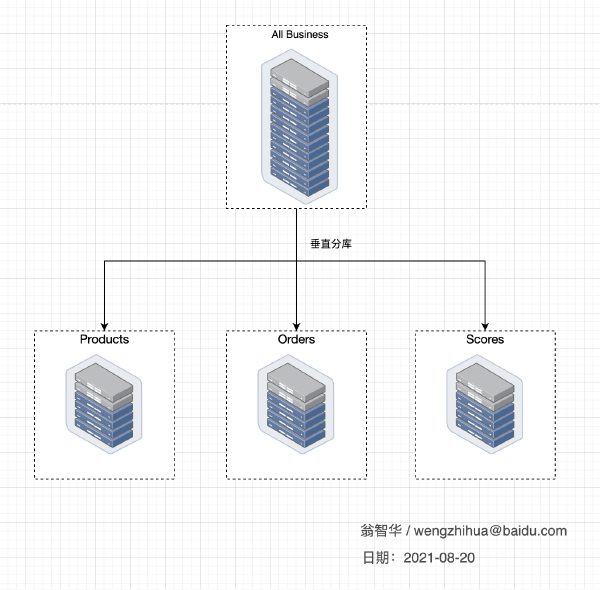
另外一种场景是ABTesting业务场景,可能不同的用户看到的业务数据是不一样的,这就需要根据业务特性动态的获取数据。
按照Spring boot的常规做法,maven添加依赖,在Yaml中配置对应的datasource、jpa等属性即可使用了。但是多数据源的情况下无论是配置 还是数据上下文的切换都变得无比繁琐。如果能使用注解声明的方式,粒度细化到方法级别的,那用起来就简单多了。那我们来写一个这样的实现。
2 实现过程
2.1 Maven依赖
pom文件中增加一些依赖,这边我们以Jpa为案例说明:
<!-- 增加了4.3.8版本jdbc的支持-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>4.3.8.RELEASE</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<!-- Jpa与Hibernate相关:开始-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<exclusions>
<exclusion>
<artifactId>byte-buddy</artifactId>
<groupId>net.bytebuddy</groupId>
</exclusion>
<exclusion>
<artifactId>hibernate-entitymanager</artifactId>
<groupId>org.hibernate</groupId>
</exclusion>
<exclusion>
<artifactId>hibernate-core</artifactId>
<groupId>org.hibernate</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.3.7.Final</version>
</dependency>
<dependency>
<groupId>com.vladmihalcea</groupId>
<artifactId>hibernate-types-52</artifactId>
<version>2.9.7</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- Jpa与Hibernate相关:结束-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
2.2 yaml配置
可以看到我们配置了一个默认的数据源basic,然后再扩展了一个跟basic同级的节点mutil-data-core,包含三个数据源,basic、cloudoffice、attend。
spring:
mutildata:
basic:
driver-class-name: com.mysql.jdbc.Driver
filters: stat
initial-size: 20
logAbandoned: true
maxActive: 300
maxPoolPreparedStatementPerConnectionSize: 20
maxWait: 60000
min-idle: 5
minEvictableIdleTimeMillis: 300000
poolPreparedStatements: true
removeAbandoned: true
removeAbandonedTimeout: 1800
testOnBorrow: false
testOnReturn: false
testWhileIdle: true
timeBetweenEvictionRunsMillis: 60000
validationQuery: SELECT 1
password: 123456
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/basic?autoReconnect=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
username: root
mutil-data-core:
basic:
password: 123456
url: jdbc:mysql://127.0.0.1:3306/basic?autoReconnect=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
username: root
cloud:
password: 123456
url: jdbc:mysql://127.0.0.1:3307/cloudoffice?autoReconnect=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
username: root
attend:
password: 123456
url: jdbc:mysql://127.0.0.1:3308/attend?autoReconnect=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
username: root
2.3 编写配置类Configuration
扫描我们上面的配置,spring.mutildata.basic下面的默认数据源,以及 mutil-data-core下面的多个动态数据源,有多少个扫描多少个出来,并进行组装,放到一个数据源map集合中:dataSourceMap。
@Bean(name = "basicDataSource")
@ConfigurationProperties(prefix = "spring.mutildata.basic") // 这是我们动态数据源的配置位置
public DruidDataSource basicDataSource() {
return new DruidDataSource();
}
@Autowired
private DataSourceCoreConfig dataSourceCoreConfig;
/**
* 动态集成可选的数据库路由,改掉之前硬编码的方式
* @param basicDataSource
* @return
*/
@Bean(name = "routingDataSource")
@Primary
public RoutingDataSource routingDataSource(DruidDataSource basicDataSource) {
RoutingDataSource routingDataSource = new RoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>(16);
HashMap<String, DataSourceCore> mutildatacore = dataSourceCoreConfig.getMutilDataCore();
routingDataSource.setDefaultTargetDataSource(basicDataSource);
try {
Iterator iter = mutildatacore.entrySet().iterator();
while (iter.hasNext()) { // 轮询出所有的动态数据源
Map.Entry entry = (Map.Entry) iter.next();
String key = entry.getKey().toString();
DataSourceCore dsc = (DataSourceCore) entry.getValue();
DruidDataSource ds = (DruidDataSource) basicDataSource.clone();
// 3个核心关键数据源头重新赋值
ds.setUrl(dsc.getUrl());
ds.setUsername(dsc.getUserName());
ds.setPassword(dsc.getPassWord());
dataSourceMap.put(key, ds);
}
}
catch (Exception ex) {
// Todo
}
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
2.4 数据源集合
数据源的管理:包含组织数据源、读值、赋值、清空数据源等。
/**
* @author brand
* @Description: 动态数据源
* @Copyright: Copyright (c) 2021
* @Company: Helenlyn, Inc. All Rights Reserved.
* @date 2021/12/16 10:33 上午
* @Update Time:
* @Updater:
* @Update Comments:
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
/**
* 用来保存数据源与获取数据源
*/
private static final ThreadLocal<String> CONTEXT_HOLDER = new ThreadLocal<String>();
/**
* 构造,包含一个默认数据源,和一个数据源集合
* @param defaultTargetDataSource
* @param targetDataSources
*/
public DynamicDataSource(DataSource defaultTargetDataSource, Map<String, DataSource> targetDataSources) {
super.setDefaultTargetDataSource(defaultTargetDataSource);
super.setTargetDataSources(new HashMap<Object, Object>(targetDataSources));
super.afterPropertiesSet();
}
@Override
protected Object determineCurrentLookupKey() {
return getDataSource();
}
public static void setDataSource(String dataSource) {
CONTEXT_HOLDER.set(dataSource);
}
public static String getDataSource() {
return CONTEXT_HOLDER.get();
}
public static void clearDataSource() {
CONTEXT_HOLDER.remove();
}
}
2.5 按键查找
无注解的情况下,lookupKey是空的,这边直接提供默认数据源。
有注解的时候,按照注解中的信息进行查找。
/**
* 根据 lookupkey 获取到真正的目标数据源
* @return
*/
@Override
protected DataSource determineTargetDataSource() {
Assert.notNull(this.targetDataSources, "DataSource router not initialized");
Object lookupKey = this.determineCurrentLookupKey();
DataSource dataSource = (DataSource) this.targetDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) { // 无注解的情况下,lookupKey是空的,会走到这边,这时候给默认值
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
} else {
return dataSource;
}
}
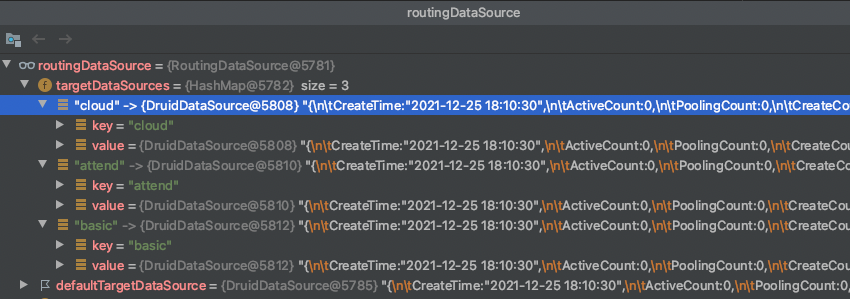
2.6 初始化后的数据源结构
注意它的key,跟我们配置中的一模一样,basic、cloudoffice、attend。这个很重要,注解用这个来匹配。
2.7 编写Annotation
写一个注解,映射的目标范围为 类型和方法。
/**
* @author brand
* @Description: 数据源切换注解
* @Copyright: Copyright (c) 2021
* @Company: Helenlyn, Inc. All Rights Reserved.
* @date 2021/12/15 7:36 下午
*/
@Target({ ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DataSource {
String name() default "";
}
2.8 编写AOP实现
编写切面代码,以实现对注解的PointCut。
/**
* @author brand
* @Description:
* @Copyright: Copyright (c) 2021
* @Company: Helenlyn, Inc. All Rights Reserved.
* @date 2021/12/15 7:49 下午
*/
@Aspect
@Component
public class DataSourceAspect implements Ordered {
/**
* 定义一个切入点,匹配到上面的注解DataSource
*/
@Pointcut("@annotation(com.helenlyn.dataassist.annotation.DataSource)")
public void dataSourcePointCut() {
}
/**
* Around 环绕方式做切面注入
* @param point
* @return
* @throws Throwable
*/
@Around("dataSourcePointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
DataSource ds = method.getAnnotation(DataSource.class);
String routeKey = ds.name(); // 从头部中取出注解的name(basic 或 cloudoffice 或 attend),用这个name进行数据源查找。
String dataSourceRouteKey = DynamicDataSourceRouteHolder.getDataSourceRouteKey();
if (StringUtils.isNotEmpty(dataSourceRouteKey)) {
// StringBuilder currentRouteKey = new StringBuilder(dataSourceRouteKey);
routeKey = ds.name();
}
DynamicDataSourceRouteHolder.setDataSourceRouteKey(routeKey);
try {
return point.proceed();
} finally { // 最后做清理,这个步骤很重要,因为我们的配置中有一个默认的数据源,执行完要回到默认的数据源。
DynamicDataSource.clearDataSource();
DynamicDataSourceRouteHolder.clearDataSourceRouteKey();
}
}
@Override
public int getOrder() {
return 1;
}
}
2.9 测试与效果
2.9.1 数据源key信息
数据源key 信息,有多少个数据源,这边就配置多少个,注意值须与yaml配置中的值保持一致。
/**
* 数据源key 信息,有多少个数据源,这边就配置多少个,
* 值须与yaml配置中的保持一致
*/
public static final String DATA_SOURCE_BASIC_NAME = "basic";
public static final String DATA_SOURCE_ATTEND_NAME = "attend";
public static final String DATA_SOURCE_CLOUD_NAME = "cloud";
2.9.2 测试方法
在Control中写三个测试方法
/**
* 无注解默认情况:数据源指向basic
* @return
*/
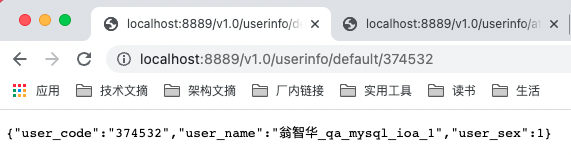
@RequestMapping(value = "/default/{user_code}", method = RequestMethod.GET)
public UserInfoDto getUserInfo(@PathVariable("user_code") String userCode) {
return userInfoService.getUserInfo(userCode);
}
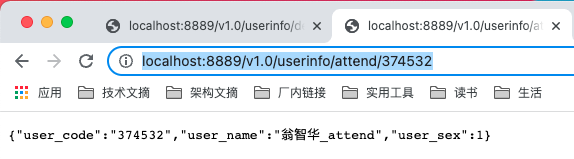
/**
* 数据源指向attend
* @return
*/
@DataSource(name= Constant.DATA_SOURCE_ATTEND_NAME)
@RequestMapping(value = "/attend/{user_code}", method = RequestMethod.GET)
public UserInfoDto getUserInfoAttend(@PathVariable("user_code") String userCode) {
return userInfoService.getUserInfo(userCode);
}
/**
* 数据源指向cloud
* @return
*/
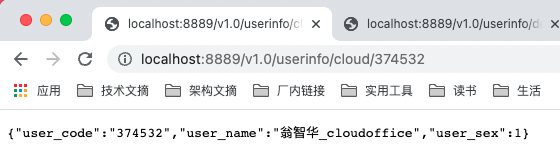
@DataSource(name= Constant.DATA_SOURCE_CLOUD_NAME)
@RequestMapping(value = "/cloud/{user_code}", method = RequestMethod.GET)
public UserInfoDto getUserInfoCloud(@PathVariable("user_code") String userCode) {
return userInfoService.getUserInfo(userCode);
}
2.9.3 效果
3 总结和代码参考
如果需要扩展数据源,在yaml的节点mutil-data-core下加配置数据就行了,简单方便。后面再写个MySQL的实现方式。
github代码:https://github.com/WengZhiHua/Helenlyn.Grocery/tree/master/parent/DynamicDataSource


