JVM菜鸟进阶高手之路五之eden survivor分配问题原创
问题
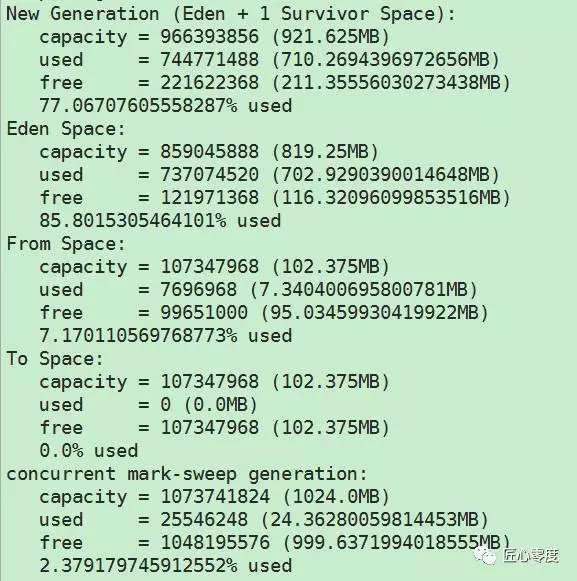
这个Xmn设置为1G,,我用jmap -heap 看,这个Eden From To怎么不是一个整8:1:1的关系呢?
我看内存分配还是没变,我Xmn1g,感觉From、To应该都是102.4M才对,现在是102.375M。
执行命令
jstat -gc pid 1s 1
结果:

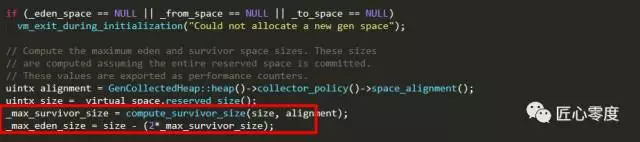
发现很奇怪,的确和我们相信的不一样,我觉得只有源码可以告诉我们他做了啥。查看源码:



执行上面的例子代码
public static void main(String[] args) {
System.out.println(107374183&~((1<<16)-1));
}
输出结果为:107347968

104832K * 1024刚刚好等于107347968B
R大以前的回复:
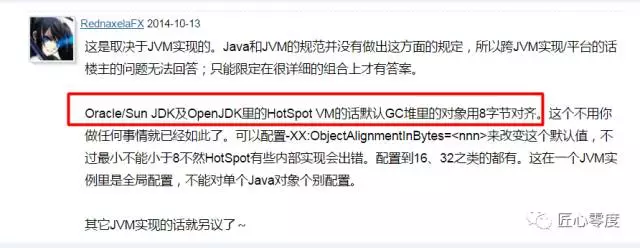
从该信息中可以得到:Oracle/Sun JDK及OpenJDK里的HotSpot VM的话默认GC堆里的对象用8字节对齐。
java内存参数对齐问题
上面问题其实就是java内存参数对齐问题。那么为什么需要java内存参数对齐问题?
内存对齐(Data Structure Alignment)是什么?
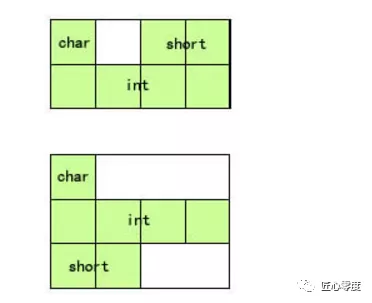
内存对齐,或者说字节对齐,是一个数据类型所能存放的内存地址的属性(Alignment is a property of a memory address)。这个属性是一个无符号整数,并且这个整数必须是2的N次方(1、2、4、8、……、1024、……)。当我们说,一个数据类型的内存对齐为8时,意思就是指这个数据类型所定义出来的所有变量,其内存地址都是8的倍数。当一个基本数据类型(fundamental types)的对齐属性,和这个数据类型的大小相等时,这种对齐方式称作自然对齐(naturally aligned)。比如,一个4字节大小的int型数据,默认情况下它的字节对齐也是4。
为什么我们需要内存对齐?
这是因为,并不是每一个硬件平台都能够随便访问任意位置的内存的。
微软的MSDN里有这样一段话:
Many CPUs, such as those based on Alpha, IA-64, MIPS, and SuperH architectures, refuse to read misaligned data. When a program requests that one of these CPUs access data that is not aligned, the CPU enters an exception state and notifies the software that it cannot continue. On ARM, MIPS, and SH device platforms, for example, the operating system default is to give the application an exception notification when a misaligned access is requested.
大意是说,有不少平台的CPU,比如Alpha、IA-64、MIPS还有SuperH架构,若读取的数据是未对齐的(比如一个4字节的int在一个奇数内存地址上),将拒绝访问,或抛出硬件异常。
另外,在维基百科里也记载着如下内容:
Data alignment means putting the data at a memory offset equal to some multiple of the word size, which increases the system's performance due to the way the CPU handles memory.
意思是,考虑到CPU处理内存的方式(32位的x86 CPU,一个时钟周期可以读取4个连续的内存单元,即4字节),使用字节对齐将会提高系统的性能(也就是CPU读取内存数据的效率。比如你一个int放在奇数内存位置上,想把这4个字节读出来,32位CPU就需要两次。但对齐之后一次就可以了)。
-
需要字节对齐的根本原因在于CPU访问数据的效率问题。假设上面整型变量的地址不是自然对齐,比如为0x00000002,则CPU如果取它的值的话需要访问两次内存,第一次取从0x00000002-0x00000003的一个short,第二次取从0x00000004-0x00000005的一个short然后组合得到所要的数据,如果变量在0x00000003地址上的话则要访问三次内存,第一次为char,第二次为short,第三次为char,然后组合得到整型数据。
-
而如果变量在自然对齐位置上,则只要一次就可以取出数据。一些系统对对齐要求非常严格,比如sparc系统,如果取未对齐的数据会发生错误,而在x86上就不会出现错误,只是效率下降。
-
各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。
-
比如有些架构的CPU在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐,但其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。
-
比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。显然在读取效率上下降很多。
-
另外字节对齐的作用不仅是==便于cpu快速访问==,同时合理的利用字节对齐可以==有效地节省存储空间==。
-
也即CPU一次访问时,要么读0x01~0x04,要么读0x05~0x08…硬件不支持一次访问就读到0x02~0x05
-
例:如果0x02~0x05存了一个int,读取这个int就需要先读0x01~0x04,留下0x02~0x04的内容,再读0x05~0x08,留下0x05的内容,两部分拼接起来才能得到那个int的值,这样读一个int就要两次内存访问,效率就低了。