暴力破解美团最新JVM面试题:无限执行原创
哈喽,我是子牙。十余年技术生涯,一路披荆斩棘从技术小白到技术总监到JVM专家到创业。技术栈如汇编、C语言、C++、Windows内核、Linux内核。特别喜欢研究虚拟机底层实现,对JVM有深入研究。分享的文章偏硬核,很硬的那种。
手撸过JVM、内存池、垃圾回收算法、synchronized、线程池、NIO、三色标记算法…
昨天Java圈,美团曝出了一道**级面试题:为什么栈溢出后线程没有崩溃?为什么这段代码会永远执行下去?

我的几个交流群、VIP群,争论不休,看大家都是在Java层找答案。很明显,这个问题的答案不在Java层,接下来咱们分析下这个问题,然后一起去找答案,争取下次被问到,一举击溃面试官的心理防线:偶滴乖乖,是这道题难度太小还是我太菜?
我会按照看到这个问题我是如何分析如何做实验如何得出结论,层层递进展开,你读起来应该会越来越嗨皮!瓦特?你没嗨皮?你是不是没看懂哦?
01
我的第一反应
我的第一反应是catch Error会永远执行,那catch Exception呢?接下来上代码

看运行结果

会报栈OOM
我脑海中马上想到两个问题:
1、这个栈深度是多少时抛出的?
2、为什么catch Exception会抛出?
怎么查看栈深度呢?JVM提供了相关方法吗?木有!我们通过Linux命令来统计

报栈OOM时,栈的深度是1024,这个数字大家记一下,后面还会讲到,很关键!
接下来第二个问题,为什么catch Exception会抛出OOM?其实对于这段代码,这个问题就是坑,因为栈溢出抛出的是StackOverflowError,你catch Exception是无效的,等同于

什么?你不信?你把代码改成这样,看看catch代码块会不会执行

02
第二段探索
研究完了我的第一反应并得到答案以后,我就开始了我的第二段探索:这个Java程序能够无限执行,这个能力是操作系统自带的还是JVM自己开发出来的?
我们来看看操作系统是否具备让程序永远运行的能力。怎么测试呢?需要你懂一点Linux多线程相关的东西。不懂也没关系,看我演示的现象及结论即可。底层内功重不重要,从这里可见一斑。
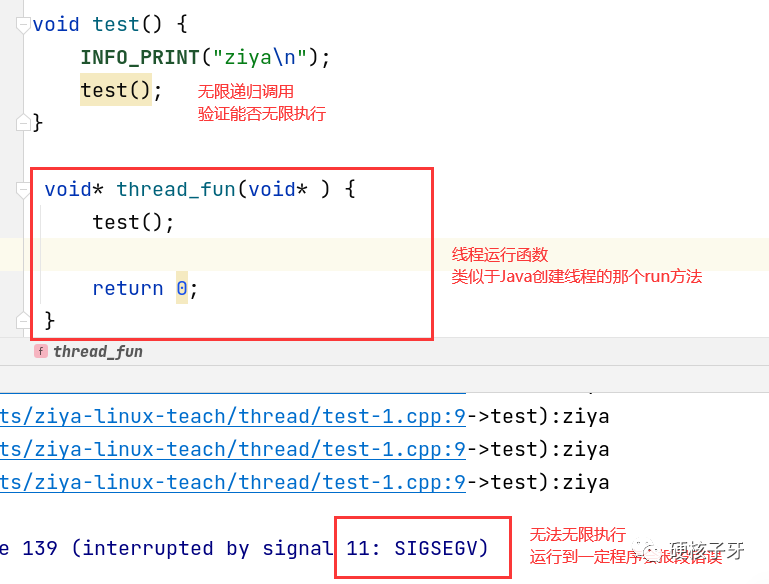
可以看到,Linux系统默认是不支持程序无限执行的
为什么最后会报段错误呢?因为Linux系统创建线程,默认的栈大小是8M,程序无限递归把8M用光了,但是程序还不会终止,不自觉会用到8M之外的内存
这里面还有个隐含知识点,栈图,没有这个基础你可能很难理解上面讲的,放个图帮助你理解

03
第三段探索
既然Linux系统没有提供这样的能力,然JVM能如此,大胆猜想可能的原因:
1、JVM改变了系统默认栈大小8M,可能改成了很大很大。如果是这样,那我们看这段程序的无限执行其实是假象,如果让它一直跑,跑很久很久,可能它就over了。
2、JVM内部做了优化,比如栈帧回溯、递归内联、尾递归优化。验证这个的时候还得考虑方法执行的两个阶段:解释执行,执行JIT及时编译后的代码。是真滴复杂!
我们开始看下JVM的主线程有没有改线程栈的默认大小,改成了多少。这个要怎么看?单步调试openjdk
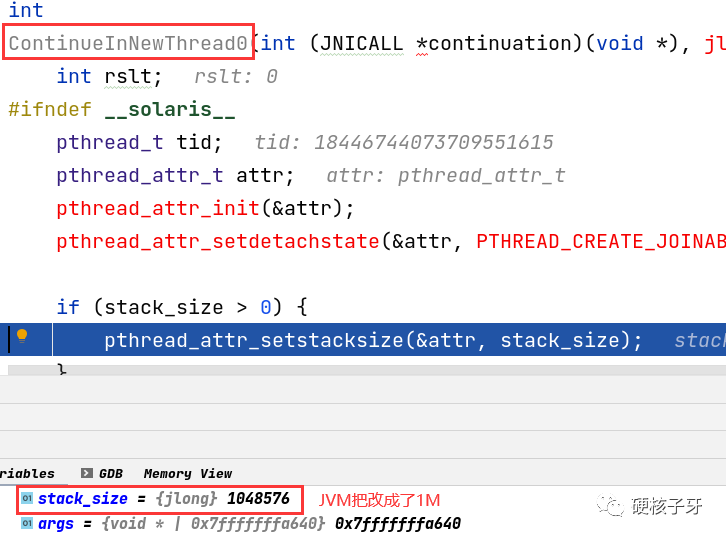
JVM把改成了1M。
JVM的虚拟机栈是在操作系统的线程栈上进行拓展的,Linux系统的默认线程栈是8M,如果是递归调用,一下就跑完了。但是美团的这段程序,很明显跑了很久都没结束,所以这种情况pass,只剩最后一种情况。
04
第四段探索
前面提到了两个关键的东西:栈深度1024,如果程序递归调用把线程栈用光了会报段错误。这两个玩意这里都要用上。开始探索
咱们先就之前的三段探索得出的经验进行头脑风暴一下:程序无限执行的能力,Linux没有提供,但是这段Java程序能够无限执行,说明这个能力是JVM赋予的。
那JVM如何做到的呢?首先,栈的内存大小决定了,一个程序的调用深度是有限的,超过了栈内存大小,Linux会触发段错误信号:SIGSEGV。JVM应该是捕获了这个信号,并进行了处理。那什么样的处理能支持程序一直运行下去呢?如果你理解了刚刚那个栈图你就清晰了,一定是做了栈帧回溯。
最终结论是:JVM捕获了段错误信号并做了处理,处理方式是栈帧回溯。接下来我只贴核心代码,有能力研究Hotspot源码的可以去自行研究。当然,我的结论不一定就是百分百正确的,如果你有不一样的结论并完成了论证,欢迎找我交流。
这里面还有个知识点我跳过了,我提一下,感兴趣的自己去研究:yellow zone、red zone、glibc guard
JVM捕获了异常,并为此创建了执行流

研究这个执行流一直往后面追,最终会追到这里

之前说的1024是怎么来的,就是MaxJavaStackTraceDepth的值。JVM默认支持的栈最大深度就是1024。为什么是1024,因为触发异常的时候需要遍历栈,导出栈信息,如果栈的深度很深,很费时间费性能,就取了一个有象征意义的值。
1024也是一个临界点,当栈深度达到1024,栈帧开始回溯。你可以理解成程序跑起来把栈深度冲到1024,开始回溯,回溯到初始调用时的栈,然后栈深度又开始冲1024,循环往复
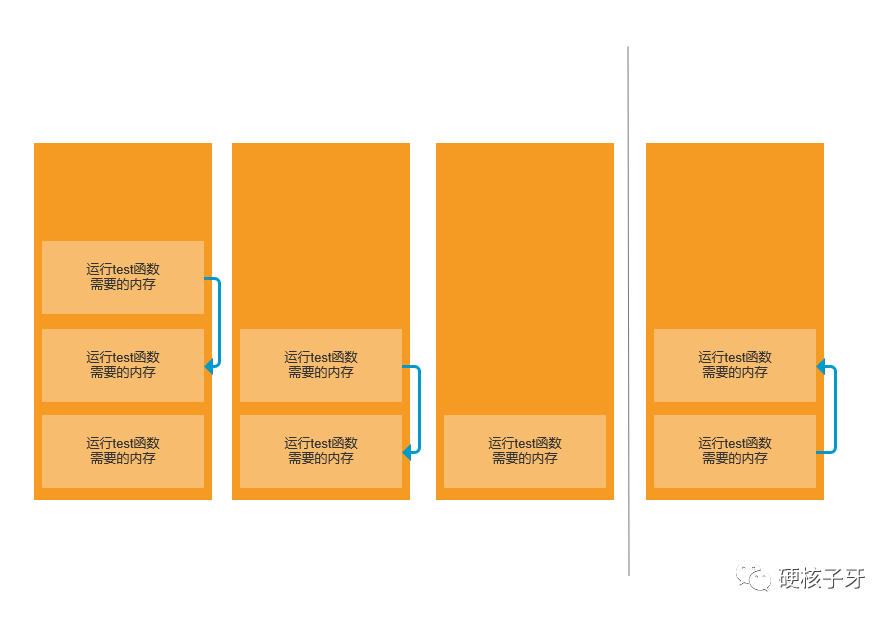
解释执行时是这样干的,那JIT编译又做了哪些优化呢?
05
最终探索
针对回调做优化,目前主流的优化方式有:尾递归优化、内联优化。JVM没有用尾递归优化,而是用的内联优化,专业名词叫递归内联。
此结论来自之前看的R大的某篇文章。本来想找到贴出来的,没找着。有贴心的小伙伴找着了可以发给我,我贴出来。
到这里,这个问题就探索得无比清晰了。撒花~

题外话

你好,我是子牙。十余年技术生涯,一路披荆斩棘从小白到技术总监到大厂中间件到创业。技术栈如汇编、C语言、C++、Windows内核、Linux内核及特别喜欢研究虚拟机底层实现,对JVM有深入研究。分享的文章偏硬核,很硬的那种。不考虑交个朋友吗?关注硬核子牙: