
OpenJDK16 ZGC 详细源码分析原创
概览
ZGC 在 JDK11 中作为实验性功能引入后,已经经过了 5 个版本的演进,目前较之前版本有了较大的变化。本文将分析 ZGC 的设计思想和原理。
ZGC 主要设计理念如下:
-
ZGC 为了支持 TB 级内存,采用了基于 Page 的分页管理(类似于 G1 的 Region)。
-
同时,为了加快内存访问速度,快速的进行并发标记和 relocate,ZGC 新引入了 Color Pointers;Color Pointers 与 Shenandoah GC 使用的 Brooks Pointers 机制不同,依赖内核提供的多视图映射,因此仅能支持部分操作系统的 64 位版本,适用性不如 Shenandoah GC,同时也无法支持指针压缩 CompressedOops。
-
另外,为了高效内存管理,设计了两级内存管理系统。
内存管理
指针结构
zGlobals_x86.cpp
// Address Space & Pointer Layout 3
// --------------------------------
//
// +--------------------------------+ 0x00007FFFFFFFFFFF (127TB)
// . .
// . .
// . .
// +--------------------------------+ 0x0000500000000000 (80TB)
// | Remapped View |
// +--------------------------------+ 0x0000400000000000 (64TB)
// . .
// +--------------------------------+ 0x0000300000000000 (48TB)
// | Marked1 View |
// +--------------------------------+ 0x0000200000000000 (32TB)
// | Marked0 View |
// +--------------------------------+ 0x0000100000000000 (16TB)
// . .
// +--------------------------------+ 0x0000000000000000
//
// 6 4 4 4 4
// 3 8 7 4 3 0
// +------------------+----+-------------------------------------------------+
// |00000000 00000000 |1111|1111 11111111 11111111 11111111 11111111 11111111|
// +------------------+----+-------------------------------------------------+
// | | |
// | | * 43-0 Object Offset (44-bits, 16TB address space)
// | |
// | * 47-44 Metadata Bits (4-bits) 0001 = Marked0 (Address view 16-32TB)
// | 0010 = Marked1 (Address view 32-48TB)
// | 0100 = Remapped (Address view 64-80TB)
// | 1000 = Finalizable (Address view N/A)
// |
// * 63-48 Fixed (16-bits, always zero)
//
-
ZGC 指针布局有三种方式,分别用于支持 4TB、8TB、16TB 的堆空间,以上代码用于为 layout 3 支持 16TB 的布局;
-
43-0 bit 对象地址;
-
47-44 对象视图,分为三种对象视图:
-
Marked0、Marked1
-
Remapped
-
-
x86 和 aarch64 架构下最多仅支持 48 位指针,主要是因为硬件限制。通常为了节约成本,64 位处理器地址线一般仅 40-50 条,因此寻址范围远不及 64 位的理论值。
多视图
ZGC 将同一段物理内存映射到 3 个不同的虚拟内存视图,分别为 Marked0、Marked1、Remapped,这即是 ZGC 中的 Color Pointers,通过 Color Pointers 区分不同的 GC 阶段。
映射
ZGC 的多视图映射依赖于内核提供的 mmap 方法,具体代码如下
zPhysicalMemory.hpp, zPhysicalMemory.cpp, zPhysicalMemoryBacking_linux.cpp
// 物理内存管理类
class ZPhysicalMemory {
private:
ZArray<ZPhysicalMemorySegment> _segments;
void insert_segment(int index, uintptr_t start, size_t size, bool committed);
void replace_segment(int index, uintptr_t start, size_t size, bool committed);
void remove_segment(int index);
public:
ZPhysicalMemory();
ZPhysicalMemory(const ZPhysicalMemorySegment& segment);
ZPhysicalMemory(const ZPhysicalMemory& pmem);
const ZPhysicalMemory& operator=(const ZPhysicalMemory& pmem);
bool is_null() const;
size_t size() const;
int nsegments() const;
const ZPhysicalMemorySegment& segment(int index) const;
void add_segments(const ZPhysicalMemory& pmem);
void remove_segments();
void add_segment(const ZPhysicalMemorySegment& segment);
bool commit_segment(int index, size_t size);
bool uncommit_segment(int index, size_t size);
ZPhysicalMemory split(size_t size);
ZPhysicalMemory split_committed();
};
// 将三个虚拟内存视图映射到同一物理内存
// 在JDK14中增加了对于ZVerifyViews JVM参数的支持(https://bugs.openjdk.java.net/browse/JDK-8232604)
void ZPhysicalMemoryManager::map(uintptr_t offset, const ZPhysicalMemory& pmem) const {
const size_t size = pmem.size();
if (ZVerifyViews) {
// Map good view
map_view(ZAddress::good(offset), pmem);
} else {
// Map all views
map_view(ZAddress::marked0(offset), pmem);
map_view(ZAddress::marked1(offset), pmem);
map_view(ZAddress::remapped(offset), pmem);
}
nmt_commit(offset, size);
}
void ZPhysicalMemoryManager::map_view(uintptr_t addr, const ZPhysicalMemory& pmem) const {
size_t size = 0;
// 逐个映射物理内存
// ZGC中使用segment管理物理内存,后续文章将详细介绍
for (int i = 0; i < pmem.nsegments(); i++) {
const ZPhysicalMemorySegment& segment = pmem.segment(i);
_backing.map(addr + size, segment.size(), segment.start());
size += segment.size();
}
// Setup NUMA interleaving for large pages
if (ZNUMA::is_enabled() && ZLargePages::is_explicit()) {
// To get granule-level NUMA interleaving when using large pages,
// we simply let the kernel interleave the memory for us at page
// fault time.
os::numa_make_global((char*)addr, size);
}
}
// 最终对于map的调用
// 对于linux系统,调用mmap进行映射
void ZPhysicalMemoryBacking::map(uintptr_t addr, size_t size, uintptr_t offset) const {
// 可读、可写、修改共享
// 如果参数start所指的地址无法成功建立映射时,则放弃映射,不对地址做修正。
const void* const res = mmap((void*)addr, size, PROT_READ|PROT_WRITE, MAP_FIXED|MAP_SHARED, _fd, offset);
if (res == MAP_FAILED) {
ZErrno err;
fatal("Failed to map memory (%s)", err.to_string());
}
}
-
ZPhysicalMemory 是 ZGC 对于物理内存管理的抽象,收敛 ZGC 对于物理内存的访问。
-
ZPhysicalMemory 底层根据宿主操作系统调用不同的 ZPhysicalMemoryBacking 实现,进行多视图映射。
物理内存管理
ZGC 对于物理内存的管理主要在 ZPhysicalMemory 类中,此处需要注意,ZGC 上下文中的物理内存,不是真正的物理内存,而是操作系统虚拟内存。
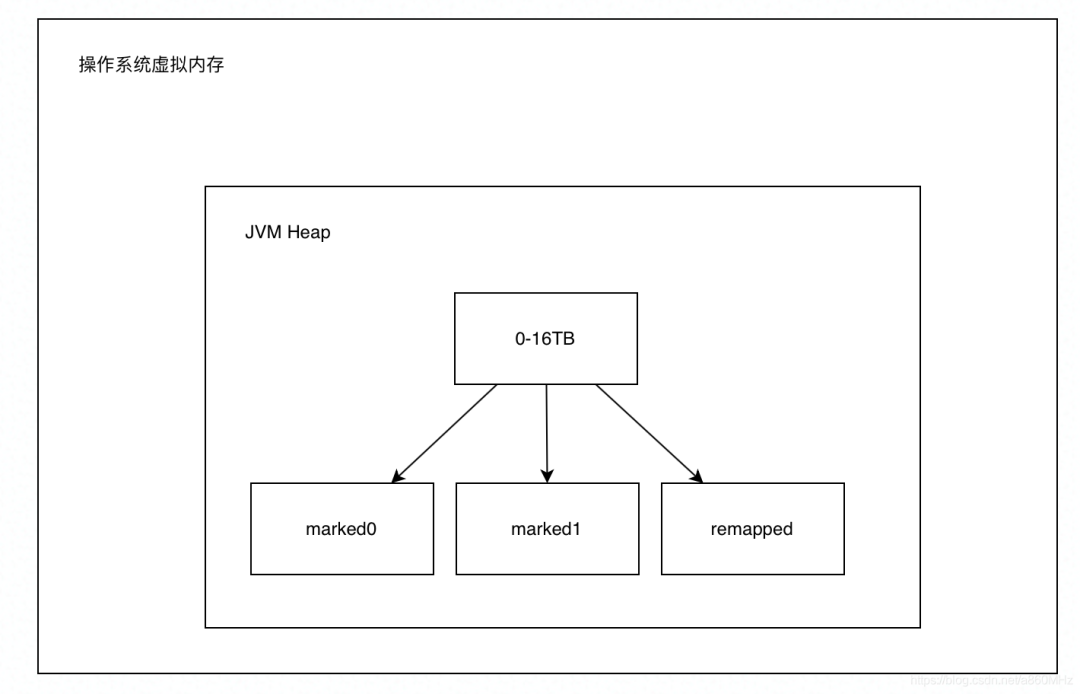
ZGC 中管理物理内存的基本单位是 segment。segment 默认与 small page size 一样,都是 2MB。引入 segment 是为了避免频繁的申请和释放内存的系统调用,一次申请 2MB,当 segment 空闲时,将加入空闲列表,等待之后重复使用。
zGlobals_x86.hpp
// 默认page size偏移量
const size_t ZPlatformGranuleSizeShift = 21; // 2MB
ZPhysicalMemorySegment 是 ZGC 对于物理内存 segment 的抽象,定义如下:
zPhysicalMemory.cpp
private:
// 开始偏移量
uintptr_t _start;
// 开始偏移量+size
uintptr_t _end;
bool _committed;
public:
ZPhysicalMemorySegment();
ZPhysicalMemorySegment(uintptr_t start, size_t size, bool committed);
uintptr_t start() const;
uintptr_t end() const;
size_t size() const;
bool is_committed() const;
void set_committed(bool committed);
};
页面管理
Page 介绍
ZGC 中内存管理的基本单元是 Page(类似于 G1 中的 region),ZGC 有 3 种不同的页面类型:小型(2MB),中型(32MB)和大型(2MB 的倍数)。
zGlobals_x86.hpp
const size_t ZPlatformGranuleSizeShift = 21; // 2MBzGlobals.hpp
// Page types
const uint8_t ZPageTypeSmall = 0;
const uint8_t ZPageTypeMedium = 1;
const uint8_t ZPageTypeLarge = 2;
// Page size shifts
const size_t ZPageSizeSmallShift = ZGranuleSizeShift;
extern size_t ZPageSizeMediumShift;
// Page sizes
// small page 2MB
const size_t ZPageSizeSmall = (size_t)1 << ZPageSizeSmallShift;
extern size_t ZPageSizeMedium;
// 对象size限制,small page不超过2MB/8, 256KB
const size_t ZObjectSizeLimitSmall = ZPageSizeSmall / 8; // 12.5% max waste
extern size_t ZObjectSizeLimitMedium;
medium 页 size 的计算方法如下:
zHeuristics.cpp
void ZHeuristics::set_medium_page_size() {
// Set ZPageSizeMedium so that a medium page occupies at most 3.125% of the
// max heap size. ZPageSizeMedium is initially set to 0, which means medium
// pages are effectively disabled. It is adjusted only if ZPageSizeMedium
// becomes larger than ZPageSizeSmall.
const size_t min = ZGranuleSize;
const size_t max = ZGranuleSize * 16;
const size_t unclamped = MaxHeapSize * 0.03125;
const size_t clamped = clamp(unclamped, min, max);
const size_t size = round_down_power_of_2(clamped);
if (size > ZPageSizeSmall) {
// Enable medium pages
ZPageSizeMedium = size;
ZPageSizeMediumShift = log2_intptr(ZPageSizeMedium);
ZObjectSizeLimitMedium = ZPageSizeMedium / 8;
ZObjectAlignmentMediumShift = (int)ZPageSizeMediumShift - 13;
ZObjectAlignmentMedium = 1 << ZObjectAlignmentMediumShift;
}
}
-
取堆最大容量(Xmx)的 0.03125 unclamped;
-
如果 unclamped 在 2MB 到 32MB 之间,clamped 赋值 unclamped;如果 unclamped 小于 2MB,则 clamped 赋值 2MB;如果 unclamped 大于 32MB,则 clamped 赋值 32MB;
-
向下取 clamped 最接近的 2 的幂数,即为 medium 页 size;
-
考虑到目前的硬件环境,通常的 medium 页 size 为 32MB;
-
ZObjectSizeLimitMedium 为 ZPageSizeMedium / 8,则通常情况下,medium 页的对象 size 限制为 4MB。超过 4MB 的对象需要放入 large 页。
对于 large page 的处理如下:
zObjectAllocator.cpp
uintptr_t ZObjectAllocator::alloc_large_object(size_t size, ZAllocationFlags flags) {
uintptr_t addr = 0;
// Allocate new large page
const size_t page_size = align_up(size, ZGranuleSize);
ZPage* const page = alloc_page(ZPageTypeLarge, page_size, flags);
if (page != NULL) {
// Allocate the object
addr = page->alloc_object(size);
}
return addr;
}
-
分配大对象时,触发分配 large page;
-
对齐大对象 size 到 2MB 的倍数后分配 large page。
zObjectAllocator.cpp
uintptr_t ZObjectAllocator::alloc_large_object(size_t size, ZAllocationFlags flags) {
uintptr_t addr = 0;
// Allocate new large page
const size_t page_size = align_up(size, ZGranuleSize);
ZPage* const page = alloc_page(ZPageTypeLarge, page_size, flags);
if (page != NULL) {
// Allocate the object
addr = page->alloc_object(size);
}
return addr;
}
-
当对象 size 大于 medium 页对象 size 限制时,触发大对象分配;
-
因此,large 页的实际 size 很可能小于 medium 页 size。
Page 的分配
Page 分配的入口在 ZHeap 的 alloc_page 方法:
zHeap.cpp
ZPage* ZObjectAllocator::alloc_page(uint8_t type, size_t size, ZAllocationFlags flags) {
// 调用了page分配器的alloc_page函数
ZPage* const page = ZHeap::heap()->alloc_page(type, size, flags);
if (page != NULL) {
// 增加使用内存数
Atomic::add(_used.addr(), size);
}
return page;
}
zPageAllocator.cpp
ZPage* ZPageAllocator::alloc_page(uint8_t type, size_t size, ZAllocationFlags flags) {
EventZPageAllocation event;
retry:
ZPageAllocation allocation(type, size, flags);
// 从page cache分配page
// 如果分配成功,调用alloc_page_finalize完成分配
// 分配过程中,如果是阻塞模式,有可能在安全点被阻塞
if (!alloc_page_or_stall(&allocation)) {
// Out of memory
return NULL;
}
// 如果从page cache分配失败,则从物理内存申请页
// 提交page
ZPage* const page = alloc_page_finalize(&allocation);
if (page == NULL) {
// 如果commit或者map失败,则goto到retry,重新分配
alloc_page_failed(&allocation);
goto retry;
}
// ...
// ...
// ...
return page;
}
bool ZPageAllocator::alloc_page_or_stall(ZPageAllocation* allocation) {
{
// 分配page需要上锁,因为只有一个堆
ZLocker<ZLock> locker(&_lock);
// 分配成功,返回true
if (alloc_page_common(allocation)) {
return true;
}
// 如果是非阻塞模式,返回false
if (allocation->flags().non_blocking()) {
return false;
}
// 分配请求入队,等待GC完成
_stalled.insert_last(allocation);
}
return alloc_page_stall(allocation);
}
// 阻塞分配,等待GC
bool ZPageAllocator::alloc_page_stall(ZPageAllocation* allocation) {
ZStatTimer timer(ZCriticalPhaseAllocationStall);
EventZAllocationStall event;
ZPageAllocationStall result;
// 检查虚拟机是否已经完成初始化
check_out_of_memory_during_initialization();
do {
// 启动异步GC
ZCollectedHeap::heap()->collect(GCCause::_z_allocation_stall);
// 挂起,等待GC结果
result = allocation->wait();
} while (result == ZPageAllocationStallStartGC);
// ...
// ...
// ...
return (result == ZPageAllocationStallSuccess);
}
-
阻塞分配与非阻塞分配,由系统参数 ZStallOnOutOfMemory 控制,默认阻塞分配。阻塞分配时,如果分配失败,则触发 GC,等待 GC 结束后再次分配,直到分配成功。
对象分配
自从 JDK10 中的引入了 JEP 304: Garbage Collector Interface 后,OpenJDK 定义了一整套关于 GC 的虚方法,供具体的 GC 算法实现。极大了简化了开发难度和代码的可维护性。
JEP 304 定义了 CollectedHeap 类,每个 GC 都需要实现。CollectedHeap 类负责驱动 HotSpot 的 GC,以及和其他模块的交互。GC 应当实现如下功能:
-
CollectedHeap 的子类;
-
BarrierSet 集合类的实现,提供在运行时各种屏障功能;
-
CollectorPolicy 类的实现;
-
GCInterpreterSupport 的实现,提供 GC 在解释执行时各种屏障功能(使用汇编指令);
-
GCC1Support 的实现,提供 GC 在 C1 编译代码中各种屏障功能;
-
GCC2Support 的实现,提供 GC 在 C2 编译代码中各种屏障功能;
-
最终 GC 指定参数的初始化;
-
一个 MemoryService,提供内存池、内存管理等。
通常地,对象分配的入口在 InstanceKlass::allocate_instance,该方法调用 heap->obj_allocate()进行分配。
instanceOop InstanceKlass::allocate_instance(TRAPS) {
bool has_finalizer_flag = has_finalizer(); // Query before possible GC
int size = size_helper(); // Query before forming handle.
instanceOop i;
i = (instanceOop)Universe::heap()->obj_allocate(this, size, CHECK_NULL);
if (has_finalizer_flag && !RegisterFinalizersAtInit) {
// 对于实现了finalize方法的类的实例的特殊处理
i = register_finalizer(i, CHECK_NULL);
}
return i;
}
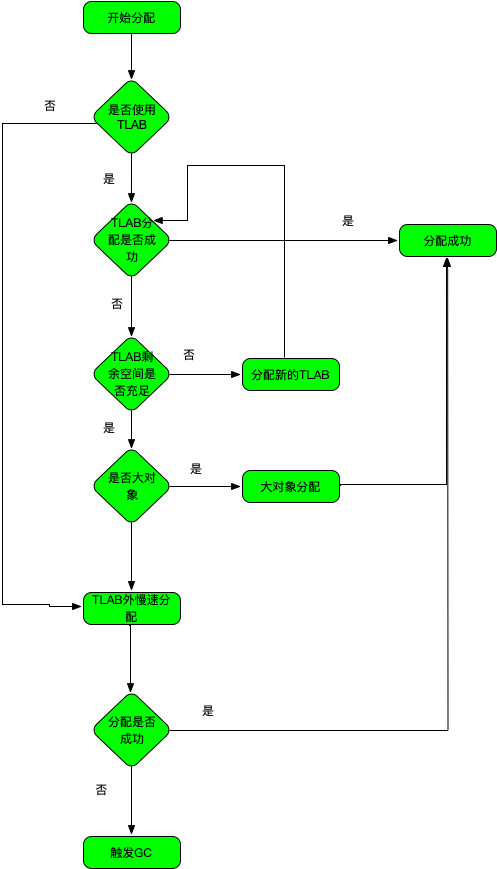
CollectedHeap 对象分配流程图
对象分配一般遵循如下流程:
源码分析
ZCollectedHeap
ZCollectedHeap 重载了 CollectedHeap 的方法,其中包含了对象分配的相关方法。而核心逻辑在放在 ZHeap 中。ZCollectedHeap 中主要的成员方法如下:
class ZCollectedHeap : public CollectedHeap {
friend class VMStructs;
private:
// 软引用清理策略
SoftRefPolicy _soft_ref_policy;
// 内存屏障,解释执行/C1/C2执行时对象访问的屏障
ZBarrierSet _barrier_set;
// 初始化逻辑
ZInitialize _initialize;
// 堆管理的核心逻辑,包括对象分配、转移、标记
ZHeap _heap;
// 垃圾回收线程,触发
ZDirector* _director;
// 垃圾回收线程,执行
ZDriver* _driver;
// 垃圾回收线程,统计
ZStat* _stat;
// 工作线程
ZRuntimeWorkers _runtime_workers;
}
ZHeap
ZHeap 是 ZGC 内存管理的核心类。主要变量如下:
class ZHeap {
friend class VMStructs;
private:
static ZHeap* _heap;
// 工作线程
ZWorkers _workers;
// 对象分配器
ZObjectAllocator _object_allocator;
// 页面分配器
ZPageAllocator _page_allocator;
// 页表
ZPageTable _page_table;
// 转发表,用于对象迁移后的指针映射
ZForwardingTable _forwarding_table;
// 标记管理
ZMark _mark;
// 引用处理器
ZReferenceProcessor _reference_processor;
// 弱引用处理器
ZWeakRootsProcessor _weak_roots_processor;
// 转移管理器,用于对象迁移(类比G1的疏散)
ZRelocate _relocate;
// 转移集合
ZRelocationSet _relocation_set;
// 从元空间卸载类
ZUnload _unload;
ZServiceability _serviceability;
}
对象分配器
对象分配的主要逻辑在 ZObjectAllocator。
对象分配器主要变量
ZObjectAllocator 的主要变量如下:
class ZObjectAllocator {
private:
const bool _use_per_cpu_shared_small_pages;
// 分CPU记录使用内存size
ZPerCPU<size_t> _used;
// 分CPU记录undo内存size
ZPerCPU<size_t> _undone;
// 缓存行对齐的模板类
ZContended<ZPage*> _shared_medium_page;
// 按CPU从缓存分配对象
ZPerCPU<ZPage*> _shared_small_page;
}
分配方法
对象分配的核心方法是 alloc_object
uintptr_t ZObjectAllocator::alloc_object(size_t size, ZAllocationFlags flags) {
if (size <= ZObjectSizeLimitSmall) {
// Small
return alloc_small_object(size, flags);
} else if (size <= ZObjectSizeLimitMedium) {
// Medium
return alloc_medium_object(size, flags);
} else {
// Large
return alloc_large_object(size, flags);
}
}
-
按对象的 size,决定调用 small page 分配、medium page 分配还是 large page 分配。
-
分配入参除了 size 外,还有个 ZAllocationFlags。ZAllocationFlags 是个 8bit 的配置参数。
large page 分配方法如下:
uintptr_t ZObjectAllocator::alloc_large_object(size_t size, ZAllocationFlags flags) {
uintptr_t addr = 0;
// 对齐2MB
const size_t page_size = align_up(size, ZGranuleSize);
// 分配页面
ZPage* const page = alloc_page(ZPageTypeLarge, page_size, flags);
if (page != NULL) {
// 在页面中分配对象
addr = page->alloc_object(size);
}
return addr;
}
-
small page 分配和 medium page 分配都会调用到 alloc_object_in_shared_page 方法;
-
小对象和中对象的分配略有不同,小对象是根据所在 CPU 从共享页面中分配对象。而中对象则是全部线程共享一个 medium page。
// shared_page:页面地址
// page_type:page类型,small还是medium
// page_size: page size
// size: 对象size
// flags: 分配标识
uintptr_t ZObjectAllocator::alloc_object_in_shared_page(ZPage** shared_page,
uint8_t page_type,
size_t page_size,
size_t size,
ZAllocationFlags flags) {
uintptr_t addr = 0;
// 获取一个page
ZPage* page = Atomic::load_acquire(shared_page);
if (page != NULL) {
// 调用page的分配对象方法
addr = page->alloc_object_atomic(size);
}
if (addr == 0) {
// 如果刚才没有获取page成功,则分配一个new page
ZPage* const new_page = alloc_page(page_type, page_size, flags);
if (new_page != NULL) {
// 先分配对象,然后加载page到shared_page缓存
addr = new_page->alloc_object(size);
retry:
// 加载page到shared_page缓存
ZPage* const prev_page = Atomic::cmpxchg(shared_page, page, new_page);
if (prev_page != page) {
if (prev_page == NULL) {
// 如果prev_page已经淘汰,则goto到retry一直重试
page = prev_page;
goto retry;
}
// 其他线程加载了页面,则使用prev_page分配
const uintptr_t prev_addr = prev_page->alloc_object_atomic(size);
if (prev_addr == 0) {
// 如果分配失败,则goto到retry一直重试
page = prev_page;
goto retry;
}
addr = prev_addr;
undo_alloc_page(new_page);
}
}
}
return addr;
}
Page 内的对象分配
page 内的对象分配主要是两个方法 alloc_object_atomic 和 alloc_object,其中 alloc_object 没有锁竞争,主要用于新 page 的第一次对象分配。
先看 alloc_object_atomic
inline uintptr_t ZPage::alloc_object_atomic(size_t size) {
assert(is_allocating(), "Invalid state");
// 对象对齐,默认8字节对齐
const size_t aligned_size = align_up(size, object_alignment());
uintptr_t addr = top();
for (;;) {
const uintptr_t new_top = addr + aligned_size;
if (new_top > end()) {
// page没有申昱空间,则返回0
return 0;
}
// cas操作更新prev_top指针
const uintptr_t prev_top = Atomic::cmpxchg(&_top, addr, new_top);
if (prev_top == addr) {
// 调用ZAddress::good获取colored pointer
return ZAddress::good(addr);
}
// 无限重试
addr = prev_top;
}
}
再看看 alloc_object
inline uintptr_t ZPage::alloc_object(size_t size) {
assert(is_allocating(), "Invalid state");
// 对象空间对齐,默认8字节
const size_t aligned_size = align_up(size, object_alignment());
const uintptr_t addr = top();
const uintptr_t new_top = addr + aligned_size;
if (new_top > end()) {
// 剩余空间不足,返回0
return 0;
}
_top = new_top;
// 调用ZAddress::good获取colored pointer
return ZAddress::good(addr);
}
Colored pointer 的计算
可以看到上述两个方法在分配结束都调用了 ZAddress::good 返回 colored pointer。看看 ZAddress::good 的实现。
inline uintptr_t ZAddress::offset(uintptr_t value) {
return value & ZAddressOffsetMask;
}
inline uintptr_t ZAddress::good(uintptr_t value) {
return offset(value) | ZAddressGoodMask;
}
void ZAddress::set_good_mask(uintptr_t mask) {
ZAddressGoodMask = mask;
ZAddressBadMask = ZAddressGoodMask ^ ZAddressMetadataMask;
ZAddressWeakBadMask = (ZAddressGoodMask | ZAddressMetadataRemapped | ZAddressMetadataFinalizable) ^ ZAddressMetadataMask;
}
-
good 方法其实挺简单,先取 4 位染色值,然后或操作实际地址,获取 colored pointer。
-
colored pointer 将在 load barrier 中使用,后文将详细介绍 load barrier 机制。
读屏障
对于并发 GC 来说,最复杂的事情在于 GC worker 在标记-整理,而 Java 线程(Mutator)同时还在不断的创建新对象、修改字段,不停的更新对象引用关系。因此并发 GC 一般采用两种策略 Incremental Update(增量更新、CMS) 和 SATB(snapshot at beginning、G1) ,两种策略网上介绍文章很多,此处不再赘述。
SATB 重点关注引用关系的删除,可以参考我之前的博客 JVM G1 源码分析(四)- Dirty Card Queue Set(https://blog.csdn.net/a860MHz/article/details/97631300),而 Incremental Update 重点关注引用关系的增加。
而 ZGC 并没有采取类似方式,而是借助读屏障、colored pointer 来实现并发标记-整理。
原理
什么是 Load Barrier
-
一小段在最佳位置由 JIT 注入的代码
-
从堆中加载一个对象引用时
-
-
检查这个引用是否是 bad color
-
如果是,则自愈
-
Load Barrier 的触发
从堆中加载对象引用时触发 load barrier。
// 从堆中加载一个对象引用,需要load barrier
String n = person.name;
// 不需要load barrier,不是从堆中加载
String p = n;
// 不需要load barrier,不是从堆中加载
n.isEmpty();
// 不需要load barrier,不是引用类型
int age = person.age;
当引用类型 n 被赋值修改后,在下一次使用 n 前,会测试 n 的染色指针是否为 good。此时测试为 bad color 可知 n 的引用地址进行过修改,需要自愈。
触发 load barrier 的伪代码如下:
// 从堆中加载一个对象引用,需要load barrier
String n = person.name;
if (n & bad_bit_mask) {
slow_path(register_for(n), address_of)
}
对应的汇编代码:
// String n = person.name;
mov 0x10(%rax), %rbx
// 是否bad color
test %rbx, (0x16)%r15
// 如是,进入slow path
jnz slow_path
源码分析
掩码
zGlobals.hpp
//
// Good/Bad mask states
// --------------------
//
// GoodMask BadMask WeakGoodMask WeakBadMask
// --------------------------------------------------------------
// Marked0 001 110 101 010
// Marked1 010 101 110 001
// Remapped 100 011 100 011
//
// Good/bad masks
extern uintptr_t ZAddressGoodMask;
extern uintptr_t ZAddressBadMask;
extern uintptr_t ZAddressWeakBadMask;
zAddress.inline.hpp
inline bool ZAddress::is_null(uintptr_t value) {
return value == 0;
}
inline bool ZAddress::is_bad(uintptr_t value) {
return value & ZAddressBadMask;
}
inline bool ZAddress::is_good(uintptr_t value) {
return !is_bad(value) && !is_null(value);
}
从以上两段代码可以很清晰看出,colored pointer 的状态是 Good/WeakGood/Bad/WeakBad 由 GoodMask 及 BadMask 来测定。
同时,GoodMask、BadMask 由 GC 所处的阶段决定。
void ZAddress::set_good_mask(uintptr_t mask) {
ZAddressGoodMask = mask;
ZAddressBadMask = ZAddressGoodMask ^ ZAddressMetadataMask;
ZAddressWeakBadMask = (ZAddressGoodMask | ZAddressMetadataRemapped | ZAddressMetadataFinalizable) ^ ZAddressMetadataMask;
}
void ZAddress::initialize() {
ZAddressOffsetBits = ZPlatformAddressOffsetBits();
ZAddressOffsetMask = (((uintptr_t)1 << ZAddressOffsetBits) - 1) << ZAddressOffsetShift;
ZAddressOffsetMax = (uintptr_t)1 << ZAddressOffsetBits;
ZAddressMetadataShift = ZPlatformAddressMetadataShift();
ZAddressMetadataMask = (((uintptr_t)1 << ZAddressMetadataBits) - 1) << ZAddressMetadataShift;
ZAddressMetadataMarked0 = (uintptr_t)1 << (ZAddressMetadataShift + 0);
ZAddressMetadataMarked1 = (uintptr_t)1 << (ZAddressMetadataShift + 1);
ZAddressMetadataRemapped = (uintptr_t)1 << (ZAddressMetadataShift + 2);
ZAddressMetadataFinalizable = (uintptr_t)1 << (ZAddressMetadataShift + 3);
ZAddressMetadataMarked = ZAddressMetadataMarked0;
set_good_mask(ZAddressMetadataRemapped);
}
void ZAddress::flip_to_marked() {
ZAddressMetadataMarked ^= (ZAddressMetadataMarked0 | ZAddressMetadataMarked1);
set_good_mask(ZAddressMetadataMarked);
}
void ZAddress::flip_to_remapped() {
set_good_mask(ZAddressMetadataRemapped);
}
比如,ZGC 初始化后,地址视图为 Remapped,GoodMask 是 100,BadMask 是 011。进入标记阶段后,地址视图切换为 M0,GoodMask 和 BadMask 变更为 001 和 110。
屏障的进入条件
accessDecorators.cpp
// === Access Location ===
// 对堆的访问
const DecoratorSet IN_HEAP = UCONST64(1) << 18;
// 对堆外的访问
const DecoratorSet IN_NATIVE = UCONST64(1) << 19;
const DecoratorSet IN_DECORATOR_MASK = IN_HEAP | IN_NATIVE;
zBarrierSet.cpp
bool ZBarrierSet::barrier_needed(DecoratorSet decorators, BasicType type) {
assert((decorators & AS_RAW) == 0, "Unexpected decorator");
//assert((decorators & ON_UNKNOWN_OOP_REF) == 0, "Unexpected decorator");
// 是否引用类型
if (is_reference_type(type)) {
// 是否从堆中或者堆外加载一个对象引用
assert((decorators & (IN_HEAP | IN_NATIVE)) != 0, "Where is reference?");
// Barrier needed even when IN_NATIVE, to allow concurrent scanning.
return true;
}
// Barrier not needed
return false;
}
屏障
load barrier 的入口代码在 zBarrier.inline.hpp
// 模板函数
template <ZBarrierFastPath fast_path, ZBarrierSlowPath slow_path>
inline oop ZBarrier::barrier(volatile oop* p, oop o) {
const uintptr_t addr = ZOop::to_address(o);
// 如果是good指针,只需做一次类型转换
if (fast_path(addr)) {
return ZOop::from_address(addr);
}
// 否则,进入slow path
const uintptr_t good_addr = slow_path(addr);
// 指针自愈
if (p != NULL) {
self_heal<fast_path>(p, addr, good_addr);
}
// 类型转换
return ZOop::from_address(good_addr);
}
-
barrier 接收两个模板函数指针,根据输入函数的执行结果决定走 fast path 还是 slow path;
-
fast path 仅需一次类型转换;
-
slow path 执行后,还需要进行指针自愈,最后返回前做类型转换。
fast path
fast path 根据执行场景和 colored pointer 不同有不少选择,使用比较多的如下:zBarrier.inline.hpp
// 又调回到ZAddress的inline函数了,都是一堆用colored pointer & 掩码的操作
inline bool ZBarrier::is_good_or_null_fast_path(uintptr_t addr) {
return ZAddress::is_good_or_null(addr);
}
inline bool ZBarrier::is_weak_good_or_null_fast_path(uintptr_t addr) {
return ZAddress::is_weak_good_or_null(addr);
}
inline bool ZBarrier::is_marked_or_null_fast_path(uintptr_t addr) {
return ZAddress::is_marked_or_null(addr);
}
slow path
同样的 slow path 根据场景不同,也有好几个选择,但是使用较多的就是 load_barrier_on_oop_slow_path zBarrier.cpp
uintptr_t ZBarrier::load_barrier_on_oop_slow_path(uintptr_t addr) {
// 迁移还是标记
return relocate_or_mark(addr);
}
// 迁移
uintptr_t ZBarrier::relocate(uintptr_t addr) {
assert(!ZAddress::is_good(addr), "Should not be good");
assert(!ZAddress::is_weak_good(addr), "Should not be weak good");
// 调用heap的relocate_object
return ZHeap::heap()->relocate_object(addr);
}
迁移对象
zHeap.inline.cpp zRelocate.cpp
// 迁移对象
inline uintptr_t ZHeap::relocate_object(uintptr_t addr) {
assert(ZGlobalPhase == ZPhaseRelocate, "Relocate not allowed");
// 从forwarding table拿到地址映射关系
// forwarding table会在后文介绍GC的执行过程时详细介绍。先简单理解成一个旧地址到新地址的映射好了。
ZForwarding* const forwarding = _forwarding_table.get(addr);
if (forwarding == NULL) {
// 不在forwarding table内,那就是个good address
return ZAddress::good(addr);
}
// 迁移对象
return _relocate.relocate_object(forwarding, ZAddress::good(addr));
}
// 实际的迁移方法
uintptr_t ZRelocate::relocate_object(ZForwarding* forwarding, uintptr_t from_addr) const {
ZForwardingCursor cursor;
// 在forwarding table找到新地址
// 如果新地址非0,则表示对象已经疏散到新page了,直接返回新地址
// 如果新地址为0,则先迁移对象
uintptr_t to_addr = forwarding_find(forwarding, from_addr, &cursor);
if (to_addr != 0) {
// Already relocated
return to_addr;
}
// 迁移对象
if (forwarding->retain_page()) {
to_addr = relocate_object_inner(forwarding, from_addr, &cursor);
forwarding->release_page();
if (to_addr != 0) {
// 迁移成功
return to_addr;
}
// 如果迁移失败,等待GC 工作线程完成迁移整个page
forwarding->wait_page_released();
}
return forward_object(forwarding, from_addr);
}
标记
zBarrier.cpp zHeap.inline.cpp
template <bool follow, bool finalizable, bool publish>
uintptr_t ZBarrier::mark(uintptr_t addr) {
uintptr_t good_addr;
if (ZAddress::is_marked(addr)) {
// 如果已经标记过,或 Good掩码
good_addr = ZAddress::good(addr);
} else if (ZAddress::is_remapped(addr)) {
// 如果remapped,表示GC开始前创建的对象,或 Good掩码
// 需要标记
good_addr = ZAddress::good(addr);
} else {
// 需要remap和标记
good_addr = remap(addr);
}
// 标记对象
if (should_mark_through<finalizable>(addr)) {
ZHeap::heap()->mark_object<follow, finalizable, publish>(good_addr);
}
if (finalizable) {
// 如果是可回收对象,则或Finalizable和Good掩码
return ZAddress::finalizable_good(good_addr);
}
return good_addr;
}
// 调用ZHeap的remap对象
uintptr_t ZBarrier::remap(uintptr_t addr) {
assert(!ZAddress::is_good(addr), "Should not be good");
assert(!ZAddress::is_weak_good(addr), "Should not be weak good");
return ZHeap::heap()->remap_object(addr);
}
// remap对象
inline uintptr_t ZHeap::remap_object(uintptr_t addr) {
assert(ZGlobalPhase == ZPhaseMark ||
ZGlobalPhase == ZPhaseMarkCompleted, "Forward not allowed");
ZForwarding* const forwarding = _forwarding_table.get(addr);
if (forwarding == NULL) {
// 如果forwarding table中没有,则无需迁移
return ZAddress::good(addr);
}
// 迁移对象
// 主要是迁移上一次GC时标记的对象
return _relocate.forward_object(forwarding, ZAddress::good(addr));
}
指针自愈
zBarrier.inline.hpp
template <ZBarrierFastPath fast_path>
inline void ZBarrier::self_heal(volatile oop* p, uintptr_t addr, uintptr_t heal_addr) {
if (heal_addr == 0) {
return;
}
assert(!fast_path(addr), "Invalid self heal");
assert(fast_path(heal_addr), "Invalid self heal");
// 死循环
for (;;) {
// CAS good指针替换原指针
const uintptr_t prev_addr = Atomic::cmpxchg((volatile uintptr_t*)p, addr, heal_addr);
if (prev_addr == addr) {
// CAS成功即可返回
return;
}
if (fast_path(prev_addr)) {
// 如果fast path判断为true,则直接返回
return;
}
// 走到这儿,可能是指针已经被其他barrier自愈了。
assert(ZAddress::offset(prev_addr) == ZAddress::offset(heal_addr), "Invalid offset");
addr = prev_addr;
}
}
总的来说,ZGC 的 load barrier 是个非常精巧的设计,借助 colored pointer 和多视图,有效地避免了 load barrier 带来的性能压力。
加入我们
我们是线索智能营销团队,负责字节跳动线索营销型产品研发。致力于帮助百万中小广告主更快速、更高效地获取高价值客户。利用字节的精准流量、数据智能技术,为广告主提供了具有线索获取、线索跟进、培育销转和再营销增长闭环的一站式客户线索管理平台。期待您的加入。
社招:https://job.toutiao.com/s/LK66Cf7
实习生:https://job.toutiao.com/s/LK61qf7



